Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Сочетаемостные ограничения в системе автоматического синтаксического анализа
Аннотация:Предложена структура компьютерного словаря сочетаемости, содержащего описания различных типов ограниче-ний на сочетаемость слов. Описан метод, позволяющий использовать словарь сочетаемости для улучшения качества автоматического синтаксического анализа.
Abstract:In this article, we present a kind of computer dictionary which stores different types of selectional preferences. The use of this dictionary enabled us to improve a quality of syntactic analysis.
| Авторы: Мальковский М.Г. (malk@cs.msu.su) - Московский государственный университет им. М.В. Ломоносова, Москва, Россия, доктор физико-математических наук, Арефьев Н.В. (malk@cs.msu.su) - Московский государственный университет им. М.В. Ломоносова | |
| Ключевые слова: ограничения на сочетаемость слов, компьютерный словарь, автоматический синтаксический анализ |
|
| Keywords: selectional preferences, computer dictionary, syntactic analysis |
|
| Количество просмотров: 8698 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
Задача автоматического анализа текстов на естественном языке возникает в самых различных приложениях: машинный перевод, информационный поиск, извлечение фактов из текстов, автоматическое реферирование и др. Для большинства приложений выполнения поверхностного анализа, основанного, например, на поиске ключевых слов, недостаточно – требуется учитывать различные лингвистические явления, в том числе синтаксические отношения. В данной работе рассматривается проблема учета ограничений на сочетаемость слов в процессе автоматического выделения синтаксических отношений в тексте (синтаксического анализа). Описанный в статье подход к решению этой проблемы реализован в системе автоматического синтаксического анализа Treeton, создаваемой на факультете ВМК МГУ [1]. Алгоритм синтаксического анализа, реализованный в Treeton, базируется на идее эвристического перебора, на каждом шаге которого строятся новые синтаксические связи между словами или словосочетаниями анализируемого предложения. С помощью эвристической функции оцениваются как окончательные структуры, покрывающие анализируемое предложение целиком, так и промежуточные, порождаемые на каждом шаге анализа. Отметим, что эвристическая функция в Treeton также называется штрафной, а ее значение – штрафом синтаксической структуры, поскольку это значение тем больше, чем серьезнее нарушение языковых норм структурой. Использование штрафной функции позволяет отбрасывать заведомо ошибочные гипотезы на ранних этапах перебора, а также упорядочивать результаты работы анализатора. В работе [1] предлагалась штрафная функция, учитывающая только топологические свойства оцениваемых структур (штрафовались пересечение стрелок синтаксических связей, большое количество выходящих из одной вершины стрелок и т.п.), при этом не принималось во внимание конкретное лексическое наполнение структур. Как показала практика, такая штрафная функция часто не отличает правильные структуры от неправильных. Например, предложная группа может быть связана как с глаголом, так и с существительным, поэтому для каждой из фраз съесть пирог с черникой, съесть пирог с удовольствием анализатор построит как правильную структуру (пирогàсàчерникой, съестьàсàудовольствием), так и неправильную (съестьàсàчерникой и пирогàсàудовольствием) и, оценивая только топологические свойства, не сможет выбрать нужную. Авторами предлагается новая штрафная функция, учитывающая сочетаемость слов, описанную в специальном компьютерном словаре сочетаемости. В процессе синтаксического анализа при построении новой связи r от слова w1 к слову w2 полученная конструкция w1àrw2 проверяется на соответствие словарной информации. Если в словаре нет описания сочетаемости ни для одного из связанных слов, считается, что оба слова свободно сочетаются с любыми словами, следовательно, конструкция w1àrw2 допустима и не штрафуется. Иначе конструкция проверяется на соответствие приведенным описаниям и в случае несоответствия штрафуется. Таким образом, словарь задает ограничения на сочетаемость слов. Структуры, не соответствующие этим ограничениям, штрафуются, за счет чего правильные структуры получают преимущество при анализе и на выходе анализатора появляются первыми (как по времени, так и по расположению в списке результатов). Структура компьютерного словаря сочетаемости В словаре описываются три типа ограничений сочетаемости слов: морфосинтаксические, лексические и семантические [2]. Ограничения можно представить в виде набора троек (далее используется более наглядная форма записи – S1àr S2), где r – тип синтаксической связи; Si – либо лексема, либо сема (название семантического класса), либо знак «*» (любая лексема). Морфосинтаксические ограничения характеризуют возможные типы исходящих синтаксических связей (например, genet и acc – связи с именной группой соответственно в родительном или винительном падежах), при этом не накладываются ограничения на слова, находящиеся на другом конце связи, поэтому S2=*. Морфосинтаксические ограничения могут быть указаны как для лексем (купитьàacc *), так и для семантических классов (ЕМКОСТЬàgenet *). Лексические и семантические ограничения описывают множества слов, которые могут находиться на конце синтаксической связи. В случае лексических ограничений S1 и S2 – лексемы (букетàgenet вино). В случае семантических ограничений на одном из концов связи (или на обоих) указывается сема (букетàgenet ЦВЕТЫ). Принадлежность слов к семантическим классам и родовидовые отношения между классами также описываются в словаре. Так, можно указать, что астры, розы, васильки – ЦВЕТЫ, тогда словосочетания букет астр / роз / васильков будут считаться допустимыми. Также можно связать родовидовым отношением классы ЦВЕТЫ и РАСТЕНИЯ, тогда сочетаемость класса РАСТЕНИЯ (например, поливатьàacc РАСТЕНИЯ) будет унаследована классом ЦВЕТЫ (станут допустимыми словосочетания поливать астры / розы / васильки). Словарь сочетаемости содержит два типа информации: статистическую и онтологическую. Статистическая информация вносится в словарь в результате автоматического анализа корпуса текстов [3]. Она представляет собой количественные оценки сочетаемости и может использоваться без дополнительной обработки в процессе синтаксического анализа. Онтологическая информация вносится в словарь в процессе работы экспертов (в том числе по обобщению имеющейся статистической информации), а также при импорте данных из существующих словарей. Для эффективного формирования онтологической информации эксперты используют специальные инструменты, помогающие выполнять рутинную работу (поиск примеров в корпусе, выявление похожих по смыслу слов и прочее). Подсистема тестирования синтаксического анализатора позволяет следить за тем, как внесенные в словарь сочетаемости изменения отражаются на качестве работы анализатора. Такой комбинированный подход к описанию сочетаемости позволяет обеспечить изначально широкий охват лексики (который сложно обеспечить вручную), а затем повышать качество синтаксического анализа текстов некоторой предметной области за счет улучшения критичных для качества анализа лингвистических описаний (например, описаний терминов этой предметной области). Отметим, что в текстах разных предметных областей одно и то же слово может иметь разную сочетаемость (например, можно свернуть диалоговое окно, но нельзя его зашторить). Поэтому для достижения наилучших результатов в процессе синтаксического анализа наряду со словарем сочетаемости общей лексики желательно использовать специализированный словарь сочетаемости, сформированный на корпусе текстов той предметной области, которой принадлежат анализируемые тексты. Рассмотрим структуры данных, в которых хранится информация о сочетаемости, – тензор сочетаемости и матрицу семантических классов. Тензор сочетаемости представляет собой тензор третьего ранга, два измерения которого соответствуют лексемам и семантическим классам, а третье – синтаксическим отношениям. В ячейке тензора хранится разнообразная информация о словосочетаниях типа S1àr S2: их частотность в корпусе (обозначим ее через f), оценка меры их неслучайности (p), а также экспертная оценка данного типа словосочетаний (o). Таким образом, в тензоре представлена как статистическая, так и онтологическая информация. Для хранения в тензоре морфосинтаксических ограничений сочетаемости вводится специальное значение третьего измерения «*». Ячейка тензора показывает, допускает ли слово или класс S1 исходящую связь типа r. Не приводя подробных выкладок, отметим, что оценка меры неслучайности вычисляется по следующей формуле: p= Используя тензор сочетаемости, любое слово или класс S1 можно представить в виде вектора с компонентами, соответствующими контекстам (парам rk, Si), в которых встречается слово, а значение соответствующей компоненты равно p (заметим, что в данный вектор можно также включить компоненты, соответствующие входящим связям p). Если ввести расстояние между контекстными векторами [4], появляется возможность численно оценивать смысловую схожесть слов и семантических классов. Эта возможность используется, в частности, для автоматизированного выявления семантических классов (кластеризации слов) [3]. Матрица семантических классов содержит информацию о принадлежности слов семантическим классам и о родовидовых отношениях между классами. Как и в случае с тензором сочетаемости, ячейка матрицы хранит статистическую и онтологическую информацию: оценку вероятности принадлежности слова (или вложенности класса) S классу C (p), вычисленную с использованием контекстных векторов, и экспертную оценку принадлежности (вложенности) по трехбалльной шкале (o). Использование словаря сочетаемости в процессе синтаксического анализа Ограничения сочетаемости слов используются при оценке структур, порождаемых в процессе перебора. Оценка итоговой синтаксической структуры, являющейся вариантом анализа входного предложения, представляет собой норму штрафного вектора, одной из компонент которого является штраф за нарушение структурой ограничений сочетаемости (другие компоненты связаны с топологическими огрничениями). Данный штраф сводится к оценке условных вероятностей конструкций w1àrw2, из которых состоит итоговая структура:
где произведение и сумма берутся по всем входящим в структуру конструкциям w1àrw2. В тех случаях, когда оценка вероятности равна нулю, вместо ее логарифма берется заранее фиксированное достаточно большое число (конструкция сильно штрафуется). Заметим, что введенная штрафная функция обладает свойствами аддитивности и монотонности. Как показано в [5], при использовании штрафной функции с такими свойствами у синтаксического анализатора появляется привлекательная особенность: результаты анализа можно использовать, не дожидаясь окончания работы анализатора (или даже остановив его в любое время), при этом алгоритм гарантирует, что выданные результаты лучше (меньше оштрафованы) всех остальных. Условная вероятность конструкции w1àrw2 складывается из вероятностей наличия исходящей из w1 связи r и нахождения на другом конце связи слова w2:
где максимумы берутся по множеству, включающему в себя как само слово wi, так и всевозможные семантические классы, содержащие wi:
Таким образом, даже если конструкция w1àrw2 ни разу не встретилась в корпусе текстов, она будет признана допустимой, если найдется класс S1 (или S2), содержащий w1 (w2) и сочетающийся с w2 (w1), либо найдется пара сочетающихся классов, один из которых содержит w1, а другой w2. Подводя итог, можно отметить, что на базе рассмотренного в данной статье подхода в системе Treeton был реализован модуль оценки соответствия синтаксических структур описанным в словаре сочетаемости ограничениям, используемый в процессе синтаксического анализа. Для поддержки работы со словарем сочетаемости созданы подсистема сопровождения и развития компьютерных словарей сочетаемости, включающая инструменты автоматического извлечения информации о сочетаемости из корпуса текстов и коррекции этого процесса экспертом, а также подсистема тестирования синтаксического анализатора, позволяющая оценивать качество его работы, визуализировать результаты анализа, выявлять ошибки анализа и устранять их причины (например, ошибочные входы словаря сочетаемости). Литература 1. Мальковский М.Г., Старостин А.С. Система Treeton: Анализ под управлением штрафной функции // Программные продукты и системы. 2009. № 1. С. 33–35. 2. Апресян Ю.Д. Лексическая семантика: 2-е изд.: избран. тр.: Т. 1. М.: Издат. фирма «Восточная лит-ра» РАН, 1995. 472 с. (Языки русской культуры). 3. Арефьев Н.В. Формирование словаря сочетаемости для системы автоматического синтаксического анализа // Научные исследования и их практическое применение. Современное состояние и пути развития ¢2011: Сб. науч. тр. SWorld. Междунар. науч.-практич. конф. Одесса: Черноморье. 2011. Т. 4. С. 35–39. 4. Julie Weeds, David Weir, Diana McCarthy. Characterising measures of lexical distributional similarity // Proceedings of the 20th international conference on Computational Linguistics, COLING-2004. Geneva, Switzerland, pp. 1015–1021. 5. Старостин А.С., Арефьев Н.В., Мальковский М.Г. Синтаксический анализатор «Treevial». Принцип динамического ранжирования гипотез // Компьютерная лингвистика и интеллектуальные технологии: матер. ежегод. Междунар. конф. «Диалог» (26–30 мая 2010 г., Бекасово). М.: Изд-во РГГУ. 2010. Вып. 9 (16). С. 477–490. |
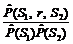 , где
, где 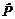 (S1, r, S2) – оценка вероятности появления в тексте словосочетания типа S1àr S2;
(S1, r, S2) – оценка вероятности появления в тексте словосочетания типа S1àr S2; 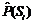 – оценка вероятности появления слова или одного из слов семантического класса Si (ср. с мерой MI [4]). Оценки вероятностей вычисляются как относительные частоты соответствующих событий. Если S1 является семантическим классом, то p обнуляется в том случае, когда менее половины слов класса S1 сочетаются с S2 по связи r (аналогично для S2). Таким образом, семантический класс наследует только общую для входящих в него слов сочетаемость. В ячейках p вместо меры неслучайности хранится оценка условной вероятности
– оценка вероятности появления слова или одного из слов семантического класса Si (ср. с мерой MI [4]). Оценки вероятностей вычисляются как относительные частоты соответствующих событий. Если S1 является семантическим классом, то p обнуляется в том случае, когда менее половины слов класса S1 сочетаются с S2 по связи r (аналогично для S2). Таким образом, семантический класс наследует только общую для входящих в него слов сочетаемость. В ячейках p вместо меры неслучайности хранится оценка условной вероятности  . Для оценки o эксперт использует трехбалльную шкалу: правильно, неправильно, сомнительно. По мнению авторов, трехбалльная шкала оптимальна для подобных задач, поскольку двоичная система (правильно–неправильно) заставляет искусственно сводить сомнительные случаи к одному из двух вариантов, а введение большего числа градаций в отсутствие объективных критериев выбора между ними понижает эффективность работы эксперта, ничего не предлагая взамен.
. Для оценки o эксперт использует трехбалльную шкалу: правильно, неправильно, сомнительно. По мнению авторов, трехбалльная шкала оптимальна для подобных задач, поскольку двоичная система (правильно–неправильно) заставляет искусственно сводить сомнительные случаи к одному из двух вариантов, а введение большего числа градаций в отсутствие объективных критериев выбора между ними понижает эффективность работы эксперта, ничего не предлагая взамен.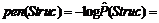
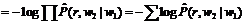 ,
, и оценивается по словарю сочетаемости:
и оценивается по словарю сочетаемости: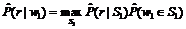 ,
,  ,
, . Оценки вероятностей в правых частях равенств вычисляются исходя из онтологической информации, если она доступна, либо на основе собранной статистики:
. Оценки вероятностей в правых частях равенств вычисляются исходя из онтологической информации, если она доступна, либо на основе собранной статистики: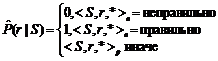
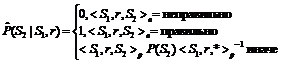
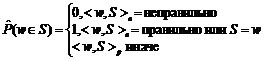
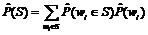 .
.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3007 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
| Статья опубликована в выпуске журнала № 1 за 2012 год. [ на стр. 28 - 31 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: