Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Персональные базы данных
Аннотация:
Abstract:
| Авторы: Ананьевский С.А. () - , Шолмов Л.И. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 19344 |
Версия для печати |
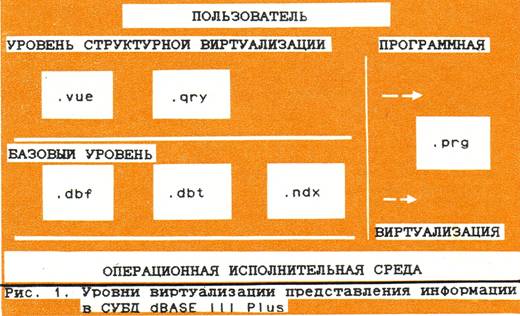
В области автоматизации управленческой деятельности в последнее время выделяется направление автоматизация учрежденческих работ. С точки зрения автоматизации его можно считать направлением автоматизации сферы управления «снизу вверх» на базе персональных ЭВМ (ПЭВМ), используемых на рабочем месте сотрудниками, т.е. в принципе АРМ (автоматизированные рабочие места). АРМ — совокупность технических и программных средств, позволяющих использовать машинные носители информации вместо традиционных бумажных и, как следствие, автоматизировать операции обработки как элементарные, связанные с подготовкой и редактированием текстовой, графической и табличной информации, так и более сложные, связанные с проведением расчетов, общеалгоритмической обработкой, принятием решений и т. п. В отличие от этого традиционного взгляда АРМ могут рассматриваться как относительно независимые элементы некоторой инфраструктуры коммуникаций людей, занятых совместным трудом, наличие или отсутствие которых по отдельности не сказывается на функционировании системы в целом. Внедрение АРМ является принципиальным моментом и в этом смысле представляет собой определенную альтернативу методам проектирования традиционных АСУ. Одиночные АРМ даже при высокой насыщенности не дадут значительного прямого эффекта. Основными достоинствами их должны стать качественное повышение культуры информационной деятельности и подготовка информационной среды на машинных носителях, что обеспечит в будущем переход к реализации разнообразных задач. Существенным этапом должна стать интеграция информации одиночных АРМ на базе локальных сетей, которая позволит рассматривать совокупность АРМ как некоторую систему информационного обслуживания (СИО) учреждения. Термин СИО нельзя считать устоявшимся, поскольку он во многом совпадает с некоторым вариантом термина АСУ, которая реализована на программно-технической базе локальных учрежденческих сетей ПЭВМ. Однако если предполагать, что СИО является не результатом какого-то одного исходного проекта, а эволюционной интеграцией АРМ, то имеется существенное отличие СИО от традиционных АСУ в методах проектирования, сопровождения и развития. Эти различия в первую очередь касаются того, что функциональная и обеспечивающие части проекта (программно-техническое, информационное, методическое и другие) для АСУ носят единый неразрывный характер и создаются как взаимосвязанные компоненты. В СИО допускается иная идеология с большей степенью независимости как обеспечивающих компонентов, так и функциональных систем. Эволюционный путь создания систем автоматизации информационной технологии от разработки и внедрения одиночных АРМ до СИО учреждений и последующих их сопряжений порождает новый круг проблем. Одна из них — организация баз данных на ПЭВМ. Понятие персональной базы данных (ПБД) вытекает из названия рассматриваемого типа ЭВМ и соответствует отношению пользователя к используемой и хранимой в ПЭВМ информации. ПРОГРАММНЫЕ СРЕДСТВА ДЛЯ ПБД Персональную базу данных пользователя ПЭВМ образует совокупность файлов, которые, как правило, содержат текстовую, табличную и графическую информацию. Можно рассматривать следующие уровни организации персональной базы: • операционной системы и независимых пакетов обработки соответствующих типов файлов (текстовые и графические редакторы, табличные процессоры и др. ); • СУБД; • интегрированной программной среды. На практике первый уровень остается доминирующим средством организации совокупной информации, перспективными являются среды, интегрирующие информацию. Следует отметить, что имеющиеся пакеты программ по своим функциям «размывают» границы между указанными уровнями. Так, в рамках операционной системы MS DOS фирмой Microsoft интенсивно развивается интегрирующая среда Microsoft Windows. Уровень СУБД включает как СУБД общего назначения, так и простые системы управления файлами (File Manager), причем развитая система типов данных некоторых СУБД (dBASE III Plus) приближает их к интегрированным пакетам. Интегрированная программная среда представлена по крайней мере тремя слоями: простая интеграция (modular programs), интегрированные пакеты (all-in-one programs) и развивающаяся объектно-ориентированная среда (прототип — Small-talk V). Для нас основной интерес представляют системы класса СУБД и интегрированных пакетов (их характеристики приведены в DATAPRO REPORTS ON MICROCOMPUTERS VOL.2.JULY 1987). В СУБД используются реляционная модель данных и интерактивные меню-ориентированные режимы работы. Развитые системы имеют входной язык разработки приложений с алгоритмической полнотой. Имеется тенденция расширения обычного набора типов данных (символьные строки, числа и логические значения) другими типами (дата, время, тексты, графические образы и др.). Ведущими изделиями данного класса являются dBASE III Plus, dBASE III R: base System v и Paradox. Интегрированные пакеты позволяют работать с текстовыми и табличными данными, отношениями реляционных СУБД, деловой графикой, отражающей в виде диаграмм различного типа одно-, двух- и трехмерные числовые ряды, содержащиеся в таблицах и (или) отношениях. Сущность интеграции данных в этих пакетах заключается в возможности перемещения прямоугольных фрагментов данных одного типа в другой, например из таблицы в текст и т. д. Новейшим изделием данного класса можно считать Framework-II. Персональная направленность отражается как набором структур данных, так и интерфейсом пользователя, организованным в виде множества средств, зависящих от уровня подготовки пользователя: от простейших меню до сложных языков программирования, ориентированных на профессионалов-программистов. Для всех систем характерно наличие контекстной подсказки и автоматизированных курсов обучения. Невозможность прямого использования этих пакетов определяет стратегии реализации программной поддержки ПБД для отечественных ПЭВМ, обеспечивающей русскоязычный интерфейс конечного пользователя. Ведутся отечественные разработки данного класса (интегрированные пакеты: МАСТЕР, разработчик ВЦ АН СССР, ИНФОРМОНТАЖ, разработчик НПО «Ленгорсистемотехника» и др.). Основным экспертом качества программных изделий является массовый рынок конечных пользователей, важно поэтому ускорить процесс внедрения соответствующего программного обеспечения в практику автоматизации учрежденческих работ. В связи с этим заслуживает внимания вопрос использования некоторых зарубежных СУБД, например системы dBASE III Plus. СТРУКТУРА И ИНФОРМАЦИОННЫЕ ИНТЕРФЕЙСЫ ПБД Программно-техническая среда ПБД ПБД как систему обработки данных можно рассматривать в виде некоторой структуры, нижние уровни которой представляют аппаратно реализованные универсальные алгоритмические системы, а последующие уровни, реализуемые программно, обеспечивают требуемые приложения. Каждый уровень определяется некоторым формальным входным языком, при этом соответствующая этому уровню система обработки данных является виртуальной машиной, определяемой своим входным языком. Следует отметить, что СУБД, предназначенные для создания и манипулирования небольшими по объему ПБД, в языковом смысле объединяют языки описания данных (ЯОД) и языки манипулирования данными (ЯМД). На рис. 1 показаны уровни виртуализации представления информации для СУБД на ПЭВМ. Процессору dBASE III Plus доступны непосредственно два нижних уровня представления информации (под непосредственным доступом понимается наличие элементарных операторов входного языка, манипулирующих с соответствующими объектами). Первый — базовый уровень, представляющий объекты базовых типов, поддерживаемые реальными данными в структурах хранения во внешней памяти. На этом уровне определяются все основные понятия реляционной модели: отношение, кортеж, атрибут, типы данных и др. Для СУБД dBASE III Plus базовый уровень хранения данных определяется .dbf, .dbt и .ndx (.ntx для Slipper) файлами. Второй — уровень структурной визуализации, объекты которого создаются при помощи операций языка разработки приложений (входящих в систему команд процессора СУБД), определенных над базовыми объектами. Такими операциями для реляционных структур могут быть: горизонтальная и вертикальная фильтрация, связи (по ключу) между отношениями. Таким образом, второй уровень порождает некоторые виртуальные объекты — виртуальные отношения и др., воспринимаемые процессором СУБД как результат выполнения определенных операций над реальными объектами базового уровня. Для СУБД dBASE III Plus данный уровень обеспечивается .qry и .vue файлами. Дальнейшая виртуализация— порождение объектов нового логического уровня и определение набора операций над ними — может быть реализована в виде некоторой программной «надстройки», т. е. программы на языке разработки приложений, создающей новый уровень виртуализации с присущими ему объектами, операциями и внешним интерфейсом. Порождаемые уровни представления информации могут быть названы уровнями программной виртуализации, которая обеспечивается .prg файлами. Программная виртуализация может быть использована для решения следующих задач: • русификация интерфейса (реализация русскоязычных имен отношений и атрибутов, а также введение русских имен для реализуемых операций); • виртуализация атрибутов (построение виртуальных атрибутов как некоторых выражений над реальными атрибутами); • введение составных типов данных в качестве атрибутов; • преобразование значений во внешние представления и наоборот (при использовании кодированных значений атрибутов и соответствующих классификаторов); • контроль ввода и управление выводом; • введение новых операций над виртуальными атрибутами. Вышеприведенная многоуровневая логическая модель СУБД может быть эффективно использована и при расширении базового уровня дополнительными, в частности, графическими возможностями. На каждом из описанных уровней могут быть зафиксированы соответствующие объекты и определены операции над ними.
ПРЕДСТАВЛЕНИЕ ПРЕДМЕТНОЙ ОБЛАСТИ В ПБД Отличие СУБД для ПЭВМ от СУБД общего назначения касается не только программно-реализованного аспекта ПБД, но и других вопросов, включая проектирование и сопровождение. ПБД создается в интересах конкретного пользователя и эксплуатируется им, в связи с чем он выполняет функции администратора БД. Информация, погружаемая в БД, отражает уже существующую на других носителях и используемую информационную базу, которая имеет для пользователя некоторый личностный аспект. Переход к машинным носителям не безболезнен как по причине меньшей надежности хранения информации, так и в связи с иными процедурами доступа, визуализации и т. п. Явная или интуитивная классификация существующих информационных объектов и процедур информационной технологии при «ручной» обработке данных не может быть быстро перенесена пользователем в АРМ. а предлагаемая соответствующими программными средствами технология требует весьма длительной адаптации пользователя. Рассмотрим некоторые классификационные вопросы ПБД, связанные с проектированием и модификацией ее структуры, что влияет на реализацию интерфейса конечного пользователя и определяет различные стороны технологии эксплуатации. Структура ПБД — это модель данных, которая в свою очередь является моделью окружающего мира. В качестве модели данных уровня СУБД будет использоваться реляционная модель, основанная на математическом понятии отношения. Отношение представляет множество упорядоченных кортежей: , где dl, d2, ... dn — элементы некоторых множеств значений Dl, D2 ... Dn, называемых доменами и идентифицируемых некоторыми именами — атрибутами отношения. Величина n называется степенью отношения. Отношение может быть именованным или выразимым. Именованное отношение идентифицируется некоторым именем, а выразимое является результатом некоторых операций над именованными отношениями. Между отношениями могут быть установлены эффективные связи, если атрибуты отношений определены на одинаковых доменах. При подобных связях поиск в одном отношении может сопровождаться автоматической установкой в другом отношении на кортеж с равным значением атрибута связи. При соблюдении требований целостности (ограничении на ключи и связи) совокупность именованных отношений образует базу данных. Указанный алгебраический уровень модели данных удобно дополнить семантическим уровнем моделирования, на котором принимается несколько форм абстракции. Для реляционной модели данных приемлемой формой абстракции является классификация, по которой именованное отношение представляет некоторый класс объектов, а кортеж отношения является экземпляром этого класса. Отсюда следует, что проектирование персональной базы данных начинается с поиска и выделения классов однородных объектов предметной области. Набор характеристик, общих для всех экземпляров класса, является набором атрибутов соответствующего отношения. Рассмотрим ряд типовых ситуаций, возникающих при создании ПБД. Будем считать, что после выделения класса объектов предметной области, т. е. задания именованного отношения, определяется степень отношения (количество независимых характеристик объектов) и тип значений характеристик. В качестве базовых типов, поддерживаемых dBASE III Plus, используются логические, числовые и символьные данные, данные типа «дата» и особо организованный текст. При организации хранения информации в ПБД для выбранных отношений возникают вопросы упорядочивания, архивации данных и сохранения копий. Если в ПБД достаточно отражать только текущее состояние характеристик простых объектов, то отношение реализуется одним .dbf файлом. Упорядочение может достигаться средствами сортировки или индексирования. Архивация может быть частичной и полной. В случае полной архивации сохраняется требуемое число поколений данных всего отношения, что порождает дополнительные .dbf файлы аналогичной структуры. При частичной архивации сохраняются поколения данных для некоторых атрибутов. Архивные отношения могут также включать накапливаемые данные. При описании характеристик объектов (атрибутов) для ПБД возникают вопросы именования, доступа и области значений. Имя атрибута должно соответствовать употребляемым в естественной речи терминам для его обозначения с учетом грамматических особенностей употребления в операциях и в то же время быть достаточно лаконичным. Атрибут может быть ключевым для организации поиска информации, доступным или для корректировки значения, или только для визуализации. Он может быть и недоступным (при выполнении служебных функций). Для области значений атрибута могут возникать вопросы введения дополнительных ограничений на область значений, предоставляемую описанием типа. Важным частным случаем является использование внутренних классификаторов, которые могут быть представлены как в форме фиксированного в программах поддержки ПБД перечисления, так и в форме отдельного отношения — классификатора (с ним для основного отношения устанавливается связь, например в виде .vue файла). Особо следует отметить накапливающие атрибуты, для которых предусматривается операция начальной установки. Рассмотренный круг вопросов позволяет ввести ряд терминов, уточняющих понятие ПБД. Назовем фреймом схему данных, определяемую совокупностью атрибутов некоторого виртуального отношения, поддерживаемого структурными и программными средствами виртуализации dBASE III Plus, а описание соответствия между фреймом и виртуальными структурами СУБД — метафреймом. Тогда совокупность фреймов и метафреймов будет представлять собой ПБД. ИНФОРМАЦИОННЫЕ ИНТЕРФЕЙСЫ ПБД Для ПБД можно выделить три обобщенных категории операций: создание (модификация, удаление) фреймов, сопровождение информации в ПБД (ввод, корректировка, удаление) и запрос. Дополнительно можно специфицировать другие операции применительно к конкретной ПБД, связанные с произвольной обработай, передачей и преобразованием информации. Поскольку осуществляется взаимодействие ПБД и пользователя, а также этой ПБД с другими ПБД, то требуется рассмотреть внешние (ПБД—пользователь и ПБД—ПБД) и внутренние интерфейсы виртуальной СУБД. Понятие внешнего интерфейса ПБД требует также введения соответствующих моделей обмена ввода-вывода) информации. Основными средствами ввода информации, обеспечиваемыми базовыми возможностями СУБД dBASE III Plus, являются клавиатура, файлы и средства телекоммуникации. Вывод обеспечивается на экран монитора, устройства печати, в файлы и телекоммуникационные каналы. Для фиксации информации конечного пользователя в удобном для него виде предусмотрены структуры хранения — формируемые пользователем специальные файлы (.frm, .scr, .fmt файлов), называемые экранными формами и формами вывода отчетов (рис. 2).
Однако при создании и сопровождении ПБД с русскоязычным внешним интерфейсом на основе dBASE III Plus трудно воспользоваться возможностями структурной виртуализации, поскольку файлы типа .qry, .vue, а также структуры формирования ввода-вывода (.scr, .fmt, .гхт)создаются только в интерактивном режиме с англоязычным интерфейсом. Создание подобных структур в другой программной среде (например в Си) возможно, но имеет ряд существенных трудностей (для совместимости с компилятором Clipper необходимы соответствующие версии Lattice Сит. п.). В данной версии ПБД возможности средств структурной виртуализации моделируются не на уровне файлов (.qry, .vue и т. д.), а на уровне альтернативных возможностей операторов SET с записью соответствующей информации в метафрейм. Эта версия предлагается в двух вариантах: замкнутом — для ведения и использования ПБД в информационно-запросном режиме, и открытом — с возможностью подключения произвольных программ обработки на языке dBASE III Plus Clipper). Рассмотрим общее описание интерфейса замкнутого варианта. Основными понятиями пользовательского уровня являются понятия базовой схемы данных и производной схемы. Базовая схема данных соответствует одному .dbf файлу с возможным заданием одного индекса (.ndx файла). Производная схема создается путем применения четырех групп операций: упорядочивания, фильтрации, вычисления и связывания. Схема характеризуется списком доступных полей и состоит из доступных записей. Исходное меню содержит следующие позиции: СПРАВКА ОПРЕДЕЛЕНИЕ ДОСТУП СОПРОВОЖДЕНИЕ ЗАПРОС ОБ-IEH Позиция СПРАВКА определяет действия для получения справочной информации о структуре и состоянии ПБД. Позиция ОПРЕДЕЛЕНИЕ связана с действиями по созданию и модификации схем данных с возможностью интерактивного просмотра и использования существующих схем. Позиция содержит следующие основные операции. СОЗДАТЬ схему данных <имя схемы> ИЗМЕНИТЬ схему данных <имя схемы> УДАЛИТЬ схему данных <имя схемы> Меню-ориентированный диалог позволяет определить базовую или производную схему. Для базовой схемы диалог включает следующие действия: СТРУКТУРА схемы данных <имя схемы> поле 1 <имя поля> <тип значения> <длина> Характеристика значения> поле 2 <имя поля> <тип значения> <длина> <характеристика значения> . .................................................................................................................................... поле n <имя поля> <тип значения> <длина> <характеристика значения> КЛЮЧЕВЫЕ АТРИБУТЫ ПРОСМОТРА <список имен полей и соответствующих операций сравнения> ОТНОШЕНИЕ ПОРЯДКА <[возрастание / убывание] имя поля> На основании приведенных диалоговых операций формируются (или модифицируются) структуры хранения, поддерживаемые СУБД , а также соответствующая информация в метафрейме. Для производной схемы пользователь выбирает исходные базовые схемы и соответствующие группы операций. УПОРЯДОЧЕНИЕ < [возрастание / убывание] индексное выражение > (построение дополнительных индексных файлов) ФИЛЬТРАЦИЯ ЗАПИСЕЙ <логическое выражение> (задание горизонтального фильтра) ФИЛЬТРАЦИЯ ПОЛЕЙ <список имен> (задание вертикального фильтра) ВЫЧИСЛЕНИЕ поле 1 <имя поля> <тип значения > <длина> <выражение> поле 2 <имя поля> <тип значения > <длина> <выражение> . ................................................................................................................................................... поле n <имя поля> <тип значения > <длина> <выражение> (формирование новых виртуальных атрибутов на основе вычисления выражений над существующими атрибутами) СВЯЗЬ <имя поля> : <имя схемы> -> <имя схемы> (формирование связи схем по ключевому атрибуту) Позиция ДОСТУП основного меню определяет действия, связанные с открытием (размещением) созданных схем данных в одной или нескольких рабочих зонах. Позиция СОПРОВОЖДЕНИЕ основного меню определяет следующие диалоговые действия только с базовыми схемами: ВВОД Пользователь может добавлять одну или несколько новых записей с заполнением полей значениями по заданной экранной форме. ПРОСМОТР Пользователю предлагается группа следующих операций: ИСКЛЮЧИТЬ, КОРРЕКТИРОВАТЬ, СЛЕДУЮЩАЯ, ПРЕДЫДУЩАЯ (с возможностью интерактивного задания дополнительного горизонтального фильтра просмотра по заданным при определении схемы ключевым полям). УСТАНОВКА Возможны перемещения указателей текущей записи схемы в начало, конец или на требуемую запись. Позиция ЗАПРОС основного меню соответствует основному информационно-запросному режиму работы конечного пользователя и включает три группы диалоговых операций. НЕФОРМАТНЫЙ ВЫВОД Для текущей схемы задается список выводимых в свободном формате полей и условие вывода в виде допустимого логического выражения. По смыслу они являются дополнительными вертикальными и горизонтальными фильтрами схемы, но действуют только на время вывода. ВЫВОД ФОРМЫ Для текущей схемы по заданной форме (.frm файл) задается временный горизонтальный фильтр вывода аналогично предыдущему режиму. РАСЧЕТНЫЕ ДАННЫЕ Может быть задан временный горизонтальный фильтр, после чего можно получить количество записей, сумму значений или среднее значение для числовых полей. Для всех операций вывода дополнительно указывается возможность печати результата. Позиция ОБМЕН главного меню позволяет определять экранные формы и формат вывода отчетных форм, а также изменять режим печати (шрифты, межстрочные расстояния и др.) для устройств печати матричного типа. Реализация русскоязычного интерфейса конечного пользователя позволяет использовать в рассмотренных действиях (или их фрагментах) термины своей предметной области, что обеспечивает основные требования к «дружественности» интерфейса. Информация о подобных соответствиях также сохраняется в структурах метафрейма и используется программами виртуализации. Интерфейс ПБД-ПБД в общем случае связан с выполнением на передающей стороне операции ВЫВОД ..., а на приемной стороне — ДОБАВИТЬ. Внутренние интерфейсы ПБД определяются принятыми структурами виртуализации СУБД и соответствующими отображениями понятий верхних и нижних уровней СУБД, содержащимися в метафрейме. Рассмотренные концептуальные аспекты, касающиеся ПБД, используются в теоретических и экспериментальных разработках НПО «Горсистемотехника» (г. Киев) по проблематике автоматизации учрежденческих работ. |

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1361 |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 1989 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Использование графических постпроцессоров VVG и LEONARDO в вычислительной гидродинамике
- Методы восстановления пропусков в массивах данных
- Проблемы визуализации и отображения информации
- Исследовательское проектирование в кораблестроении на основе гибридных экспертных систем
- Автоматизированная система принятия решений при стратегическом планировании устойчивого развития региона в условиях нечеткой информации
Назад, к списку статей