Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Интеграция данных и язык запросов в масштабных информационных инфраструктурах
Аннотация:Автоматизация различных форм профессиональной деятельности с помощью компьютерных технологий порож-дает массивы информации, которые сохраняются в базах данных. Эта информация используется, в первую очередь, внутри учреждений, но может быть полезной для решения важных задач, выходящих за их границы. Создание соот-ветствующих приложений значительно затрудняется при отсутствии специализированных системных средств, на-значение которых – обеспечение доступа к данным из множества баз. В этом направлении, получившем название «интеграция данных», разработаны общие, не зависящие от приложений методы, позволяющие объединять гетеро-генные БД. Созданные на такой основе системы используются на практике, однако проблема их масштабируемости по числу интегрируемых баз остается нерешенной. В статье излагается подход к решению задачи массовой интеграции десятков и сотен БД. Рассматриваются два вопроса, наиболее существенные для таких условий: метод интеграции и форма информационных запросов. Метод интеграции позволяет определить представление (глобальную схему), в котором данные интегрируемых баз образуют единое унифицированное пространство. Метод направлен на создание информационных инфраструктур с динамически меняющимся составом баз: изменение состава не требует модификации глобальной схемы и су-ществующих приложений. Язык поисковых запросов является расширением SQL-92, отличаясь тем, что операции в запросах выполняются над подмножествами баз инфраструктуры. Источники не адресуются явно: для выделения баз используется дескрип-тивная информация – метаатрибуты. Такой способ позволяет создавать приложения, способные обрабатывать данные из различных совокупностей источников.
Abstract:Automation of various forms of professional activity by means of computer technologies generates arrays of information stored in databases. This information is used, first, inside organizations, but can be helpful for solving important tasks outside their borders. Development of the corresponding applications is considerably complicated in the absence of the specialized system tools supporting access to data from multiple databases. In this direction, named data integration, the general, application-independent methods, allowing consolidation of heterogeneous databases are developed. The tools created on such basis are used in practice, however the problem of their scalability on the number of integrated databases remains open. In the paper, an approach to the problem of mass integration (tens and hundred databases) is described. The two questions are considered that seems to be the most essential under these conditions: the method of data integration and the type of informational queries. The integration method allows defining a representation (the global scheme) in which the data of the integrated databases form a common unified space. The method is aimed at the creation of information infrastructures with dynamically changing database set: change of a set does not require modification of the global scheme or existing applications. The language of search queries is an SQL-92 extension, with the difference that the operations are executed on subsets of databases. In addition, databases are not addressed explicitly: descriptive information – meta-attributes – is used for their se-lection. Such type of queries allows creating applications capable of processing data from varied sets of sources.
| Авторы: Коваленко В.Н. (kvn@keldysh.ru) - Институт прикладной математики им. М.В. Келдыша РАН, г. Москва, кандидат физико-математических наук, Куликов А.Ю. (akul87@mail.ru) - Институт прикладной математики им. М.В. Келдыша РАН, г. Москва | |
| Ключевые слова: ogsa-dqp., ogsa-dai, массовая интеграция данных, распределенный запрос, информационный грид |
|
| Keywords: OGSA-DQP, OGSA-DAI, massive data integration, distributed query, informational grid |
|
| Количество просмотров: 6722 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
Задача интеграции БД состоит, как известно, в том, чтобы несколько баз представить в виде одной, объединив содержащиеся в них данные в единое информационное пространство и обеспечив к ним доступ, который не зависит от их физического расположения и способа хранения [1]. Интеграция БД имеет большое практическое значение, так как структурированная информация (или данные), хранимая в них, составляет основу для автоматизации различных видов профессиональной деятельности. В отличие от неформальной информации (текстов, изображений, аудио и видео), на которую ориентирован современный Интернет, для структурированной разработаны не зависящие от ее природы способы представления (реляционная, объектно-ориентированная, XML-модели) и мощный набор операций над массивами данных. СУБД, построенные на этом фундаменте, существенно упростили разработку информационной составляющей приложений для работы с одной БД. Существует и направление интеграции БД, занимающееся созданием инструментария, подобного СУБД, для работы с несколькими БД. Исследования в этом направлении начались почти три десятилетия назад, получены значимые теоретические результаты, реализован ряд систем интеграции, в том числе от ведущих производителей ПО (IBM, Oracle, Microsoft), но проблема остается актуальной и сегодня. Объяснить это можно ростом технических возможностей, в первую очередь, производительности сетевых коммуникаций, на которые опираются технологии интеграции. В настоящее время актуальны сценарии профессиональной деятельности (в сферах государственного и корпоративного управления, планирования и контроля, в областях финансов, торговли, медицины, транспорта и во многих других), в которых требуется оперативное получение достоверной информации из многочисленных источников, функционирующих автономно и слабо связанных друг с другом. С учетом этих потребностей рассмотрим задачу массовой интеграции, когда число интегрируемых БД велико (десятки и сотни единиц) и состав информационной инфраструктуры постоянно меняется. Основные положения интеграции БД На практике информационные приложения, работающие с несколькими источниками данных, создаются с помощью разнообразных средств, таких как оболочки интеграции приложений, интеграционные порталы, метапоисковые машины, однако эти средства не решают проблему управления распределенными данными на уровне, сопоставимом с традиционными СУБД [2].
Общая, не зависящая от приложений архитектура виртуальной интеграции впервые предложена в [3]. Центральным компонентом в этой архитектуре является медиатор, который играет роль посредника между клиентским приложением и СУБД источников (рис. 1). Клиентский интерфейс медиатора предоставляет общую точку ввода запросов к совокупности интегрируемых БД и реализует последовательность их обработки. Обработка запросов осуществляется при взаимодействии медиатора с источниками. Медиатор выполняет ряд функций: преобразование исходного запроса в частичные запросы к отдельным БД, выполнение операций над частичными результатами, обеспечение доступа клиентов к конечному результату запроса. В рамках медиаторной архитектуры получены важные результаты по интеграции гетерогенных БД, которые различаются системами управления, протоколами доступа, а также методами построения плана распределенного выполнения запроса и его оптимизации [4]. С концептуальной точки зрения ключевой проблемой интеграции является интеграция данных. Даже если модели интегрируемых БД одинаковы, их схемы могут различаться, и в разных базах однотипные данные могут быть представлены по-разному. Согласно [1], интеграция данных, находящихся в распределенных источниках, заключается в определении единого пользовательского представления данных, в качестве которого чаще всего используется глобальная схема. В результате интеграции пользователь получает унифицированную структуру данных с унифицированной семантикой ее элементов. Запросы к медиатору формулируются в терминах глобальной схемы, что позволяет, во-первых, абстрагироваться от особенностей отдельных БД и, во-вторых, адресовать с помощью одного элемента глобальной схемы данные, хранящиеся в нескольких базах. Медиатор обрабатывает исходный запрос, преобразуя его в запросы к одному или нескольким источникам в соответствии с их схемами. Методы, используемые для таких преобразований, основаны на определении отображения между элементами глобальной схемы и схем источников. На практике наиболее употребительны два подхода, формальное определение и сравнение которых даются в [1]. И при том, и при другом отображение задается в виде набора правил. При первом подходе (Global As View – GAV) каждое правило отображения ассоциирует один элемент (в реляционной модели – таблицу) глобальной схемы с распределенным запросом к одному или нескольким источникам, которые содержат соответствующие данные. При втором (Local As View – LAV), наоборот, схемы источников определяются через глобальную схему: правило отображения связывает элемент схемы источника с запросом к глобальной схеме. Достоинством подхода GAV является то, что правила отображения прямо определяют преобразование запроса из глобальной схемы в схемы источников, так что алгоритм преобразования фактически сводится к замене глобальных элементов на запросы к источникам. Однако в целом подход эффективен только в случае стабильного состава: добавление нового источника может оказать влияние на определения различных элементов глобальной схемы, в результате соответствующие правила отображения должны корректироваться. В этом отношении преимущество имеет подход LAV: правила отображения определяются независимо для каждого источника, и добавление нового источника означает просто добавление новых правил. С другой стороны, известно, что задача преобразования запросов в LAV является трудной, а алгоритмы подхода имеют высокую вычислительную сложность и ряд ограничений.
Стандартизация удаленного доступа к БД на основе концепции грида Новый этап развития технологий интеграции БД связан с концепцией грида и Web-службами. Важным стимулирующим фактором стали предложения по унификации удаленного доступа к распределенным базам, представленные в семействе спецификаций WS-DAI (Web Service Data Access and Integration) и опирающиеся на стандарты архитектуры грида OGSA и Web-служб. Эти спецификации положены в основу комплекса OGSA-DAI (http://www.ogsadai.org.uk), в котором реализованы программный интерфейс для дистанционного выполнения запросов к СУБД (реляционным и XML) на удаленных ресурсах данных, а также операции передачи данных и их преобразования. Последовательность такого рода действий, заданных в одном составном запросе, позволяет описать совместную обработку данных из нескольких ресурсов. С помощью комплекса OGSA-DAI разработано достаточно много распределенных информационных систем для различных прикладных областей. Кроме того, этот комплекс использовался в качестве базового средства в ряде исследовательских систем интеграции данных (AutoMed, ADMIRE, XMAP, OGSA-WebDB). Востребованность OGSA-DAI свидетельствует о продуктивности применения технологий грида в информационной области. Открытая, основанная на службах архитектура, наличие формально определенных интерфейсов грид- и Web-служб дают возможность создавать модульные распределенные системы выполнения запросов, способствуют повторному использованию функциональных блоков и позволяют встраивать в конвейер обработки новые методы и алгоритмы. В состав комплекса OGSA-DAI входит система OGSA-DQP, реализованная как надстройка над базовой частью и выполняющая интеграцию БД реляционного типа. OGSA-DQP дает более высокий уровень работы с данными: поддерживаются декларативные запросы, соответствующие стандарту SQL-92 с некоторыми ограничениями. Архитектура OGSA-DQP в целом соответствует медиаторной, но есть важное отличие, отвечающее концепции грида (рис. 2). Выполнение запросов в OGSA-DQP происходит не на единственном медиаторе, а на множестве вычислительных ресурсов – серверах OGSA-DAI, количество и состав которых могут определяться динамически. Каждый такой сервер способен выполнять функции медиатора (компиляции запроса, построения плана выполнения, взаимодействия с СУБД). План выполнения строится таким образом, что независимые части запроса распределяются по множеству серверов OGSA-DAI. OGSA-DQP эффективно задействует инфраструктуру вычислительных ресурсов, адаптируя методы параллельных БД – конвейерный параллелизм и параллельное выполнение независимых фрагментов плана. Подобная оптимизация существенно улучшает временные характеристики выполнения запросов. Задача массовой интеграции Представленные подходы и методы реализованы в ряде исследовательских (K2/Kleisli, Garlic, TSIMMIS, DISCO) и коммерческих (Microsoft SQL Server 2008 R2, Oracle Data Integrator, IBM InfoSphere Federation Server) систем, поддерживающих виртуальную и физическую интеграцию БД. Благодаря росту производительности и доступности сетевых коммуникаций использование систем интеграции в практике разработки информационных приложений расширяется. Можно, однако, утверждать, что область применения этих средств остается ограниченной информационными приложениями со стабильным составом информационных источников, что характерно для условий распределенных организаций и устоявшихся коалиций смежных организаций. Предлагаемое в настоящей работе развитие средств интеграции направлено на поддержку динамического формирования масштабных информационных инфраструктур из большого числа БД. Из двух вариантов интеграции такой постановке задачи в большей степени отвечает виртуальная интеграция. Предполагается, что интегрируемые БД автономны, то есть порождение и хранение информации осуществляются средствами локальных СУБД, в связи с чем рассматриваются только запросы поискового характера. Отличие условий виртуальной интеграции в постановке авторов в следующем: – количество интегрируемых БД может быть большим (десятки и сотни единиц); – набор БД, образующих интегрированное информационное пространство данных, в ходе функционирования может динамически меняться; – поддерживаемые системой интеграции поисковые запросы могут получать и комбинировать данные из большого числа БД (такие запросы будем называть массовыми). Для поддержки функционирования масштабных информационных инфраструктур и обработки массовых запросов в ИПМ им. М.В. Келдыша РАН разрабатывается система MQ-DAI (Massive Queries DAI). Применение технологий грида представляется перспективным, и в качестве базы разработки используется система OGSA-DQP. В то же время рассматриваемая постановка задачи требует развития OGSA-DQP и реализованных в ней методов в нескольких направлениях: интеграция данных, оптимизация выполнения запросов, управление информационной инфраструктурой, обеспечение безопасности. В данной работе представлен способ решения вопросов интеграции данных. Работа с данными в условиях масштабных информационных инфраструктур Как основные цели образования масштабных информационных инфраструктур рассматриваются поиск и получение однотипных данных из множества БД, которые их содержат. Наличие однотипных данных характерно для профессиональной сферы: любое учреждение ведет финансовую деятельность и учет персонала – соответствующие данные семантически эквивалентны, то есть имеют одинаковый смысл, хотя и могут представляться в отдельных базах по-разному. Каждое учреждение имеет свою специфику, но учреждения с близкой специализацией собирают семантически эквивалентные данные. В соответствии с этим к способу интеграции данных предъявляются следующие требования. · Работая с масштабной инфраструктурой, пользователь, как правило, не знает, где расположены интересующие его данные и в каком виде они хранятся. Способ интеграции должен обеспечивать, во-первых, такое пользовательское представление, в котором данные образуют единое пространство с унифицированными структурой (глобальной схемой) и семантикой, и, во-вторых, доступ к данным, не зависящий от их размещения. · С точки зрения обслуживания динамически формирующихся инфраструктур критически важно, чтобы добавление/отключение отдельных источников не требовало корректировки определения глобальной схемы. · В аспекте разработки информационных приложений для масштабных инфраструктур существенным представляется требование, чтобы средства интеграции поддерживали разработку приложений, способных обрабатывать данные как из отдельных баз, так и из их произвольной совокупности. Рассмотрим последнее требование подробнее. Прикладная обработка однотипных данных не зависит от того, в каком месте они расположены и в скольких базах хранятся. В условиях масштабных информационных инфраструктур необходимо наделять приложения следующими свойствами. 1. Способность работы с любой БД информационной инфраструктуры. Хотя концепция интеграции БД исходит из того, что приложения не должны зависеть от расположения данных, соотнесение их учреждениям, в которых они порождаются, является естественным. Поэтому одно и то же приложение должно обладать способностью обрабатывать данные из любой отдельной базы по выбору пользователя. Благодаря этому пользователь приложения может с любой периодичностью и без дополнительных действий со стороны персонала учреждения получать, например, агрегированные данные для составления отчетов или детальные данные справочного характера. 2. Способность работы с определенной совокупностью данных информационного пространства. Укажем два вида задач, где требуется поиск информации по множеству БД. Первый вид – поиск информации с неизвестным местонахождением, например, дополнительных сведений о человеке, если есть только его паспортные данные. Результативность поиска в подобных задачах зависит от полноты охвата БД учреждений, которые содержат искомый тип данных. Второй вид задач, в которых необходим аппарат для работы с множествами БД, – получение интегральной информации по их совокупности. Такой информацией могут быть номенклатура выпускаемой продукции определенного назначения, общая численность работников отрасли, средняя зарплата. Важно, чтобы приложения могли работать с произвольной совокупностью баз из информационной инфраструктуры: критериями выделения могут служить тип учреждений, регион, в котором они расположены, ведомственная принадлежность. Заметим также, что и в инфраструктуре автономных БД может быть полезна комбинированная обработка данных из нескольких баз. Хотя автономные БД не имеют прямых связей друг с другом (подобных реализуемым через суррогатные ключи в рамках одной базы), связи могут существовать в виде одинаковых значений данных, в качестве которых выступают общепринятые обозначения, отраслевые стандарты. Таким образом, и в случае автономных БД может применяться оператор связывания JOIN. Метод интеграции данных Предлагаемый метод основан на подходе GAV, но применяется вариант, упрощающий управление глобальной схемой. В подходе GAV правила отображения элементов глобальной схемы в схемы источников имеют вид g→q, где g – элемент глобальной схемы, q – запрос к некоторому числу источников. Обычно в запросе q указываются адреса конкретных источников, поэтому добавление/удаление источника требует корректировки правил отображения. Предложение состоит в том, чтобы данные, соответствующие глобальным элементам, представить в виде совокупности экстентов (аналогичное понятие применяется в системе DISCO [6]), каждый из которых содержит данные только из одной базы, а глобальный элемент является объединением экстентов одного типа. В соответствии с этим глобальные элементы по-прежнему задают унифицированную структуру и семантику однотипных данных, но каждый из них определяется не единственным правилом, а набором правил вида {g→qi, i=1, ..., Ng}, причем каждый запрос qi выполняется в экстенте одного источника, Ng – число экстентов. Заметим, что понятие экстента может быть обобщено так, чтобы запросы qi комбинировали данные из нескольких источников. Правила, относящиеся к разным экстентам и к разным источникам, не зависят друг от друга, так что включение в инфраструктуру нового источника сводится к добавлению правил отображения его экстентов. Сложность корректировки определения глобальной схемы при изменении состава источников получается такой же, как и в подходе LAV, при этом простота интерпретации запросов, присущая подходу GAV, сохраняется. В реляционной модели определения экстентов глобальных таблиц могут быть реализованы в виде пользовательских представлений (VIEW), которые задаются администраторами БД, составляющих инфраструктуру, с помощью запроса языка SQL: CREATE VIEW view [column_name_list ] AS SELECT query. При таком использовании view – имя определяемой глобальной таблицы; column_name_list – список столбцов глобальной таблицы view; query – запрос SELECT к некоторой БД, порождающий таблицу со столбцами column_name_list. Язык массовых запросов Для работы с масштабными инфраструктурами требуется некоторое расширение традиционного языка поисковых запросов. В соответствии с требованиями, сформулированными выше, расширение должно обеспечивать, во-первых, адресацию данных в терминах глобальной схемы и, во-вторых, определение множеств БД, в которых выполняется поиск. Представим структуру обычного SQL-запроса получения данных в следующем виде: SELECT [distinct_condition] select_expressions [ FROM table_expression [WHERE select_conditions] [GROUP BY grouping_conditions] [HAVING having_conditions] [ORDER BY order_conditions] ] Интерес представляет конструкция table_expression, выделенная ключевым словом FROM: в ней определяются области поиска (одна или несколько). В запросах Select, используемых в обычных информационных приложениях, область поиска – это имя таблицы или пользовательского представления. В системе OGSA-DQP поиск и извлечение данных ведутся по нескольким распределенным базам, которые идентифицируются в запросе явным образом: глобальным именем реляционного ресурса, содержащим сетевой адрес (URL) базы. Область поиска в OGSA-DQP задается парой {DB, LT}, где DB – идентификатор ресурса, соответствующего некоторой БД; LT – имя локальной таблицы в этой базе. Вместо имени таблицы LT в OGSA-DQP может указываться имя представления, которое определено в БД, соответствующей ресурсу DB. Как уже было показано, массовые запросы должны позволять работать со всеми интегрированными данными инфраструктуры и с их подмножествами, но форма запросов не может явно зависеть от физического расположения данных. Это достигается за счет использования глобальной схемы и определения поисковой области как группы БД с переменным составом. В массовом запросе предлагается идентифицировать область поиска парой {SP, GT}, где SP – имя группы БД, из которых выбираются данные, соответствующие глобальной таблице GT. Состав группы SP переменный и определяется в приложении. Если состав SP={DB1, DB2, …, DBn}, то имена вида SP.GT интерпретируются как объединение данных типа GT из всех БД группы SP: DB1_GT È DB2_GT … È DBn_GT. Например, при обработке запроса SELECT select_expressions FROM SP.GT заменяется на SELECT select_expressions FROM (DB1_GT È DB2_GT … È DBn_GT) Заметим, что возможны два варианта объединения – Union и Union ALL. Исходя из ранее сказанного получаем, что составляющие группы DBi_GT адресуют экстенты таблицы GT в БД и им соотносятся правила отображения, в которых имя глобальной таблицы GT выступает в качестве имени представления, определенного в БД DBi. Такой вид адресации непосредственно поддерживается системой OGSA-DQP, и подстановка вместо названия группы ее составляющих делает возможной обработку запроса средствами этой системы. Таким образом, массовый запрос отличается от обычного тем, что области поиска в конструкции FROM указываются в форме <имя группы>.<имя глобальной таблицы>. В остальных конструкциях адресация элементов данных имеет вид <имя группы>.<имя глобальной таблицы>.<имя колонки>. Сохраняется возможность опускать лидирующие префиксы при уникальности имени элемента данных. Приведем пример массового запроса, в котором выполняется оператор связывания JOIN между двумя областями поиска: SELECT sp1.people.name, sp1.people.address, sp2.cars.regnumber FROM sp1.people LEFT JOIN sp2.cars ON sp1.people.passport = sp2.cars.ownerpassport WHERE sp1.people.name LIKE ‘%Сидоров%‘ По запросу выполняется поиск владельцев автомобилей, чьи фамилии похожи на ‘Сидоров’. В результате выдаются их Ф.И.О., адреса и регистрационные номера принадлежащих им автомобилей. Поиск ведется по двум областям – sp1 и sp2. Глобальная таблица people содержит паспортные данные людей, таблица cars – регистрационные номера автомобилей и номера паспортов владельцев. Формирование групп БД Состав групп, указанных в запросе, вычисляется непосредственно в процессе его интерпретации. Это дает возможность разрабатывать параметризованные приложения, пользователи которых могут выбирать области поиска непосредственно в ходе работы. При этом не предполагается, что группа задается перечислением ее состава. Определяя группу, пользователь не располагает сведениями об адресах и составе данных отдельных БД (тем более что состав инфраструктуры непостоянен) и может исходить только из содержательной модели информационного пространства. При таких условиях отбор БД для образования группы может осуществляться по содержательным критериям: названиям организаций-владельцев, адресу организации, тематике данных, то есть по метаданным, описывающим источник. Тем самым достигаются две цели: – так как формирование групп происходит при выполнении приложения, их состав соответствует текущему состоянию информационной инфраструктуры: в группы включаются только «живые» БД; – запрос может выполняться как ко всей совокупности данных инфраструктуры, так и к подмножествам БД, в которых существует экстент требуемых данных. Хотя способ отбора БД зависит от приложения и формы его использования, в системной поддержке нуждается представление метаданных. В качестве одного из возможных вариантов рассматривается реляционное представление. Реляционная база метаданных состоит из одной таблицы (она может быть распределенной), содержащей метаатрибуты всех БД инфраструктуры. Для формирования группы предназначены функции отбора баз и определения группы. При обращении к первой функции указывается критерий отбора – это запрос c условиями на значения метаатрибутов. В качестве результата функция отбора возвращает список баз, а вторая функция связывает отобранный список с конкретной группой. При выполнении запросов применяется текущее значение состава группы. Существует и другой способ определения групп путем задания условий на метаатрибуты непосредственно в запросе. Например, запрос SELECT sp1.persons.name FROM sp1.persons WHERE sp1.orgname LIKE ‘%РАН‘ выдает атрибуты name из таблицы persons; состав группы sp1, определяющей область поиска, специфицируется в конструкции WHERE: в группу sp1 включаются БД организаций, в названии (метаатрибут orgname) которых указана принадлежность РАН. В общем случае метаатрибуты могут использоваться в массовых запросах наряду с обычными данными. Однако в отличие от элементов данных метаатрибуты соотносятся не с таблицами, а с группами и идентифицируются в формате <имя группы>.<имя метаатрибута>. В заключение следует отметить, что в статье изложен подход к созданию масштабных информационных инфраструктур путем виртуальной интеграции распределенных автономных БД реляционного типа. Рассмотрен способ использования таких инфраструктур, и предложено расширение языка SQL конструкциями массовых запросов. Реализация подхода в системе MQ-DAI опирается на комплекс OGSA-DAI, в котором наряду с классическими методами обработки распределенных запросов применяются архитектурные принципы грида. Поддержка языка массовых запросов реализована в виде подсистемы управления запросами MQ-DAI. Клиентская часть этой компоненты, оформленная в виде библиотеки классов, используется при разработке приложений и содержит средства для определения областей поиска, формирования и дистанционного выполнения запроса, получения результатов. Серверная часть является надстройкой над комплексом OGSA-DAI: получая массовый запрос, она преобразует его в форму, которая далее интерпретируется базовым комплексом. Помимо подстановки адресов БД, производятся оптимизирующие преобразования, специфичные для массовых запросов, и подготавливается среда выполнения запроса. Поддержка распределенных запросов – не единственная задача, которую необходимо решить для обеспечения работы с масштабными информационными инфраструктурами. MQ-DAI содержит административные средства интеграции данных – описания глобальной схемы и задания правил ее отображения в схемы интегрируемых БД. Среди других задач выделим управление инфраструктурой (включение/отключение БД и вычислительных серверов) и обеспечение безопасности данных на основе прав доступа. Литература 1. Lenzerini M. Data Integration: A Theoretical Perspective. PODS 2002, pp. 233–246. 2. Haas L.M., Lin E.T., Roth M.A. Data integration through database federation. IBM Systems Journal. Vol. 41. Iss. 4 (October 2002), pp. 578–596. 3. Wiederhold G. Mediators in the Architecture of Future Information Systems. IEEE Computer. 1992. № 25 (3), pp. 38–49. 4. Kossmann D. The State of the Art in Distributed Query Processing. ACM Computing Surveys. 2000. № 32 (4), pp. 422–469 (http://www.db.fmi.uni-passau.de/~kossmann). 5. Бездушный А.А. Математическая модель системы интеграции данных на основе онтологий // Вестн. НГУ: Сер. Информационные технологии. Новосибирск, 2008. Т. 6. Вып. 2. С. 15–40. 6. Tomasic A., Raschid L., Valduriez P. Scaling Access to Heterogeneous Data Sources with DISCO. IEEE Trans. Knowl. Data Eng. 1998. № 10 (5), pp. 808–823. |
 В направлении интеграции БД, задачей которого является создание специального аппарата для управления распределенными данными, сформировались два главных подхода – физическая интеграция и виртуальная (или федеративное объе- динение). Физическая интеграция предполагает создание централизованного хранилища и перемещение в него данных из интегрируемых баз. При виртуальной интеграции данные не дублируются, хранятся во множестве распределенных баз, но тем не менее системные средства поддерживают запросы к ним. Ставя задачу массовой интеграции, рассмотрим второй подход – виртуальную интеграцию.
В направлении интеграции БД, задачей которого является создание специального аппарата для управления распределенными данными, сформировались два главных подхода – физическая интеграция и виртуальная (или федеративное объе- динение). Физическая интеграция предполагает создание централизованного хранилища и перемещение в него данных из интегрируемых баз. При виртуальной интеграции данные не дублируются, хранятся во множестве распределенных баз, но тем не менее системные средства поддерживают запросы к ним. Ставя задачу массовой интеграции, рассмотрим второй подход – виртуальную интеграцию.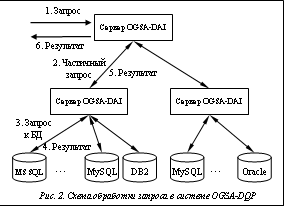 Интеграция данных остается областью активных исследований. В подходах GLAV, BAV отображение между глобальной схемой и схемами источников определяется правилами и типа GAV, и типа LAV. Появились исследования, направленные на отказ от использования централизованной медиаторной архитектуры и глобальной схемы. В подходе распределенной интеграции каждый источник данных полностью автономен, а интеграция достигается путем установления отображений непосредственно между схемами разных источников. Следует также отметить работы по семантической интеграции. В них ставится вопрос о разрешении семантических конфликтов между схемами интегрируемых источников, то есть об автоматизации проектирования глобальной схемы. Ряд результатов по этой проблеме получен отечественными специалистами, использующими онтологическое описание данных (например [5]).
Интеграция данных остается областью активных исследований. В подходах GLAV, BAV отображение между глобальной схемой и схемами источников определяется правилами и типа GAV, и типа LAV. Появились исследования, направленные на отказ от использования централизованной медиаторной архитектуры и глобальной схемы. В подходе распределенной интеграции каждый источник данных полностью автономен, а интеграция достигается путем установления отображений непосредственно между схемами разных источников. Следует также отметить работы по семантической интеграции. В них ставится вопрос о разрешении семантических конфликтов между схемами интегрируемых источников, то есть об автоматизации проектирования глобальной схемы. Ряд результатов по этой проблеме получен отечественными специалистами, использующими онтологическое описание данных (например [5]).| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3227 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
| Статья опубликована в выпуске журнала № 3 за 2012 год. [ на стр. 124-130 ] |
Назад, к списку статей