Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Методы обобщающей кластеризации при анализе социальных сетей
Аннотация:Описаны результаты анализа социальных сетей с использованием комбинации различных методов кластериза-ции для получения наиболее полной кластерной структуры, которая в дальнейшем будет использоваться для более сложного анализа сети.
Abstract:In our social network analysis project we use combined clustering techniques in order to obtain meaningful clustering structure, which could be use as a base for different analysis methodologies.
| Автор: Сивоголовко Е.В. (efecca@gmail.com) - Санкт-Петербургский государственный университет | |
| Ключевые слова: оценка качества кластеризации, обобщающая кластеризация, анализ социальных сетей |
|
| Keywords: cluster validity, clustering, social network |
|
| Количество просмотров: 12998 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
При анализе социальных сетей автор ставила перед собой задачу изучить взаимодействие пользователей в сети, а также распространение влияния наиболее авторитетных в том или ином кругу общения пользователей на группу единомышленников и изменение различных групп пользователей с течением времени. В этой работе важная роль базового этапа отведена кластеризации, позволяющей выделить близкие по контексту группы пользователей, которые потом обрабатываются с помощью других методов анализа данных. Цель большинства существующих подходов к кластеризации социальных сетей – построить одну общую модель кластеризации, в которой будет учитываться весь окружающий пользователя контекст. Автор предлагает использовать двухэтапный подход, позволяющий кластеризовать различные семантические контексты по отдельности, а после этого объединять получившиеся структуры в одну конечную структуру классов. Структура данных В работе использованы данные, полученные из социальной сети Facebook специальным приложением, устанавливаемым исключительно по же- ланию пользователя и собирающим как личную информацию со страницы пользователя, так и информацию о его взаимодействии с другими пользователями сети. Такой подход в состоянии обеспечить случайную выборку пользователей, эксперименты на которой можно будет считать объективными. Подробное устройство тестового множества отражено на рисунке. Таким образом, собранную информацию о пользователе можно разделить на три семантические группы: личные (демографические) данные, интересы и взаимоотношения. Заметим, что в группу интересов попадает не то, что указывает пользователь в соответствующем разделе своей личной страницы, а информация о посещаемых им страницах, о группах, в которых он состоит, и о событиях, в которых участвует. Общее количество объектов в полученном множестве данных следующее: пользователей – 12346, групп – 1288, страниц – 2500 и событий – 1053. Кластеризация В силу того, что данные о пользователе зачастую имеют самую различную природу, для учета этого семантического разрыва в характеристиках предлагается применить двухэтапный подход при кластеризации социальной сети. Первый этап – кластеризация данных по отдельным характеристикам. Второй этап – обобщающая кластеризация на основе всех или некоторых кластерных структур, полученных на предыдущем шаге.
Кластеризация для отдельных характеристик. В качестве алгоритма для кластеризации по отдельным характеристикам в данной системе используется DBSCAN как эффективный и достаточно быстрый алгоритм кластеризации, позволяющий находить кластеры произвольной формы, выделять их нужное число и игнорировать выбросы данных [1]. Реализация DBSCAN взята из проекта Weka, в который было добавлено вычисление Manhattan distance между строками. Параметры, используемые при кластеризации демографических характеристик, и количество полученных кластеров приведены в таблице 1. Таблица 1 Кластеризация демографических характеристик
Кластеризация по интересам производилась в два этапа: сначала строилась структура кластеров для групп, событий или страниц, потом на ее основе с учетом отношения принадлежности строились кластеры пользователей. Таким образом, если В качестве меры схожести при кластеризации групп и событий на первом этапе использовалось количество общих пользователей между двумя сравниваемыми объектами. То есть, если Таблица 2 Кластеризация по интересам
Обобщающая кластеризация. В качестве методологии обобщающей кластеризации была использована метакластеризация, или кластеризация кластеров. Пусть есть кластерные структуры
В данной работе для получения обобщающей кластеризации использовалась система GenePatternServer [2]. К сожалению, она написана не самым оптимальным образом: из-за ограничения на оперативную память для получения обобщающей структуры кластеров использовалась только часть характеристик (информация о них приведена в табл. 3). Количественная разница в выборке обусловлена тем, что не для всех пользователей имеется полная информация о возрасте или интересах. Таблица 3 Данные для обобщающей кластеризации
Для запуска GenePatternServer необходимы были следующие параметры: no sampling, SOM (в качестве алгоритма кластеризации) и 500 (в качестве количества итераций для SOM), 5 (максимальное число кластеров в полученной обобщенной структуре). Система GenePatternServer последовательно строит обобщенные структуры кластеров с числом кластеров от двух до некоторого заданного пользователем значения, потом пользователю предоставляется возможность выбрать из полученных структур оптимальную, руководствуясь либо статистическими оценками каждой структуры, посчитанными системой, либо какими-то своими методами оценки качества кластеризации. Результаты обобщающей кластеризации приведены в таблице 4. В колонке «Метки» указываются кластеры отдельных характеристик, которые были объединены в данный метакластер. Просмотрев отдельные составляющие метакластера, аналитик может сделать вывод о его семантике. В работе использовался следующий механизм проставления меток для метакластеров. · Для каждого метакластера входящие в него кластеры отдельных характеристик упорядочивались по количеству пользователей. · Из всех кластеров отбирались те, число пользователей в которых было выше некоторого порогового значения (своего для каждого мета-кластера). · Для всех отобранных кластеров составлялся список страниц, групп или событий, пользователи которых сформировали этот кластер. · Выявление общей составляющей производилось вручную путем анализа названий из полученного на предыдущем шаге списка. К сожалению, два первых кластера оказались слишком разнородными для того, чтобы выделить в них какую-либо направленность, но для остальных трех метки были составлены и указаны в соответствующем столбце таблицы 4. Таблица 4 Обобщающая кластеризация по интересам
Методы оценки Качество кластеризации по отдельным характеристикам. При оценке качества кластеризации по отдельным характеристикам использовалась методология Pooling, которая заключается в следующем. · Случайным образом выбирается 10 % из всех имеющихся кластеров. · Если кластер включает менее 10 элементов, он проверяется целиком, если же более, для проверки случайным образом выбираются 10 элементов плюс еще 10 % от всего кластера. Проверка в данном случае проводилась вручную. При просмотре выбранных элементов семантическое значение кластера определялось по наибольшей подгруппе схожих элементов, и уже относительно их делалось предположение о верном или неверном распределении оставшихся. Мерой качества служила аккуратность кластеризации, вычисляемая по формуле Качество обобщающей кластеризации. Для оценки качества обобщающей кластеризации использовался модифицированный индекс Девиса–Болдуина, перенесенный в пространство схожести [3]. Эта метрика качества достаточно легко вычисляется и показывает хорошие результаты при оценках обобщающей кластеризации. Рассмотрим попарную меру схожести Используем
Центральный элемент
Индекс Девиса–Болдуина в пространстве схожести определяется следующим образом:
где Подытоживая, отметим, что в ходе проекта по анализу социальных сетей [4] была разработана методология двухэтапной кластеризации пользователей. Установлено, что обобщающая кластеризация позволяет выделять более сложные кластерные структуры, чем кластеризация по отдельным характеристикам пользователей, что увеличивает значимость кластеризации для аналитиков сети. К недостаткам данного метода следует отнести длительное время работы, что в данном случае является менее значимым по сравнению с эффективностью техники. Литература 1. Ester M., Kriegel H.-p., Jorg S., and Xu X. Portland. A density-based algorithm for discovering clusters in large spatial databases with noise // Conf. on Knowledge Discovery in Databases and Data Mining, 1996. 2. Duarte F.J. [et al]. On Consensus Clustering Validation. IAPR Int. Conf. on Structural, syntactic and statistical pattern recognition, 2010. 3. Reich M. [et al]. GenePattern 2.0. Nature Genetics 38. 2006. № 5, pp. 500–501. 4. Simoes J. [et al]. Exploring Influence and Interests among Users within Social Networks. Computational Social Networks: Springer-Verlag, 2011. |
 Использование обобщающей кластеризации позволяет преодолеть семантическую разницу между характеристиками и применять различные алгоритмы (или же разные параметры для одного алгоритма) при кластеризации разных характеристик, подбирая для каждой наиболее оптимальный вариант, тем самым улучшая конечную структуру кластеров.
Использование обобщающей кластеризации позволяет преодолеть семантическую разницу между характеристиками и применять различные алгоритмы (или же разные параметры для одного алгоритма) при кластеризации разных характеристик, подбирая для каждой наиболее оптимальный вариант, тем самым улучшая конечную структуру кластеров.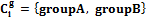 и
и 
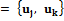 , а
, а 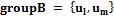 , то
, то 
 . Очевидно, что при таком построении в конечной кластерной структуре пользователей один пользователь может принадлежать нескольким кластерам одновременно. Результаты кластеризации по интересам приведены в табли- це 2.
. Очевидно, что при таком построении в конечной кластерной структуре пользователей один пользователь может принадлежать нескольким кластерам одновременно. Результаты кластеризации по интересам приведены в табли- це 2. и
и  , то, скорее всего, эти объекты близки по смыслу, потому что большое количество людей состоит в них обоих.
, то, скорее всего, эти объекты близки по смыслу, потому что большое количество людей состоит в них обоих. и
и 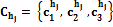 , полученные для характеристик
, полученные для характеристик  и
и  соответственно. Для каждого пользователя
соответственно. Для каждого пользователя 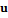 , участвующего хотя бы в одной структуре кластеров, строится характеристический вектор
, участвующего хотя бы в одной структуре кластеров, строится характеристический вектор  размерности
размерности 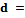
 где N – общее количество кластерных структур. Значение каждой компоненты этого вектора определяется по правилу
где N – общее количество кластерных структур. Значение каждой компоненты этого вектора определяется по правилу

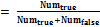 .
.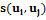 между элементами
между элементами 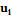 и
и  .
. , где N – количество кластерных структур для создания обобщенной структуры кластеров;
, где N – количество кластерных структур для создания обобщенной структуры кластеров;
 обобщенного кластера
обобщенного кластера 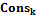 – это элемент с максимальной средней схожестью в кластере:
– это элемент с максимальной средней схожестью в кластере: .
. ,
, – количество кластеров в обобщенной кластерной структуре;
– количество кластеров в обобщенной кластерной структуре; 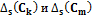 – средняя попарная схожесть в структурах
– средняя попарная схожесть в структурах  соответственно. Малые значения
соответственно. Малые значения  означают, что сходство между элементами из разных кластеров (
означают, что сходство между элементами из разных кластеров ( ) мало, а между элементами, принадлежащими одному и тому же кластеру (
) мало, а между элементами, принадлежащими одному и тому же кластеру (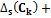
 ), велико. Разбиение, минимизирующее
), велико. Разбиение, минимизирующее | Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2924 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2011 год. [ на стр. 98 – 101 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: