Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Проблема обнаружения аномалий в наборах временных рядов
Аннотация:Рассматривается проблема обнаружения аномалий в наборах временных рядов. Исследуется случай, когда обу-чающее множество содержит наборы временных рядов единственного класса – положительные примеры. Предлага-ется новый алгоритм, позволяющий эффективно строить критерии для распознавания аномалии во временных ря-дах. Приводятся результаты программного моделирования.
Abstract:A problem of one-class anomaly detection in time series is considered. A new algorithm is proposed, which allows to build criteria for detecting anomalies in time series efficiently.
| Авторы: Антипов С.Г. (antisergey@gmail.com) - Национальный исследовательский университет МЭИ, г. Москва, Фомина М.В. (FominaMV@mpei.ru) - Национальный исследовательский университет «МЭИ» (доцент), Москва, Россия, кандидат технических наук | |
| Ключевые слова: поиск исключений, аномалия, временной ряд |
|
| Keywords: search exception, the anomaly, time series |
|
| Количество просмотров: 14897 |
Версия для печати Выпуск в формате PDF (5.19Мб) Скачать обложку в формате PDF (1.31Мб) |
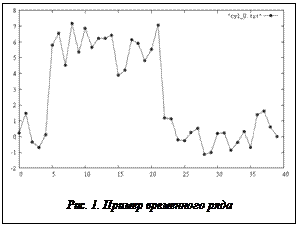
В последнее время большое внимание уделяется анализу временных рядов, которые используются в различных областях и описывают длительные процессы, протекающие во времени. В общем случае временной ряд TS (Time Series) – это упорядоченная последовательность значений TS=, описывающая протекание какого-либо длительного процесса. Значениями tsi могут быть показания датчиков, цены на какой-либо продукт, курс валюты и т.п. На рисунке 1 приведен пример временного ряда, где i-я точка на графике соответствует значению tsi, полученному в момент времени i (время t полагается дискретным).
Аномалия, или выброс, определяется как элемент, явно выделяющийся из набора данных, к которому он принадлежит, и существенно отличающийся от других элементов выборки. Неформально задача определения аномалий в наборах временных рядов ставится следующим образом. Существует коллекция временных рядов, описывающих некоторые процессы, используемая для описания нормального протекания процессов. Требуется на основании имеющихся данных построить модель, которая является обобщенным описанием нормальных процессов и позволяет различать нормальные и аномальные процессы. Обнаружение аномалий в наборах временных рядов Пусть имеется набор объектов, где каждый объект есть временной ряд: TSGOOD= – обучающая выборка. Каждый из временных рядов в обучающей выборке является примером нормального протекания некоторого процесса. На основании анализа временных рядов из TSGOOD необходимо построить модель, позволяющую относить временные ряды из экзаменационной выборки TSTEST= к нормальным рядам или аномалиям на основании некоторого критерия. Рассмотрим данную задачу на простом примере. Пусть обучающая выборка TSGOOD (рис. 2) и экзаменационная выборка TSTEST состоят из трех временных рядов (рис. 3).
В работе рассматривается задача поиска аномалий для случая, когда обучающее множество состоит из примеров единственного класса – положительных. Задача усложняется тем, что набор исходных данных ограничен и не содержит примеров аномальных процессов; также не задан критерий, по которому можно было бы различать нормальные и аномальные временные ряды. В связи с этим трудно точно оценить качество работы алгоритма (процент правильно определенных аномалий, количество ложных срабатываний и пропущенных аномалий). Более того, многие алгоритмы, хорошо показавшие себя на одних наборах данных, совершенно не подходят для других предметных областей. Также может отличаться и критерий, на основании которого определяется нормальность рядов, – в приведенном примере таким критерием была форма ряда (временной ряд вида «П» считался нормальным, отличные от него по форме считались аномалиями). О способах представления временных рядов Для создания алгоритмов обобщения информации, представленной временными рядами, требуется, безусловно, разработка методов предварительного преобразования самих рядов. Временные ряды, представляющие данные из разных областей в различных единицах измерения, следует привести к некоторым типовым, удобным для дальнейшего анализа формам. Для работы с временными рядами предлагается использовать два способа их представления – нормализованное и символьное. Нормализацией назовем приведение временного ряда к такому виду, при котором среднее для него отклонение было бы равно нулю, а среднеквадратичное – единице. Настоящее преобразование является необходимым процессом при предварительной обработке данных [2]. Пример нормализованного ряда приведен в таблице 1. Символьное представление для временного ряда может быть получено из нормализованного с помощью алгоритма Symbolic Aggregate approXimation [2]. Для выполнения такого преобразования вводится алфавит А – конечный набор символов: А={a1, a2, …, a|A|-1}. При создании данного алгоритма сделано допущение о том, что желательно иметь равные вероятности появления символов алфавита A [2]. С этой целью для нормализованного временного ряда ищется упорядоченное множество таких точек B=β0, β1, β2, ..., β|A|-1, β|A| (β0=–∞, β|A|=+∞), которые делили бы область под графиком стандартной нормальной (гауссовой) кривой N(0, 1) на одинаковые площади, равные 1/|A|. Символьное представление для временного ряда TS получается далее по следующему правилу: если очередной элемент tsi меньше β0, то он отображается в первый символ алфавита A, если элемент tsi больше β|A|, то он отображается в последний символ алфавита A. Если же элемент ts попадает в интервал (βk, βk+1), то есть βk≤tsi≤βk+1, то он отображается в символ алфавита, соответствующий данному интервалу. Пример символьного представления (рассматривался алфавит А из 20 символов, A={A, B, C, …, T}) для временного ряда приведен в таблице 1. Таблица 1 Способы представления временных рядов
Алгоритм обнаружения аномалий в наборах временных рядов Как было отмечено выше, критерий, позволяющий выявлять аномалии среди нормальных рядов, от задачи к задаче может меняться. Одним из наиболее универсальных способов обнаружения аномалий при наличии в обучающем множестве примеров единственного класса является использование нейронной сети [1]. Однако сам по себе процесс построения и обучения нейронной сети весьма трудоемок, особенно в условиях ограниченности имеющихся для анализа данных. Поэтому была поставлена задача создать такой алгоритм, который можно было бы использовать для поиска аномалий в наборах временных рядов даже при минимальном наборе данных для обучения. Алгоритм при этом должен быть достаточно простым в применении, но способным эффективно определять аномалии в предъявленных временных рядах. В данной работе предлагается алгоритм TS-ADEEP, который является модификацией алгоритма, основанного на точном описании исключения [3] для определения аномалий в наборах временных рядов. Исходная постановка задачи [3] следующая: для заданного множества объектов I необходимо получить множество-исключение Ix. Для этого на множестве I вводятся: – функция неподобия (dissimilarity) D: P(I)→ →R0+, P(I) – множество всех подмножеств для I; – функция мощности (cardinality) C: P(I)→ →R0+ такая, что для любых I1, I2 – подмножеств I выполняется I1ÌI2→C(I1) – фактор сглаживания (smoothing factor): SF(Ij)=C(I-Ij)*(D(I)–D(Ij)), который вычисляется для каждого IjÍI . Тогда IxÍI является множеством-исключением для I относительно D и C, если его фактор сглаживания SF(Ix) максимален [3]. Данный метод, на основе которого разработан алгоритм TS-ADEEP, был адаптирован для задачи поиска аномалий в наборах временных рядов. В качестве множества I рассматриваются множества I=TSGOODÈTSTestj для каждого TSTestjÍTSTest. Функция неподобия для временных рядов будет задана следующим образом: Сначала вычисляется Функция мощности задается формулой
Формула для вычисления фактора сглаживания имеет прежний вид: SF(Ij)= C(I-Ij)*(D(I)–D(Ij)). Если множество-исключение Ix, построенное для I=TSGOODÈTSTestj, содержит TSTestj, то TSTestj является аномалией для TSGOOD. Приведем псевдокод алгоритма.
Алгоритм TS-ADEEP (TSGOOD: обучающее множество, TSTest: экзаменационное множество) Результат: TSAnom – набор временных рядов-аномалий начало TSAnom=Æ Для j от 1 до |TSTest| нц выбрать TSTestjÍTSTest I=TSGOODÈTSTestj Найти множество-исключение Ix в I Если, TSTestjÎIx, то TSAnom= =TSAnomÈ TSTestj кц вывести TSAnom конец Помимо этого, предлагается следующая модификация для алгоритма поиска исключений: найдя множество-исключение Ix, можно продолжить поиск множества-исключения Ix' уже в нем. Таким образом, этот поиск может производиться до тех пор, пока в исходном множестве три или более элементов. Данная модификация позволяет исключить большое число ложных срабатываний алгоритма определения аномалий, поскольку накладывает более строгое условие на отнесение временного ряда к аномальным. О временных рядах, используемых для моделирования процесса обнаружения аномалий Моделирование процесса обнаружения аномалий было проведено как на искусственных, так и на реальных данных. В качестве искусственных данных взяты классические описания временных рядов, используемые в научной литературе: cylinder-bell-funnel и control chart. В качестве реальных – трафик (использовались данные, собранные с помощью специальных систем анализа трафика при передаче файлов по различным протоколам). Дадим их краткое описание. Сylinder-bell-funnel [4] содержит три различных класса – цилиндр, колокол, воронка. Сontrol chart [5] включает шесть различных классов, описывающих тренды, которые могут присутствовать в процессах: цикличность, уменьшение значения, резкое падение, увеличение значения, постоянная величина, резкое возрастание. Трафик – данные, полученные на основе анализа трафика при передаче файлов по протоколу ftp в различных условиях (в том числе при одновременной передаче нескольких файлов по нескольким протоколам). В качестве тестовых данных, помимо прочих, использовались специальным образом сгенерированные временные ряды, имитирующие передачу данных.
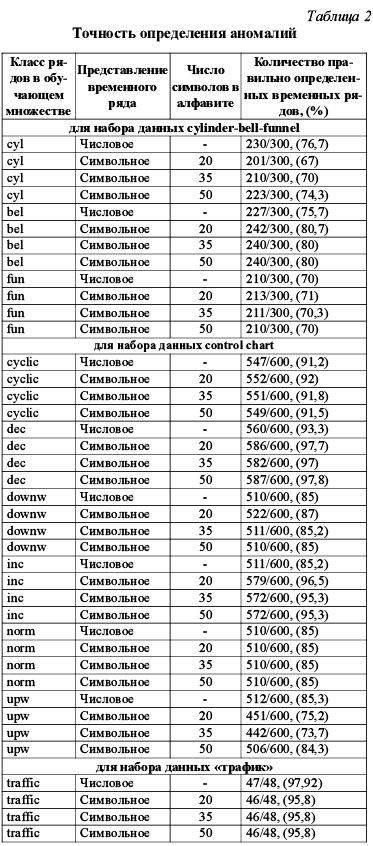
Чтобы определить, насколько хорошо предложенный алгоритм справляется с обнаружением аномалий в наборах временных рядов, было проведено его программное моделирование. Рассмотрим процесс моделирования на примере набора данных cylinder-bell-funnel. Сначала в качестве обучающего множества TSGOOD генерируется набор временных рядов, принадлежащих первому из классов, цилиндр. В качестве экзаменационного множества TSTEST генерируются временные ряды, принадлежащие всем трем классам, – цилиндр, колокол, воронка. Временной ряд TStestj является нормальным, если он принадлежит классу цилиндр, и аномалией, если принадлежит классу колокол или воронка. Соответственно, алгоритм корректно находит аномалии, если он относит временные ряды класса колокол и воронка из TSTEST к аномалиям, а временные ряды класса цилиндр аномалиями не считает. При этом были рассмотрены как численное представление временных рядов, так и символьное с разным размером алфавита. Аналогично проводилось моделирование для классов колокол и воронка. Данные, приведенные в таблице 2, дают возможность оценить результаты распознавания аномалий. Полученные в эксперименте данные позволяют сделать вывод, что предложенный алгоритм успешно решает такую сложную задачу, как поиск аномалий в наборах временных рядов. В заключение необходимо отметить, что в работе рассмотрена задача поиска аномалий среди наборов временных рядов. Предложен непараметрический алгоритм TS-ADEEP для определения аномалий в наборах временных рядов для случая, когда обучающее множество содержит примеры одного класса. Проведено программное модели- рование предложенного алгоритма. Результаты показали, что он успешно справляется с задачей поиска аномалий в наборах временных рядов. В дальнейшем предполагается модифицировать предложенный алгоритм для определения аномалий в наборах временных рядов для случая, когда обучающее множество содержит примеры нескольких классов. Литература 1. Chandola V., Banerjee A. and Kumar V. Anomaly Detection A Survey, ACM Computing Surveys. Vol. 41(3). Article 15, July 2009, pp. 1–72. 2. Lin J., Keogh E., Lonardi S., Chiu B. A Symbolic Representation of Time Series, with Implications for Streaming Algorithms // In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, 2003, pp. 2–11. 3. Arning A., Agrawal R., Raghavan P. A Linear Method for Deviation Detection in Large Databases // In Proceedings of KDD'1996, pp. 164–169. 4. Saito Naoki. Local feature extraction and its application using a library of bases. PhD thesis, Yale University, December 1994. 5. Pham D.T., Chan A.B. Control Chart Pattern Recognition using a New Type of Self Organizing Neural Network // Proc. Instn, Mech, Engrs. Vol. 212. No 1. 1998, pp. 115–127. |
 В данной работе решается задача определения аномалий в наборах временных рядов. Проблема определения, или обнаружения, аномалий [1] была поставлена как задача поиска в наборах данных образцов, не удовлетворяющих предполагаемому типовому поведению. Возможность найти аномалии в некотором наборе данных важна при анализе работы сложных технических систем (например, телеметрии спутников), анализе сетевого трафика, в медицине (анализ снимков МРТ), в банковском деле (анализ транзакций, производимых с помощью кредитных карт) и в других предметных областях.
В данной работе решается задача определения аномалий в наборах временных рядов. Проблема определения, или обнаружения, аномалий [1] была поставлена как задача поиска в наборах данных образцов, не удовлетворяющих предполагаемому типовому поведению. Возможность найти аномалии в некотором наборе данных важна при анализе работы сложных технических систем (например, телеметрии спутников), анализе сетевого трафика, в медицине (анализ снимков МРТ), в банковском деле (анализ транзакций, производимых с помощью кредитных карт) и в других предметных областях.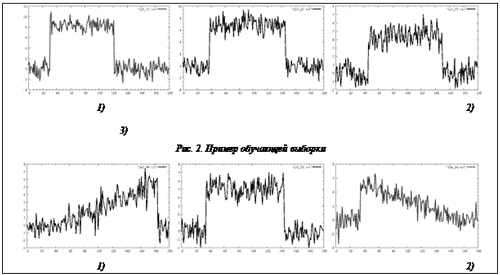
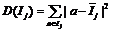 , где
, где 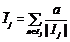 .
.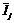 – среднее для векторов из Ij. Функция неподобия вычисляется как сумма квадратов расстояний между средним и векторами из Ij.
– среднее для векторов из Ij. Функция неподобия вычисляется как сумма квадратов расстояний между средним и векторами из Ij.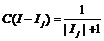 .
.
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3117 |
Версия для печати Выпуск в формате PDF (5.19Мб) Скачать обложку в формате PDF (1.31Мб) |
| Статья опубликована в выпуске журнала № 2 за 2012 год. [ на стр. 79 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Применение нейронных сетей для краткосрочного прогнозирования электропотребления
- Адекватные междисциплинарные модели в прогнозировании временных рядов статистических данных
- Автоматическое детектирование аудиодефектов с применением параллельных вычислений
- Система раннего предупреждения о нарушении показателей качества питьевой воды
- Программный комплекс обнаружения аномалий формы рельсовых путей
Назад, к списку статей