Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Моделирование головы человека по изображениям для систем виртуальной реальности
Аннотация:Описан алгоритм построения синтетической гибкой модели головы человека по изображениям. Предлагаются новый эвристический алгоритм и новая метрика для определения меры сходства построенной формы головы и черт лица на входных фотографиях. Применимость предложенного метода моделирования головы человека по изображениям подтверждена результатами тестирования алгоритма на реальных данных.
Abstract:In this paper we propose a new method for building synthetic flexible model of human head from images. We present a novel heuristic algorithm and new metric for determination of similarity measure of built head model and facial features on input photographs. Applicability of proposed method for human head modeling from images is corroborated by results of experiments on real world data.
| Автор: Федюков М.А. (mfedyukov@graphics.cs.msu.ru) - Московский государственный университет им. М.В. Ломоносова | |
| Ключевые слова: активная модель формы, тонколистовой сплайн, метод нелдера–мида, генетический алгоритм, синтетическая гибкая модель, 3d-реконструкция, машинное зрение |
|
| Keywords: active shape model, thin plate spline, Nelder–Mead method, generic algorithm, synthetic flexible model, 3D-reconstruction, computer vision |
|
| Количество просмотров: 10575 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
Задача моделирования головы человека является актуальной во многих областях: при идентификации, отслеживании, видеокодировании на базе трехмерных моделей, моделировании виртуального присутствия и других. В зависимости от применения моделирование может проводиться с помощью трехмерного лазерного сканера, по стереопаре, по одной фотографии либо по набору изображений – фотографиям или кадрам видеопоследовательности. При постановке задачи реконструкции модели всей головы (а не только лица) с минимальными требованиями к входным данным оптимальным является последний подход. Методы моделирования можно классифицировать и по типу выходных данных. В некоторых работах ими является облако точек. Во многих работах реконструированная форма представляется в виде полигональной модели. Отдельной задачей, ставшей актуальной с развитием систем виртуальной реальности, является реконструкция гибких моделей [1], описывающих форму головы компактным набором параметров. Широко используемыми гибкими моделями являются активные модели формы [2], активные модели внешнего вида [3], морфируемые модели [4], однако все они получены из реальных статистических данных (БД фотографий лиц, БД трехмерных отсканированных моделей лиц). В данной работе рассматривается подход, основанный на синтетических гибких моделях головы. Положительной стороной таких моделей является четкое соответствие морфологическим характеристикам головы человека, таким как расстояние между глазами, пухлость губ или глубина ямочки на подбородке LAD [5]. Как следствие, в зависимости от приложения преимуществами могут являться простота ее редактирования неподготовленным пользователем, возможность работы с ней на уровне возрастных, гендерных или этнотерриториальных морфологических характеристик. Другим преимуществом таких моделей является их компактное представление: в клиент-серверной архитектуре достаточно передать гибкую модель один раз, а впоследствии передавать только набор ее параметров, что ускоряет отправку клиенту нескольких моделей и их анимацию. Сложность работы с такими моделями в невозможности для некоторых входных фотографий реконструировать ряд черт лица с достаточной точностью из-за отсутствия соответствующих параметров в модели. Предлагаемый метод Формализуем общепринятое понятие полигональной модели. Полигональная модель – четверка Распознавание антропометрических точек. Для решения задачи распознавания антропометрических точек лица, таких как центры зрачков и уголки губ, используется модификация метода активной модели формы, в которой в соответствии с поставленной задачей пренебрежем оптимизацией алгоритма по скорости, однако максимизируем точность распознавания характерных точек. В предложенной модификации высокая точность достигается за счет использования двухмерных моделей профилей характерных точек вместо одномерных, увеличения числа собственных векторов, используемых в модели формы, увеличения диапазона допустимых значений параметров на верхнем уровне гауссовой пирамиды изображения, а также за счет расширения набора характерных точек. Тренировка алгоритма производилась на нормальных фотографиях, то есть фотографиях лиц с нейтральными эмоциями, с открытыми глазами, без очков и без объектов, загораживающих часть лица. Инициализация алгоритма активной модели формы осуществляется с помощью метода Виолы–Джонса, показавшего более устойчивое обнаружение нормальных лиц, чем метод Роули. После нахождения антропометрических точек на каждую фотографию проецируется соответствующий набор ломаных: Регистрация фотографий. На данном этапе фотографии как текстурированные прямоугольники располагаются в Построение параметрической модели. На этом шаге положение узлов ломаных Интерполяция неразмеченных вершин. Полученный набор параметров Генерация текстуры. Для генерации текстуры создается полигональная модель В заключение необходимо отметить, что тестирование алгоритма производилось на открытой базе фотографий лиц CVL Face Database, содержащей цветные фотографии анфас и в профиль лиц разных рас и национальностей в возрасте от 18 до 94 лет. Было проведено сравнение предложенного алгоритма с двумя другими алгоритмами моделирования синтетических параметрических моделей, доведенными до уровня коммерческой реализации и позволяющими, таким образом, проведение сравнения на произвольном наборе фотографий: AvMaker, разработанный американской компанией CyberExtruder Inc., работающий с моделью LAD [5], и FaceGen, разработанный канадской компанией Singular Inversions Inc., работающий с собственной синтетической гибкой моделью. Сравнение проведено методом субъективного тестирования, для чего было выбрано 20 пар фотографий, по каждой паре построены модели предложенным методом, а также в системах AvMaker и FaceGen. Для проведения эксперимента был разработан специальный интерфейс, на каждом этапе которого участнику демонстрировалась сначала случайно выбранная пара фотографий с предложением запомнить лицо, затем, на следующем экране – выстроенные в случайном порядке снимки экрана с текстурированными моделями, построенными тремя сравниваемыми алгоритмами, с возможностью поставить каждой модели оценку от 1 до 10. Семнадцати участникам-добровольцам в возрасте от 16 до 48 лет было предложено оценить 20 наборов построенных моделей. Коэффициент согласия между участниками эксперимента рассчитывался как каппа Флайсса, значение которого составило В статье представлен разработанный метод построения синтетической гибкой модели головы человека по набору изображений. Данный подход применим к любым гибким моделям, обладающим описанными свойствами. Литература 1. Cristinacce D. and Cootes T. Automatic feature localisation with constrained local models. Pattern Recognition, 2008. 2. Cootes T. Deformable object modelling and matching. Asian Conference on Computer Vision. Queenstown, New Zealand. 2011. 3. Gao X. [et al.]. A review of active appearance models. IEEE Transactions on Systems, Man, and Cybernetics. Prague, Czech Republic. 2010. 4. Paysan P. [et al.]. A 3D face model for pose and illumination invariant face recognition. IEEE International Conference on Advanced Video and Signal Based Surveillance. Genova, Italy. 2009. 5. Agent appearance definition. URL: http://lib.openmetaverse.org/wiki/AgentSetAppearance (дата обращения: 18.06.2011). |
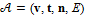 , где
, где 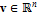 – вектор вершин (пространственных координат),
– вектор вершин (пространственных координат),  ;
;  – вектор текстурных координат,
– вектор текстурных координат, 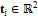 ;
; 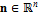 – вектор нормалей,
– вектор нормалей, 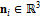 ;
;  – матрица полигонов (треугольников),
– матрица полигонов (треугольников),  ,
,  . Параметрическая модель –
. Параметрическая модель – 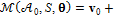
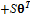 , где
, где  – базовая полигональная модель, задающая координаты вершин по умолчанию,
– базовая полигональная модель, задающая координаты вершин по умолчанию, 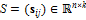 – матрица смещений,
– матрица смещений, 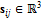 ;
; 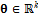 – вектор параметров модели,
– вектор параметров модели,  ,
, 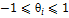 . Решаемая задача заключается в разработке алгоритма, определяющего значения всех параметров
. Решаемая задача заключается в разработке алгоритма, определяющего значения всех параметров 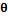 и текстуру по набору из 1–4 фотографий (анфас, в профиль слева, в профиль справа и сзади). Базовая полигональная модель предварительно размечена. Универсальная разметка u
и текстуру по набору из 1–4 фотографий (анфас, в профиль слева, в профиль справа и сзади). Базовая полигональная модель предварительно размечена. Универсальная разметка u  представляет собой набор векторов
представляет собой набор векторов 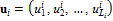 , элементами которых являются индексы
, элементами которых являются индексы 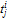 вершин базовой полигональной модели. Таким образом, вектор
вершин базовой полигональной модели. Таким образом, вектор 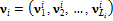 , где
, где 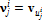 , задает ломаную, узлами которой являются вершины базовой полигональной модели. Каждая ломаная описывает одну характерную черту лица человека, такую как контур глаза, носа, или всей головы. Разметка (и соответствующие ломаные) задана для каждой проекции – анфас, в профиль слева, в профиль справа и сзади. Однако в силу того, что работа с разметкой (и ломаными) на большинстве этапов происходит одинаково для каждой проекции, для упрощения записи, где это возможно, будем писать
, задает ломаную, узлами которой являются вершины базовой полигональной модели. Каждая ломаная описывает одну характерную черту лица человека, такую как контур глаза, носа, или всей головы. Разметка (и соответствующие ломаные) задана для каждой проекции – анфас, в профиль слева, в профиль справа и сзади. Однако в силу того, что работа с разметкой (и ломаными) на большинстве этапов происходит одинаково для каждой проекции, для упрощения записи, где это возможно, будем писать 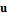 и
и  , не уточняя используемую проекцию.
, не уточняя используемую проекцию.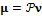 , где
, где  – оператор ортогонального проецирования на координатную плоскость. Узлы спроецированных ломаных, соответствующие найденным характерным точкам, перемещаются в подходящие им координаты. По ним вычисляется матрица аффинного преобразования, с помощью которой перемещаются все остальные узлы каждой ломаной. После этого дополнительно скорректировать положение узлов спроецированных ломаных
– оператор ортогонального проецирования на координатную плоскость. Узлы спроецированных ломаных, соответствующие найденным характерным точкам, перемещаются в подходящие им координаты. По ним вычисляется матрица аффинного преобразования, с помощью которой перемещаются все остальные узлы каждой ломаной. После этого дополнительно скорректировать положение узлов спроецированных ломаных 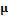 можно вручную. В дальнейшем, не ограничивая общности, будем полагать, что на вход системе подаются две фотографии: анфас и в профиль справа. Работа системы с тремя или четырьмя фотографиями производится аналогично работе с двумя. В случае же подачи системе на вход только фотографии анфас в качестве
можно вручную. В дальнейшем, не ограничивая общности, будем полагать, что на вход системе подаются две фотографии: анфас и в профиль справа. Работа системы с тремя или четырьмя фотографиями производится аналогично работе с двумя. В случае же подачи системе на вход только фотографии анфас в качестве  , корректируются их положение, поворот и масштаб. Полагаем, что плоскость
, корректируются их положение, поворот и масштаб. Полагаем, что плоскость 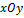 расположена горизонтально, ось
расположена горизонтально, ось  направлена на наблюдателя, ось
направлена на наблюдателя, ось 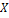 – вправо, ось
– вправо, ось  – вверх. Сначала определяется положение фотографии анфас. Она располагается в плоскости
– вверх. Сначала определяется положение фотографии анфас. Она располагается в плоскости 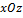 и поворачивается вдоль оси
и поворачивается вдоль оси 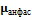 на ней совпадала с осью
на ней совпадала с осью 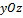 , и ее положение, поворот и масштаб определяются при помощи минимизации среднеквадратичного отклонения вершин, входящих одновременно как в набор ломаных для фотографии анфас
, и ее положение, поворот и масштаб определяются при помощи минимизации среднеквадратичного отклонения вершин, входящих одновременно как в набор ломаных для фотографии анфас 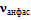 , так и в набор ломаных для фотографии в профиль
, так и в набор ломаных для фотографии в профиль 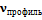 .
.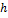 групп таким образом, чтобы в первой группе содержались контуры всего лица и минимальный набор характерных точек всех черт лица, а в остальных
групп таким образом, чтобы в первой группе содержались контуры всего лица и минимальный набор характерных точек всех черт лица, а в остальных 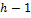 группах содержался контур только одной черты лица. На каждом этапе минимизируется функционал невязки
группах содержался контур только одной черты лица. На каждом этапе минимизируется функционал невязки  , где
, где 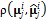 – евклидово расстояние между вершинами фиксированных ломаных
– евклидово расстояние между вершинами фиксированных ломаных  . Минимизация осуществляется грубо/точным алгоритмом: для выполнения грубого этапа используется генетический алгоритм, позволяющий оптимизировать большой набор параметров и избежать попадания в ближайший локальный минимум, точные этапы подгонки отдельных черт лица осуществляются с помощью метода Нелдера–Мида.
. Минимизация осуществляется грубо/точным алгоритмом: для выполнения грубого этапа используется генетический алгоритм, позволяющий оптимизировать большой набор параметров и избежать попадания в ближайший локальный минимум, точные этапы подгонки отдельных черт лица осуществляются с помощью метода Нелдера–Мида. от контуров на входных фотографиях. Однако в зависимости от заданной матрицы смещений
от контуров на входных фотографиях. Однако в зависимости от заданной матрицы смещений 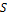 значения функционалов невязки могут быть достаточно большими и получаемая модель
значения функционалов невязки могут быть достаточно большими и получаемая модель  – копия базовой модели
– копия базовой модели  . Затем ломаные на фотографиях
. Затем ломаные на фотографиях 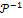 из
из 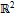 в
в 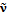 ):
):  ,
, 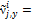
 , а значение z-компоненты восстанавливается из исходной модели:
, а значение z-компоненты восстанавливается из исходной модели: 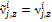 . Подгонка полигональной модели
. Подгонка полигональной модели  вершины, принадлежащие одной черте лица (заданной разметкой
вершины, принадлежащие одной черте лица (заданной разметкой 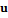 ), перемещаются в соответствующие координаты
), перемещаются в соответствующие координаты 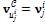 . Кроме того, на каждой итерации перемещаются вершины, лежащие в окрестности
. Кроме того, на каждой итерации перемещаются вершины, лежащие в окрестности 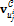 . Окрестность также находится итеративно. Каждой вершине модели
. Окрестность также находится итеративно. Каждой вершине модели  . Изначально вес каждой из вершин равен 0. На первой итерации вес каждой вершины, принадлежащей текущей черте лица,
. Изначально вес каждой из вершин равен 0. На первой итерации вес каждой вершины, принадлежащей текущей черте лица,  перебираются все вершины модели
перебираются все вершины модели 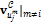 , не принадлежащих черте лица итерации
, не принадлежащих черте лица итерации  , где
, где 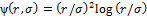 – тонколистовой сплайн, обеспечивающий гладкий вид функции интерполяции;
– тонколистовой сплайн, обеспечивающий гладкий вид функции интерполяции; 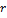 – расстояние между перебираемой и фиксированной вершинами;
– расстояние между перебираемой и фиксированной вершинами; 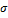 – масштабный коэффициент, характеризующий жесткость сплайна.
– масштабный коэффициент, характеризующий жесткость сплайна.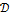 . В случае фотографии анфас значения элементов
. В случае фотографии анфас значения элементов 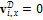 ,
,  ,
,  ,
,  ,
, 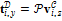 , где
, где 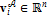 – компоненты вектора пространственных координат (вершин) модели
– компоненты вектора пространственных координат (вершин) модели 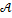 ;
;  – компоненты вектора текстурных координат модели
– компоненты вектора текстурных координат модели  – оператор ортогонального проецирования. Полученная плоская полигональная модель визуализируется в текстуру (в данном случае фронтальную) с помощью растеризации полигонов на графическом процессоре. Аналогично генерируется текстура по фотографии в профиль. Для использования на этапе смешивания текстур генерируется карта нормалей
– оператор ортогонального проецирования. Полученная плоская полигональная модель визуализируется в текстуру (в данном случае фронтальную) с помощью растеризации полигонов на графическом процессоре. Аналогично генерируется текстура по фотографии в профиль. Для использования на этапе смешивания текстур генерируется карта нормалей  модели
модели  , что является почти идеальным согласием по Лэндису–Коху. Усредненная оценка AvMaker составила 0,541, FaceGen – 0,769, предложенного метода – 0,908, что демонстрирует его значительное превосходство над существующими.
, что является почти идеальным согласием по Лэндису–Коху. Усредненная оценка AvMaker составила 0,541, FaceGen – 0,769, предложенного метода – 0,908, что демонстрирует его значительное превосходство над существующими.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2950 |
Версия для печати Выпуск в формате PDF (5.83Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2011 год. [ на стр. 197 – 199 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Реконструкция плоских объектов по изображениям с микроскопа
- Интеллектуальная система прогнозирования на основе методов искусственного интеллекта и статистики
- Генетический алгоритм автоматизированного проектирования подготовительных переходов ковки
- Программный комплекс решения задачи кластеризации
- Решение расширенной логистической задачи с использованием эволюционного алгоритма
Назад, к списку статей