Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Расширение базы знаний с учетом доверия к новому знанию
Аннотация:В данной работе рассматривается методика решения вопросов, возникающих при расширении базы знаний, которая основывается на использовании рейтингов (или, другими словами, репутации) для оценки утверждений, получаемых от пользователей, документов из сети и утверждений, хранящихся во внешних системах. Обсуждаются подход к построению рейтингов и их совместное применение с задаваемыми политиками при использовании распределенной базы знаний и гетерогенных агентов. За основу взяты технологии Semantic Web и распределенные источники знаний, представленные в виде OWL и RDF, позволяющие осуществлять вывод новых знаний и получать их из гетерогенных источников.
Abstract:Issues about trust and reputation in context of describing multimedia assets and knowledge base extension are addressed in this paper. Knowledge database may be extended using statements from distributed sources over the web or directly from users. Approach for evaluating reputation and using it with predefined politics is discussing in this paper. Semantic Web and its OWL and RDF specifications was used as foundation for working dealing with knowledge bases and agents allowing process inference and safe discovering new knowledge.
| Автор: Новиков С.В. (serrnovik@gmail.com) - Московский государственный институт электроники и математики (технический университет) | |
| Ключевые слова: онтологии, распределенная база знаний, доверие, semantic web |
|
| Keywords: ontology, distributed knowledge base, web of trust, semantic web |
|
| Количество просмотров: 11253 |
Версия для печати Выпуск в формате PDF (5.84Мб) Скачать обложку в формате PDF (1.43Мб) |
В связи со значительным увеличением количества мультимедийных данных возникает необходимость в решении новых задач [1]. Системы управления мультимедиаресурсами должны давать возможность осуществлять поиск, создавать, хранить и обмениваться аннотациями с внешними системами. Примерами мультимедиаресурсов могут быть цифровые изображения собрания музея или домашней коллекции фотографий. Ценность ресурса в таких системах часто определяется тем, насколько легко и быстро его можно найти. Под технологиями Semantic Web в данной работе понимаются три основные спецификации этой концепции: язык описания ресурсов Resource Description Framework (RDF), язык описания онтологий Web Ontology Language (OWL), язык запросов к RDF SPARQL Protocol and RDF Query Language (SPARQL). С развитием технологий, таких как Semantic Web, стало возможным рассмотрение Интернета как распределенной базы знаний. В связи с этим, с одной стороны, открываются новые возможности для более качественных аннотаций, где утверждения могут быть связаны с понятиями внешней базы знаний, с другой – встает вопрос доверия к внешним источникам и достоверности их утверждений. Например, при описании изображения дятла отмечено, что это птица. На внешнем ресурсе, например на веб-странице, в формате RDF описан класс «птица». Там же указано, что эта птица относится к классу оперенных. Встает вопрос: можем ли мы доверять этому описанию, стоит ли системе добавить утверждение к описанию мультимедиаресурса, что на изображении присутствует «представитель класса оперенных»? Предполагается, что: · пользователи, делая описания и утверждения, могут ошибаться, · ни один агент не обладает полным знанием (то есть мир открыт), · часть существующих знаний неточная или, может быть, заведомо неверная, · доверие к источнику знаний не может быть полным, так как невозможно знать все про всех. Сегодня, просматривая веб-страницы, люди самостоятельно оценивают, насколько можно доверять тому или иному источнику. В Semantic Web наряду и наравне с людьми информацию обрабатывают программные агенты. Способ оценки доверия к источнику, веб-странице, в данном случае работать не будет: нужен подход, при котором агент может автоматически принимать решение об уровне доверия. (Доверие можно определить как субъективное ожидание объектом поведения другого агента в будущем на основе опыта.) Вопрос достоверности в информационных технологиях не нов. Такие области, как безопасность, контроль доступа в компьютерных сетях, надежность распределенных систем, теория игр и системы агентов, принятие решений при неопределенности, в разной степени были предметом многих исследований. Для примера рассмотрим систему, автоматизирующую аннотацию мультимедиаэлементов. При построении базы знаний автор статьи предлагает опираться на общепринятые, разработанные экспертами онтологии высшего уровня, например UMBEL, а также использовать базы знаний DBPedia, OpenBase и другие источники, связанные с ними. Кроме того, могут использоваться знания, получаемые в результате действий пользователя. Таким образом, ставятся две задачи для программного обеспечения – выведение нового знания и накопление его. Сами по себе они известны, механизм для их решения заложен в семантических стандартах RDF и OWL. Нерешенными остаются вопросы: как принимать решение, доверять новым утверждениям или нет. К примеру, верное утверждение «орел летит» необходимо отделить от выведенного или от полученного из внешней базы знаний утверждения «пингвин летит (летает)». Также возможно, что будут существовать два противоречивых утверждения: «пингвин летит (летает)» и «пингвин не летит (летает)». Два основных пути для определения достоверности – применение репутации и политик [1]. Основное их отличие в том, что политики используют «явное доказательство», а репутации – «предполагаемую достоверность». В ситуации, когда существует система, использующая онтологию высшего уровня третьей стороны, имеющая свои онтологии для специфичного домена и получающая знания из распределенных источников, а также от пользователей, которые могут вносить новые знания, предлагается комбинированный подход с применением и политик, и основанных на рейтингах оценок. Таким образом, для известных источников можно задать политики повышенного доверия, а для всех остальных, не определенных политиками явно, использовать оценку, основанную на вычисленной репутации. Вместе с тем рейтинги можно использовать для выведенного знания из уже имеющихся в базе знаний утверждений. Рейтинги в данном случае важны, так как эти утверждения могут быть неточными и недостоверными. Ряд исследователей заявляют, что в Semantic Web утверждения должны рассматриваться как заявления или утверждения, а не как факты. Автор данной работы разделяет это мнение. В ряде других исследований представляются системы, в которых агенты наделены способностью принимать решения о доверии, а не полагаться на централизованный процесс. При таком подходе решение принимается на основе истории взаимодействий с агентами и другими системами. Получение информации о доверии может быть неявным. Например, если пользователь-архивист, имеющий некоторый опыт и знания о реальном мире, использовал предложенное утверждение «орел летает», это можно считать фактом признания утверждения, которое заслуживает определенного доверия на основании знаний пользователя о мире, и пересчитать уровень доверия. Аналогично, если агент отвергает предложенное утверждение, доверие к этому утверждению понижается. Таким образом, критерием доверия к утверждениям является явное или неявное согласие с ними третьей стороны. Подобным образом на основании общего числа сделанных утверждений и соотнесения их с аналогичными действиями, произведенными остальными участниками, определяется рейтинг агента.
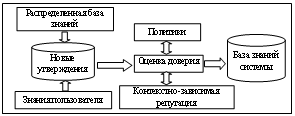
В часто цитируемой диссертации Стивена Марша [2] в качестве первой предлагается известная сложная формальная модель доверия. Марш предложил скомбинировать субъективный набор переменных и их путь, чтобы получить диапазон от полного недоверия до полного доверия [-1, 1]. Однако он утверждает, что эти экстремальные состояния на самом деле невозможны, и определяет три типа доверия: основное – в любом контексте; общее – между двумя агентами и любым контекстом в их взаимодействии; ситуационное – между двумя агентами в специфичном контексте. Применительно к описываемой системе вместо людей используется более общее понятие – агент. Таким образом, для каждого агента накапливается набор утверждений с учетом контекста. Говоря о контексте, можно указывать как конкретную онтологию, так и определенный класс в этой онтологии. Программное обеспечение, разработанное в соответствии с концепцией Semantic Web, работает с OWL-онтологиями и RDFS-схемами и наборами фактов, формализованных в RDF. За представление данных в семантической модели обычно отвечает логическая прослойка между базой данных и программой. Приложениям требуется решать вопросы доверия к знаниям и фактам, как правило, когда импортируются либо индексируются внешние источники с целью агрегировать информацию. Необходимость агрегации обусловлена, например, потребностью работать с более узкоспециализированной онтологией, но при этом иметь связи и опираться на онтологию более высокого уровня для того, чтобы обеспечивать работу с другими агентами. Другим примером служит ситуация, когда необходимо работать с несколькими источниками фактов и знаний, содержимое которых изменяется с течением времени, а потому требуется периодически их индексировать и извлекать новые факты, которые могут вызывать противоречия с уже существующими. Для решения такой задачи автором в разрабатываемом программном компоненте использовалась база знаний, наполнение которой обеспечивалось агрегированием нескольких источников. На основании опыта, полученного при разработке компонента, был выработан следующий алгоритм, позволяющий получать репутацию агента или источника для оценки сделанного им утверждения, концептуальная схема которого представлена на рисунке. 1. Проверяется наличие политики. 2. Если политика не найдена, исследуется иерархия классов в онтологии от более специфичного к более общему классу до тех пор, пока не будет найдена информация о репутации. 3. Если информация все еще не найдена, берется репутация на онтологию для данного агента. 4. Если значение репутации по-прежнему не найдено, используется общая репутация агента, средняя по всем доменам. 5. Если вообще нет информации, делается утверждение, что это новый агент, не обладающий ни положительной, ни отрицательной репутацией, если только для нового агента явно не задана другая политика. Изменение значения рейтинга агента для класса основывается на данных, полученных от других агентов, и результатах вывода, а также на понятиях, находящихся ниже в иерархии классов. После установления значения репутации пересчитываются рейтинги данного агента для более общих и высокоуровневых классов, онтологий и, наконец, общий рейтинг агента. RDFS и OWL позволяют находить противоречия, которые вместе с рейтингами утверждений могут использоваться для определения правильного утверждения. Например, если рейтинг одного из двух противоречивых утверждений больше другого на определенное пороговое значение, принимается решение о признании одного утверждения верным, а другого – нет. Это может быть реализовано за счет добавления соответствующего правила для вывода. Весовые коэффициенты при принятии решения о репутации, а также закон зависимости доверия в более узких доменах с уровнем доверия более общих доменов – предмет дальнейших исследований, так как на практике оказалось, что коэф- фициенты, дающие хороший результат на небольших наборах данных, плохо работают на больших, и наоборот. В ряде работ предлагается использовать контекстно-зависимое доверие вместе с применением правил здравого смысла, например, «не следует доверять продавцу, если цена ниже рыночной более чем на 50 %». В описываемой модели набор таких правил может быть реализован политиками. В работе [3] описаны пять стратегий доверия для агентов в Semantc Web: оптимизм, пессимизм, централизованное и транзитивное доверие, а также расследование. Оптимизм подразумевает доверие, пессимизм – недоверие, централизованное доверие – это доверие через третью сторону, расследование – сбор информации из множества источников, транзитивность – использование сети доверия. В предлагаемой автором модели используется комбинация стратегий расследования и транзитивного доверия. На основе сказанного предложены алгоритм и программная реализация системы управления мультимедиаресурсами, основанная на выводе в распределенных базах знаний и технологиях Semantic Web и позволяющая расширять базу знаний, а также учитывать уровень доверия к утверждениям. Литература 1. Donovan Artz, Yolanda Gil. A Survey of Trust in Computer Science and the Semantic Web, Journal of Web Semantics: Science, Services and Agents on the World Wide Web. 2007. 2. Marsh S. Formalizing Trust as a Computational Concept. PhD thesis, University of Stirling, Department of Computer Science and Mathematics. 1994. 3. O’Hara K., Alani H., Kalfoglou Y. and Shadbolt N. Trust strategies for the semantic web. In Proceedings of Workshop on Trust, Security, and Reputation on the Semantic Web, 3rd International Semantic Web Conference. 2004. |
 Принятие решения о доверии в реальном мире также является транзитивным процессом, где доверие одной части информации или одного источника требует доверия другого связанного с ним источника. Например, одна сторона доверяет автору книги из-за репутации издательства, а издатель может доверять автору только потому, что он был рекомендован другом. Важно отметить, что репутация должна учитываться в контексте. Действительно, агент, являющийся экспертом в области физики, может вносить ошибочные утверждения в области зоологии и заявлять, что «пингвин летает».
Принятие решения о доверии в реальном мире также является транзитивным процессом, где доверие одной части информации или одного источника требует доверия другого связанного с ним источника. Например, одна сторона доверяет автору книги из-за репутации издательства, а издатель может доверять автору только потому, что он был рекомендован другом. Важно отметить, что репутация должна учитываться в контексте. Действительно, агент, являющийся экспертом в области физики, может вносить ошибочные утверждения в области зоологии и заявлять, что «пингвин летает».| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2555 |
Версия для печати Выпуск в формате PDF (5.84Мб) Скачать обложку в формате PDF (1.43Мб) |
| Статья опубликована в выпуске журнала № 3 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Полуавтоматическое семантическое аннотирование мультимедиаресурсов
- Онтологии для реализации обратной трассировки при разработке и сопровождении программ
- Подход к реализации автоматизированного поиска онтологической информации в источнике
- Подсистема воспроизведения иммерсивных виртуальных тренажеров с биологической обратной связью
- Мультиагентная система распределения производственных ресурсов в тяжелом машиностроении
Назад, к списку статей