Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Многомерный анализ данных в системах недоопределенных вычислений
Аннотация:В статье представлен метод многомерного анализа данных на основе технологии недоопределенных вычислений, значительно расширяющий возможности аналитической обработки не полностью определенных данных в системах OLAP.
Abstract:The article presents a method of multidimensional data analysis based on the subdefinite computations technology. The method significantly extends the possibilities of subdefinite data analytical processing in OLAP systems.
| Авторы: Смирнов К.Е. (konstantin.e.smirnov@gmail.com) - Центр информационных технологий и систем органов исполнительной власти, г. Москва | |
| Ключевые слова: программирование в ограничениях, недоопределенные вычисления, olap, многомерный анализ данных |
|
| Keywords: constraint programming, subdefinite computations, olap, multidimensional data analysis |
|
| Количество просмотров: 14991 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
В настоящее время для быстрой обработки сложных запросов к БД в системах поддержки принятия решений широко применяется технология оперативной аналитической обработки OLAP (Online analytical processing). В основе концепции OLAP лежит представление данных в виде многомерной структуры, называемой кубом. OLAP-куб содержит несколько измерений, в разрезе которых осуществляется анализ численных показателей, называемых мерами. Данный подход позволяет получать время обработки запросов на порядки меньшее, чем при запросах к реляционной БД, в частности, за счет предварительно вычисленных агрегатов. Одной из важных проблем в системах OLAP является необходимость учета неточности и недоопределенности исходных данных, находящихся в БД. Недоопределенность характерна как для данных, относящихся к истекшему временному отрезку, так и для значений прогнозируемых показателей. Представлению неточных данных в OLAP посвящен ряд исследований, в которых основное внимание уделяется расширению понятия OLAP-куба с помощью аппарата нечетких множеств, а также разработке методов извлечения нечетких данных [1]. Однако для решения большинства аналитических задач требуется не только возможность представления и извлечения недоопределенных данных, но и поддержка сложных вычислений над ними. При этом между показателями могут существовать алгебраические зависимости произвольного вида, а также логические условия. Кроме того, для обеспечения интерактивного анализа данных необходимо наличие функции обратной записи в ячейки куба, позволяющей изменять значения мер и осуществлять моделирование для данного сценария. Существующие методы представления и обработки неточных данных в OLAP не дают возможности решать задачи удовлетворения ограничений и определения областей возможных значений переменных в общей постановке. Таким образом, разработка методов многомерного анализа данных с учетом их недоопределенности является актуальной задачей. В данной работе описывается разработанный автором метод многомерного анализа данных, основанный на применении математического аппарата недоопределенных вычислений (Н-вычислений) [2]. Этот аппарат относится к активно развиваемому в мире направлению «программирование в ограничениях» и основан на декларативном описании задачи в виде недоопределенной модели (Н-модели), а не на задании алгоритма решения. Н-модель представляет собой набор ограничений R={R1, R2, …, Rk} над переменными x1, x2, …, xn с областями значений, соответственно, A1, A2, …, An. Ограничения могут иметь вид уравнений, неравенств, логических выражений и т.п. Метод Н-вычислений обеспечивает автоматическое нахождение наборов значений (a1, a2, …, an), принадлежащих областям значений Ai, i=1, 2, …, n, одновременно удовлетворяющих всем ограничениям из множества R. Примером Н-модели является следующая модель: const int=11; real x [N]; r=100*((1–x[1])2+sum(int i=11, …, N–1; (x[i+1]– –x[i]2)2)); r=0. Решение данной модели: x[i]=1, i=1, …, 11. Основными преимуществами метода Н-моделей являются: - возможность задания произвольных систем ограничений, не решаемых другими методами; - определение областей возможных значений переменных, а не только конкретных решений; - отсутствие необходимости составлять алгоритм решения задачи; - возможность решения как прямых, так и обратных задач. Указанные свойства значительно расширяют возможности представления и обработки недоопределенных данных при решении широкого класса задач. Метод Н-моделей уже показал свою эффективность для решения ряда экономических задач, в частности, при моделировании инвестиционных проектов и моделировании региональной экономики. Вместе с тем до настоящего времени в системах Н-вычислений отсутствовали методы многомерного представления и аналитической обработки недоопределенных данных. В основе предложенного метода многомерного анализа недоопределенных данных лежит следующее структурное представление Н-модели. Данные хранятся в таблицах реляционной БД, имеющей структуру звезды. Таблица фактов содержит уникальный составной ключ, который объединяет первичные ключи таблиц измерений, и столбцы с численными показателями, представляющими минимальное и максимальное значения соответствующей недоопределенной величины. С каждой записью в таблице фактов связаны одна или несколько недоопределенных переменных (Н-переменных) в Н-модели, представляющих некоторый многомерный показатель. В таблицах измерений содержатся столбец с уникальным ключом, связанным с таблицей фактов, а также столбцы (атрибуты), описывающие данное измерение. Такая структура БД позволяет ускорить выполнение многомерных запросов и использовать при запросах метаданные из нескольких таблиц, что ранее было недоступно в системах Н-вычислений. Архитектура системы многомерного анализа данных на основе Н-вычислений состоит из следующих компонентов. Основным клиентским приложением, в котором происходит работа с данными, является программная система Microsoft Excel. Ее функциональное назначение – предоставление пользовательского интерфейса для выполнения операций с многомерными данными, включая динамическое создание запросов к OLAP-кубу и построение отчетов, изменение значений ячеек с целью пересчета куба и визуализацию показателей.
Основным компонентом, обрабатывающим недоопределенные данные, является вычислительное ядро на основе метода Н-моделей. Ядро производит вычисление Н-модели, в которой задается связь между многомерными показателями. Взаимодействие с вычислительным ядром происходит с помощью расположенного на веб-сервере модуля на языке PHP. После вычислений модели выполняются обновление данных в БД и соответствующее обновление OLAP-куба. Компонент передачи данных из Microsoft Excel в вычислительное ядро отслеживает измененные пользователем ячейки и затем для проведения пересчета передает данные в вычислитель по протоколу HTTP. В изменяемых пользователем ячейках могут находиться значения конкретных многомерных показателей либо их агрегированные в соответствии с выбранной иерархией таблицы значения. В последнем случае происходит автоматическое определение входящих в агрегат аргументов для дальнейшего динамического формирования ограничения, включаемого в Н-модель. Это существенно упрощает работу с Н-моделями большой размерности. Основной особенностью данного метода является автоматическое уточнение всех связанных с измененной величиной интервальных Н-переменных. Рассмотрим пример использования пред- ложенного метода для анализа прогнозных показателей деятельности компании, вычисляемых с помощью метода Н-моделей. С каждым из моделируемых показателей связана Н-переменная, способная уточняться при поступлении дополнительных условий. По математической форме ограничения в Н-модели в общем случае могут иметь вид смеси линейных и нелинейных уравнений и неравенств, логических условий (например, условий типа «если… то…») и условий максимума либо минимума. Также возможны ограничения в виде неявных функций.
Важной функциональной возможностью для анализа многомерных данных является применение фильтров по значениям атрибутов и Н-переменных. Фильтрация может производиться по значениям из различных таблиц БД, значениям Н-переменных, а также дополнительным мерам, определяемым с помощью языка DAX. В последнем случае мера может быть функцией от нижней и верхней границ Н-переменной, например, модулем их разности. Это позволяет учитывать ширину интервала недоопределенности и отображать только нужные для анализа показатели. На рисунке 2 представлена экранная форма модели с использованием данной возможности. Фильтрация осуществляется по категории продукта, а затем и по минимальному значению интересующего недоопределенного показателя уровня продаж (ПродажиМин). В данном отчете значения этого показателя выводятся только для заданной категории продуктов и каналов с уровнем продаж выше заданного в фильтре значения.
Перечисленные выше функции интегрируют возможности аналитической обработки OLAP-систем и представления недоопределенных данных в рамках этих систем. Так как процесс работы с Н-моделью обычно заключается в пошаговом уточнении значений показателей модели, эти функции служат для анализа результатов вычислений после очередного уточнения всего набора показателей. Для обеспечения полноценного анализа требуется также наличие функций изменения многомерных показателей с последующим вычислением Н-модели при новых значениях переменных.
Рассмотренные функциональные возможности системы ранее не были реализованы в системах Н-вычислений и являются новыми. Средства пользовательского интерфейса позволяют существенно упростить работу над Н-моделями большой размерности и автоматизировать процесс внесения изменений в модель. Таким образом, разработанный метод многомерного анализа данных на основе Н-вычислений значительно расширяет возможности аналитической обработки не полностью определенных данных в системах OLAP и повышает эффективность применения технологии Н-моделей для обработки многомерных данных. Литература 1. Burdick D., Deshpande P.M., Jayram T.S., Ramakrishnan R. and Vaithyanathan S. OLAP over uncertain and imprecise data // The VLDB Journal. 2007. Vol. 16, № 1, pp. 123–144. 2. Нариньяни А.С. [и др.]. Программирование в ограничениях и недоопределенные модели // Информационные технологии. 1998. № 7. С. 13–22. |
 При загрузке и подготовке используемых для анализа данных применяется компонент Microsoft SQL Server PowerPivot. Подготовка данных требует определения связи между таблицами БД, а для создания дополнительных вычисляемых полей и мер необходимо использовать язык Data Analysis Expressions (DAX). Данный компонент осуществляет сжатие и обработку данных в оперативной памяти, что позволяет получить высокую скорость выполнения операций при больших объемах данных.
При загрузке и подготовке используемых для анализа данных применяется компонент Microsoft SQL Server PowerPivot. Подготовка данных требует определения связи между таблицами БД, а для создания дополнительных вычисляемых полей и мер необходимо использовать язык Data Analysis Expressions (DAX). Данный компонент осуществляет сжатие и обработку данных в оперативной памяти, что позволяет получить высокую скорость выполнения операций при больших объемах данных. Работа с системой осуществляется с помощью традиционного для OLAP интерфейса сводных таблиц, предоставляющего широкие возможности управления видом генерируемых отчетов (рис. 1). Отчет формируется путем выбора полей (атрибутов измерений OLAP-куба), их переноса в область строк, столбцов или значений таблицы, а также применения дополнительных фильтров и выбора срезов куба. Основной особенностью отчета является наличие столбцов, в которых численное значение показателей соответствует нижней и верхней границам Н-переменной. На рисунке 1 представлен пример отчета с прогнозируемыми значениями показателя «Продажи» в разрезе кварталов и каналов продаж. Возможность динамического формирования отчета существенно увеличивает эффективность работы с Н-моделями по сравнению с существующими системами Н-вычислений.
Работа с системой осуществляется с помощью традиционного для OLAP интерфейса сводных таблиц, предоставляющего широкие возможности управления видом генерируемых отчетов (рис. 1). Отчет формируется путем выбора полей (атрибутов измерений OLAP-куба), их переноса в область строк, столбцов или значений таблицы, а также применения дополнительных фильтров и выбора срезов куба. Основной особенностью отчета является наличие столбцов, в которых численное значение показателей соответствует нижней и верхней границам Н-переменной. На рисунке 1 представлен пример отчета с прогнозируемыми значениями показателя «Продажи» в разрезе кварталов и каналов продаж. Возможность динамического формирования отчета существенно увеличивает эффективность работы с Н-моделями по сравнению с существующими системами Н-вычислений.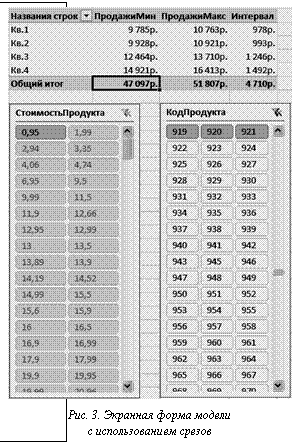 Аналогичную возможность для фильтрации данных предоставляют срезы – элементы интерфейса для выбора подмножества значений, содержащихся в OLAP-кубе (рис. 3). Срезы позволяют включать в рассчитываемые агрегированные значения только элементы с заданными значениями атрибутов.
Аналогичную возможность для фильтрации данных предоставляют срезы – элементы интерфейса для выбора подмножества значений, содержащихся в OLAP-кубе (рис. 3). Срезы позволяют включать в рассчитываемые агрегированные значения только элементы с заданными значениями атрибутов.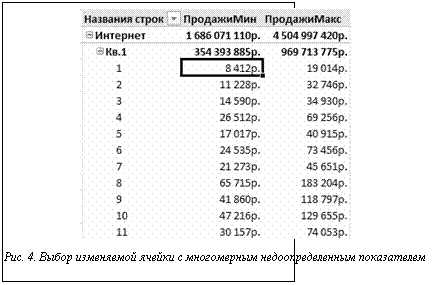 При изменении пользователем значения многомерного показателя активизируется модуль, определяющий, находится ли измененный показатель на листовом уровне в иерархии для данной Н-модели или же является агрегированным значением, зависящим от нескольких переменных (рис. 4). Например, Н-модель может содержать показатели с измерениями «Канал продаж», «Время» и «Продукт». В этом случае выделенная ячейка на рисунке 4 характеризует показатель на листовом уровне иерархии, так как значения всех измерений однозначно заданы. Если выбранная ячейка соответствует суммарному показателю по всем продуктам компании за первый квартал, выполняются определение входящих в сумму переменных и дальнейшая генерация ограничения для Н-модели вида
При изменении пользователем значения многомерного показателя активизируется модуль, определяющий, находится ли измененный показатель на листовом уровне в иерархии для данной Н-модели или же является агрегированным значением, зависящим от нескольких переменных (рис. 4). Например, Н-модель может содержать показатели с измерениями «Канал продаж», «Время» и «Продукт». В этом случае выделенная ячейка на рисунке 4 характеризует показатель на листовом уровне иерархии, так как значения всех измерений однозначно заданы. Если выбранная ячейка соответствует суммарному показателю по всем продуктам компании за первый квартал, выполняются определение входящих в сумму переменных и дальнейшая генерация ограничения для Н-модели вида 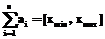 , где в левую часть равенства входят компоненты агрегированного показателя, а в правую – заданные значения измененного в таблице показателя. В случае применения иного способа агрегации (минимум, максимум и др.) ограничение принимает соответствующий вид. С изменяемой ячейкой в Н-модели может быть связано произвольное число ограничений.
, где в левую часть равенства входят компоненты агрегированного показателя, а в правую – заданные значения измененного в таблице показателя. В случае применения иного способа агрегации (минимум, максимум и др.) ограничение принимает соответствующий вид. С изменяемой ячейкой в Н-модели может быть связано произвольное число ограничений.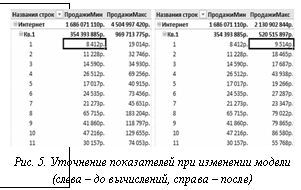 После вычислений Н-модели и обновления таблицы данные становятся доступными для последующей аналитической обработки. На рисунке 5 приведен пример уточнения показателей (уменьшения интервала недоопределенности) при изменении переменных в модели. Так как параметры Н-модели не делятся на входные и выходные, пользователь имеет возможность изменить произвольный многомерный показатель, полученный после выбора некоторого среза куба. При этом происходит сжатие всех интервальных значений переменных в модели. Возможно решение обратных задач: например, после задания требуемого значения прогнозного показателя, относящегося к некоторому промежутку времени, определяются значения остальных параметров Н-модели, необходимые для достижения данной цели.
После вычислений Н-модели и обновления таблицы данные становятся доступными для последующей аналитической обработки. На рисунке 5 приведен пример уточнения показателей (уменьшения интервала недоопределенности) при изменении переменных в модели. Так как параметры Н-модели не делятся на входные и выходные, пользователь имеет возможность изменить произвольный многомерный показатель, полученный после выбора некоторого среза куба. При этом происходит сжатие всех интервальных значений переменных в модели. Возможно решение обратных задач: например, после задания требуемого значения прогнозного показателя, относящегося к некоторому промежутку времени, определяются значения остальных параметров Н-модели, необходимые для достижения данной цели.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2614 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Геоинформационные системы на основе метода недоопределенных вычислений
- Построение OLAP-кубов с помощью стандартных средств разработки web-приложений
- Использование трехмерных кубов данных в реализации системы бизнес-анализа
- OLAP-система для моделирования риска здоровью населения от загрязнения воздуха
Назад, к списку статей