Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Полуавтоматическое семантическое аннотирование мультимедиаресурсов
Аннотация:В данной работе предлагается методика для автоматизации аннотирования аудиовизуальных мультимедийных ресурсов на примере изображений. Производятся уточнение, актуализация и расширение набора утверждений об изображении и/или набора извлеченных визуальных свойств за счет использования технологий Semantic Web и рас-пределенных БЗ, представленных в RDF и OWL. Показано, как можно использовать при этом начальное извлечение аудиовизуальных свойств и их связывание с высокоуровневыми концептами для преодоления семантической пропасти.
Abstract:In this paper approach for automated multimedia assets annotation is been described using images as example. This approach describe how to extend and actualize set of statements about assed and list of extracted audio visual features using Semantic Web technologies and distributed knowledge base expressed in RDF and OWL. Also author discuss about possible ways of linking hi and low level concepts for solving semantic gap issue.
| Авторы: Тюхов Б.П. (serrnovik@gmail.com) - Московский государственный институт электроники и математики (технический университет), кандидат технических наук, Новиков С.В. (serrnovik@gmail.com) - Московский государственный институт электроники и математики (технический университет) | |
| Ключевые слова: автоматическая аннотация, семантическая пропасть, аудиовизуальные свойства, онтологии, semantic web |
|
| Keywords: automatic annotations, semantic gap, visual features, ontology, semantic web |
|
| Количество просмотров: 11679 |
Версия для печати Выпуск в формате PDF (4.97Мб) Скачать обложку в формате PDF (1.38Мб) |
В связи с быстрым ростом количества цифровых аудиовизуальных данных повышаются требования к уровню сложности систем поиска и управления мультимедиаресурсами. Для мультимедийных данных наличие и качество аннотаций достаточно критичны, поскольку без качественных аннотаций невозможно найти ресурс, например изображение. Использование популярных в текстовом поиске синтаксических алгоритмов для мультимедиаресурсов невозможно, а применение системы, основанной только на извлечении аудиовизуальных свойств и/или нахождении визуального сходства, не дает удовлетворительных результатов. Для решения задач поиска мультимедиаресурсы предварительно описываются человеком. Такой подход имеет недостатки: большие затраты времени, а также невозможность автоматического использования семантики описаний. При поиске мультимедиаресурсов пользователя чаще всего интересуют концептуальные описания: что изображено, какое действие происходит, кем производится действие, где, как и т.д. Основой для выдачи содержимого являются семантические аннотации. Наиболее распространенный подход – индексирование, то есть добавление к документам или мультимедиаресурсам ключевых слов, описывающих их содержимое. Если не используется словарь значений слов, они не будут представлены семантически. Семантику может описать онтология. Некоторые системы используют собственные ограниченные словари. Это расширяет возможности для семантического поиска, но создает сложности для обмена метаданными с другими системами. Ряд систем, в том числе и обсуждаемые в [1, 2], опираются на онтологический подход к аннотированию метаданных. Главным ограничением для их широкого применения является размер самой онтологии. В большинстве систем требуется описывать обширные области, например, в одних – всю область медицинских изображений, в других – «все знание человечества» с определенной детализацией. Для решения этой проблемы предлагается использовать распределенные БЗ. Сегодня в открытом доступе уже находятся большие объемы знаний, формализованных в виде RDF и OWL, в частности, существуют как большие БЗ (например DBPEDIA) и ряд онтологий высокого уровня (такие, как UMBEL), так и множество узкоспециализированных онтологий и наборов утверждений о мире, которые образуют распределенную БЗ. Ее можно расширить своей онтологией и набором понятий, а объединив несколько баз знаний, вывести новое знание, которое ни в одной из них не присутствует явно. Основными задачами, решаемыми в данной работе, являются повышение качества аннотаций концептуального содержимого мультимедиаэлементов и, следовательно, поиска, а также значительное уменьшение временных затрат на аннотирование мультимедиаресурсов. При рассмотрении ручного аннотирования, которое основано на использовании достаточно широкой онтологии, можно выделить две проблемы: субъективность описаний и недостаточную детализацию. Действительно, аннотируя изображение кисти руки и внося утверждение, что на изображении кисть человека, получаем ситуацию, когда на поисковый запрос «конечности млекопитающих» это изображение выдано не будет, хотя на основании онтологий получить такое знание несложно, так как учет обобщенного знания – важнейший признак онтологии. Проблема субъективности заключается в том, что два человека могут трактовать одно и то же изображение по-разному. Выделим следующие направления решения. Первое направление – это предложение пользователю добавить набор утверждений, полученных выводом на БЗ. Следовательно, пользователь в основном выбирает утверждения, а не добавляет их самостоятельно, за счет этого время аннотирования сокращается. Предлагается выводить утверждения, основываясь на распределенной БЗ. В качестве системы управления семантической БЗ можно использовать такие решения, как Semantic Web с машиной вывода Eruller или семантическую надстройку (появившуюся недавно) в Oracle n11. Второе направление – это дополнение знаниями, автоматически извлеченными на основании визуальных свойств. Методика извлечения визуальных свойств хорошо представлена в спецификации MPEG-7. Позже в [3] был предложен подход, позволяющий использовать этот стандарт в контексте Semantic Web с использованием OWL и RDF. Для обработки визуальных свойств предлагается их приведение к низкоуровневым концептам, например, к названию цветов или текстур, форм и т.п. и их значениям. Получить такие правила и онтологию можно, используя уже имеющуюся базу аннотированных изображений, путем извлечения и сопоставления визуальных свойств и соответствующих им низкоуровневых концептов с высокоуровневыми, что предлагается выполнять на основе машинного обучения и обратной связи. Для того чтобы связать низкоуровневые концепты с более высокими, потребуются набор правил и онтология, описывающая низкоуровневые концепты. Проблему связи низкоуровневых и высокоуровневых свойств часто называют семантической пропастью. Сегодня, чтобы описать высокоуровневый концепт для достаточно широких доменов, требуется вмешательство человека. В случае распределенной БЗ, охватывающей большую предметную область, извлечение визуальных свойств предлагается использовать в качестве отправной точки при аннотировании нового мультимедиаресурса. До начала ручного аннотирования изображения система уже предлагает ряд утверждений. Качество алгоритмов извлечения визуальных свойств – достаточно критичное требование. Однако конкретный набор алгоритмов не влияет на описываемый подход, что обеспечивает масштабируемость системы.
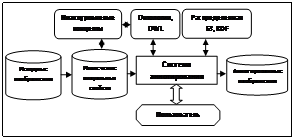
По мнению авторов, недостатком этого подхода является алгоритм обнаружения правил вывода: он не учитывает совместную вероятность появления визуальных свойств. Предлагается взять этот подход за основу, так как он дает ряд ключевых преимуществ, основным из которых является возможность работать с визуальными свойствами как с низкоуровневыми концептами на онтологическом уровне после конвертирования их в низкоуровневый концепт. Другим важным преимуществом можно считать масштабируемость набора алгоритмов: при вводе нового алгоритма в систему достаточно запрограммировать связь значения визуальных свойств и низкоуровневых концептов, предварительно добавив их в онтологию. В работе [2] авторы решали задачу автоматического описания изображений ключевыми словами на основании извлечения визуальных свойств. Сходство с описываемым подходом и решением, использованным в [1], в том, что ключевые слова в данном контексте являются промежуточным звеном, имеющим в онтологии связи как с низкоуровневыми свойствами, так и с высокоуровневыми концептами. Использование знания из онтологии позволяет в том числе исключить правила, которые будут взаимопротиворечащими. Любой объект, для которого ищутся новые правила, может быть представлен как вектор свойств, где каждая координата – свойство. Значения свойств булевы и характеризуют наличие или отсутствие данного свойства у этого объекта. Наиболее интересным является предложение использовать байесовскую сеть доверия для поиска новых правил, учитывая совместную вероятность появления визуальных свойств. Однако в отличие от классического обучения на байесовской сети процесс обучения осуществляется как на онтологиях, так и на совместной вероятности появления визуальных свойств и ключевых слов в аннотируемом изображении. Предлагается, опираясь на опыт [2], использовать обучение на байесовской сети применительно к низкоуровневым концептам, полученным из визуальных свойств. На рисунке изображена концептуальная схема системы семантического аннотирования. Опишем обобщенный алгоритм ее работы при аннотировании изображений. 1. Открыть файл мультимедиаресурса. Выполнить набор алгоритмов по извлечению визуальных свойств. Для изображений в качестве простого набора алгоритмов можно использовать: EHD (Edge histogram descriptor) – для извлечения свойств текстуры; Contour-SD – для определения контура текстур и формы; CSD – для получения свойств цвета. Отметим, что качество повышается, если производить предварительную сегментацию изображения, например, на основании областей интереса (ROI). 2. Сопоставить значения визуальных свойств с низкоуровневыми концептами на основании промежуточной онтологии и правил сопоставления. 3. Найти высокоуровневые концепты, содержащие схожие наборы визуальных свойств, используя полученные низкоуровневые концепты. 4. Сделать ряд утверждений о ресурсе на основании полученных сопоставлений. 5. Опираясь на имеющиеся знания, осуществить вывод новых утверждений на онтологии. 6. Предложить пользователю набор полученных утверждений для подтверждения. Пользователь начинает взаимодействие с системой на этом этапе и уже имеет аннотированное изображение. 7. Если пользователем введены дополнительные утверждения, заново осуществить вывод и предложить новые утверждения. Если таковые будут найдены, перейти к пункту 6. 8. Сохранить полученные утверждения для ресурса. 9. После накопления определенного количества мультимедиаресурсов осуществить вывод, целью которого является определение новых правил, связывающих низкоуровневые концепты с высокоуровневыми, а также вывод новых утверждений о высокоуровневых концептах на БЗ в предметной области. Стоит отметить, что качество утверждений, предлагаемых пользователю алгоритмом, будет возрастать при значительном увеличении числа мультимедиаресурсов, которыми оперирует система. Результат применения такого подхода – улучшение качества и сокращение затрат на аннотации за счет того, что предложенные утверждения основываются на знаниях из распределенной базы, обеспечивая возможность для семантического поиска. Литература 1. Kyung-Wook Park и др.: OLYBIA: Ontology-Based Automatic Image Annotation System Using Semantic Inference Rules, Advances in Databases: Concepts, Systems and Applications, 2008. Vol. 4443, pp. 485–496. 2. Oge Marques и др. Semi-automatic semantic annotation of images using machine learning techniques, The Semantic Web – ISWC. 2003. Vol. 2870, pp. 550–565. 3. Hunter J. Adding Multimedia to the Semantic Web - Building and Applying an MPEG-7 Ontology. Wiley, 2006. |
 В [1] предложен метод описания семантической информации за счет использования онтологии объектов вместе с дескрипторами промежуточных уровней. Визуальные свойства после извлечения связываются с дескрипторами промежуточного уровня, читаемыми человеком, и уже через них идентифицируются с объектом из онтологии. Например, тигр описывается как Яркость = {высокая, средняя}, зеленый-красный = {красный мало, красный средне}, синий-желтый = {желтый средний, желтый высокий} и размер = {маленький, средний}. Эти значения получены из алгоритмов извлечения визуальных свойств. Машина вывода связывает низкоуровневые концепты и онтологии, используя правила семантического вывода. Высокоуровневые концепты могут иметь название объекта (например, тигр, орел и т.д.). Низкоуровневые концепты имеют вид простого текста, присваиваемого в соответствии с визуальными свойствами, например, «много» и «мало» для значений визуальных свойств.
В [1] предложен метод описания семантической информации за счет использования онтологии объектов вместе с дескрипторами промежуточных уровней. Визуальные свойства после извлечения связываются с дескрипторами промежуточного уровня, читаемыми человеком, и уже через них идентифицируются с объектом из онтологии. Например, тигр описывается как Яркость = {высокая, средняя}, зеленый-красный = {красный мало, красный средне}, синий-желтый = {желтый средний, желтый высокий} и размер = {маленький, средний}. Эти значения получены из алгоритмов извлечения визуальных свойств. Машина вывода связывает низкоуровневые концепты и онтологии, используя правила семантического вывода. Высокоуровневые концепты могут иметь название объекта (например, тигр, орел и т.д.). Низкоуровневые концепты имеют вид простого текста, присваиваемого в соответствии с визуальными свойствами, например, «много» и «мало» для значений визуальных свойств.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2519 |
Версия для печати Выпуск в формате PDF (4.97Мб) Скачать обложку в формате PDF (1.38Мб) |
| Статья опубликована в выпуске журнала № 2 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Расширение базы знаний с учетом доверия к новому знанию
- Онтологии для реализации обратной трассировки при разработке и сопровождении программ
- Подход к реализации автоматизированного поиска онтологической информации в источнике
- Подсистема воспроизведения иммерсивных виртуальных тренажеров с биологической обратной связью
- Мультиагентная система распределения производственных ресурсов в тяжелом машиностроении
Назад, к списку статей