Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Редактор иерархической информации
Аннотация:
Abstract:
| Авторы: Михайлюк М.В. (mix@niisi.ras.ru) - НИИСИ РАН, г. Москва, Москва, Россия, доктор физико-математических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10869 |
Версия для печати |
В работе рассматривается модель редактора иерархической информации, то есть любой информации, организация которой имеет древовидную структуру. У этой модели универсальный характер в том смысле, что с помощью механизма настройки она может быть применима к любой информации такого вида. Сначала мы опишем саму модель редактора, а затем приведем пример ее настройки для обработки алгебраических формул в системе символьных преобразований "Алгебра". Заметим, что любая информация, с которой сталкивается и работает пользователь, по сути дела является упорядоченной. Это объясняется в первую очередь спецификой человеческого мышления, его стремлением анализировать и классифицировать информацию об окружающем мире. Рассмотрим несколько примеров. Пример 1. Любая книга является формой организации определенного текста, имеет заглавие, необходимое число глав или параграфов, которые состоят из абзацев текста. Абзацы в свою очередь включают в себя предложения, состоящие из слов, и т.д. Тем самым определено отношение вхождения и порядка на множестве структурных единиц текста, или, другими словами, это множество имеет иерархическую структуру. Пример 2. Более сложным примером являются таблицы. Каждая таблица имеет определенную структуру столбцов и обобщенных строк, в которые входят предложения, подчиненные тому же порядку, что и обычный текст. Под обобщенной строкой мы понимаем строку одного столбца таблицы, относящуюся к одному пункту горизонтальной разграфки. Пример 3. Текст программы на языке программирования представляет собой последовательность операторов, причем есть сложные операторы (блоки), состоящие из последовательности простых. У каждого оператора вполне определенная структура, которая обычно задается в формальном виде в форме Бэкуса-Наура. Здесь опять же мы имеем иерархическое множество программных компонентов. Пример 4. Произвольная алгебраическая формула является строго организованным множеством имен функций и их аргументов. В качестве аргументов функций могут выступать числа, переменные и такие же алгебраические формулы. Ниже мы рассмотрим этот пример более подробно. Иерархическая или частично упорядоченная информация, примеры которой приведены ранее, как известно, может быть представлена в виде дерева или множества деревьев (леса). В каждом узле дерева находится некоторая часть информации, причем в зависимости от уровня глубины обработки информации эти части могут быть различными. В частности, некоторые узлы могут быть пустыми и использоваться только для определения структурного разделения информации. Рассмотрим примеры деревьев для перечисленных видов информационных массивов. Для примера 1 дерево изображено на рисунке 1.
Здесь в корне дерева записано заглавие книги, в узлах первого уровня - наименования глав, в узлах второго ничего не записано, они соответствуют абзацам (которые не имеют названий). Узлы следующего уровня также пусты, они соответствуют предложениям, а в узлах последнего уровня (листьях дерева) записаны отдельные слова. Можно сделать еще большее деление, разбив слова на буквы. Для примера 2 рассмотрим таблицу, изображенную на рисунке 2.
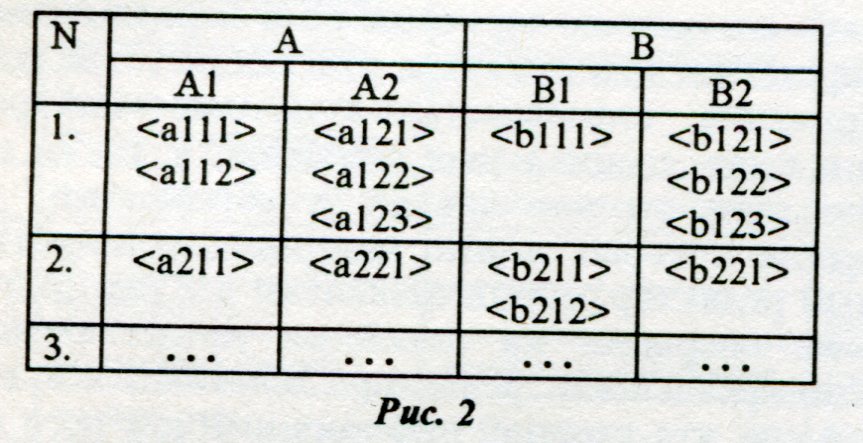
Таблица имеет столбцы А и В, разделенные на подстолбцы соответственно Al, A2 и Bl, B2. В самом левом столбце нумеруются обобщенные строки. Фактически каждый номер соответствует одной строке, но в связи с тем, что ширина, например, столбца А2 меньше, чем длина текста, который должен быть в него записан, этот текст разбит на подстроки а121, а122 и а123. Всю структуру подстрок, относящуюся к одному номеру, мы и называем обобщенной строкой. Дерево, соответствующее этой таблице, изображено на рисунке 3. Название таблицы
Для примера 3 мы не будем приводить изображение соответствующего дерева, так как его нетрудно себе представить на основе предыдущих примеров. Рассмотрим пример алгебраической формулы.
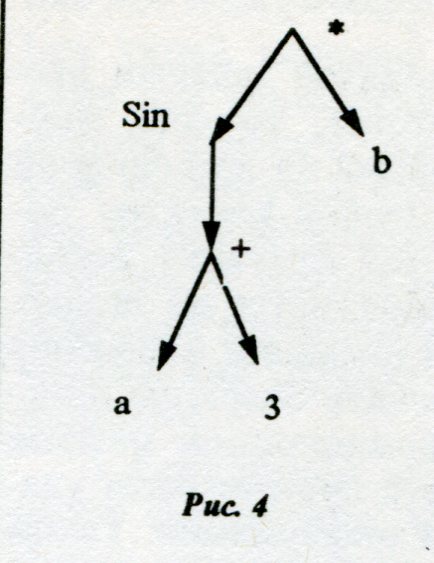
Алгебраической формуле Sin(a+3)*b соответствует естественным образом дерево, изображенное на рисунке 4. Здесь в узлах дерева записаны имена функций из сигнатуры алгебры, в которой представлена формула, а в листьях - переменные или числа. Естественно, что такая иерархическая организация информации предполагает и специфические средства ее обработки, в частности в редакторе. Важно отметить, что подобная организация присуща информации как таковой, а не виду ее записи или представления. Именно этим обусловлена важность наличия таких редакторских операций, которые адекватны этой внутренней сущности. Однако в существующих редакторах нет четкого соотнесения имеющихся операций их иерархическим двойникам, например: переход вниз или вверх на соседнюю строку в той же колонке ничему не соответствует в иерархии дерева. Дело здесь заключается в наличии еще одной иерархической структуры (структуры экранов и строк редактора), относительно которой и выполняются операции. Это структура представления информации, она не присуща самой информации как таковой. Таким образом, имеются как бы две наложенных структуры: одна обусловлена представлением информации в строчном редакторе, а другая - самой природой информации. Подобное наличие двух наложенных структур определяет необходимость соответствующих двух множеств редакторских операций. Первое множество имеется во всех редакторах. Оно основано на таких объектах, как символ, строка символов, группа строк, и включает следующие основные операции. Переходы курсора: - на одну позицию влево, вправо, вверх и вниз, - на начало строки, - на конец строки, - на предыдущий экран, - на следующий экран, - на первую строку текущего экрана, - на последнюю строку текущего экрана, - на начало файла, - на конец файла. Удаления: - символа справа (слева) от курсора, - текущей строки, - выделенного линейного куска текста. Вставки: - символа, - строки, -выделенного ранее линейного куска текста. Нашей же основной задачей является рассмотрение второго множества, то есть множества редакторских операций на древовидной структуре. Отметим, что любой редактор позволяет изменять только тот фрагмент исходного текста, который отображается на экране. Другими словами, каждой операции изменения текста должна предшествовать операция поиска нужного места в информационном массиве [1], после чего в этом месте производится удаление, замена или вставка информации. Таким образом, основными в дереве являются следующие специальные операции. 1. Переходы из произвольного узла дерева: - на i-ro сына, - на отца, - на следующего (предыдущего) брата, - на 1 -го (последнего) брата, - на начало дерева (корень), - на конец дерева, - на 1-й (последний) узел одного уровня (не зависимо от отца), - на следующий (предыдущий) узел одного уровня (независимо от отца), - на начало (конец) имени узла. 2. Поиск: - имени (части имени) узла в текущем под дереве, - поиск поддерева по шаблону в текущем поддереве. 3. Выделение, замена, удаление и вставка поддерева. Заметим, что поиск имени или его части в текущем поддереве можно проводить несколькими различными способами, определяемыми алгоритмом обхода узлов дерева. Например, возможен обход "сначала отец, потом его дети", а возможен и другой обход - "сначала все отцы, потом все дети" (то есть поиск по уровням). Что касается операций выделения, замены, удаления и вставки, то они производятся в рамках всего поддерева, в корне которого мы в настоящий момент находимся. Это значит, что мы можем удалить текущее поддерево, заменить его на новое и т.д. При этом вставка нового поддерева может производиться как перед, так и после текущего поддерева. Представление и реализация выделенных операций на дереве достаточно прозрачны, однако сложность заключается в том, что практически всегда иерархическая информация представляется в редакторах в линейном виде, то есть в виде последовательности строк текста. Попытки отказаться от такого представления вызывают большие затруднения и не приводят к успеху. В [1] отмечено, что "при разработке специального редактора для языка программирования требование совместимости текстовых файлов с файлами операционной системы не позволило отказаться от концептуальной модели текста программы как последовательности строк символов" и что "отказ от требований совместимости позволит перейти к редакторам на основе естественной концептуальной модели программы в виде дерева". В линейном представлении для сохранения сведений о структуре информации приходится использовать специальные символы и соглашения. Например, в алгебраической формуле f(a,b,c) для отделения отца (имени функции) от сыновей (аргументов) используются скобки, а для отделения сыновей друг от друга - запятые. Естественно, что такое представление затрудняет выполнение иерархических редакторских операций, но не снимает их необходимости. Наша задача рассмотреть способы отображения иерархической информации в линейный вид и на этой основе попытаться сформулировать алгоритмы перечисленных иерархических переходов. Мы покажем, что любое такое отображение определяется конечным набором множеств специальных символов, а также небольшим числом правил и соглашений, на основе которых можно построить универсальный редактор, обеспечивающий все иерархические операции на линейном представлении. Универсальность редактора понимается в том смысле, что входной информацией для него является не только информационный файл, но и специальная настроечная информация, на основе которой он будет производить операции. Рассмотрим более подробно представление иерархической информации в линейном виде. Это представление должно быть взаимно однозначным, то есть таким, по которому можно было бы восстановить деревянную структуру. Мы можем выделить три основных представления иерархического веера - префиксный, инфиксный и постфиксный. Их форма и примеры из области алгебраических формул приведены на рисунке 5.
Из рисунка видно, что должны существовать некоторые специальные множества Мн, Мк и Мс обобщенных символов, используемых для отделения отца от сьшовей и сьшовей друг от друга. Для алгебраической формулы такими символами являются скобки и запятая, то есть Мн = { ( }, Мк = { ) }, Мс= {,}, для языка программирования - ключевые слова begin, end и точка с запятой (соответственно Мн = { begin }, Мк = {end}, Мс= {;}) и т.д. Заметим, что наличие специальных множеств МН) Мк и Мс позволяет по любой правильной линейной записи однозначно восстановить древовидную структуру информации. Используя терминологию алгебры, введем следующее ОПРЕДЕЛЕНИЕ 1. Отец в префиксной (инфиксной, постфиксной) форме веера называется соответственно префиксной (инфиксной, постфиксной) операцией. Сын в любой форме записи называется аргументом. Сын, не являющийся отцом, называется элементарной формулой (в случае алгебраической формулы это может быть переменная или число).
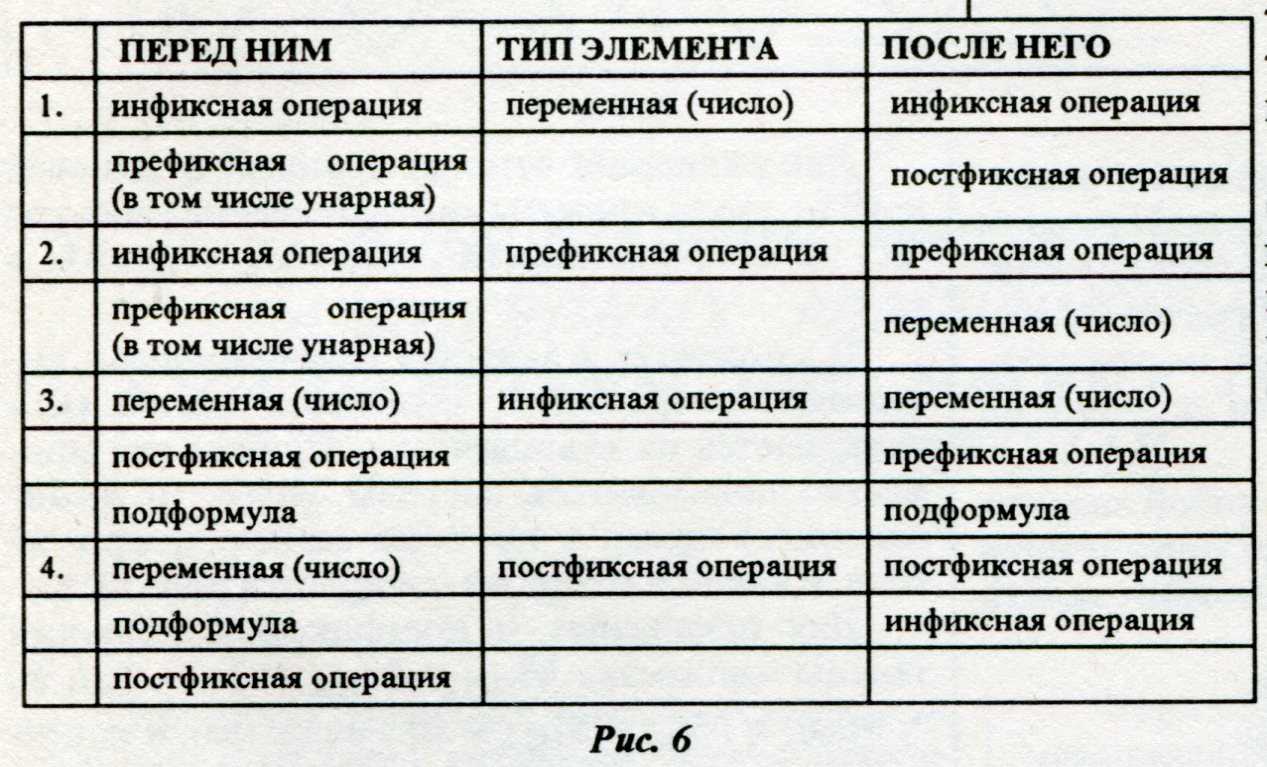
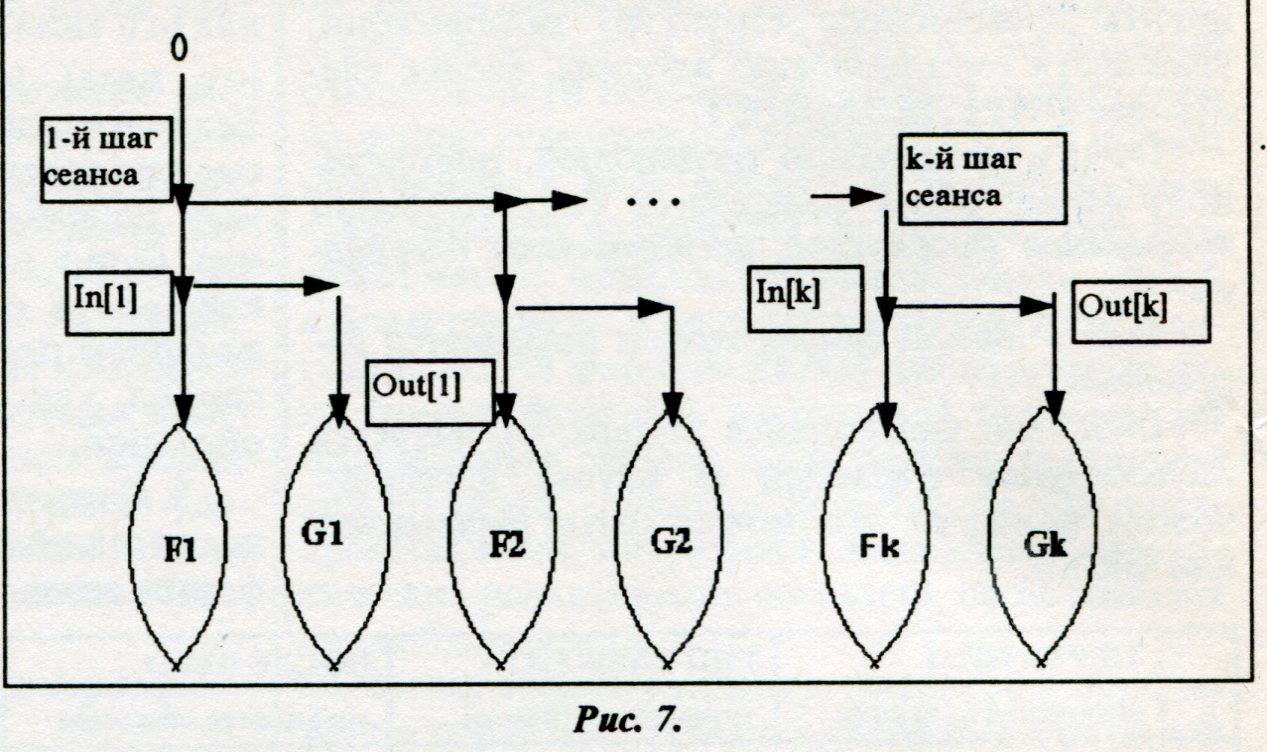
Специальные знаки, отделяющие отца от сыновей, будем называть скобками. Поддерево, заключенное в скобки, называется подформулой. Проанализируем линейный вид иерархической информации, чтобы понять, в какой последовательности могут следовать элементы различных типов. Для этого составим таблицу (рис. 6), в которой для каждого типа элемента указано, какие типы могут быть записаны непосредственно перед ним и какие после него в линейной записи. Например, первая строка показывает, что перед элементарной формулой может быть записана только инфиксная или префиксная операция, а после нее - инфиксная или постфиксная. Обычно стараются упростить линейную форму записи, опуская, где можно, специальные знаки. Однако каждая такая процедура определяет некое соглашение, которое позволяет однозначно восстановить древовидную структуру. Рассмотрим следующее множество общепринятых процедур и соглашений. 1. Скобки должны опускаться попарно: если мы убираем правую скобку, то должны убрать и левую и наоборот. 2. Если мы убираем скобки, отделяющие один тип от другого, то тем самым определяют ся множества Мкд (конечных символов в име нах i-ro типа) и Мн j (начальных символов имен j-ro типа), которые должны не пересекаться. Если эти множества пересекаются, то мы не сможем отделить одно имя от другого и тем са мым однозначно восстановить дерево. Напри мер, если в инфиксной форме записи мы не за ключаем в скобки переменные, то последним символом переменной не может быть такой же символ, как первый символ имени инфиксной операции. 3. Соглашение о скобках в последовательности одинаковых операций. Если инфиксная форма ассоциативна, то в последовательности таких форм скобки можно опустить, предполагая левую ассоциативность. 4. В последовательности любых отцов можно опускать скобки, предполагая заданным старшинство операций. В порядке убывания старшинство задается следующим списком. • Префиксные операции. • Постфиксные операции сле ва направо. • Инфиксные операции слева направо по старшинству. Таким образом, редактор иерархической информации должен учитывать перечисленные соглашения. Для этого в нем должны быть определены следующие множества. 1. Множества спецсимволов Мн и Мк для отделения отца от сыновей. 2. Множество Мс спецсимволов для отделе ния сыновей друг от друга. 3. Упорядоченное множество I инфиксных операций. 4. Множества MH>j и MK>j специфических начальных и конечных символов имен i-ro ти па. Задание этих множеств, то есть набор X = {Мн, МК) Мс, I, {МН4 ,МкД}}, можно рассматривать как настройку универсального редактора на конкретный вид информации. Этот редактор будет в своей работе использовать заданные множества. С другой стороны, используя эти определения, можно реализовать описанные выше специальные редакторские функции. Эту же настроечную информацию можно использовать для контроля информации в смысле правильности задания ее структуры. В линейном отображении информации имеются еще две проблемы. Первая заключается в том, что часто надо разрешать редактировать не всю информацию, а только какую-то ее часть. Например, если выводится шаблон таблицы, которую необходимо заполнять вводимой информацией, то хорошо бы запретить исправлять шапку таблицы и названия вводимых показателей, которые записаны в первом столбце. Ниже будут приведены и другие примеры. Для осуществления этого вводится понятие поля редактирования и шаблона строки. Рассмотрим эти понятия более подробно. Поле редактирования определяется как интервал последовательных строк, в которых разрешено редактирование. В процессе обработки информации интервал задается и может изменяться вручную или программными модулями. Нажатие произвольной символьной клавиши вне поля редактирования не оказывает никакого действия на информационный файл. Шаблон строки представляет собой задание полей в строке, внутри которых осуществляется работа редактора. Например, можно задать шаблон из трех полей: 1 -е поле с 5-й по 10-ю позиции, 2-е поле с 17-й по 40-ю позиции, 3-е поле с 56-й по 78-ю позиции. Тогда при работе редактору будут доступны для редактирования только эти поля каждой строки поля редактирования. Если курсор находится на 10-й позиции и пользователь нажимает клавишу "сдвиг курсора вправо", то курсор перейдет не на 11 -ю, а на 17-ю позицию. Шаблон строки также может задаваться и изменяться в процессе редактирования. Использование поля редактирования и шаблона строки предоставляет пользователю большие удобства и возможности при работе. Настройка модели для редактирования алгебраических формул В соответствии с описанной моделью нами создан редактор иерархической информации, который был настроен на конкретный вид информации - алгебраические формулы - заданием указанных множеств из Н. Настройка позволила использовать редактор в системе символьных преобразований "Алгебра", разработанной в ИВВС РАН. Информационный файл в системе представляет собой последовательность шагов сеанса работы. Каждый шаг состоит из входа (алгебраической формулы) и выхода (результата ее преобразования), а каждая алгебраическая формула представляется в виде дерева. Таким образом, все дерево сеанса имеет вид, изображенный на рисунке 7.
Для отделения отца от сыновей и сыновей друг от друга приняты соответственно символы "(", ")" и ",", то есть Мн = {(}, Мк = {)}, Мс = В множестве I задается полный список инфиксных операций и числовыми величинами указывается их старшинство. Причем это множество пользователь системы задает (и может изменить) прямо в процессе сеанса, исходя из того, в какой алгебре он собирается работать. Для инфиксных и постфиксных операций заданы множества Мн>р = МК)р = {+, -, *, /, &, Л, #, @} и Мнд = МК4 = W начальных и конечных символов, из которых могут состоять их имена. Все числа начинаются и заканчиваются десятичной цифрой. Вход шага сеанса с номером 1 начинается с символов InpJ, а выход - с символов OutJiJ. Заканчиваются же они символом ';'• Задание этих множеств автоматически настраивает редактор на данный тип информации и не требует никакого дополнительного программирования. Кроме перечисленных основных операций, редактор обеспечивает выполнение специальных операций, которые для алгебраических формул приобретают следующий смысл. 1. Переходы из произвольного узла дерева: - на i-й аргумент функции, - на имя вышестоящей функции, - на следующий (предыдущий) аргумент, - на 1-й (последний) аргумент функции, - на самую внешнюю функцию формулы, - на самое последнее поддерево, - на 1-ю (последнюю) подформулу текущего уровня (независимо от отца), - на следующую (предыдущую) подформулу текущего уровня (независимо от отца), - на начало (конец) имени операции. 2. Поиск: -имени (части имени) операции (переменной), -выделение, замена, удаление и вставка подформулы. Далее очевидно, что, проводя сеанс работы в системе, редактировать можно только последнюю вводимую алгебраическую формулу (то есть вход последнего шага сеанса). Нельзя исправлять результаты предыдущих шагов сеанса или их входы, так как тогда пропадет уверенность в правильности полученных окончательных результатов. Эта проблема и решается в редакторе заданием "поля редактирования", которое в системе "Алгебра" автоматически устанавливается равным входу последнего шага сеанса. Шаблон строки используется в системе для того, чтобы не разрешить пользователю исправить выводимые автоматически номера шагов сеанса. Эти номера выводятся в начале строки и занимают первые 8 позиций. Алгебраические формулы располагаются с 9 по 80 позиции, что и задается с помощью шаблона строки. Кроме того, шаблон строки используется в системе для работы с таблицами, что позволяет осуществлять быстрые переходы между столбцами таблиц и блокирует исправление их шапок. Список литературы 1. Бетелин В.Б. Экранные редакторы, ориентированные на язык программирования. - М., 198S. - (Препр. /НСК АН СССР). 2. Michajliuk M.V. Editor for Hierarchical Information. Proceedings of the International Workshop "New Computer Technologies in Control Systems", Pereslavl-Zalessky, 1995. |



| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1090 |
Версия для печати |
| Статья опубликована в выпуске журнала № 4 за 1996 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Компьютерная интеграция и интеллектуализация производств на основе их унифицированных моделей
- Базовое программное обеспечение целостных компьютеризированных курсов в современной операционной обстановке
- Реализация теней с помощью библиотеки OpenGL
- Компьютер - хранитель домашнего очага
- Место XML-технологий в среде современных информационных технологий
Назад, к списку статей