Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Искусственный интеллект в CASE-технологии
Аннотация:
Abstract:
| Авторы: Вагин В.Н. (vagin@appmat.ru) - Московский энергетический институт (технический университет), г. Москва, Россия, доктор технических наук, Головина Е.Ю. () - , Салапина Н.О. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 12060 |
Версия для печати |
Широкое использование вычислительной техники в различных сферах деятельности человека привело к потребности создания соответствующего программного обеспечения (ПО). Однако трудоемкость и наукоемкость разработки программ настолько огромны, что ведутся работы по созданию новых технологий автоматизации проектирования программных средств. Это направление получило название CASE-технология (Computer - Aided Software Engineering) [13]. Применению методов и средств инженерии знаний нет границ, и в последние годы ведущими фирмами США, Японии и Западных стран проводятся работы по созданию интеллектуальных CASE-систем, которые значительно повысят качество и надежность программных систем, а также значительно уменьшат сроки их разработки [6,8,9,11,13,16,19]. Одно из центральных звеньев в CASE-системе - это репозиторий (информационная база проекта), являющийся основой интеграции в технологических системах. В репозиторий сосредоточена информация о создаваемом ПО на всех стадиях жизненного цикла (ЖЦ) от технического задания до сопровождения [4]. При этом репозиторий должен обеспечивать хранение не только самих проектируемых объектов, но и их версий или вносимых изменений. В зависимости от уровня автоматизации и степени охвата ею этапов разработки в репозитории хранятся тексты программ, спецификации требований, различные текстово-графические представления проекта, комментарий к нему, а также проектная и программная документация [5]. Репозиторий, построенный на основе традиционного подхода, представляет собой хранилище информации, необходимой для разработки ПО в CASE-системе. В настоящее время возникла необходимость в создании интеллектуального репозитория, который облегчит разработчикам процесс создания в CASE-системе ПО, отвечающего современному уровню. Создание интеллектуального репозитория имеет ряд преимуществ по сравнению с традиционным подходом к его разработке (как БД и система управления БД (СУБД)), среди которых можно выделить следующие: • возможность представления знаний, которые являются обобщением накопленного опыта о процессе проектирования ПО, и предоставление доступа к этим знаниям при разработке ПО; • получение новых знаний о разрабатываемом ПО из знаний, представленных в репозитории, которые помогают разработчику в процессе его проектирования; • возможность контроля непротиворечивости знаний; • возможность прогнозирования результатов проектных операций; • возможность сократить объем информации, представленной в репозитории, благодаря ее получению с помощью логического вывода и процедур. ОСНОВНЫЕ ФУНКЦИИ ИНТЕЛЛЕКТУАЛЬНОГО РЕПОЗИТОРИЯ Интеллектуальный репозиторий представляет собой сложную многофункциональную компоненту CASE-системы со следующими функциями: Охранения информации о разрабатываемом ПО на всех его стадиях ЖЦ; 2) пополнения информации, хранимой в репозитории; 3) логического контроля непротиворечивости вводимой информации; 4) получения ответов на запросы к информации о ПО в процессе его проектирования; 5) "интеллектуального советчика"; 6) группировки и совместного использования описаний по каждой прикладной системе; 7) управления доступом к информации в репозитории с помощью имен и паролей; 8) поддержки версий прикладной системы; 9) генерации отчетов. Остановимся на функциях, которые отсутствуют в репозитории, построенном на традиционном подходе, как БД и СУБД. Такими являются перечисленные выше функции с 3 по 5. Функция логического контроля на непротиворечивость вводимой информации должна быть реализована для любой стадии проектирования ПО. Непротиворечивость предполагает проверку допустимости вводимых значений и совместимости информации в репозитории на основе логического вывода. Для получения ответов на различные типы запросов к информации, представленной в репозитории, в процессе проектирования ПО введена функция 4. Функция интеллектуального советчика используется в процессе проектирования ПО; при инсталляции распределенной CASE-системы для выбора ее конфигурации, удовлетворяющей требованиям разработчиков ПО и рациональному использованию вычислительной техники в организации разработчиков; в аварийных ситуациях для выбора новой конфигурации CASE-системы. При использовании этой функции в процессе проектирования в качестве ее подфункций можно выделить следующие: - прогнозирование результатов проектных операций, то есть ответ на вопрос "Что будет, если применена конкретная проектная операция к некоторому состоянию разрабатываемого ПО?"; -планирование проектных операций (при этом должна быть выделена цепочка проектных операций, применение которой к некоторому исходному состоянию разрабатываемого ПО приводит к достижению требуемого проектного результата); - управление процессом проектирования ПО (эта функция определяет рекомендуемую разработчикам очередность применения операций и работ при проектировании ПО, например: "Если выполнена проектная операция iи проектная операция j, то выполнить проектную операцию к)". Эти функции репозитория могут быть реализованы в результате формализации очередности применения проектных операций и работ в продукционной модели, используя прямой, обратный и смешанный выводы на продукциях, при которых может происходить обращение как к формализуемой составляющей предметной области CASE-системы, так и к неформализуемой, а также к пользователю для получения дополнительной информации.
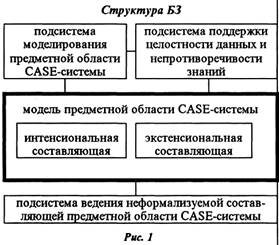
АРХИТЕКТУРА ИНТЕЛЛЕКТУАЛЬНОГО РЕПОЗИТОРИЯ Приведем компоненты интеллектуального репозитория, основываясь на концепциях инженерии знаний и программной инженерии для его построения. Компонентами интеллектуального репозитория являются база знаний (БЗ); интеллектуальная информационно-поисковая система (ИИПС); подсистема помощи при проектировании ПО; вспомогательные компоненты. Для реализации функции интеллектуального советчика в структуру репозитория должна входить ИИПС. Она содержит знания CASE о самой себе. Компонентой интеллектуального репозитория является и подсистема помощи при проектировании ПО. В ее состав входят две подсистемы: помощи в управлении процессом проектирования ПО; поддержки знаний о проектировании ПО. Вспомогательными компонентами интеллектуального репозитория являются: подсистема поддержки различных версий программных компонент; подсистема генерации отчетов и проектной документации; БЗ повторно используемых программных компонент. Одна из центральных компонент интеллектуального репозитория - это БЗ, структура которой представлена на рисунке 1. В основе БЗ лежит формальная модель предметной области CASE-системы. Вся информация о разрабатываемом ПО, которая может быть формализована, представляется в модели предметной области CASE-системы. Например, модель предметной области CASE-системы для создания систем поддержки управления состоит из следующих подмоделей: модели проектируемого ПО, модели организации пользователя, модели наблюдаемого (внешнего) объекта и системы наблюдения (контроля). Для ведения модели предметной области CASE-системы служат подсистема моделирования предметной области и подсистема поддержки целостности данных и непротиворечивости знаний. Подсистема моделирования предметной области CASE-системы должна обеспечивать пополнение/извлечение информации, содержащейся в модели предметной области, то есть добавление новых объектов (классов объектов, отношений, атрибутов, аксиом и правил вывода), изменение существующих и извлечение информации из модели, необходимой в процессе проектирования ПО. Подсистема поддержки целостности данных и непротиворечивости знаний осуществляет логический контроль данных и знаний на каждом этапе ЖЦ ПО. Репозиторий CASE-системы не может быть построен как чистая БЗ, в основе которой лежит одна или несколько моделей представления знаний. Это обусловлено тем, что репозиторий содержит разнородные формы представления информации, такие как текстовые, табличные, графические, звуковые и видео, которые не всегда могут быть формализованы в модели предметной области. Для пополнения/извлечения такой информации используется подсистема ведения неформализуемой составляющей предметной области CASE-системы, которая содержит различные формы представления объектов предметной области CASE-системы. ГИБРИДНАЯ МОДЕЛЬ ПРЕДМЕТНОЙ ОБЛАСТИ CASE-СИСТЕМЫ Поскольку в основе БЗ лежит формальная модель предметной области CASE-системы, рассмотрим методы ее построения. При построении формальной модели предметной области выделяются следующие этапы: • разработка концептуальной модели предметной области, содержащая классы объектов, представителей классов, разнообразные иерархические структуры, отношения между классами объектов, атрибуты классов объектов, различные описания; • разработка формальной модели предметной области, содержащая описание концептуальной модели предметной области на выбранном языке представления знаний, аксиомы и механизмы обработки знаний; • реализация формальной модели предметной области в компьютере. Концептуальная модель предметной области CASE-системы Рассмотрим подход к построению концептуальной модели предметной области CASE-системы, представляющей собой многоуровневую модель. Подмодели каждого уровня служат для представления информации, необходимой для проведения работ на соответствующем этапе ЖЦ ПО, и которые выделены в соответствии с группами людей, участвующими в разработке ПО, а именно: первый уровень модели хранит информацию о разрабатываемом ПО, получаемую на этапе анализа (модель анализа), второй - на этапе проектирования (модель проектирования), третий - на этапе кодирования и автономной отладки (модель кодирования), четвертый - на этапе комплектования и испытания (модель испытания), а на пятом и шестом уровнях модели представляется информация, необходимая для выполнения работ по инсталляции и сопровождению системы (модель инсталляции и сопровождения). Для успешного проведения работ на всех этапах ЖЦ ПО в модели предметной области CASE-системы выделяется нулевой уровень, на котором хранится информация для управления проектом (модель управления проектом), например сетевой график Ганта. Рассмотрим модели, которые представляются на каждом уровне многоуровневой модели предметной области CASE-системы проектирования систем поддержки управления (CASE/СПУ). Модель анализа состоит из двух подмоделей. а) Модель для пользователя, которая содержит описание предметной области проектируемой программной системы и начальные требования к ней. Она заполняется совместно разработчиками ПО и пользователями программной системы, которая будет разрабатываться в CASE-системе. Модель содержит классы объектов, атрибутов и отношения между классами, которые описывают, например, для системы поддержки управления [3,7,12]: - структуру организации пользователя; - аппаратные (сетевые) средства; - существующее ПО в организации пользователя; - внешний объект, или объект управления; - систему наблюдения (контроля). Отношения описывают взаимосвязи (что с чем соединено, какая информация откуда/куда поступает и т.д.) между классами объектов. Атрибуты задают характеристики классов объектов и требования к разрабатываемой системе. б) Модель для аналитика, в которой задаются системные требования к разрабатываемой системе, определяющие что система должна делать, описывается разбиение системы на логические компоненты и задаются взаимосвязи между ними. Она содержит различные документы, диаграммы, классы объектов, атрибуты и отношения, которые уточняют требования к ПО [17]. Модель проектирования служит для представления разрабатываемой программной системы на втором этапе ЖЦ ПО. Она содержит иерархии наследования и подчиненности классов объектов, описывающих проектируемую систему, структуру и интерфейсы классов объектов, уточненные диаграммы, спроектированные информационные объекты, их экранные формы, таблицы соответствия информационных объектов и экранных форм [1,10]. Модель кодирования и автономной отладки программных компонент системы содержит перечень ошибок, которые обнаружены в процессе их отладки, набор тестов, методы верификации. Модель испытания включает методику испытаний. Модель инсталляции и сопровождения содержит руководство по инсталляции, руководство пользователя, руководство оператора, тестовые примеры. В подмоделях каждого уровня выделены три составляющие, а именно: интенсиональная, экстенсиональная составляющие предметной области CASE-системы, а также процедурная составляющая, которая выделяется на уровне реализации БЗ. В интенсиональной составляющей подмоделей содержится информация, которая используется для проектирования системы поддержки управления определенным объектом, например аэропортом. Экстенсиональная составляющая подмоделей содержит конкретные объекты и отношения между ними, где структурное отношение часть-целое может образовывать Part of иерархию на представителях классов. В экстенсиональной составляющей находится информация, необходимая для проектирования конкретного ПО, например системы поддержки управления аэропортом "Внуково". Процедурная составляющая подмоделей содержит функции вычисления атрибутов, определения экстенсионалов отношений, а также процедуры, реализующие операции над объектами (отношениями и классами объектов), схемы вывода и алгоритмы принятия решений. Формальная модель предметной области CASE-системы Этапы анализа и проектирования являются наиболее важными, поскольку цена ошибок на этих этапах очень велика, и от правильного проведения работ на них зависит успех всей разработки ПО. Поэтому создадим формальную модель предметной области CASE-системы, удобную для представления необходимой информации, получаемой на этапах анализа и проектирования. Для формализации модели предметной области CASE-системы необходимо выбрать язык представления знаний, удобный для ее описания. В качестве формальной модели предметной области CASE-системы выбираем гибридную модель, объединяющую парадигмы программная инженерия и инженерия знаний: процедуры и модель представления знаний предметной области. Процедуры вызываются в процессе дедуктивного вывода. Они используются, например, для определения экстенсионалов отношений, нахождения значений атрибутов, реализации операций над объектами.
Концептуальные модели этапов анализа и проектирования содержат сложноструктурированную информацию. Поэтому в качестве формализма представления знаний предметной области CASE-системы используем логическую модель, основанную на многоуровневой логике (Multi-layer logic, или коротко MLL) [14,15], которая была разработана Setsuo Ohsuga и Hiroyuki Yamauchi. MLL является интеграцией логического подхода и подхода, основанного на семантической сети, к построению языка представления знаний. Для представления ISA и Part of иерархий в MLL используется иерархическая абстракция [15], представляющая граф, вершины которого соответствуют классам объектов или их представителям, а ребра - отношениям класс-подкласс либо часть-целое. Иерархическая абстракция представляет собой многоуровневую структуру. Уровни в иерархической абстракции, соответствующей отношению класс-подкласс, выделяются в соответствии с наследованием свойств. В иерархической абстракции, соответствующей отношению часть-целое. уровни выделяются в соответствии с принципом декомпозиции, основополагающим при объектно-ориентированном подходе к разработке ПО. Класс объектов и классы, из которых он состоит, располагаются на различных уровнях. Атрибуты классов объектов или их представителей (объектов) и отношения между классами объектов, исключая структурные отношения, в иерархической абстракции могут быть описаны отдельными предикатами и правильно построенными формулами (ППФ). Иерархические структуры (на рис. 2 представлены в стандартной форме [15]) являются многоуровневыми. Уровни, как и в иерархической абстракции, выделяются в соответствии с наследованием свойств. Так, классы объектов и их представители, которые находятся в отношении элемент-множество, располагаются на различных уровнях, а классы объектов, которые находятся в отношении содержит, - на одном уровне, поскольку нет наследования свойств. Описание двух видов иерархической абстракции и иерархической структуры множеством ППФ многоуровневой логики Принципиальной разницей между MLL и многосортной логикой (MSL) является форма представления иерархической абстракции и иерархической структуры посредством множества ППФ. MSL описывает явно отношение элемент-множество между объектами в префиксе ППФ в форме x/d, где х является элементом множества (сорта) d. Для задания иерархической абстракции, соответствующей ISA иерархии на предметной области, MLL использует расширение этого метода. Так, MLL позволяет работать с сортами, которые представляют собой структурированные единицы, элементами доменов которых могут быть множества, множества подмножеств и т.д. Для описания иерархической абстракции и иерархической структуры, соответствующих Part of иерархии классов объектов и Part of иерархии представителей классов, аппарат MSL использовать неудобно, поскольку Part of иерархия представляет собой взаимодействие различных сортов при описании предметной области, a MSL рассматривает сорта как отдельные, независимые единицы, и в ней нет средств, кроме предикатов, позволяющих описывать взаимодействие сортов. Использование предикатов для описания взаимодействия сортов усложняет и загромождает описание предметной области и снижает эффективность дедуктивного вывода. Для задания Part of иерархии в MLL введено три вида специальных знаков-слэшей [15]. Слэшем называется некий разделитель, который используется в префиксе формулы. Так, простой слэш (Qx/X) применяется для обозначения, когда х является элементом множества X (x Î Х), простой "жирный" слэш (Qx/X) обозначает, что х определен на множестве, элементами которого являются компоненты объекта X (XÑx), а двойной слэш (Qx// X) обозначает, что х определен на множестве, элементами которого являются части объекта X (XÑx). Синтаксис многоуровневой логики Для дальнейшего изложения материала представим синтаксис MLL и ее основные определения [15]. Алфавит:
(3). Все термы получаются применением (1) и (2). Правила образования ППФ: Fl. Если Р является n-местным предикатным символом и t1,t2,...,tn есть термы, то P(t1,t2,...,tn) является ППФ (атомарной формулой). F2. Если F и G - ППФ, то ~ (F), (F & G), (F V G), (F →G) и (F ↔ G) являются ППФ. F3. Если F - ППФ и х - предметная переменная, то
Формула (1) записана в стандартной форме для MLL [15]. Если объект Y имеет в качестве компонент несколько объектов, как показано на рисунке 2 б), то для того, чтобы задать нужную нам компоненту X объекта Y, необходимо использовать селектор, который представляется предикатом F(X, Y) [15]. Для этого случая, чтобы определить свойства х Î Х, являющегося частью объекта Y, необходимо написать формулу: Используя формализм задания структурных отношений в префиксе формулы, предлагаем замену селектора, представляющегося предикатом и используемого для нахождения нужной компоненты некоторого объекта, на композицию префикса. Рассмотрим предложенное расширение синтаксиса MLL.
Пусть объект #Y имеет в качестве компонент несколько объектов Xi, то есть <#Y> = {Xi}, i=l ¸ N, тогда префикс может содержать запись вида:
Запись (2) содержательно означает, что х определена на объединении частей #Y, имеющих сортность Xi Таким образом, расширены правила образования ППФ, которые имеют следующий вид: F1. Если P является n-местным предикатным символом и t1,t2,...,tn есть термы, то P(t1,t2,...,tn) является ППФ (атомарной формулой). F2. Если F и G - ППФ, то ~(F), (F & G), (FVG), (F →G) и (F«G) являются ППФ. F3. Если F - ППФ и х- предметная переменная, то
являются ППФ, где у есть константа или переменная, Z есть константное множество. F4. Других правил образования ППФ нет. Пример. Программная компонента х, входящая в состав системы поддержки управления #Р, обеспечивает посадку самолета у, приписанного к аэропорту #A, если имеется ЭВМ t, на которой функционирует х; радиолокационная станция (РЛС) s, соединенная с ЭВМ t; поток информации #I1, содержащий поток сообщений t1, принимаемый РЛС s и содержащий класс сообщений r7, описывающий самолет у и обрабатываемый x; поток информации #I2, содержащий поток сообщений t1, передающийся РЛС s, в который входит класс сообщений r2, содержащий сведения, необходимые для посадки самолета у, вырабатываемый х и принимаемый у. Запись в MSL:
Из рассмотренного примера следует, что аппарат MLL увеличивает эффективность дедуктивного вывода за счет сокращения пространства поиска, которое достигается структуризацией предметной области, и представления структурных отношений в префиксе логической формулы. Разработаны алгоритмы дедуктивного вывода в MLL для случая рассмотренного расширения ее синтаксиса, которые положены в основу системы моделирования предметной области КМ. Иерархическая абстракция и продукционная модель Поскольку предметная область системы поддержки управления является сложноструктурированной и динамической, и она представляется в базе знаний репозитория, рассмотрим средства для ее формализации. Из вышерассмотренного следует, что MLL является удобным средством для формализации структурного аспекта предметной области. Иерархическую абстракцию удобно использовать и при описании предметной области продукционной моделью представления знаний, которая применяется для отражения динамики изменения предметной области, когда для ее задания требуется огромное количество (1-10 тыс.) продукционных правил [2]. Иерархическая абстракция позволяет разбить продукционные правила на блоки в соответствии с принадлежностью к ее элементам и использовать механизм наследования продукционных правил. Механизм наследования продукционных правил позволяет сжать базу знаний, сделать ее более компактной. Рассмотрим механизм наследования продукционных правил на примере. Пусть задана иерархическая абстракция, которая описывает некоторую абстрактную предметную область "Аэропорт". Иерархическая абстракция состоит и 3-х уровней детализации: 1-й уровень - Аэропорт; 2-й уровень - РЛС, классы самолетов (ТУ, ИЛ, АН,...); 3-й уровень - представители классов РЛС, самолетов (конкретные объекты). Управление работой аэропорта задается множеством продукционных правил, которые разбиваются на блоки в соответствии с уровнями в иерархической абстракции следующим образом: в блок 1-го уровня входят продукционные правила, которые описывают принципы управления аэропортом в целом; в блоки 2-го уровня входят продукционные правила, которые описывают управление РЛС и классами самолетов; число блоков 3-го уровня определяется количеством представителей классов РЛС и самолетов. В каждый такой блок входят продукционные правила, которые задают специфические законы управления конкретным самолетом или РЛС. Остальные продукционные правила, которые задают общие законы управления РЛС и самолетами, могут быть получены благодаря механизму наследования. Таким образом, иерархическая абстракция позволяет создать иерархию продукционных правил и использовать принцип наследования продукционных правил, подобно механизму наследования свойств в ISA иерархии. Предлагаем использовать продукционную модель и для управления процессом проектирования ПО (прогнозирование, планирование и рекомендация проектных работ). Она совместно с иерархической абстракцией, описывающей структуру проектируемой программной системы, позволит на основе логического вывода получать рекомендуемые проектные работы для разработки конкретных компонент программной системы, используя механизм наследования продукционных правил, то есть продукционные правила, описывающие проектирование некоторого класса программных компонент, наследуются его представителями. При этом для представителей программного класса могут быть заданы специфические продукционные правила, используемые для выработки рекомендуемых проектных работ по их созданию. СИСТЕМА МОДЕЛИРОВАНИЯ ПРЕДМЕТНОЙ ОБЛАСТИ КМ Система KM (Knowledge Model) разработана как средство моделирования предметной области. Она может быть использована в качестве компоненты интеллектуального репозитория CASE-системы. В качестве компоненты репозитория CASE-системы КМ служит для: -пополнения модели знаний CASE-системы о самой себе, которая включает следующие подмодели: модель организации разработчиков, модели компонент CASE-системы, справочную модель (представление этих знаний в репозитории облегчает разработчикам создание ПО в CASE-системе); - пополнения репозитория на основе моделирования предметной области разрабатываемой системы и самой системы, которое осуществляется при проведении начальных этапов в ЖЦ ПО различными группами разработчиков (моделирование программных систем является методом для формализации начальных требований к программной системе на этапе анализа и методом для выделения классов объектов программной системы и требований к ним, которые необходимо реализовать, на этапе проектирования); - логического контроля информации, представленной в репозитории CASE-системы, на основе вывода в MLL; - получения значений атрибутов и экстенсионалов отношений с помощью логического вывода в MLL, что позволяет сжать экстенсиональную составляющую репозитория; - получения ответов на запросы пользователя на основе вывода в MLL. Система КМ поддерживает свободное соединение [18] БЗ и БД, под управлением СУБД Paradox. Подобная реализация системы КМ обеспечивает использование всех возможностей СУБД Paradox, таких как распределенная обработка, высокая производительность, сложный контроль, обеспечение целостности и безопасности данных, отказ и восстановление БД, поддержка очень больших БД. Работа выполнена на кафедре "Прикладная математика" Московского Энергетического института (технического университета) при финансовой поддержке Российского фонда фундаментальных исследований (код проекта 93-012-756). Авторы благодарят за помощь в работе ведущих сотрудников РосНИИ ИТ и АП Викторову Н.П. и Паронджанова С.Д. Список литературы 1. Буч Г. Объектно-ориентированное проектирование с примерами применения /Пер. с англ. - Совмест. изд-е: Диалектика, К., ИВК, 1992. 2. Вагин В.Н., Головина Е.Ю. Многоуровневая логика • модель представления знаний в экспертных системах.- В кн.: III конф. по ИИ /Сб. научн. тр.: В 2 т. - Тверь, Центрпрограммсистем, 1992. С.16-18. З.Викторова Н.П., Паронджанов С.Д. Особенности проектирования систем реального времени и требования к CASE-технологии разработки таких систем. /Материалы сем.: CASE-технология. -М.: ЦРДЗ,1992.-С. 17-27. 4. Позин Б.А. CASE-автоматизация проектирования программных средств /CASE-технология.-М.: МДНТП, 1992.-С.З-5. 5. Позин Б.А. Принципы реализации и направления развития интегрированных инструментальных средств. /Материалы сем.: Рабочие станции.- М.: ЦРДЗ,1992. - С.80-88. 6. Andrew J.Symohds Creating a Software-Engineering Knowledge Base.- Software Development Computer-Aided Software engineerig (CASE) / Chirofsky EJ.- IEEE Computer Society press technology series, 1989. 7. Cooling J.E.. Software Design for Real-time Systems.-CHAPMAN AND HALL (University and Professional Division).-1991,p.505. 8. Eisenstadt M., Brayshaw M. A Knowledge Engineering Toolkit.- BYTE, vol.15, No. 10,12,1990. 9. Eisenstadt M., Domingue J., Rajan T.,Motta E. Visual Knowledge Engineering,- IEEE Transactions on Software Engineering, Vol.16, No. 10, October 1990. 10. Gibson E. Objects - Born and Bred.- BYTE, October, 1990. 11.Hakkrainen K., Ihme Т., Metcalfe M. Prospex: knowledge - based case tool.- 1989 Scandinavian conference on artificial intelligence - 89 : proceeding of the SCAF 89, pp. 255-266. 12.Harel D. and ets. Statemate: a Working Environment for the Development of Complex Reactive Systems.-IEEE Transactions on Software Engineering, Vol. 16, No. 4, April 1990,pp.403-413. 13. Modern Software Engineering. Foundation and Current Perspectives.- Edited by Peter A.Ng., Raymond T. Yeh. - VAN NOSTRAND REINHOLD, New York,-1990.- p.591. 14. Ohsuga S. Toward inlelligent CAD systems.- Computer AidedDesing, Vol.2 l,-No.5,-1989.- p.315-337. 15. Ohsuga S., Yamauchi H. Multi-layer logic - a predicate logic including data structure as knowledge representation language.- New generation computing, Vol.3,-No.4,-1985-p.451-485. 16. Robert V. Rubin, James Walker II, Eric J. Golin Early Experience with the Visual Programmer's Workbench.-IEEE Transactions on Software Engineering, vol.16, No.10, 1990. 17. Sally Shlaer and Stephen J. Mellor " Object Lifecycles: Modeling the World in States",Prentice-Hall, Englewood Cliffs, NJ., 1992. 18. Yamauchi H., Ohsuga S. Loose coupling of KAUS with existing RDBMSs.- Data & Knowledge Engineering, 5, 1990,-pp.227-251. 19. Yokoyamat An object-oriented and constraint-based knowledge representation system for design object modeling.-Tokyo, Japan, ICOT Research Center, 1989. |







| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1080 |
Версия для печати |
| Статья опубликована в выпуске журнала № 3 за 1996 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Учебный банк: технологии изучения банковских систем и телекоммуникаций
- Оптимизация структуры базы данных информационной системы ПАТЕНТ
- Автоматизированная информационная система маркетолога
- Система визуализации реального времени на основе программируемых сигнальных процессоров
- Сравнительная характеристика текстовых редакторов
Назад, к списку статей