Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Повышение эффективности тестирования программ за счет усложнения диагностического эксперимента
Аннотация:
Abstract:
| Автор: Цыков П.В. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 11374 |
Версия для печати |
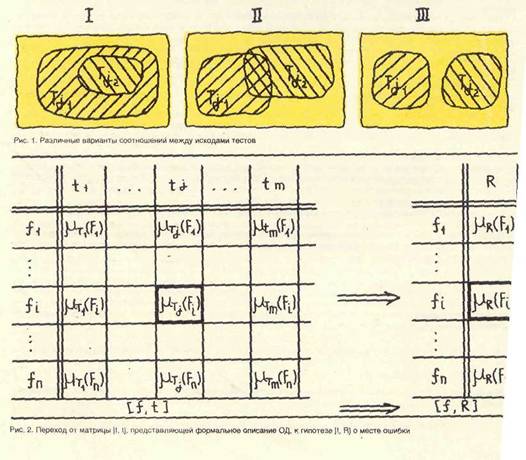
По мере развития вычислительной техники поиск ошибок в программах и программных комплексах с помощью различных наборов тестов при отладке становится все более трудоемким, поскольку каждый тест определяется входными и выходными данными, точками ввода данных и контрольными точками. Для программы как объекта диагностирования (ОД) характерны следующие особенности: — отсутствие полностью определенного эталона, которому должны соответствовать все результаты тестирования программы; — высокая сложность программ и невозможность построения в большинстве случаев набора тестов, достаточных для их исчерпывающей проверки; — относительно невысокая степень формализации критериев качества тестирования. В .этих условиях становится принципиально невозможным получение полны» исходных данных об ОД, подразумевающих описание всего множества допустимых ошибок и реакций тестов на них, что сделало бы решение задачи поиска ошибок чисто автоматическим. Поэтому на практике при отладке программ разработчику обычно приходится полагаться на личный опыт, который редко поддается непосредственной количественной оценке, и итеративно, выдвигая на каждом шаге гипотезу и затем, уточняя ее, отыскивать ошибку. Прохождение каждого шага, как правило, связано с анализом результата выполнения одного теста, ориентированного на проверку одной или небольшого числа программных компонент. Таким образом, следуя данной схеме построения диагностического эксперимента, разработчику приходится тщательно строить каждый эксперимент и проверять много гипотез, возвращаясь в случае неудачи к анализу первого теста. При этом практически никак не учитываются соотношения между исходами различных тестов, что позволяет в большинстве случаев существенно повысить их разрешающую способность. Для повышения эффективности тестирования программ можно усложнить диагностический эксперимент благодаря возможности анализировать совокупный результат выполнения нескольких тестов, дифференцированно описывать результат выполнения отдельного теста и выдвигать более сложные гипотезы о классе и месте ошибки. Эффект повышения разрешающей способности тестов в совокупном результате тестирования иллюстрируется рис. 1, гдеТ , Т —подмножества ошибок, обнаруживаемых тестами t-, t . Каждому из трех изображенных вариантов ниже дано соответствующее формальное определение. Для решения поставленных задач .предлагается использовать отдельные положения вероятностного подхода, первоначально разработанного автором для автоматизации обработки результатов тестирования аппаратуры вычислительных комплексов СМ ЭВМ, представляющих собой сложные ОД. При этом ошибку в программе и неисправность в аппаратуре предлагается рассматривать с единых позиций как некоторое отклонение реального ОД от эталона, которое вызывает неправильное выполнение каких-либо функциональных требований, предъявляемых к нему. Поскольку опыт разработчика носит прс-имущественнС) неколичественный характер, то в качестве основной формы описания ОД выбирается нечеткая модель. А для вычисления функций принадлежности вводимых в рассмотрение нечетки* множеств используется качественное вероятностное отношение предпочтения «менее вероятно, чем>.. Пусть f.(j = 1,п) являются отдельными компонентами программы или программного комплекса, проверяемыми с помощью набора тестов tj(j = l,m). С каждой компонентой f-связываем подмножество F, допустимых ошибок, которые могут иметь место в этой компоненте. Таким образом, Fs ПРЬ = £Э при ij ф i, и UF, = Т. где "V —- множество всех допустимых ошибок в проверяемой программе. Для_отраженин причинно-следственных связей между наличием ошибок в программных компонентах fj(i = l,n) и исходами тестов ^(j = l,m) введем нечеткие множестваTjfj = l,m), соответствующие ошибочному выполнению тестов. Нечеткие множества Т{ будут соответствовать выполнению тестов без ошибок. Значения функции принадлежности flj-j нечеткого множества Т. определяются на подмноже- ствал Fjfi = 1 ,п) и будут иметь тем большее значение, чем больше вероятность обнаружения тестом t-ошибки в программной компоненте. Вероятность обнаружения ошибки в задачах технической диагностики интерпретируется также как полнота проверки тестом отдельной компоненты ОД. Для построения функций принадлежности Мт№)0 = l,m) используем качественное вероятностное отношение предпочтения «менее вероятно, чем». Именно в этих терминах разработчику программы предлагается отразить свои знания по вероятности обнаружения тестами ошибок в рассматриваемых компонентах (чем полнее тест тгроверяет программную компоненту, тем выше предпочтение). Чтобы обработка совокупного результата выполнения тесгов была согласованной, предпочтения должны устанавливаться не только для каждого теста в отдельности, но и попарно между тестами из используемого набора. Кроме того, из-за неаддитивности функции принадлежности предпочтения по вероятности целесообразно устанавливать с учетом двух возможных исяодов (с ошибкой и без ошибки). Если построенное вероятностное отношение предпочтения является отношением слабого порядка, то на его основе уже можно непротиворечивым и согласованным образом построить все рассматриваемые функции принадлежности [i, (Fj)(j = 1 ,m) , которые будут количественно отражать предпочтения разработчика. Кратко существо методики построения функций принадлежности состоит в следующем. Если множество элементов удается слабо упорядочить, то его можно разбить на группы так, что внутри каждой оказываются одинаково предпочтительные элементы, а между элементами разных групп устанавливается строгое предпочтение. Причем если элемент одной группы более предпочтителен, чем хотя бы один элемент другой, то он будет предпочтительнее и любого другого элемента из этой же группы. Далее значения функций принадлежности устанавливаются в интервале (0,1) таким образом, чтобы отразить предпочтения между группами. Если число групп равно /, то значений функций принадлежности в общем случае будет / + 2, так как значения 0 и 1 целесообразно устанавливать только при наличии абсолютно достоверных знаний о полноте проверки тестом соответствующей программной компоненты. Все / + 2 значения устанавливаются равномерно или неравномерно на отрезке [0,1] в зависимости от равномерности шкалы предпочтений. Построение функций принадлежности упрощается, если разработчик может установить свои предпочтения в баллах (при максимальной оценке в один балл). Однако возможность установления отношения слабого порядка определяет в общем случае ту нижнюю границу, за которой уже не удается построить непротиворечивую формальную процедуру поиска ошибок. Значения функций принадлежности собираются в матрицу [f, tj. представленную на рис. 2, которую можно рассматривать как обобщение традиционной диагностической таблицы неисправностей. Строки матрицы соответствуют программным компонентам f.(i = l,n), а столбцы — тестам t.(j = l,m). Элементы матрицы равны соответствующим значениям функции принадлежности [t» (FJ/1 = 1,п; j = l,m). Матрица [f, t) представляет формальное описание ОД, на его основе строится обработка результатов вьшолнения тестов. Пусть при выполнении диагностического эксперимента К тестов из набора прошли с ошибкой, а остальные (т — к) — без ошибки. Тогда совокупный результат будет описываться через нечеткое множество
Гипотеза о месте ошибки [f, Rj (см. рис. 2) формулируется следующим образом: в число подозреваемых на ошибку программных компонент входят те из них, для которых значения функции принадлежности HB(Fl)(i = Тд>) результирующего нечеткого множества больше нуля; чем больше значение этой функции, тем больше и вероятность того, что в соответствующей компоненте программы имеется ошибка. Звючения функции принадлежности результирующего нечеткого множества R предлагается вычислять тремя различными способами в зависимости от того, как связаны между собой неходы различных тестов из набора. Если тесты в наборе построены таким образом, что из каждых двух тестон один обнаруживает ошибки в программе, составляющие точное подмножество ошибок, которые обнаруживает другой тест (см. вариант I, рис. I), тогда
Если тесты к наборе построены так, что каждые два теста обнаруживают непересекающиеся подмножества ошибок (см. вариант III, рис. I), тогда
И наконец в промежуточных случаях, когда тесты в наборе строятся произвольно (см. вариант U, рис. I), тогда
Правила, предлагаемы!. №„ , трем различным способам определения функции принадлеж-нуц,! Бьвдвигаемая на основе функции принадлежности Цц(Р() гипотеза о месте ошибки может оыть ниш.., нителыю скорректирована, если учесть неодинаковые априорные вероятности присутствия ошибки в различных компонентах программы 15 ряде случаев целесообразно строить гипотезы о месте ошибки в предположении офаниченности класса допустимых ошибок С С F. Тогда элементы матрицы If, i] будут иметь значения Ць(Б^ПС)(| = 1,п; j = l,m), которые отражают предпочтения разработчика при введенных ограничениях и затем будут перенесены на совокупный результат выполнения тестов. Еще более дифференцированные гипотезы можно построить, если ввести несколько классов допустимых ошибок. Следует отметить, что а правилах выдерживается основная, подтвержденная практикой стратегия диагностирования, согласно которой лучше ошибочно указать на наличие ошибки, чем пропустить ее. Это тем более оправдано для таких ОД, как программы, для которых построение полных тестов — невыполнимая задача. К тому же, яри заведомой неполноте ■гестов, если все они прошли без ошибок., а программа все-таки работает неверно, значения функции принадлежности результирующего нечеткого множества можно интерпретировать несколько иным способом. Чем больше значеная n^Fj), тем в меньшей степени проверяются соответствующие компоненты; значит тесты, используемые на следующем этапе отладки программы, должны ориентироваться в первую очередь на проверку этих компонент. Если в гипотезе, выдвинутой по совокупному результату выполнения нескольких тестов, среди подозреваемых компонент ошибки не обнаружены (например при неверном установлении значений 0 и 1 для функций принадлежности ^(F,) (j = 1-,тп)> тогда в анализе совокупного результата можно вернуться на один или несколько шагов назад. Для этого в результирующем нечетком множестве R надо исключить из рассмотрения исходы последних тестов. Все предложенные правила имеют определенное обоснование с позиций теории вероятностей и математической статистики. Они также получили и практическое подтверждение: при построении процедуры поиска неисправностей в аппаратуре контроллеров крейта КАМАК, что позволило в три раза сократить время поиска; в медицинской диагностике, если вместо значений функций принадлежности |Lj. (F,) используются условные вероятности Р (Tj/Fj). При этом Ft рассматривается как случайное собы-тй!е, связанное с возникновением некоторой допустимой ошибки в программной компоненте £,, а Т. — как случайное событие, связанное с ошибочным выполнением теста tj. Правила можно использовать и в тех случаях, когда справедливо соответствующее предположение о связи между исходами тестов.
|
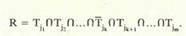
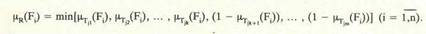
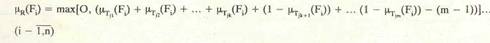
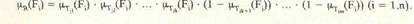
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1348 |
Версия для печати |
| Статья опубликована в выпуске журнала № 1 за 1989 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик: