Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Оценка селективности XPath-запросов в XML-СУБД
Аннотация:
Abstract:
| Автор: Лукичёв М.С. () - | |
| Ключевые слова: оценка стоимости, оптимизация запросов, xpath, xml, базы данных |
|
| Keywords: , , , xml, database |
|
| Количество просмотров: 13261 |
Версия для печати Выпуск в формате PDF (4.72Мб) |
Высокоуровневые языки запросов принято рассматривать как одно из наиболее важных средств, предоставляемых СУБД. Высокая эффективность исполнения запросов достигается в процессе оптимизации. По существу оптимизатор выбирает один из эквивалентных планов выполнения исходного запроса, но имеющий наименьшую стоимость. Обычно в качестве стоимости рассматривают приблизительную оценку времени выполнения той или иной операции, а стоимость самого плана вычисляется на основе стоимостей всех операций, из которых он состоит. При этом оценка для каждой операции вычисляется на основе размеров и характеристик ее операндов. Определение точного размера операнда не имеет смысла, так как это по сути потребует вычисления самого запроса. Поэтому в высокопроизводительных СУБД используются компактные структуры, обобщающие содержание базы данных. В системах, основанных на реляционной модели, в качестве таких структур обычно используются гистограммы [1]. Однако для XML-ориентированных моделей данных, учитывая их специфику, методы обобщения и оценки стоимости, разработанные в контексте реляционной модели, требуют пересмотра. Язык запросов и методы оценки стоимости В качестве языка XML-запросов наибольшее распространение получили язык XQuery и его подмножество XPath, отвечающее за выборку данных. Стоимость операции вычисляется на основе размеров ее операндов. Учитывая, что операндами в конечном счете являются операции, отображающие XPath-выражение (навигационное выражение), необходимо уметь оценивать размеры результатов их выполнения (далее – селективность запроса). Навигационное выражение состоит из последовательности шагов. Каждый шаг характеризуется осью, условием перехода и необязательным предикатом. Условие перехода определяет, можно ли включить узел в результат. Например, обладает ли узел требуемым именем. Оси описывают отношения в XML-иерархии между текущим (контекстным) узлом и узлами, выбираемыми на данном шаге. Например, ось child выделяет узлы, являющиеся детьми контекстного. Всего спецификация XPath определяет 13 осей. Пять из них (ancestor, descendant, following, preceding и self) являются разделяющими. То есть для некоторого текущего узла эти оси задают непересекающиеся множества, содержащие все узлы иерархии. Первые две оси обычно называют основными, а последние две – вспомогательными. Following и preceding относятся к широким вспомогательным осям, а following–sibling и preceding–sibling к узким. Существующие подходы, ориентированные на оценку селективности XPath-запросов, различаются по ведению сбора статистики (путем просмотра всего содержимого базы или на основе результатов вычисления запросов), по типу поддерживаемых запросов (простые XPath-запросы или запросы со сложными предикатами) и по способу организации статистических структур (обобщения путей [2] или гистограммы [3]). Методы оценки селективности XPath-запросов, содержащих только основные оси вместе с осями child и parent, хорошо изучены. Методы для оценки запросов, содержащих вспомогательные оси, изучены значительно меньше. Отчасти это связано с относительной новизной области и с тем фактом, что до недавнего времени XML использовался в основном как формат для хранения данных, для которых порядок не важен. Примером таких данных может служить DBLP, где порядок следования статей в документе не имеет значения. В данной статье предложены способ обобщения XML-данных, называемый группировкой по соседям, и методы оценки селективности запросов, содержащих как основные, так и вспомогательные оси. Группировка по соседям Основная идея группировки по соседям заключается в построении графа, обобщающего исходное XML-дерево. В литературе такой подход часто называется обобщением путей (path synopsis) [4]. Каждая вершина графа соответствует множеству узлов, которые могут быть получены в результате выполнения некоторого запроса. В свою очередь, каждый узел иерархии соответствует единственной вершине дерева. То есть узлы исходной XML-иерархии соответствуют вершине графа (или попадают в одну группу), если: 1) имеют одинаковое имя; 2) их родительские узлы относятся к одной группе; 3) обладают одинаковым набором различных имен узлов-детей. Вершины родительских узлов соединены дугами с вершинами детей, а дуги получают вес, равный количеству узлов в последних. Такие дуги соответствуют отношениям parent–child. При этом для отношений following–sibling и preceding–sibling добавляются дополнительные дуги. Вес этих дуг равен количеству узлов одной группы, находящихся в соответствующем отношении с узлами той группы, из которой эта дуга выходит. Обобщение строится путем обхода XML-иерархии сверху вниз, начиная с корневого узла. На рисунке слева изображено исходное XML-дерево, а справа – структура, получаемая в результате группировки по соседям.
Так как в приведенном примере не все вершины обладали одинаковым набором различных имен узлов-детей, они были разделены на две группы. Отметим, что порядок следования групп не важен, так как он может быть восстановлен при помощи вспомогательных (пунктирных) дуг. Оценка селективности Для вычисления селективности запросов, содержащих узкие вспомогательные оси, применяется алгоритм, подобный используемому для вычисления XPath, с той разницей, что поиск производится на графе обобщения, а для вычисления узких вспомогательных осей берутся соответствующие дополнительные дуги. После выполнения последнего шага получается некоторое множество вершин графа (возможно, пустое). Результатом будет сумма весов всех дуг, ведущих в элементы полученного множества. Вычисление селективности выражений, содержащих широкие вспомогательные оси, основано на том факте, что их можно преобразовать к набору выражений, содержащих только узкие. Например, чтобы вычислить выражение A/B/C/following::D, достаточно вычислить следующие два выражения и объединить их результаты: A/B/following-sibling::*/descendant-or-self::D; A/B/C/following-sibling::*/descendant-or-self::D. Таким образом, селективность будет равна сумме селективностей последних двух выражений. Обозначим навигационное выражение как Экспериментальные оценки Для оценки свойств полученного обобщения использовались три набора тестовых данных, отличающихся структурой. 1. XHTML-страницы (спецификации W3C) как пример документ-ориентированных нерегулярных XML-данных. Особенностью этих данных является относительно большое количество узлов с различными именами. 2. Описание университетских курсов в виде XML как пример регулярных данных. 3. Пьесы Шекспира в виде XML в качестве компромисса между предыдущими двумя. Эксперименты показали, что размер получившейся структуры для нерегулярных данных первого типа составил 20 % от размера исходного документа (измерялось количество узлов), а для последних двух типов – 0,08 % и 0,75 % соответственно. Для определения точности методов оценки были сгенерированы все возможные XPath-запросы, содержащие по одному шагу по одной из вспомогательных осей. Эти запросы были разделены на четыре класса в зависимости от того, где располагался шаг по вспомогательной оси – в конце (t) или в середине (m), и от типа самого шага (широкий или узкий). В таблице приведены результаты вычисления точности оценки. Здесь выражения с шагами по широким осям обозначены как major, а по узким – как minor. Средняя относительная погрешность оценки селективности
Из результатов экспериментов видно, что предложенная техника является достаточно компактной и точной для относительно регулярных данных, потребность выполнения запросов к которым встречается на практике наиболее часто. Таким образом, она может быть применена при построении оптимизаторов запросов, использующих стоимостные оценки. Литература 1. Yannis E. Ioannidis. The history of histograms. The VLDB Journal, 2003, pp. 19–30. 2. Ashraf Aboulnaga, Alaa R. Alameldeen, and Jeffrey F. Naughton. Estimating the selectivity of XML path expressions for internet scale applications. The VLDB Journal, 2001, pp. 591–600. 3. Wei Wang, Haifeng Jiang, Hongjun Lu, and Jeffrey Xu Yu. Bloom histogram: Path selectivity estimation for xml data with updates. VLDB’04: Proceedings of the Thirtieth International Conference on Very Large Data Bases, 2004, pp. 240–251. 4. Roy Goldman and Jennifer Widom. Dataguides: Enabling query formulation and optimization in semistructured databases. In VLDB ’97: Proceedings of the 23-rd International Conference on Very Large Data Bases, 1997, pp. 436–445. 5. Yury Soldak and Maxim Lukichev. Enabling xpath optional axes cardinality estimation using path synopses. ADBIS, 2008, pp. 279–294. | |||||||||||||||||||||||
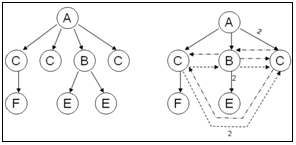 Для упрощения рисунка вес дуг, у которых он не приведен, равен 1. Сплошными линиями обозначены дуги по оси child, штриховыми – по оси following–sibling, штрихпунктирными – по оси preceding–sibling.
Для упрощения рисунка вес дуг, у которых он не приведен, равен 1. Сплошными линиями обозначены дуги по оси child, штриховыми – по оси following–sibling, штрихпунктирными – по оси preceding–sibling.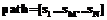 , где si – i-й шаг; M – индекс шага с широкой вспомогательной осью, для которого будет проводиться преобразование. Обозначим каждый шаг как
, где si – i-й шаг; M – индекс шага с широкой вспомогательной осью, для которого будет проводиться преобразование. Обозначим каждый шаг как 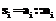 , где
, где 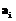 – ось;
– ось; 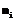 – условие перехода, а ось descendant–or–self как ds. Тогда для расчета селективности навигационного выражения используем следующую формулу:
– условие перехода, а ось descendant–or–self как ds. Тогда для расчета селективности навигационного выражения используем следующую формулу: 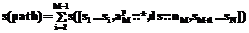 , где
, где 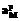 – узкая вспомогательная ось, соответствующая
– узкая вспомогательная ось, соответствующая 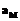 .
.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2266 |
Версия для печати Выпуск в формате PDF (4.72Мб) |
| Статья опубликована в выпуске журнала № 2 за 2009 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Применение методов нечеткого регулирования в соединении онтологий предметной области
- Методы сокращения количества уязвимостей в специальном программном обеспечении реального времени
- Генератор текста программ в исходном виде для систем реального времени
- Разработка многоагентного ПК ИНТЭК-М для исследований проблемы энергетической безопасности
- Обработка ошибок реляционных баз данных
Назад, к списку статей