Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Открытость структур в эволюционной модели данных
Аннотация:
Abstract:
| Авторы: Дрождин В.В. (drozhdin@yandex.ru) - Пензенский государственный педагогический университет им. В.Г. Белинского, г. Пенза, Россия, кандидат технических наук | |
| Ключевые слова: семантика данных, операции над структурами данных, преобразование структур данных, структура данных, эволюционная модель данных, модель данных, информационная система, самоорганизующаяся система |
|
| Keywords: , , , data structure, , Data Model, information system, self-organizing system |
|
| Всего комментариев: 1 Количество просмотров: 10731 |
Версия для печати Выпуск в формате PDF (4.72Мб) |
Эволюционная модель данных (ЭМД) предназначена для создания активных самоорганизующихся информационных сред (СИС), способных самостоятельно поддерживать информационные модели с высокой степенью адекватности отражаемой предметной области в течение длительного времени. Это требует наличия в ЭМД очень мощных средств для организации информации об объектах различной структуры и сложности и возможности формирования представлений объектов с требуемой степенью детализации, включающих обобщенные (укрупненные, интегральные) показатели. В [1] на основе системного подхода определяется пятислойная организация данных локальных систем. Эта организация данных является достаточно гибкой и может быть адаптирована для создания СИС. При этом различают структуры Si, являющиеся целостными объектами-системами и представляющие один объект i-го уровня, и структуры Ri, являющиеся множествами допустимых структур Si [2]. В таблице приведены слои организации данных локальной системы с их описаниями.
Приведенные структуры конструктивно имеют следующие характеристики: R0 – тип данных языка программирования или абстрактный тип данных, определенный и реализованный в системе, элементами которых являются атомарные объекты S0; R1 – подмножество базового типа R0, объекты S1 которого получены по закону f (в частном случае тривиальному) из объектов S0; R2 – множество сложных объектов S2, каждый из которых является композицией объектов S1; R3 – более сильно связанная (совместно используемая) часть объектов S2 или совместно используемые S2 и ранее созданные объекты S3'; R4 – единственный объект S4, представляющий всю взаимосвязанную совокупность данных S2 и S3 локальной системы. Можно провести определенную аналогию между структурами ЭМД и структурами реляционной модели данных (РМД) соответственно: S1 – элемент домена; R1 – домен; S2 – кортеж; R2 – отношение; S3 – кортеж представления; R3 – представление; S4, R4 – базы данных. Как видно из характеристики структур и проведенной аналогии их со структурами РМД, открытость структур ЭМД вверх до формирования единой структуры, содержащей всю БД локальной системы, не содержит серьезных (логических) ограничений, следовательно, может считаться вполне приемлемой для организации данных в рамках ЭМД. Однако открытость структур вниз (до байтов и битов) ограничивается структурами R1, объекты S1 которых обладают изначально минимальной семантикой в моделируемой предметной области и представляют, например, фамилии, адреса, даты рождения и др. Но возникшая потребность в более точном моделировании предметной области часто требует выделения отдельных компонентов из принятых изначально минимальных объектов, например, названия населенного пункта из адреса или фамилии из ФИО. Поэтому необходима разработка методов и средств, позволяющих декомпозировать целостные структуры S1 на более мелкие подструктуры S-1 с возможностью восстановления из них исходных структур S1. Для декомпозиции и согласования структур S1 и S-1 будем использовать две операции – q1 и q–1, которые определим следующим образом:
Операция q1 осуществляет декомпозицию структуры S1 на две более низкого уровня, Использование объектов Последовательное применение операций
В качестве простой операции q1 может использоваться операция выделения одного или k первых слов из S1, в результате чего S1 разбивается на В более сложных случаях операция q1, например, может выделять различные компоненты адреса, заданного строкой символов, и некоторую подстроку из строки по заданному условию, декомпозировать числовое значение на два значения путем использования операции взятия по модулю и другие. Операция q–1 всегда будет восстанавливать из объектов Типы данных объектов Семантика объектов Если же для реализации операции q1 используется общая часть часто задаваемых запросов, то объекту Если операция q1 осуществляет разбиение объекта S1 на Проблема формирования обобщенных показателей существенно более сложная, поэтому в данной работе рассмотривается только простейший вариант обобщения объектов. Простое обобщение можно сформировать на основе принципа совместного использования данных. Например, если имеются отдельные парамет- ры «число», «месяц» и «год», «часы», «минуты» и «секунды» или «фамилия», «имя» и «отчество», а их данные в подавляющем большинстве случаев используются совместно, то целесообразно композировать их в укрупненные параметры «дата», «время» и «ФИО» с указанием местоположения каждого отдельного параметра в укрупненном параметре. При этом отдельные параметры будут соответствовать структурам Укрупнение параметров позволяет стандартно уменьшать количество компонентов в СИС без организации дополнительных слоев, что повышает эффективность обработки данных. Взаимообратные операции q–1 и q1, введенные для осуществления композиции и декомпозиции структур, являются операциями-шаблонами, для которых известны назначение, принцип действия и требования к исходным данным и результату. Особенности выполнения операций зависят от типов обрабатываемых данных и методов преобразования структур, поэтому их реализация на основе запросов пользователей будет определять возможности конкретных СИС в эволюции внутренней организации данных и достижении определенного максимума эффективности обработки данных. Таким образом, открытость структур данных вверх и вниз в ЭМД позволяет создавать информационные модели предметной области с произвольной степенью детализации и последующим уточнением или огрублением этой модели с помощью средств, имеющихся в ЭМД. Литература 1. Дрождин В.В. Системный подход к построению модели данных эволюционных баз данных // Программные продукты и системы. 2007. № 3. С. 52–55. 2. Система, симметрия, гармония. М.: Мысль, 1988. 315 с. |

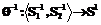 .
.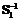 и
и  , выделением по определенному закону из структуры S1 подструктуры
, выделением по определенному закону из структуры S1 подструктуры 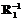 и
и  , которые в общей структуре объектов будут соответствовать объектам уровня R1.
, которые в общей структуре объектов будут соответствовать объектам уровня R1.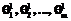 к остаточной структуре предыдущего разбиения
к остаточной структуре предыдущего разбиения 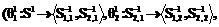
 позволяет декомпозировать исходную структуру S1 на m+1 структур более низкого уровня, а последовательность операций
позволяет декомпозировать исходную структуру S1 на m+1 структур более низкого уровня, а последовательность операций 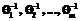 восстанавливает исходный объект S1, то есть
восстанавливает исходный объект S1, то есть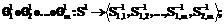
 .
.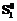 и
и  , из которых формируются объекты
, из которых формируются объекты  – «почтовый индекс» и
– «почтовый индекс» и 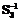 , а укрупненный параметр – структуре S1. Осуществление композиции укрупненного параметра из отдельных параметров будет соответствовать операции q–1, а выделение отдельных параметров из укрупненного параметра – операции q1.
, а укрупненный параметр – структуре S1. Осуществление композиции укрупненного параметра из отдельных параметров будет соответствовать операции q–1, а выделение отдельных параметров из укрупненного параметра – операции q1.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2270 |
Версия для печати Выпуск в формате PDF (4.72Мб) |
| Статья опубликована в выпуске журнала № 2 за 2009 год. | Версия для печати с комментариями |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Модели как основные артефакты архитектуры информации
- Управление развитием надежных кластерных структур информационных систем
- Методики оптимизации транспортно-погрузочного комплекса предприятия
- Об одном подходе к реализации системы управления мастер-данными об активах
- Анализ особенностей процессов управления требованиями к информационным системам государственных структур
Назад, к списку статей
Comments
автор: Роман [2010-01-02 17:10:42]Еще одна блестящая статья создателя Эволюционной модели данных (ЭМД) В.В. Дрождина показывает, что открытость структур данных в ЭМД позволяет создавать активные самоорганизующиеся информационные системы, многократно превосходящие современные пассивные программные системы.
Оценка пользователя: 10 баллов