Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
Аннотация:
Abstract:
| Автор: Островский А.А. () - | |
| Ключевые слова: нечеткие множества, классификация, кластеризация, fcm-метод |
|
| Keywords: fuzzy sets, classification, clusterization, |
|
| Количество просмотров: 14918 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
Огромные объемы информации зачастую приводят к тому, что количество объектов, выдаваемых по запросу пользователя, очень велико. Это затрудняет обзор результатов и выбор наиболее подходящих материалов из множества найденных. Однако в большинстве случаев огромные объемы информации можно сделать доступными для восприятия, если разбивать источники информации (например электронные документы) на тематические группы. Тогда пользователь сразу может отбрасывать множество документов из малорелевантных групп. Так, группировка данных (в нашем случае текстовых) осуществляется с помощью кластеризации набора документов. В данной статье описан один из таких алгоритмов – Fuzzy Classifier Means (FCM). Это метод кластеризации набора объектов на 2 или более кластеров, разработанный J.C. Dunn в 1973 г. FCM-метод Цель алгоритма кластеризации FCM – автоматическая классификация множества объектов, которые задаются векторами признаков в пространстве признаков. Иначе, такой алгоритм определяет кластеры и классифицирует объекты. Кластеры представляются нечеткими множествами, границы между кластерами также являются нечеткими. FCM-алгоритм предполагает, что объекты принадлежат всем кластерам с определенной функцией принадлежности. Степень принадлежности определяется расстоянием от объекта до соответствующих кластерных центров. Данный алгоритм итерационно вычисляет центры кластеров и новые степени принадлежности объектов. Алгоритм основан на минимизации целевой функции: Адаптация FCM-метода для кластеризации документов интеллектуального проектного репозитария Объектами кластеризации в интеллектуальном проектном репозитарии являются электронные текстовые документы. Задача FCM-алгоритма – разбиение этого набора на заданное количество кластеров. Для каждого документа составляется частотный портрет входящих в него значимых терминов. Эти частотные портреты и являются векторами признаков объектов кластеризации. Алгоритм нечеткой кластеризации выполняется по шагам. Шаг 1. Инициализация. Задаются параметры кластеризации, и инициализируется первоначальная матрица принадлежности электронных документов кластерам. Выбираются значения следующих параметров: · параметр m – от его выбора зависит значение функции принадлежности документа кластеру. Обычно ~1,5...2. Чем больше значение, тем более нечеткая кластеризация; · мера расстояний · уровень точности ε (параметр сходимости алгоритма): кластеризация завершена, когда разность значений целевых функций текущей и предыдущей итераций достигнет этого уровня; · количество итераций алгоритма – задается во избежание зависания алгоритма при невозможности достижения уровня точности. После выбора параметров случайным образом генерируется первоначальная матрица принадлежности объектов кластерам. Шаг 2. Вычисление центров кластеров. Каждому j-му терму всех документов ставится в соответствие действительное число, вычисляемое следующим образом: Шаг 3. Формирование новой матрицы принадлежности. Формируется новая матрица принадлежности с учетом вычисленных на предыдущем шаге центров кластеров: При этом, если для некоторого кластера j и некоторого объекта i Шаг 4. Вычисление целевой функции. Вычисляется значение целевой функции и сравнивается со значением на предыдущей итерации. Если разность не превышает заданного в параметрах кластеризации значения ε, считаем, что кластеризация завершена. В противном случае переходим ко второму шагу алгоритма. Реализация FCM-метода кластеризации В качестве входных данных кластеризатор использует набор ресурсов с термами и весами этих термов в документе. На выходе должно быть построено дерево кластеров. Кластеризатор реализован на языке Java. После установления соединения с БД пользователь может начать новую кластеризацию документов, выбрав соответствующий пункт меню «Кластеризация». Информация о документах и термах запрашивается из БД MSSQL. После загрузки ресурсов формируется набор уникальных термов из термов загруженных ресурсов, который будет характеризовать центры кластеров. Затем пользователь выбирает параметры кластеризации, на основе которых происходит формирование первоначальной матрицы принадлежности ресурсов кластерам. Метод FCM не является иерархическим. Для иерархической кластеризации требуется участие пользователя. Если одного уровня кластеризации недостаточно, после его завершения пользователь сам выбирает кластеры, которые требуется кластеризовать дальше. Для каждой кластеризации также задаются параметры. Программа позволяет выполнять одновременно несколько процессов кластеризаций на одном уровне иерархии. Для наблюдения за процессом кластеризации, а также для анализа результатов реализован визуализатор кластеризации, который имеет возможности просмотра изменяющегося дерева кластеров, изменения матрицы принадлежности ресурсов кластерам, изменения центров каждого кластера и степеней принадлежности ресурсов, а также изменения текущих параметров процесса. Визуализатор доступен для каждого запущенного потока кластеризации. В заключение отметим, что приложение позволяет сохранять и повторно использовать результаты экспериментов в БД и формировать подробный XML-отчет о проделанных экспериментах, содержащий все необходимые данные для анализа результатов кластеризации. Помимо автоматической кластеризации, приложение позволяет также выполнять автоматизированную кластеризацию и классификацию документов непосредственно пользователем. |
 , где N – количество объектов; С – количество кластеров; uij – степень принадлежности объекта i кластеру j; m – любое действительное число, большее 1;
, где N – количество объектов; С – количество кластеров; uij – степень принадлежности объекта i кластеру j; m – любое действительное число, большее 1; 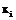 – i-й объект набора объектов;
– i-й объект набора объектов;  – j-й кластер набора кластеров;
– j-й кластер набора кластеров; 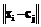 – норма, характеризующая расстояние от центра кластера j до объекта i.
– норма, характеризующая расстояние от центра кластера j до объекта i.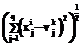 , где q – количество значимых термов набора документов;
, где q – количество значимых термов набора документов;  – количество терма j в i-м документе;
– количество терма j в i-м документе;  – значение, соответствующее терму j в k-м кластере;
– значение, соответствующее терму j в k-м кластере; , где
, где 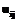 – степень принадлежности документа i кластеру j.
– степень принадлежности документа i кластеру j.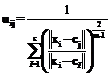 , где
, где  – вектор центра l-го кластера.
– вектор центра l-го кластера.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1614 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
| Статья опубликована в выпуске журнала № 4 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
- Комбинирование классификаторов на основе теории нечетких множеств
- Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
- Разработка теоретических основ классификации и кластеризации нечетких признаков на основе теории категорий
- Применение методов классификации и кластеризации для повышения эффективности работы прецедентных систем
Назад, к списку статей