Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
Аннотация:
Abstract:
| Автор: Корунова Н.В. () - | |
| Ключевые слова: анализ, нейронная сеть, классификация, кластеризация |
|
| Keywords: analysis, neural network, classification, clusterization |
|
| Количество просмотров: 15816 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
Кластерный анализ занимает одно из центральных мест среди методов анализа данных и представляет собой совокупность методов, подходов и процедур, разработанных для решения проблемы формирования однородных классов (кластеров) в произвольной проблемной области. Рассматриваемая проблемная область представляет собой огромный массив документации, содержащий неструктурированные электронные информационные ресурсы (ЭИР), такие как положения, стандарты, инструкции, руководства, спецификации проектов и т.п. При поддержке архива экспертом возникает ряд проблем: экспоненциальный рост количества ЭИР, субъективное разбиение ЭИР на категории, динамичность и дублирование информации. Проблемы позволяет устранить автоматическая кластеризация ЭИР. Задача кластеризации заключается в следующем. Имеются выборка Xℓ={x1,..., xℓ} Алгоритм кластеризации – это функция a:X→Y, которая любому объекту xÎX ставит в соответствие метку кластера yÎY. Решение задачи кластеризации ЭИР проектного репозитария выдвигает ряд требований к алгоритму кластеризации: - отсутствие обучающей выборки; - применимость сильно сгруппированных данных; - автоматическое определение оптимального числа кластеров; - не более чем логлинейный рост времени работы кластеризатора с увеличением количества текстов; - минимальная (в лучшем случае отсутствующая) настройка со стороны пользователя. Задача кластеризации текстов с трудом поддается формализации. Оценка адекватности разбиения ЭИР на кластеры основывается на мнении эксперта и трудновыразима в виде одной численной характеристики. Возникает требование интерпретируемости результата: кластерам должны быть присвоены некоторые метки, отражающие их семантику. Следовательно, процедура кластеризации должна еще обладать свойством интерпретируемости найденных кластеров в терминах смысла содержания относящихся к ним документов. Рассмотрим наиболее распространенные алгоритмы кластеризации. В общем виде методы кластеризации могут быть разбиты на две группы: представляющие тексты в виде векторов в многомерном пространстве признаков (и использующие метрику близости между векторами) и применяющие другие представления анализируемых текстов. Первая группа – это алгоритмы иерархической кластеризации (Single/Complete/Average Link), неиерархические алгоритмы (методы ближайшего соседа – модификация k-means, FCM, нейронные сети SOM, ART), а также большое число других базирующихся на них методов. Примером алгоритмов второй группы является алгоритм Suffix Trie Clustering (STC – древовидные структуры). Неиерархические методы выявляют более высокую устойчивость по отношению к шумам и выбросам, некорректному выбору метрики, включению незначимых переменных в набор, участвующий в кластеризации. Но при этом в большинстве алгоритмов необходимо заранее определить количество кластеров, итераций или правило остановки, а также некоторые другие параметры кластеризации. Иерархические методы строят полное дерево вложенных кластеров. Сложности данных методов кластеризации – ограничение объема набора данных, выбор меры близости, негибкость полученных классификаций. Недостатки метода STC – обязательное наличие первоначального дерева, значительное время работы при больших размерах первоначального дерева. При анализе рассмотренных методов кластеризации выявлено, что максимально соответствует перечисленным требованиям к алгоритму кластеризации метод нейронных сетей SOM (Self-Organizing Map – самоорганизующиеся карты Кохонена). Нейронная сеть, использующая метод обучения без учителя (unsupervised learning) – SOM, не требует наличия обучающей выборки, применима к сильно сгруппированным данным; сама определяет количество получаемых кластеров, дает возможность настроить параметры сети по умолчанию. При этом увеличение количества текстов не влечет за собой экспоненциальный рост времени обработки, и интерпретация найденных кластеров осуществляется осмысленно в ключевых словах. Входным вектором X является результат анализа ЭИР – частотный портрет. Автоматически извлекается индекс в виде вектора основных понятий и их связи с весовыми характеристиками. В качестве смыслового портрета текста рассматривается сеть понятий – множество ключевых слов или словосочетаний. Каждое понятие имеет некоторый вес, отражающий значимость этого понятия в тексте. Для кластеризации ЭИР используются две основные процедуры настройки нейронной сети – инициализация весов нейронов случайным образом и алгоритм SOM: · определение расстояний между входным вектором X и вектором весов W каждого нейрона по формуле: · определение нейрона-победителя с минимальным расстоянием; · определение области активации нейрона-победителя; · определение весов нейронов внутри области активации по формуле: Далее следует запись обработанного ЭИР в получаемый динамический массив кластеров. Таким образом, сеть SOM имеет набор входных элементов (частотные портреты ЭИР) и набор выходных элементов (множество кластеров). Обучение нейронной сети происходит на каждом документе. Модуль кластеризации представляет собой отдельный модуль программы «Интеллектуальный сетевой архив ЭИР», предназначенный для разбивки массива текстовых документов на классы на основе частотных портретов, полученных при проведении процесса индексирования. Программное обеспечение реализовано в среде Borland Delphi Enterprise 7.0. В модуле кластеризации реализован алгоритм нейронной сети Кохонена. Кластеризатор позволяет пользователю: · интерактивно настроить параметры подключения и подключиться к базе данных, а также изменить параметры нейронной сети; · запустить процесс кластеризации; · получить дерево результатов (где корневые директории – кластеры, содержащие каждый свои документы); · сохранить полученный результат в базе данных или в файле. Для обработки данных в качестве эксперимента были выбраны 65 документов из проектной документации организации. Были получены частотные словари, при этом отобраны только термины, приведенные к основе с помощью морфологического анализа, а также исключены стоп-слова. Полученные данные из 65 документов с 2911 терминами были обработаны кластеризатором с использованием нейронной сети Кохонена. Данная нейронная сеть имеет несколько настраиваемых числовых параметров: число нейронов, норма обучения, множитель для нормы обучения, радиус активности области нейрона-победителя, число производимых итераций, шаг модификации. Время обработки резко возрастает при увеличении числа нейронов, радиуса активации и при уменьшении нормы обучения. В ходе исследований были выявлены тенденции влияния на получаемое множество классов при изменении перечисленных выше параметров нейронной сети. В результате получены наборы комбинаций числовых параметров нейронной сети для кластеризации ЭИР в зависимости от желаемой точности/полноты классов. При оценке адекватности разбиения ЭИР на кластеры выявлено, что кластеры в большинстве своем разбивают по типам документов, при этом выносят в отдельные кластеры ЭИР с резко отличающейся лексикой. Полученный результат кластеризации адекватен экспертной разбивке проблемной области. В заключение можно сделать следующие выводы. Нейросетевой кластеризатор на основе SOM прост в реализации, удобен в обучении, требует минимального участия эксперта, а также позволяет выбирать оптимальное соотношение точность/полнота за счет настройки числовых параметров в алгоритме обучения. С другой стороны, низкая адекватность модели представления текста не позволяет улучшить характеристики точность/полнота. Таким образом, существует необходимость разработки более сложной модели текста, такой как гибридная семантическая сеть. |
 X и функция расстояния между объектами ρ(x,x′). Требуется разбить выборку на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ, а объекты разных кластеров существенно отличались. При этом каждому объекту xi
X и функция расстояния между объектами ρ(x,x′). Требуется разбить выборку на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ, а объекты разных кластеров существенно отличались. При этом каждому объекту xi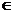 Xℓ приписывается метка (номер) кластера yi.
Xℓ приписывается метка (номер) кластера yi. ;
;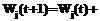
 , где
, где  – норма обучения.
– норма обучения.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1616 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
| Статья опубликована в выпуске журнала № 4 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
- Разработка теоретических основ классификации и кластеризации нечетких признаков на основе теории категорий
- Нейросетевой алгоритм и модели нечеткой логики для задачи классификации
- Применение методов классификации и кластеризации для повышения эффективности работы прецедентных систем
- Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
Назад, к списку статей