Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Нейросетевой алгоритм и модели нечеткой логики для задачи классификации
Аннотация:
Abstract:
| Авторы: Филатова Н.Н. (nfilatova99@mail.ru) - Тверской государственный технический университет, Тверь, Россия, доктор технических наук, Спиридонов А.В. () - | |
| Ключевые слова: нейронная сеть, нечеткая логика, классификация, исследование |
|
| Keywords: neural network, fuzzy logic, classification, |
|
| Количество просмотров: 13249 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
Применение искусственных нейронных сетей (ИНС) вместо обычно используемых математических методов анализа позволяет на основе описания объекта в виде набора признаков (признакового пространства) построить классификатор, который будет разделять классы объектов с учетом имеющихся различий между ними. Для принятия решения об отнесении распознаваемого объекта, представленного набором признаков, к одному из заданных классов системы диагностики используют специализированные базы знаний (БЗ). Классификатор на основе ИНС способен расширять БЗ при предъявлении ему заранее неизвестных (значительно отличающихся от уже известных в соответствии с выбранным критерием близости) объектов. Это связано со следующими особенностями нейронных сетей:
– ИНС в состоянии одновременно работать с большим количеством входных параметров (порядка сотен и выше), что практически не может быть оценено человеком; – ИНС способны обобщать полученную информацию и на основе этого обобщения принимать решения, основываясь на выявляемых ими скрытых закономерностях в данных. Модель нейронной сети для классификации спектров дыхательных шумов Для построения и исследования ИНС создана выборка дыхательных шумов (ДШ) Х, включающая N векторов вида На первом этапе осуществляется нормализация значений признаков:
где На основе множества Х формируется множество Хн, в котором
где Нормализованные векторы Хнj сохраняются в БД DB1 как основа для формирования ОВ, КВ и ТВ. Состояние каждого k-го нейрона сети задается весовым Для реализации второго этапа используется парадигма обучения без учителя. При построении обучающего правила за основу взят метод соревнования. Цикл обучения включает подачу на вход сети очередного объекта Хнj Определяем степень подобия j-го образца каждому k-му описанию класса:
где L – текущее количество нейронов в слое;
где Р1 – порог допустимого отклонения значения признака от эталона (задается эмпирически как параметр алгоритма). Модуль Comp1 сравнивает активности всех нейронов слоя и определяет нейрон-победитель, для которого формируется высокий уровень соответствующего управляющего сигнала corrk, активирующего механизм корректировки весового и эталонного векторов нейрона-победителя. Если
где Определяем R-множество. Если Если объектов ОВ больше нет, обучающий цикл выполняется рекурсивно для каждого из созданных нейронов. В качестве ОВ рассматривается совокупность объектов, отнесенных к нейрону, для которого выполняется обучение. Остальные объекты игнорируются. Для каждого нового рекурсивного процесса обучения устанавливаются собственные значения параметров Р1–Р4. В процессе формируются дочерние нейроны, для которых, в свою очередь, также выполняется обучение. Процесс заканчивается, если количество объектов в нейроне не превышает значения Построение правил вывода и классификация ДШ На основе полученного разбиения обучающей выборки автоматически формируются правила для каждого полученного класса, которые используются в процессе классификации новых объектов. Построение правил вывода выполняется для каждого k-го описания класса. На каждом уровне процессы построения правил вывода и классификации ДШ идентичны. Правила вывода формируются на основе нечетких множеств. Для каждого i-го признака определим лингвистическую переменную (ЛП) «СПМ на частоте
Ti,2 – средняя оценка, Ti,3 – высокая оценка>. (6) Значение ЛП определяется одним или несколькими термами – от соответствующего значению dkimin до соответствующего значению dkimax, где Для каждого k-го класса высказывание будет иметь вид: ЕСЛИ И где Ai,k – посылка, определяемая в соответствии с функцией принадлежности для i-го признака; Функцию принадлежности для заключения
Функцию принадлежности для всей предпосылки в высказывании (7) определим как:
Функцию принадлежности для k-го правила определим в виде:
Если Для автоматизации процессов построения классификатора и классификации по правилам было разработано программное средство (ПС), реализующее описанный алгоритм. Данное программное средство функционирует в 4 режимах: 1) инициализация классификатора и нормализация ОВ (формула (1)); 2) обучение классификатора и построение отношения между классами в виде иерархической структуры (формулы (2)–(5а),(5б)); 3) построение правил классификации на основе теории нечетких множеств (формулы (6)–(7)); 4) классификация объектов на основе построенных правил (формулы (8)–(10)). ПС отображает используемую выборку в виде таблицы, позволяет отобразить построенные правила классификации, включая значения диапазонов для каждого терма лингвистической переменной, в таблице и графическом представлении. Результаты классификации спектров ДШ Была использована выборка из N=56 спектральных характеристик ДШ, представленных объектами классов НОРМА и ПАТОЛОГИЯ, из которых 46 объектов использовались в качестве ОВ, 10 в качестве ТВ. Из 46 объектов ОВ 30 использовались в качестве КВ. Набор объектов класса ПАТОЛОГИЯ был представлен тремя типами патологий: ПНЕВМОНИЯ, БРОНХИТ и АСТМА. С помощью предложенного алгоритма (при параметрах, указанных в таблице 1) удалось разбить ОВ на 4 класса (таблица 2). Ошибки первого рода отсутствовали полностью. Классификация объектов КВ и ТВ выполнялась на основе построенных правил вывода. Таблица 1 Значения параметров обучения ИНС
Построенные эталоны позволили сделать вывод, что различия выделенных классов находятся в области частот от 600 Гц и ниже, то есть классы имеют значимые отличия в первых 56 признаках. Это существенно снижает требования к размерности ОВ, позволяет считать размерность имеющейся ОВ достаточной, а полученные на основе данной выборки результаты достоверными. Введение R-множества позволило свести к нулю ошибки первого и второго рода при классификации объектов. Это также привело к появлению показателя, определяющего количество неклассифицированных (отнесенных к R-множеству) объектов. Таблица 2 Результаты обучения ИНС
Во всех экспериментах также достоверно (без ошибок) удалось отделить объекты класса НОРМА от остальных типов объектов для каждой выборки (ОВ, КВ и ТВ). Список литературы 1. Филатова Н.Н., Спиридонов А.В. О возможности применения искусственных нейронных сетей в пульмонологии. // Информатика и процессы управления. Компьютерные системы и технологии.: Сб. науч. тр. – М.: МИФИ, 2008. – С. 46–47. 2. Филатова Н.Н., Вальдес А., Аль-Нажжар Н.К. Алгоритм распознавания класса дыхательных шумов на основе нечетких правил. // Нечеткие системы и мягкие вычисления. – 2007. – Т. 2. – № 3. |
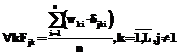 , (3)
, (3) , (4)
, (4)| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1650 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
| Статья опубликована в выпуске журнала № 4 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
- Моделирование и анализ программ многомерных интервально-логических регуляторов
- Алгоритм классификации, основанный на принципах случайного леса, для решения задачи прогнозирования
- Комплексный метод выполнения арифметических операций над нечеткими числами и его применение при экономическом анализе в условиях неопределенности
- Программная система предпроектных исследований технологических процессов формования химических волокон
Назад, к списку статей