Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метаописания и каталогизация научно-информационных ресурсов РАН
Аннотация:Значительная часть научных знаний оформляется в виде электронных ресурсов – баз данных и знаний, электрон-ных справочников и прочего. Работа с электронными ресурсами, включая их адаптацию к предметной области, сис-тематизацию и накопление данных, стала занимать равноправное с теорией и экспериментом положение. Возникли такие дисциплины, как био- и геоинформатика, предмет изучения которых полностью сводится к представлению сложноорганизованных данных. Однако по мере распространения баз данных и аналогичных средств стали нарастать глубокие проблемы, обусловленные неразвитостью интероперабельности. Автономность функционирования ресурсов, многообразие форматов и структур данных, отсутствие стандартов представления – далеко не все факторы, затрудняющие обмен данными. В мировой и отечественной практике в последние годы наметились подходы к возможному разрешению указанных проблем с помощью версий XML-языка, позволяющих стандартизовать систему метаданных и словари понятий в пределах некоторой области знаний, например, версии CML для представления химических данных, MatML – для материаловедения, ThermoML – для термодинамики. Острая необходимость в де-тальной разработке принципов и технологических решений для интеграции многочисленных ресурсов РАН обусловила формирование обширной программы работ по созданию так называемого Data Centre. Предполагается, что реализация этого проекта позволит преодолеть разрозненность и ограниченную доступность компьютерных фондов в виде БД, электронных изданий, информационно-вычислительных средств, поддерживаемых различными институтами РАН. В данной работе в качестве первого этапа интеграции предложена система паспортизации ресурсов, адекватно отражающая предметную область, типологию ресурса, условия доступа и др. Разработан портал, на котором имеется обширный набор метаданных для каждого из зарегистрированных ресурсов.
Abstract:A large part of scientific knowledge is formalized in the form of electronic resources – data and knowledge bases, electronic reference books, etc. Work with electronic resources, including their adaptation to the subject area, systematization and accumulation of data, achieved an equal status with theory and experiment. There appeared such subjects as bio- and geoinformatics, which subject of study is submission of complex data. However, with the spreading of databases and similar means deep problems arose caused by lack of interoperability. Autonomy of resources functioning, diversity of data formats and structures, lack of data presentation standards – not all the reasons complicating the data exchange. In the global and domestic practice in recent years there have been selected approaches to possible resolving problems using versions of XML language, for standardizing of metadata system and terms dictionaries within a certain area of expertise, such as CML versions for submission of chemical data, MatML – for material science, ThermoML – for thermodynamics. An insistent in elaborating principles and technologies for integration of many RAS resources led to the formation of an extensive program on creation of so-called Data Centre. It is expected that this project will help to overcome the fragmentation and limited availability of digital resources in the form of databases, electronic publications, data-processing tools, supported by various institutes of the Russian Academy of Sciences. In this work as the first phase of the integration is offered the system of resources certification, adequately reflecting the subject area, resource types, access conditions, etc. A portal is developed on which there is an extensive set of metadata for each registered resource.
| Авторы: Еркимбаев А.О. () - Объединенный институт высоких температур РАН (ОИВТ РАН), г. Москва, кандидат технических наук, Жижченко А.Б. () - Федеральный исследовательский центр «Информатика и управление» РАН, ул. Вавилова, 44-2, г. Москва, 119333, Россия (зав. отделом), г. Москва, Россия, доктор физико-математических наук, Зицерман В.Ю. () - Объединенный институт высоких температур РАН (ОИВТ РАН), г. Москва, кандидат физико-математических наук, Кобзев Г.А. () - Объединенный институт высоких температур РАН (ОИВТ РАН), г. Москва, доктор физико-математических наук, Серебряков В.А. (serebr@ultimeta.ru) - Вычислительный центр им. А. А. Дородницына РАН (профессор, зав. отделом), Москва, Россия, доктор физико-математических наук, Сотников А.Н. (asotnikov@iscc.ru) - Федеральный исследовательский центр «Информатика и управление» РАН, ул. Вавилова, 44-2, г. Москва, 119333, Россия (главный научный сотрудник), г. Москва, Россия, доктор физико-математических наук, Шиолашвили Л.Н. () - Вычислительный центр им. Дородницына РАН (ВЦ РАН), г. Москва | |
| Ключевые слова: xml., онтоло¬гия, портал, метаописание, метаданные, интеграция данных, информационные ресурсы |
|
| Keywords: XML, ontology, portal, metadescription, metadata, data integration, information resources |
|
| Количество просмотров: 10406 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
В современной науке значительная часть накопленных знаний оформляется в виде электронных ресурсов: баз данных и знаний, электронных справочников и др. По множеству показателей (физический объем, простота обновления, интеграция с аналитическими средствами) они намного превосходят печатные формы в виде справочников, энциклопедий, многотомных руководств и проч. Постепенно работа с информационными ресурсами (ИР), включая их адаптацию к предметной области, систематизацию и накопление данных, во многих сферах стала не менее значимой, чем теория и эксперимент. Возникли даже специальные дисциплины, такие как био- или геоинформатика, предмет которых полностью сводится к представлению сложноорганизованных данных. Однако по мере распространения ИР как в научных организациях, так и среди широкой общественности (образовательный процесс, запросы промышленности и бизнеса) стали нарастать достаточно глубокие проблемы, обесценивающие их потенциал, в основе которых лежит неразвитость интероперабельности, то есть возможности свободного переноса ИР и их содержимого между разными средами. Разрозненность и автономность функционирования ресурсов, безграничное множество форматов и структур данных, отсутствие или неприменение de facto стандартов представления и поддержки ИР – далеко не полный список факторов, затрудняющих доступ и исключающих возможность обмена данными. В мире ИР отсутствует устойчивая система каталогизации, аналогичная сложившейся за века в библиотечном деле и книгоиздании. Проблемой для пользователя становится даже не извлечение необходимой информации, а просто получение сведений о существовании необходимого ресурса, его потенциальных возможностях, условиях доступа и т.п. Указанные проблемы в известной степени присущи ИР любого назначения, хотя каждая область науки и ее внутренние проблемы накладывают свой отпечаток в силу собственных понятийных аппаратов, специфичных данных, требующих определенных форматов представления. Даже в пределах одной или родственных предметных областей (например термодинамика и теплофизика) приходится считаться с многообразием принятых в разных коллективах способов описания, определений констант и функций, единиц измерения и проч. В мировой и отечественной практике в последние годы наметились подходы к возможному разрешению указанных проблем путем интеграции неоднородных ИР с помощью версий XML-языка, позволяющих стандартизовать используемую систему метаданных и словари понятий в пределах некоторой области знаний. Примером подобных решений, неоднократно обсуждаемых в литературе, может быть использование версии CML для представления химических данных, MatML – в материаловедении, ThermoML – в термодинамике [1–3]. Необходимость детальной разработки принципов и технологических решений для интеграции многочисленных ресурсов РАН обусловила формирование обширной программы работ по созданию Data Centre. Предполагается, что реализация этого проекта позволит преодолеть разрозненность и ограниченность доступа к компьютерным фондам в виде БД, электронных изданий, информационно-вычислительных средств, поддерживаемых различными институтами РАН. В самом общем виде под интеграцией ИР понимается их соединение путем унифицированного представления, включая и возможность извлечения интересующей пользователя информации по запросу. Тем самым интеграция освобождает пользователя от необходимости самостоятельно отбирать источники с нужной ему информацией и обращаться к каждому источнику отдельно. Метаданные научно-информационных ресурсов. Чрезвычайные сложности объединения ресурсов при многообразии форматов и структур данных оправдывают в качестве первого шага интеграцию верхнего уровня путем создания специализированного портала, в задачу которого входит поддержка унифицированной системы метаописаний самих ресурсов, адекватно передающих особенность предметной области при различной типологии ресурса. Ранее, руководствуясь этими же соображениями, авторы работ [4, 5] предложили концепцию и технологию хранения наиболее общих данных о структуре научной организации РАН, персональном составе, публикациях, проектах и другой справочной информации. Подобная система (ЕНИП – Единое научное информационное пространство РАН) позволила структурировать множество разнородных данных верхнего уровня, обеспечивая стандартизованное описание, общее для всех отраслей науки. В данной работе сходная концепция положена в основу каталогизации и метаописания ИР. Предполагается, что на портале будут приведены детализированные сведения о ресурсах самой широкой типологии: БД, информационно-вычислительные системы, электронные издания, электронные библиотеки или коллекции, WEB-порталы и т.п. Критериями выделения этой категории научных ресурсов являются их преимущественно информационная направленность (генерация, хранение и распространение данных), происхождение в результате исследовательской деятельности института РАН, электронная форма представления. Понятие ИР расширяет перечень обязательных ресурсов, представляющих, согласно проекту ЕНИП [5], профиль научного института: организация, персоны, подразделения, проекты, публикации. Под метаописанием ИР понимается унифицированное описание, задачи которого следующие: краткое информирование о его содержании, структуре данных и технических характеристиках; обеспечение возможности поиска по множеству критериев; предоставление сведений об условиях доступа, правах пользователя, ценах на услуги и продукты и т.п. В перспективе такое метаописание должно обеспечить переход к более глубокой интеграции ИР путем объединения их метаданных в пределах узких предметных областей. Ключевым моментом является выбор метаданных, описывающих содержимое ресурса в виде набора именованных значений, в том числе указывающих на связи с другими ресурсами. Метаданные формализуют и автоматизируют анализ содержимого, используются при построении поисковых индексов, обеспечивая точность и эффективность поиска разнородной информации. При этом должен быть достигнут компромисс между достаточной структуризацией для охвата множества предметных областей и ограничениями на объем метаданных, связанными с процессом их подготовки при аттестации ресурса. Эффективным способом разрешения компромисса может быть использование Дублинского ядра (Doublin Core, DC) – по многим оценкам, наиболее успешного стандарта метаописания разнородных ресурсов. Хотя исходно проект DC предназначался для более точной, чем это делают поисковые машины, идентификации WEB-ресурсов, его семантика организована так, что может представить практически все виды электронных документов. Принятый из 15 базовых элементов набор дает поверхностную характеристику ресурса, включая содержание, вид и объем, авторство, условия распространения и проч. В дополнение к этому набору имеются инструменты для детализации различных характеристик ресурсов, в том числе и содержания, чтобы адаптировать описание к особенностям предметной области. Существенным моментом при использовании DC является подключение контролируемых словарей понятий с тщательно подобранными терминами. Это значительно улучшает автоматическую обработку, исключая нечеткость описаний, сделанных в стиле, присущем человеку. В качестве словарей могут использоваться общедоступные национальные и международные классификаторы (типа УДК), а также специально разработанные для определенной предметной области, детализирующие содержание ресурса названия и свойства объектов в соответствии с принятыми терминологическими стандартами.
Таблица 1 Предлагаемый перечень метаданных (полей) и их характеристики
Примечание. Сокращения «Опц.», «Повт.», «Контр.» означают, соответственно, опционность, повторяемость и контролируемость поля. В колонке «Опц.» обязательные поля обозначены символом M, опционные (факультативные) – символом O; в других колонках символом Y отмечено наличие требуемого свойства, символом N – его отсутствие. Контролируемые словари и классификаторы. Контролируемый словарь в самом общем понимании – это набор терминов некоторой предметной области и правил их использования для описания информации. Наиболее простая, но часто используемая форма контролируемого словаря – плоский словарь. Чаще всего плоские словари применяются для группировки некоторого набора ключевых терминов и/или наиболее употребляемых фраз с добавлением их расшифровок, определений, описаний. Классификатор (рубрикатор) представляет собой набор терминов (рубрик) и связей между ними, образующих древовидную структуру. Классификаторы используются для тематической или иной классификации ресурсов с целью упрощения их поиска. Заполнение контролируемых полей производится в строгом соответствии с принятым набором классификаторов или нотаций. Для первичного выделения предметной области на портале предложен классификатор РФФИ, который включает все области знаний, относящиеся к естественным и техническим наукам. Строго контролируются и такие атрибуты ресурса, как язык, даты создания и модификации, права доступа и локализация. Контролируемая запись метаданных исключает произвол при аттестации ресурса в отличие, например, от варианта с использованием ключевых слов. Наиболее сложный и ответственный момент – контролируемое назначение метаданных, опре- деляющих предметную область и типологию ресурса в условиях почти неограниченного числа вариантов и возможностей при интеграции академических ресурсов. Для решения этой задачи предложено использовать по два классификатора для обеих характеристик ресурса – предметная область и типология. Так, для выбора предметной области в качестве первого предложен классификатор РФФИ, перекрывающий все области знаний, относящиеся к естественным и техническим наукам (поле 6 в таблице 1). Пример из таблицы 2 показывает возможности классификатора при сужении предметной области в процессе перехода между уровнями классификатора. Таблица 2 Пример использования классификатора РФФИ для выделения предметной области
Как видно из таблицы 1, поле 6 обязательно для заполнения и является поисковым, но при этом дает лишь первую (относительно грубую) характеристику предметной области. В качестве второго классификатора для детализации предметной области можно выбрать любой из отечественных или международных классификаторов, принятых в различных областях знаний, например, PACS, Chemical Abstracts, Medical Subject Headings и т.п. Создатели DC рекомендовали также при характеристике содержания использовать классификаторы общего назначения – классическую классификацию Дьюи или классификацию библиотеки конгресса США. Соответственно в России для этих целей можно применить классификаторы УДК, ГРНТИ, классификатор специальностей ВАК.
Принципиальная возможность двухступенчатой характеризации предметной области (поля 6–8 в таблице 1) не означает, что ее детализация является обязательной. Поля 7, 8 рассматриваются как опционные, что позволяет в принципе ограничиться классификатором РФФИ. В то же время для достаточно специализированных ресурсов (скажем, БД по транспортным свойствам жидких металлов) для точного отнесения не обойтись без дополнительного классификатора типа PACS. Заметим, кстати, что PACS, будучи основной схемой для физических наук, одновременно охватывает множество смежных областей (гео- и биофизика, физическая химия, материалы и т.п.), что позволяет использовать его для широкого спектра естественнонаучных и инженерных дисциплин. Метаданные в позициях 9 и 10 из таблицы 1 предназначены для выделения типа ИР. Как и для характеристики предметной области, здесь предложено использовать два рубрикатора. Обязательным является указание кодов в соответствии с рубрикацией РФФИ (табл. 3). Опционное расширение использует словарь (табл. 4), позволяющий детализировать тип БД с точки зрения содержания (библиография, полные тексты, графика и т.п.), дополняя перечень РФФИ. Таблица 3 Рубрикатор ИР, предусмотренный РФФИ
Таблица 4 Словарь для детализации типов ИР
Онтология. При построении портала использована онтология, разработанная ранее в рамках проекта ЕНИП [4] и написанная на языке OWL. Основные классы онтологии: ИР, персона, организация, словарь «период обновления», словарь «язык», словарь «права доступа», словарь «местонахождение ИР», словарь «тип ИР», классификатор РФФИ, классификатор PACS. ИР, персона и организация являются подклассами класса ресурс (Resource) онтологии ЕНИП. Свойства двух базовых классов в онтологии ЕНИП, персона (Person) и организация (Organization) подробно рассмотрены в [4]. Приведем некоторые сведения для класса ИР (InformationResource), описывающего произвольный научно-информационный ресурс РАН (табл. 5). Свойства класса в основном соответствуют предложенным в таблице 1 полям для идентификации и определения свойств ИР. Используемые здесь словари «период обновления», «язык», «права доступа», «местонахождение ИР», «тип ИР» являются наследниками класса «контролируемый словарь» (VocabularyTerm) онтологии ЕНИП. Для описания плоских контролируемых словарей, предназначенных для группировки некоторого набора терминов, используется VocabularyTerm, являющийся абстрактным базовым классом. Каждый конкретный контролируемый словарь представляется подклассом, а элементами словаря считаются все экземпляры этого подкласса. В конкретный словарь могут быть введены дополнительные свойства элементов словаря, помимо вводимых базовым классом свойств (табл. 6). Таблица 6 Дополнительные свойства элементов словаря
Классы контролируемых словарей: Language – словарь «язык», InformationSystemType – словарь «тип информационного ресурса»; Location – словарь «местонахождение информационного ресурса»; RightAccess – словарь «права доступа»; UpdatePeriod – словарь «период обновления». Для описания иерархических классификаторов используется класс ClassifierTerm, являющийся абстрактным базовым классом. Каждый конкретный классификатор представляется подклассом, а его рубриками считаются все экземпляры этого подкласса. Используемые для описания ИР классификаторы РФФИ и PACS являются наследниками класса ClassifierTerm. Корневыми рубриками считаются те, для которых не указана вышестоящая рубрика. В конкретном словаре могут быть введены дополнительные свойства элементов классификатора, помимо вводимых базовым классом свойств (табл. 7). Таблица 7 Дополнительные свойства элементов классификатора
Примечание. Подклассами классификатора являются PACS и RFFITerm. Практическая работа с порталом. Портал расположен на серверах ОИВТ РАН (http://thermophysics.ru/datacenter) и Data Centre (www.ras.ru/datacenter). Задачами администраторов портала яв- ляются паспортизация ресурсов и открытое предоставление сведений научному сообществу. Включение сведений о ресурсах осуществляется по заявкам, направленным авторами ИР по E-mail администратору портала. В принципе объем сведений должен соответствовать полям, приведенным в таблице 1, и наиболее полно отражать предметную область, тип ресурса, возможности доступа и проч. Само заполнение полей на этапе пробной эксплуатации портала администрация берет на себя. Пользователь, пославший заявку, может внести исправления и дополнения в представленные сведения. На главной странице портала в «Каталоге» можно просмотреть список ИР, зарегистрированных на портале, поле «Рубрикатор» соответствует классификатору РФФИ. Здесь же можно перейти к более детальному классификатору, в качестве которого выбран классификатор PACS. Данный выбор классификаторов позволяет включить достаточно широкий (хотя и неисчерпывающий) перечень областей знаний. В частности, классификатор PACS наряду с физикой охватывает множество смежных областей (физическая химия, материаловедение и т.п.), что позволяет использовать его для широкого спектра ИР, разработанных в РАН. В то же время структура портала дает возможность без существенной перестройки ввести другие классификаторы для более адекватной передачи специфики различных областей знания. Литература 1. Murray-Rust P., Rzepa H.S., Wright M., Zara S.A Universal approach to Web-based Chemistry using XML and CML. ChemComm, 2000, pp. 1471–1472. 2. Kaufman J.G., Begley E.F. MatML. A Data Interchange Markup Laguage // Advanced Materials & Processes. Nov. 2003, pp. 35–36. 3. Еркимбаев А.О., Зицерман В.Ю., Кобзев Г.А., Фокин Л.Р. Логическая структура физико-химических данных. Проблемы стандартизации и обмена численными данными // Журнал физической химии. 2008. Т. 82. № 1. С. 20–31. 4. Бездушный А.А., Бездушный А.Н., Нестеренко А.К., Серебряков В.А., Сысоев Т.М. Возможности технологий ИСИР в поддержке Единого Научного Информационного Пространства РАН // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: сб. докл. 6-й Всеросс. конф. Пущино, 2004. C. 254–262. 5. Бездушный А.А., Бездушный А.Н., Серебряков В.А., Филиппов В.И. Интеграция метаданных единого научного информационного пространства РАН // Науч. изд. ВЦ им. А.А. Дородницына РАН, 2006. |
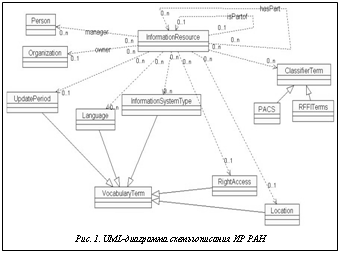 Наряду с международным стандартом DC при разработке метаописания ресурсов РАН использован отечественный стандарт более узкого назначения – ГОСТ 7.70-2003 «Описание баз данных и машиночитаемых информационных массивов». На основе указанных выше стандартов разработан набор метаданных для произвольного научно-информационного ресурса РАН. На рисунке 1 приведена UML-диаграмма схемы описания ИР РАН, где указаны отношения класс–подкласс: UML-связь генерализации – сплошными линиями, а ассоциации между классами – пунктирными линиями. Предлагаемый перечень метаданных (полей) и их характеристики приведены в таблице 1. Каждое из метаданных имеет четыре базовые характеристики: опционность, повторяемость, контролируемость и возможность использования при поиске. Поле считается опционным, если его заполнение необязательно и соответствующее решение принимается лицом, ответственным за поддержание ресурса, в противном случае поле обязательно для заполнения (mandatory). Рекомендуемое число метаданных для описания ресурса составляет 28, всего 14 из которых обязательны для заполнения. Повторяемость поля означает, что при его заполнении возможно задание нескольких реквизитов, каждый из которых при характеристике системы имеет одинаковый статус, а контролируемость – что поле заполняется не произвольно, а согласно записи в определенном словаре или классификаторе; возможно также применение жестких нотаций, например, для обозначения языка, дат и т.п. Последний из признаков (поиск) определяет возможность использования метаданных при поиске. В таблице 1 к таковым относятся метаданные под номерами 1–3 («название системы», «альтернативное название системы», «организация-держатель ресурса»), 5, 6, 8 («ключевые слова», «предметная область», «детализация предметной области») и 19 («создатель/разработчик»).
Наряду с международным стандартом DC при разработке метаописания ресурсов РАН использован отечественный стандарт более узкого назначения – ГОСТ 7.70-2003 «Описание баз данных и машиночитаемых информационных массивов». На основе указанных выше стандартов разработан набор метаданных для произвольного научно-информационного ресурса РАН. На рисунке 1 приведена UML-диаграмма схемы описания ИР РАН, где указаны отношения класс–подкласс: UML-связь генерализации – сплошными линиями, а ассоциации между классами – пунктирными линиями. Предлагаемый перечень метаданных (полей) и их характеристики приведены в таблице 1. Каждое из метаданных имеет четыре базовые характеристики: опционность, повторяемость, контролируемость и возможность использования при поиске. Поле считается опционным, если его заполнение необязательно и соответствующее решение принимается лицом, ответственным за поддержание ресурса, в противном случае поле обязательно для заполнения (mandatory). Рекомендуемое число метаданных для описания ресурса составляет 28, всего 14 из которых обязательны для заполнения. Повторяемость поля означает, что при его заполнении возможно задание нескольких реквизитов, каждый из которых при характеристике системы имеет одинаковый статус, а контролируемость – что поле заполняется не произвольно, а согласно записи в определенном словаре или классификаторе; возможно также применение жестких нотаций, например, для обозначения языка, дат и т.п. Последний из признаков (поиск) определяет возможность использования метаданных при поиске. В таблице 1 к таковым относятся метаданные под номерами 1–3 («название системы», «альтернативное название системы», «организация-держатель ресурса»), 5, 6, 8 («ключевые слова», «предметная область», «детализация предметной области») и 19 («создатель/разработчик»).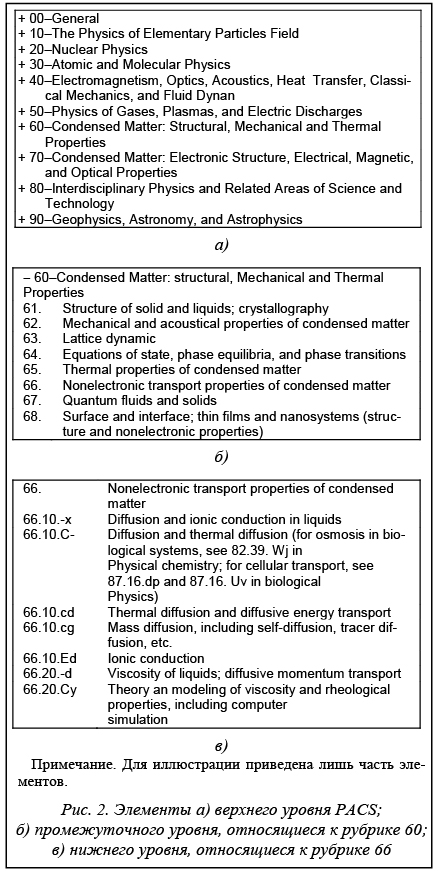
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3226 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
| Статья опубликована в выпуске журнала № 3 за 2012 год. [ на стр. 117-123 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Основные направления развития технологии открытых систем
- Информационная модель семантической библиотеки LibMeta
- Извлечение метаданных из полнотекстовых электронных русскоязычных изданий при помощи Томита-парсера
- Поддержка многокомпонентности в медицинских информационных системах
- Модели как основные артефакты архитектуры информации
Назад, к списку статей