Авторитетность издания

Добавить в закладки
Следующий номер на сайте


формировании электронных учебных курсов
Аннотация:Статья посвящена новой технологии информационной поддержки процесса создания электронных учебных курсов на основе объектной модели управления текстовыми данными.
Abstract:The article focuses on a new concept of information to support the process of creating e-learning courses based on the object model, text data management.
| Автор: Тимченко М.С. (info@jetdraft.com) - Самарский государственный аэрокосмический университет им. академика С.П. Королева | |
| Ключевые слова: технология объектной обработки документов, система обработки текста, электронный учебный курс |
|
| Keywords: the technology of object-processing docu- ments, text processing systems, e-learning course |
|
| Количество просмотров: 10883 |
Версия для печати Выпуск в формате PDF (5.09Мб) Скачать обложку в формате PDF (1.32Мб) |
Основным недостатком текстовых редакторов (процессоров) является низкая автоматизация процесса обработки текста. На практике при необходимости разделить большой документ на части или изменить формат некоторых его составляющих пользователь делает это вручную. К примеру, в документе с определенным количеством предложений для изменения их внешнего вида он самостоятельно выполняет некую последовательность операций для каждого из составляющих документ элементов. Для преодоления этих недостатков был предложен новый принцип обработки данных, основанный на объектной модели управления текстом. Человек, читая текст, воспринимает отдельные символы, используя пробелы, объединяет их в слова, точки воспринимает как разделители предложений, предложения обобщает в главы. Сложность в оперировании машиной текстовыми блоками заключается в том, что при одинаковой логике вариантов компоновки этих блоков бесчисленное множество. Решить эту проблему можно с помощью технологии обработки данных, оперирующей логи- ческими единицами документа – текстовыми объектами, такими как символ, слово, предложение, абзац, глава, раздел. Одной из ее ключевых особенностей является возможность анализа списка правил, предоставляемых пользователем, в соответствии с которыми изменяется внутреннее содержание документа. Чтобы реализовать предложенный метод, необходимо поставить и решить задачу управления многоуровневой иерархической системой данных в электронном документе. Пусть задана модель электронного документа в формате множества символов Q, которые сводятся в таблицу вида q[n, E, L, Cp, Vl], где n – порядковый номер элемента в системе электронного документа; E – номер группы элементов на уровне электронного документа; L – уровень нахождения элемента; l – признак принадлежности элемента (тега) документа к одному из уровней иерархии документа, главы, абзаца, заголовка, текста; Cp – код тега, который сопоставляется с таблицей тегов; Vl – параметр элемента или текстовое значение элемента. Причем всю систему элементов электронного документа можно представить в виде системы взаимоподчиненных элементов, находящихся на различных уровнях r (рис. 1). Всю иерархическую систему электронного документа можно разбить на ряд двухуровневых систем. Выделим двухуровневую иерархическую систему, принадлежащую r–1 и r уровням, r–1ÎR, rÎR, и опишем механизм ее функционирования: Qr, qr–1ÎQr, r, r–1ÎR,
где r – индекс номера уровня иерархического уровня системы Пусть
Векторные критерии, характеризующие эффективность работы программного комплекса обработки данных, представлены в виде набора
где Для qr–1ÎQr–1 набора критериев, определяющих функционирование модели на rÎR уровне, существует замыкающееся на qr–1ÎQr–1 множество индексов подсистем. Общая модель постановки задачи оптимизации, включающая в себя целевую функции и ограничения:
Данная модель относится к классу моделей многокритериальной оптимизации, где в качестве целевой функции оптимизации выступает время обработки данных с учетом ограничений на критерии функционала документа и минимальное количество критериев. Цель каждой системы данных состоит в минимизации критериев времени их обработки, то есть возникает векторная задача многокритериальной оптимизации:
где f – функция оптимизации по критерию kÎK; К – множество критериев оптимизации.
Такие задачи выполняются на нижнем уровне иерархии. Сформулированная модель направлена на решение двух основных проблем: 1) координация управляющих воздействий при обработке взаимоподчиненных элементов, находящихся на различных уровнях иерархии; 2) выработка оптимального решения по многим показателям функционирования системы. Для управляющего множества данных, находящихся на уровне r–1ÎR с соответствующими элементами уровня rÎR, замыкающихся на qr–1ÎQr–1, векторная задача примет вид
Модель управления многомерной иерархической системы данных представлена в виде:
G(X)£T,
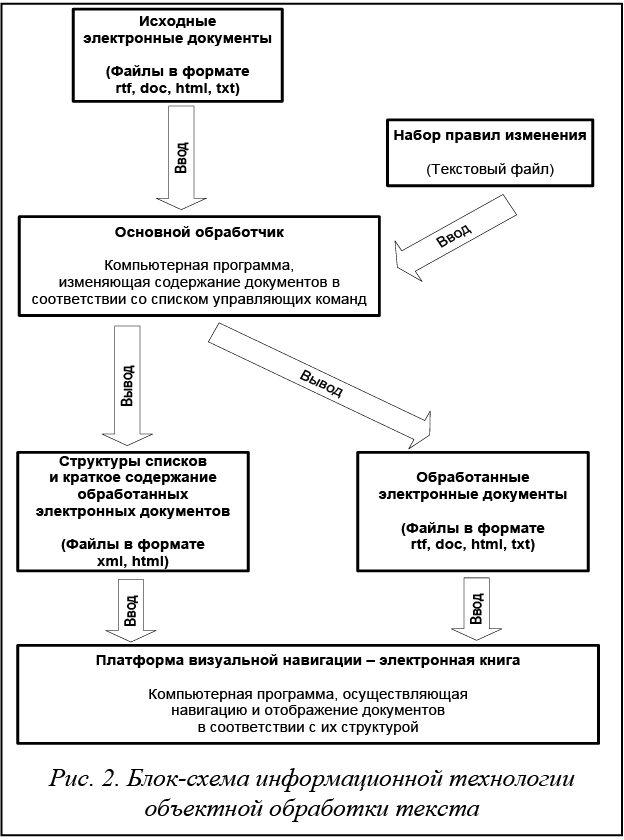
Такая задача относится к классу многовекторных задач математического программирования (R-векторной). Для решения поставленной задачи разработан программный комплекс, схематично представленный на рисунке 2. Обобщенно работу комплекса можно представить в виде трех основных этапов. 1. Пользователь в текстовом виде построчно записывает правила, в соответствии с которыми будет обрабатываться электронный документ. Правила описывают загрузку исходного документа, его изменение и обратную запись на диск. 2. Запускается команда на выполнение написанных правил. 3. Система обрабатывает правила, изменяя содержимое документа.
На выходе – текст в виде файлов или HTML-страниц, служебные данные для быстрой навигации и поиска по обработанным массивам. Пользователь инициирует процесс обработки правил, в ходе которого на экран выводится информация о текущем процессе обработки: количество загруженных документов, сформированные текстовые объекты, выгруженные файлы, дополнительная информация по документам. Выводимая информация представлена в виде отчетов с автоматической группировкой по категориям. По завершении обработки пользователь продолжает работу с документами средствами сторонних производителей или встроенными средствами системы. Результатом является полноценный электронный учебный курс, содержащий страницы ин- формации и их список в форме древовидной структуры, возможность перемещения по содержанию, текстовый поиск, функции добавления закладок. Литература 1. Джеф Р. Интерфейс: новые направления в проектировании компьютерных систем. СПб: Символ-Плюс, 2005. 2. Майоров А.Н. Теория и практика создания тестов для системы образования. М.: Народное образование, 2000. 352 с. 3. Портянкин И. Swing. Эффективные пользователь- ские интерфейсы. Библиотека программиста. СПб: Питер, 2005. 4. Ротштейн А.П., Штовба С.Д. Нечеткая надежность алгоритмических процессов. Винница: Континент-Прим, 1997. 142 с. |
 ,
, ; R – множество индексов уровней системы; qr – индекс номера подсистемы
; R – множество индексов уровней системы; qr – индекс номера подсистемы  уровня
уровня  ; Qr – множество индексов подсистем, находящихся на rÎR уровне; qr–1ÎQr–1 – индекс подсистемы r–1 уровня; Qr–1 – множество индексов подсистем, находящихся на r–1 уровне; эти подсистемы являются управляющими для rÎR уровня;
; Qr – множество индексов подсистем, находящихся на rÎR уровне; qr–1ÎQr–1 – индекс подсистемы r–1 уровня; Qr–1 – множество индексов подсистем, находящихся на r–1 уровне; эти подсистемы являются управляющими для rÎR уровня;  – индекс подсистемы rÎR уровня, замыкающейся на qr–1 подсистему r–1ÎR уровня;
– индекс подсистемы rÎR уровня, замыкающейся на qr–1 подсистему r–1ÎR уровня; 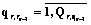 , где q является частью множества главы, абзаца, заголовка, текста;
, где q является частью множества главы, абзаца, заголовка, текста; 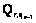 – множество индексов подсистем r уровня, замыкающихся на qr–1 подсистемы.
– множество индексов подсистем r уровня, замыкающихся на qr–1 подсистемы.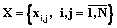 – матрица неизвестных, отображающих элементы структуры списков и краткое содержание электронных документов;
– матрица неизвестных, отображающих элементы структуры списков и краткое содержание электронных документов;  – вектор неизвестных, отображающий элементы структуры списков и краткое содержание электронных документов двухуровневой иерархической системы, верхняя управляющая система которой принадлежит уровню r–1ÎR и определена индексом qr–1ÎQr–1;
– вектор неизвестных, отображающий элементы структуры списков и краткое содержание электронных документов двухуровневой иерархической системы, верхняя управляющая система которой принадлежит уровню r–1ÎR и определена индексом qr–1ÎQr–1;  – вектор неизвестных, отображающий элементы структуры списков и краткое содержание электронных документов двухуровневой иерархической системы уровня rÎR, замыкающейся на qr–1ÎQr–1 уровня r–1ÎR.
– вектор неизвестных, отображающий элементы структуры списков и краткое содержание электронных документов двухуровневой иерархической системы уровня rÎR, замыкающейся на qr–1ÎQr–1 уровня r–1ÎR.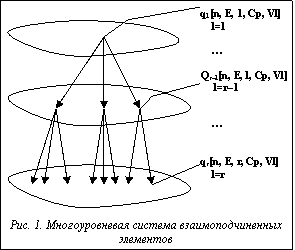 Для модели заданы глобальные ограничения по времени обработки информации, накладываемые на модуль управления иерархической системы электронных данных:
Для модели заданы глобальные ограничения по времени обработки информации, накладываемые на модуль управления иерархической системы электронных данных:  , где
, где  – комплекс данных, расположенных на уровне r–1ÎR; T={ti, iÎR} – нормативы времени, определенные для анализа данных, расположенных на уровне r–1ÎR.
– комплекс данных, расположенных на уровне r–1ÎR; T={ti, iÎR} – нормативы времени, определенные для анализа данных, расположенных на уровне r–1ÎR.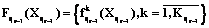 ,
,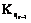 – множество индексов критериев, определяющих функционирование программного комплекса обработки данных, расположенных на уровне qr–1.
– множество индексов критериев, определяющих функционирование программного комплекса обработки данных, расположенных на уровне qr–1.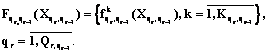

 – функция ограничения по времени (оптимизация).
– функция ограничения по времени (оптимизация).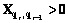 – необходимое минимальное количество критериев.
– необходимое минимальное количество критериев. ,
, ,
,  ,
,  ,
, ,
, 
 ,
,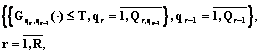

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2719 |
Версия для печати Выпуск в формате PDF (5.09Мб) Скачать обложку в формате PDF (1.32Мб) |
| Статья опубликована в выпуске журнала № 1 за 2011 год. |
Назад, к списку статей