Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Инструментарий для построения автоматизированных учетных систем с WEB-интерфейсом
Аннотация:
Abstract:
| Автор: Егорычев И.Б. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 12059 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
Автоматизация учета на предприятии предполагает замену алгоритмизируемых операций, выполняемых человеком, на человеко-машинные, где человеку отводится роль оператора, использующего компьютерный инструментарий. Данные преобразования повышают эффективность работы как отдельных исполнителей, так и предприятия в целом. Это достигается путем использования особых механизмов организации и управления информацией, что повышает ее достоверность, полноту и оперативность представления. Цель автоматизации в области управленческого учета – представление адекватной картины бизнеса и основы для принятия управленческих решений. На практике суть преобразований сводится к построению некой программной системы, обеспечивающей надежное хранение, быструю и точную обработку и удобное представление полной учетной информации. Существует ряд готовых решений для автоматизации типовых задач определенных областей учета или же учета в целом. У полнофункциональных пакетов свои преимущества: их поэтапное внедрение позволяет не только автоматизировать большинство бизнес-процессов, но и естественным образом решать проблемы интеграции подсистем, унификации пользовательского интерфейса и т.д. [1]. Однако внедрение подобной системы является достаточно рискованным процессом по ряду причин, главные из которых – необходимость настройки программы на решение специфических задач конкретного предприятия и необходимость проведения организационных преобразований для адаптации самого учета к системе. Кроме того, если для автоматизации бухгалтерского учета подойдет готовое решение (например, система «1С:Предприятие»), требующее минимальной доработки, то в такой слабо формализованной области, как управленческий учет, возможно, более эффективным решением будет создание уникальной программной системы, максимально удовлетворяющей потребности конкретного предприятия. Чаще всего такое решение будет еще и менее громоздким. Однако при отсутствии удобного инструментария построение подобной системы может потребовать значительных затрат времени. Цель данной разработки – создание инструментальных программных средств для построения автоматизированных учетных систем. Выбор архитектуры Автоматизированные учетные системы предприятия, как правило, являются многопользовательскими. Их архитектура позволяет различным пользователям со своих рабочих компьютеров одновременно получать доступ к информации, хранящейся в системе. Такие системы построены по технологии «клиент–сервер». При проектировании клиент-серверных приложений необходимо определить, какие задачи будут выполняться на клиентском рабочем месте, а какие на сервере. Это решение влияет на стоимость клиентских и серверных частей системы, устойчивость и безопасность приложения в целом, гибкость разработки для дальнейшей модификации и адаптации. Еще один вопрос проектирования – специфичность программного обеспечения (ПО) клиента. Использование на клиентском рабочем месте стандартизованного ПО, такого как web-браузер, может существенно снизить стоимость разработки. Однако в этом случае придется мириться с накладываемыми им ограничениями. В зависимости от принятых по данным вопросам решений можно говорить о построении клиент-серверной системы с использованием так называемых тонких или толстых клиентов. Тонким клиентом принято называть компьютер-клиент сети с клиент-серверной архитектурой, который переносит большинство задач по обработке информации на сервер. Для его нормальной работы всегда необходим сервер. Этим тонкий клиент отличается от толстого, который, напротив, производит основную обработку информации независимо от сервера, используя последний преимущественно для хранения данных. Толстый клиент периодически соединяется с центральным сервером по сети, но в то же время способен выполнять многие функции локально, без соединения с ним. Преимущества толстых клиентов. · Не требуется высокопроизводительный сервер, так как клиент сам выполняет большую часть обработки данных. Это приводит к значительному удешевлению серверов. · Работа в автономном режиме. Как правило, таким клиентам не требуется постоянное соединение с центральным сервером. · Большая гибкость. Некоторые программные продукты проектируются для компьютеров, имеющих свои локальные ресурсы. Запуск подобной программы на тонком клиенте может быть затруднителен или невозможен. Преимущества тонких клиентов [2]. · Меньшие затраты на администрирование. ПО тонкого клиента практически полностью управляется с сервера. Кроме того, аппаратные средства имеют меньше возможностей для отказа из-за своей простоты, а ПО меняется крайне редко, что позволяет обеспечить защиту от вредоносных программ. · Легкость в обеспечении защиты информации. ПО тонкого клиента может быть спроектировано так, чтобы на клиенте не хранились данные. Тем самым обеспечивается централизованная защита от утечки информации и минимизируются риски физического повреждения данных. · Обеспечение непрерывности работы в случае аппаратных сбоев. При поломке оборудования тонкого клиента на время ремонта пользователю может быть быстро предоставлена полноценная замена, потому что все данные хранятся на сервере. В нашем случае для решения задач автоматизации учета построение распределенной системы с ресурсоемким клиентским ПО не является существенно необходимым. Гораздо более актуально снижение затрат на администрирование, обеспечение защиты информации, целостности данных и непрерывности работы. Поэтому было принято решение ориентироваться на клиент-серверную архитектуру с тонким клиентом. Топология системы При проектировании клиент-серверных приложений для ускорения разработки имеет смысл воспользоваться шаблонами проектирования, предоставляющими эффективные способы решения типовых задач создания компьютерных программ. Шаблон не является законченным образцом проекта, который может быть прямо преобразован в код, скорее, это описание или образец того, как решить задачу. Главное достоинство каждого шаблона состоит в том, что он описывает решение целого класса абстрактных проблем. За счет шаблонов производится унификация терминологии, названий модулей и элементов проекта. Правильно сформулированный шаблон проектирования позволяет, отыскав удачное решение, пользоваться им снова и снова. Model View Controller (MVC, модель вид контроллер) является одним из шаблонов архитектуры ПО. В сложных компьютерных приложениях, которые должны предоставлять пользователю большой объем данных, разработчик часто стремится разделить обработку данных и разработку пользовательского интерфейса так, чтобы изменения интерфейса не влияли на управление данными и данные могли быть реорганизованы без изменения интерфейса. Схема MVC решает эту проблему, отделяя доступ к данным и бизнес-логику от отображения данных и действий пользователя при помощи промежуточного компонента контроллера. Таким образом, модель данных приложения, пользовательский интерфейс и управляющая логика разделены на три отдельных компонента так, что модификация одного из компонентов оказывает минимальное воздействие на другие компоненты. Модель обеспечивает хранение и представление информации, с которой работает приложение. Способ организации информации определяется особенностями предметной области. Многие приложения используют постоянный механизм хранения данных (такой, как БД). Однако в самом шаблоне MVC не определяется способ доступа к данным, поскольку подразумевается, что он определяется в модели. Вид, как правило, представляет собой интерфейс пользователя. Он выполняет функции представления данных модели в виде, удобном для обработки. Для одной модели может одновременно существовать несколько видов. Контроллер обрабатывает данные, отвечает на события, как правило, пользовательские действия, и может вносить изменения в модель. Хотя MVC реализуется по-разному, обработка данных обычно происходит следующим образом. 1. Пользователь производит некоторое действие в интерфейсе системы (например, нажимает кнопку или изменяет значение поля в форме). 2. Контроллер обрабатывает событие, полученное от пользовательского интерфейса, часто посредством вызова определенного обработчика. 3. Контроллер обращается к модели, обновляя данные в соответствии с действиями пользователя. 4. Вид обновляет пользовательский интерфейс. Данные для этого вид получает из модели посредством контроллера. 5. Пользовательский интерфейс ожидает дальнейших действий пользователя, которые запустят цикл снова. Важно отметить, что вид и контроллер зависят от модели. Однако модель не зависит ни от вида, ни от контроллера. Это одно из ключевых достоинств подобного разделения. Оно позволяет строить модель независимо от визуального представления. Разделение моделей и видов в MVC способствует упрощению проектирования архитектуры системы и повышению гибкости. Данная схема широко используется при построении web-приложений. Реализация хранилища данных Для хранения информации уже давно и успешно применяется реляционная модель данных. Реляционная СУБД MySQL является решением для малых и средних приложений. Обычно она используется в качестве сервера БД, к которому обращаются локальные или удаленные клиенты. СУБД MySQL хорошо зарекомендовала себя в составе серверного ПО при разработке web-приложений. Гибкость СУБД MySQL обеспечивается поддержкой большого количества типов таблиц: пользователи могут выбрать как таблицы типа MyISAM, поддерживающие полнотекстовый поиск, так и таблицы типа InnoDB, поддерживающие транзакции на уровне отдельных записей. Благодаря открытой архитектуре и использованию лицензии GPL, в СУБД MySQL постоянно появляются новые типы таблиц. С выходом пятой версии в этой СУБД значительно улучшилась поддержка стандарта SQL благодаря следующим нововведениям [3]: хранимые процедуры и функции, обработчики ошибок, курсоры, триггеры, представления, информационная схема (так называемый системный словарь, содержащий метаданые). Этих функциональных возможностей оказалось достаточно для использования MySQL в качестве СУБД в составе проектируемого инструментария. Технология ORM Использование реляционной модели для хранения информации об объектах реального мира часто обязывает приложение уметь обрабатывать данные в объектно-ориентированном виде, но при этом хранить их в реляционной форме. Эта постоянная необходимость в преобразовании между двумя разными формами информации существенно снижает производительность и создает трудности для программистов, поскольку обе формы данных накладывают ограничения друг на друга.
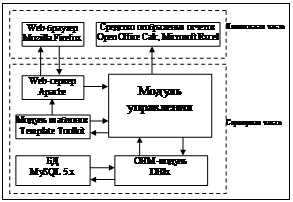
С применением ORM система с точки зрения программиста выглядит как постоянное хранилище объектов, позволяя создавать объекты и работать с ними, автоматически сохраняя их в реляционной БД. На практике возникают сложности следующего характера: слой транзакций, реализованный в ORM, может быть медленным и неэффективным. В результате программы работают медленнее и используют больше памяти, чем программы, написанные непосредственно на SQL. Однако ORM избавляет программиста от написания большого количества кодов, тем самым значительно повышая его производительность. Кроме того, большинство современных реализаций ORM позволяют программисту при необходимости самому жестко задать код SQL-запросов, который будет использоваться при тех или иных действиях (сохранение в БД, загрузка, поиск) с постоянным объектом. Структура системы Существует ряд некоммерческих продуктов с открытым программным кодом, которые можно использовать в качестве каркаса для построения web-приложений. Их использование позволяет программисту не заниматься низкоуровневым программированием. Применение таких средств делает код более простым и ясным, что способствует уменьшению количества ошибок в программе и сокращает время на разработку. После изучения и сравнения таких средств создания web-приложений было решено использовать ряд компонентов свободного кроссплатформенного программного каркаса Catalyst [4], реализующего архитектуру MVC. Он построен на языке Perl, который широко используется при разработке web-приложений благодаря своей гибкости и универсальности. В качестве транслятора реляционной БД в объектную модель могут использоваться различные модули, среди которых был выбран компонент DBIx как наиболее мощный. В качестве средства представления данных используются модули шаблонов для генерации HTML-страницы, один из которых – Template Toolkit – был выбран для использования в нашей системе. Модули Catalyst реализуют простейшие действия отображения таблиц БД в виде HTML-страниц и простейшие средства изменения данных в соответствии с действиями пользователя. Отметим, что Catalyst не является готовой прикладной системой и не содержит достаточных средств для того, чтобы создать удобное приложение, описав лишь бизнес-логику. Это средство для программиста, применение которого для реализации типовых функций web-приложения в соответствии с архитектурой MVC позволяет сократить время разработки системы и направить усилия на реализацию специфических возможностей, что и было сделано. Результатом работы стала система, структура которой приведена на рисунке. В качестве основного web-браузера было решено использовать Mozilla Firefox из-за его кроссплатформенности и приемлемой стабильности при работе с Java script. Логика инструментария сосредоточена в модуле управления. Она включает в себя гибкие средства построения пользовательского интерфейса, отражающего структуру данных, возможность реализации бизнес-логики средствами инструментария без изменения базовых механизмов работы системы, механизмы генерации отчетов и контроля доступа к данным. Логика приложения может быть распределена между контроллером, моделью и видом различными способами. Если требуется обеспечить наибольшую гибкость и универсальность, есть смысл придерживаться подхода, при котором бизнес-логика и семантика прикладной системы помещены в БД. Такой подход (Database-centric architecture) широко применяется при разработке web-приложений с использованием динамических языков программирования. Его преимущества [5]: 1) система требует заметно меньшего взаимодействия между БД и сервером приложения, что уменьшает загрузку на сервер и время отклика приложения; 2) операции внутри БД выполняются более эффективно, когда логика приложения описана в триггерах и хранимых процедурах; 3) уменьшается количество кода, и он становится более эффективным из-за того, что программисту БД доступно много дополнительных возможностей по обработке данных; ORM-средства не могут реализовать все эти возможности. Для реализации подобной архитектуры требуется описать в БД семантику и логику прикладной программы. В созданном инструментарии содержатся средства семантической разметки структуры БД и средства вызова хранимых процедур БД из пользовательского интерфейса. Следует отметить, что при такой архитектуре системы модуль ORM не используется для программирования логики прикладной программы. Он используется для реализации таких стандартных действий с данными, как создание, запись, чтение, удаление и отображение связей. Семантическая разметка структуры БД DBIx-реализация ORM имеет возможность анализировать БД при ее подключении. При этом автоматически определяются состав и атрибуты полей таблиц, а также установленные связи между таблицами. Это дает возможность создания приложения, автоматически настраивающегося согласно декларированной структуре БД. Всю необходимую дополнительную информацию, описывающую семантику объектов и их связей, в том числе права доступа к данным, можно хранить либо в полях комментариев, либо в служебных таблицах БД. При помощи этого механизма реализовано управление следующими возможностями: режим отображения таблицы (список, поиск значений, последние записи), видимость колонки, режим редактирования колонки, сортировка записей, расчет итогов по числовым колонкам, режим отображения связей между таблицами, ограничение выбора возможных значений поля. Средства вызова хранимых процедур БД из модуля управления Логику приложения в БД можно реализовать при помощи триггеров и хранимых процедур. Преимущество триггеров в том, что их вызов привязан к действию с данными, поэтому не требуется создание дополнительного механизма их вызова. Однако функциональность триггеров в MySQL ограничена, в частности, в триггерах запрещена рекурсия, что может стать серьезной проблемой при разработке эффективного прикладного решения. Поэтому был создан механизм вызова хранимых процедур БД. При операции с данными проверяется наличие в БД соответствующих процедур и вызывается их выполнение. Это позволило реализовать анализ и обработку вводимых данных, поддержание логической целостности информации и другие необходимые функции. Механизм генерации отчетов Задачи учета предполагают построение разнообразных аналитических отчетов, содержащих некую выборку данных, представленную в нужном формате. Поэтому был разработан соответствующий механизм. Для создания отчета разработчику прикладного решения нужно создать шаблон отчета, описать алгоритм заполнения шаблона и выборки данных. В качестве средства отображения отчета можно использовать редактор Microsoft Excel или Open Office Calc. Шаблон отчета создается в формате Open Office Calc и содержит, помимо заголовков, разметки и других объектов, идентификаторы переменных, значения которых подставляются при генерации отчета. Разработчик на языке SQL описывает выборку данных и команды интерпретатору, который производит заполнение шаблона и создание файла отчета. Заполнение шаблона значениями выборки осуществляется посредством механизма работы с буферами. В буфер копируется строка шаблона, в которой затем производится подстановка переменных. Содержимое буфера после этого помещается в нужное место шаблона. Кроме того, буфер может содержать группу строк одного формата, что необходимо для вывода содержимого таблиц. Для генерации отчетов первоначально планировалось использовать встроенные средства Open Office, но тестирование такой возможности показало нестабильность работы данного механизма. В заключение отметим, что итогом работы стали средства для создания клиент-серверных учетных систем с web-интерфейсом. Был использован подход, при котором данные, пользовательский интерфейс и управляющая логика разделены на отдельные компоненты. При этом логику, описывающую прикладное решение, предлагается помещать в БД. Использование такого подхода обеспечивает достаточную гибкость и универсальность инструмента. Благодаря применению в качестве клиентского ПО web-браузера и переноса обработки информации на сервер достигается необходимый уровень надежности, защиты информации и простоты обслуживания системы. Инструментарий позволяет строить приложения, выполняющие необходимые операции с данными, как базовые (ввод, чтение, редактирование, удаление), так и сложные (отображение согласно семантике, построение отчетов). Разработанный инструмент был успешно опробован при создании программных систем для учета договоров и затрат на предприятии. Список литературы 1. iOne.ru. Комплекс полноценности. (http://iteam.ru/publications/it/section_54/article_2726). 2. Грязнов Е. Тонкий клиент. // Мир ПК. – 2005. – № 2. 3. MySQL :: The world's most popular open source database. (http://mysql.com). 4. Catalyst – web framework. (http://www.catalystframework.org). 5. Paul Dorsey. Fusion Development: A Database-Centric Approach (http://www.dulcian.com/papers/ODTUG/2007/2007_ ODTUG_Fusion-Development.htm). |
 Реляционные БД используют набор таблиц, представляющих данные простых типов. Дополнительная или связанная информация хранится в других таблицах. Часто для хранения одного объекта в реляционной БД используется несколько таблиц, что требует применения сложных запросов для получения всей относящейся к объекту информации и ее обработки. В результате увеличивается сложность программного кода, в нем легче допустить ошибку. Одним из решений данной проблемы является ORM (Object-relational mapping) – технология программирования, связывающая БД с концепциями объектно-ориентированных языков программирования, создавая виртуальную объектную БД.
Реляционные БД используют набор таблиц, представляющих данные простых типов. Дополнительная или связанная информация хранится в других таблицах. Часто для хранения одного объекта в реляционной БД используется несколько таблиц, что требует применения сложных запросов для получения всей относящейся к объекту информации и ее обработки. В результате увеличивается сложность программного кода, в нем легче допустить ошибку. Одним из решений данной проблемы является ORM (Object-relational mapping) – технология программирования, связывающая БД с концепциями объектно-ориентированных языков программирования, создавая виртуальную объектную БД.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1612 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
| Статья опубликована в выпуске журнала № 4 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Интеллектуальные хранилища данных в системах государственного управления
- Механизм контроля качества программного обеспечения оптико-электронных систем контроля
- Интеграция инструментальных средств создания программного обеспечения
- Создание Web-приложений в MIDAS-технологии
- Сравнительный анализ некоторых алгоритмов распознавания
Назад, к списку статей