Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Организация эффективных вычислений для расчета электронной структуры больших молекул
Аннотация:Представлены параллельный алгоритм расчета электронной структуры молекул, разработанный на основе мето-да Пальцера–Манолополиса, и его реализация в рамках вычислительной модели передачи сообщений для плотных и разреженных структур данных. Приводятся оценки трудоемкости алгоритма.
Abstract:A parallel modification of Palser-Manolopoulos method for calculation of electronic structure of large molecules based on distributed memory model is described. A parallel algorithm for dense and sparse data structures is developed. It allows to increase calculation efficiency essentially. Estimations for computational complexity are given.
| Авторы: Шамаева О.Ю. (shamayevaoy@mpei.ru) - Национальный исследовательский университет «Московский энергетический институт» (доцент), Москва, Россия, кандидат технических наук, Чернецов А.М. (an@ccas.ru) - Вычислительный центр им. А.А. Дородницына ФИЦ ИУ РАН, Национальный исследовательский университет «Московский энергетический институт» (научный сотрудник, доцент), Москва, Россия, кандидат технических наук | |
| Ключевые слова: разреженная матрица блочно-трехдиагональной структуры, mpi, метод очистки, прямые методы, диагонализация матриц, электронная структура молекул |
|
| Keywords: sparse block-tridiagonal matrix, MPI, purification method, direct methods, matrix diagonalization, electronic molecular structure |
|
| Количество просмотров: 9160 |
Версия для печати Выпуск в формате PDF (5.19Мб) Скачать обложку в формате PDF (1.31Мб) |
Расчеты электронной структуры гигантских молекул являются одними из самых сложных в современной науке и требуют использования высокопроизводительных вычислительных архитектур. Например, вычислительный эксперимент по изучению свойств молекулы октана C8H18 (размер базиса 1 468) на кластере HP, содержащем 1 400 процессоров Itanium 2, потребовал более 23 часов работы. При этом загрузка процессоров составила 75 %, а средняя производительность системы – 6,3 Tflops [1]. Расчеты электронной структуры, в частности, биомолекул (белков, ДНК) и наночастиц, актуальны для химии, биохимии, физики конденсированного состояния вещества и других областей науки. В практическом плане эти расчеты важны для фармакологии, нанотехнологий, исследований явлений сверхпроводимости, разработки квантовых компьютеров. По мнению специалистов компании Intel, компьютер, способный проводить квантово-химические расчеты любой сложности, должен иметь производительность не менее 1 Zettaflops (1021 flops), что значительно превышает потребности в вычислительных ресурсах для таких сложных задач, как аэродинамические расчеты и расчеты в космологии. По прогнозам, такая мощность будет достигнута не ранее 2030 года [2]. Математическая постановка задачи Большинство теорий для определения состояния многоэлектронной системы, имеющей минимальный уровень полной энергии, используют концепцию эффективного одноэлектронного гамильтониана (фокиана), который представляется в виде Таким образом, задача сводится к обработке матрицы размерности N, где N – размерность задачи, пропорциональная числу атомов. Основными методами расчетов электронной структуры молекул являются неэмпирические и полуэмпирические методы квантовой химии [3]. Неэмпирические методы имеют сложность расчета от O(N5) до O(N!), а требования к памяти от O(N3). Для расчета больших молекулярных систем, которые могут содержать от 103 до 107 атомов, целесообразно применение полуэмпирических методов квантовой химии в так называемом приближении нулевого дифференциального перекрывания [3], в общем случае имеющих асимптоти- ческую сложность расчета O(N3). Центральным звеном при расчете молекулярных систем является решение симметричной задачи на собственные значения методом матричной диагонализации. Для расчета физико-химических свойств нужны не сами собственные векторы, а матрица плотности P, являющаяся функцией от них. При нахождении матрицы плотности P начальное приближение матрицы формируется из исходного фокиана F. Фокиан, в свою очередь, строится по определенным правилам на основе декартовых координат атомов, входящих в молекулу [3, 4]. Сложность расчета фокиана для плотных матриц составляет O(N2). Методы расчета Другой путь нахождения P, альтернативный решению задачи на собственные значения, – прямое извлечение P из фокиана. Одним из численных методов прямого нахождения матрицы плотности P является метод очистки (purification method) [5], разработанный еще в 1960 г. Однако в силу отсутствия в то время необходимых вычислительных ресурсов его применение было ограничено расчетом только небольших молекул. В 90-х годах ХХ века на основе этого метода разработаны различные модификации, позволяющие ускорить процесс вычислений. Общая идея использования метода очистки для построения матрицы плотности основывается на итерационном разложении фокиана по непрерывно возрастающему полиному P(x), x Î[0, 1] с зафиксированным экстремумом между 0 и 1, то есть P(0)=0, P(1)=1 и P¢(0)=P¢(1)=0. Можно показать, что вложенная последовательность таких многочленов сходится к ступенчатой функции со ступенькой где-то на [0, 1]. В одной из современных модификаций – методе Пальцера–Манолополиса [5] – итерационная формула для нахождения матрицы плотности P выглядит следующим образом:
где n – номер шага итерационного процесса; P – матрица плотности; tr – след матрицы; cn – коэффициент. Процесс вычислений останавливается при достижении заданной точности по идемпотентности:
Из анализа выражения (1) следует, что основной вклад в вычислительную трудоемкость вносят матричные операции. Для нахождения матрицы плотности P необходимо определить начальное приближение P0, например, как фокиан, нормализованный таким образом, что все его собственные значения Ei лежат на отрезке [-1, 1], то есть
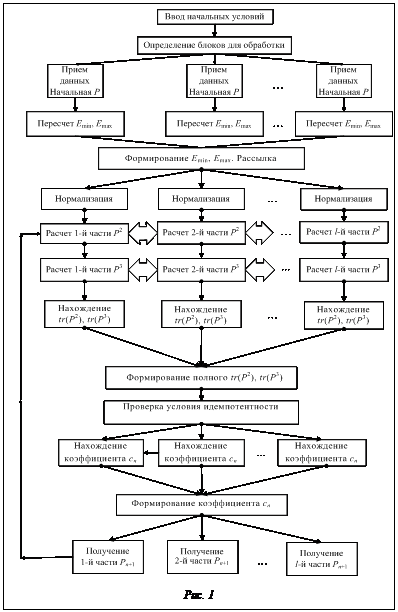
В связи со значительной вычислительной сложностью задачи расчета больших молекулярных систем одним из путей ускорения расчетов является построение эффективных алгоритмов и программ с использованием технологии параллельных вычислений. На рисунке 1 приведена структурная схема параллельного алгоритма расчета по методу Пальцера–Манолополиса, разработанная в рамках модели распределенных вычислений, которая представ- ляет вычисления в виде совокупности взаимо- действующих, последовательно выполняемых процессов. Для организации взаимодействия используются стандартные коммуникационные библиотеки, например MPI (Message Passing Interface). Главный процесс рассылает матрицу исходного фокиана F, затем оценивает минимальное и максимальное собственные значения матрицы. Далее все процессы выполняют параллельную нормализацию фокиана. Для параллельной реализации целесообразно применить блочное умножение матриц, а также провести расчеты этих блоков в разных процессах параллельно. В целом параллельный алгоритм реализован на языке Fortran-90 с использованием средств MPI (Message Passing Interface), а умножение блоков производится с помощью вызова подпрограммы DGEMM из математических библиотек, реализующих стандарт BLAS (Basic Linear Algebra Subroutines).
Разреженная структура матрицы плотности Поскольку при построении математической модели достаточно большого класса молекул возникают массивы данных разреженной структуры, целесообразно использовать это свойство для повышения эффективности расчетов. Свойство разреженности используется для снижения требований к представлению в памяти данных очень больших размеров и сокращения вычислительной сложности алгоритмов обработки матриц. Можно показать, что в общем случае матрицы фокиана F и плотности P являются разреженны- ми [5]. Рассмотрим разреженность матрицы блочно-трехдиагонального вида, которая соответствует описанию достаточно большого класса молекул, а именно полимеров и линейных несвернутых протеинов. Представим блочно-трехдиагональную матрицу:
где A1i, A2i, A3i – матричные, в общем случае плотно заполненные, блоки размерности mi; nbl – число блоков главной диагонали; A1i (i=1, nbl) – матрицы блоков главной диагонали; A2i и A3i (i=1, nbl-1) – соответственно матрицы блоков нижней поддиагонали и верхней наддиагонали. Количество блоков nbl может быть ограничено только доступными ресурсами памяти. Максимальная размерность мелких блоков m=max{mi} (размер m определяется исходя из квантово-химических свойств молекулярной системы). Для эффективной реализации метода Пальцера–Манолополиса в случае представления матрицы фокиана в форме блочно-трехдиагонального вида необходимо организовать эффективное выполнение операций сложения, умножения на число и умножения матриц. При умножении двух блочно-трехдиагональных матриц A и B в матрице результата R появляется четвертая ненулевая блочная диагональ, значениями которой можно пренебречь с точки зрения анализа (расчетов) электронной структуры молекул. Таким образом, матрица R представляется в форме блочно-трехдиагональной. Для представления всех трех матриц A, B, R предлагается специальная схема хранения в виде трехмерных массивов. Тогда элементы матриц имеют три индекса (например Aijk), где первые два соответствуют положению элемента внутри блока, а последний – позиции блока в соответствующей диагонали.
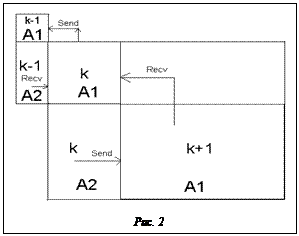
где Аij, Bij – блочные матрицы i-х диагоналей исходных матриц A и B, j – позиция блока в диагонали; Rij – блоки результирующей матрицы. Если учесть, что матрица фокиана F является симметричной и блоки на главной диагонали квадратные, то можно сэкономить память на хранении массивов блоков верхней наддиагонали и после упрощений получить выражения для R:
Факторизованные выражения для первых (R11 и R21) и последних (R1nbl и R2nbl-1) блоков можно получить из общей формулы (3). Вычислительная сложность параллельной обработки разреженных матриц может быть уменьшена за счет оптимального варианта организации обмена блоками. В отличие от реализации метода для плотных матриц нет необходимости рассылать в качестве начальных данных матрицу целиком. Теперь каждый процесс получает только те блоки матриц, которые необходимы для расчетов. По завершении вычислений происходит сбор всех результатов в главном процессе. Следовательно, можно выполнять множество распределенных расчетов. Во-первых, это расчет следа матрицы. Каждый процесс считает только свою часть, а затем главный процесс собирает результаты. Во-вторых, все линейные операции, такие как расчет коэффициентов cn и преобразования матрицы P по формуле (1), можно также вести распределенно. Это позволяет в отдельно взятом процессе выполнять действия по умножению матриц только над теми блоками, которые назначены процессу. Процесс вычислений повторяется итерационно до достижения заданной точности матрицы плотности, определяемой выражением (2). На рисунке 2 представлена схема организации обменов между процессами по типу «точка-точка» (MPI_Send/MPI_Recv) некрайними блоками. Взаимодействие между различными процессами минимально: большая часть вычислений происходит независимо, а данные от других процессов требуются только для пограничных блоков. Более того, на каждой заданной итерации возможно заранее сделать все необходимые пересылки данных и уже затем производить умножение блоков. Для произвольного некрайнего блока в k-м процессе следует получить блок A1 из процесса (k+1) и послать ему блок A2, а также отправить блок A1 из процесса k в процесс (k-1) и получить блок A2 из процесса (k-1). Использование описанных выше схем хранения и организации пересылок в параллельной программе повысило эффективность расчетов и увеличило допустимую размерность решаемой задачи. Так, при обработке плотных матриц в системе с объемом памяти 2 Гб максимальная размерность задачи составляет не более 8 500, а для разреженных матриц – до 150 000 [6]. Оценка трудоемкости параллельной модификации алгоритма с учетом разреженности матриц Оценим вычислительную сложность реализованных параллельных алгоритмов на множестве вычислителей p при следующих предположениях, которые могут быть получены из формулы (3) для Pn+1. Пусть дана вероятность того, что коэффициент cn£½ и cn>½-P{cn£½}=q, P{cn>½}=1-q; u – время аддитивной операции; v – время мультипликативной операции. Так как вычисления распределяются в среднем между вычислителями равномерно, то без ограничения общности положим, что каждый вычислитель обрабатывает одинаковое число блоков. В модели распределенной памяти необходимо учитывать время передач между вычислителями, поэтому введем функцию Fswap(x), которая обозначает взаимную передачу x байтов от одного процесса к другому в случае попарного вызова MPI_Send/MPI_Recv. Тогда ускорение S(p) и эффективность Q(p) на p вычислителях оцениваются [5] как
Таким образом, использование свойств разреженности в сочетании с параллельной модификацией метода Пальцера–Манолополиса позволило существенно увеличить размерность решаемых задач, резко повысило скорость расчетов. Теоретические оценки трудоемкости соответствуют ранее полученным экспериментальным данным [4, 6] и позволяют давать прогнозы о достигаемых значениях ускорения и эффективности на конкретной вычислительной системе. Литература 1. Pollack B.L., Windus T.L., W.A. de Jong, Dixon D.A. Thermodynamic Properties of the C5, C6, and C8 n-Alkanes from AB Initio Electronic Structure Theory // J. Phys. Chem., 2005, Vol. 109. № 31. 2. Pawlowski S. Petascale Computing Research Challenges-A Manycore Perspective, 13th International Symposium on High-Performance Computer Architecture, 2007. URL: http://www2. engr.arizona.edu/~hpca/slides/2007_HPCA_Pawlowski.pdf (дата обращения: 19.09.2011). 3. Степанов Н.Ф. Квантовая механика и квантовая химия. М.: Мир, 2001. 518 с. 4. Чернецов А.М., Шамаева О.Ю. О параллельной реализации алгоритмов расчета электронной структуры больших молекул // Вестн. МЭИ. 2009. № 3. С. 67–71. 5. Niklasson A.M.N., Tymczak C.J., Challacombe M. Trace resetting density matrix purification in O(N) self-consistent-field theory // J. Chem. Phys., 2003. Vol. 118. № 15. 6. Chernetsov A., Shamayeva O. Problems of Parallel Realization of Algorithms of Electronic Structure of Large Molecules //Proceedings of International Conference on Dependability of Computer Systems Depcos-RELCOMEX // IEEE Computer Society. Szklarska Poreba, Poland, 2008. 26–28 June, pp. 324–331. |
 , где v – оператор потенциальной энергии; "2– оператор Лапласа; r – радиус-вектор. При этом возникает задача на собственные значения: HYi=ei Yi, где i нумерует собственные значения и соответствующие собственные векторы.
, где v – оператор потенциальной энергии; "2– оператор Лапласа; r – радиус-вектор. При этом возникает задача на собственные значения: HYi=ei Yi, где i нумерует собственные значения и соответствующие собственные векторы.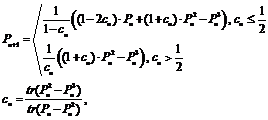 (1)
(1)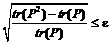 . (2)
. (2)

 В результате получим факторизованные выражения для блоков матрицы R:
В результате получим факторизованные выражения для блоков матрицы R: (3)
(3)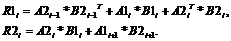
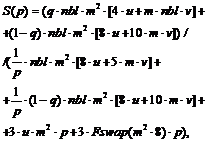
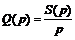 .
.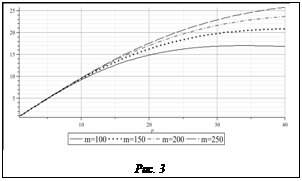 На рисунке 3 приведен график зависимости ускорения от числа процессоров p при использовании разреженности для всевозможных размерностей задачи и значений размерности мелкого блока m. В качестве скорости передачи для функции Fswap(x) взята производительность коммуникационной технологии межсоединения узлов Myrinet 2000 для сообщений подобного размера – 230 Мбайт/с.
На рисунке 3 приведен график зависимости ускорения от числа процессоров p при использовании разреженности для всевозможных размерностей задачи и значений размерности мелкого блока m. В качестве скорости передачи для функции Fswap(x) взята производительность коммуникационной технологии межсоединения узлов Myrinet 2000 для сообщений подобного размера – 230 Мбайт/с.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3119 |
Версия для печати Выпуск в формате PDF (5.19Мб) Скачать обложку в формате PDF (1.31Мб) |
| Статья опубликована в выпуске журнала № 2 за 2012 год. [ на стр. 86 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- HeО: библиотека метаэвристик для задач дискретной оптимизации
- Использование библиотеки MPI для параллельной реализации алгоритма полного перебора вариантов
- Возможности параллельного программирования в математических пакетах
- Поддержка протокола MPI в ядре ОС Linux для многопроцессорных вычислительных комплексов на базе высокоскоростных каналов RapidIO
Назад, к списку статей