Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Комбинированный метод автоматического определения тональности текста
Аннотация:Статья посвящена проблеме автоматического анализа тональности текста. Анализ тональности используется для решения многих важных прикладных задач, таких как исследование для коммерческой организации отношения по-требителей к ее продукции или разработка рекомендательной системы для покупателей определенных групп товаров и услуг. Предлагается новый метод определения тональности, комбинирующий результаты работы метода опорных век-торов (SVM) и метода ключевых слов. SVM является широко известным методом классификации, показывающим хорошие результаты при обработке текстовой информации. Метод ключевых слов основан на подсчете весов входя-щих в текст признаков. В качестве признаков используются слова и словосочетания, важность которых оценивается на основе релевантной частоты (Relevance Frequency, RF). Комбинированный метод включает две фазы – обучение и распознавание. На первой фазе на основе размеченной коллекции текстов происходит обучение SVM классификатора и классификатора на базе ключевых слов. На второй фазе результаты распознавания нового текста обоими классификаторами комбинируются и формируется итоговое решение; при этом учитываются степени уверенности классификаторов в своих результатах. Каждый метод классификации, используемый в работе (метод опорных векторов, метод ключевых слов, комби-нированный метод), имеет свой набор параметров. Подбор оптимальных значений параметров классификаторов осуществляется при помощи скользящего контроля. Эффективность комбинированного метода подтверждается экспериментами на текстовой коллекции отзывов о фильмах семинара РОМИП-2011. Для оценки используются метрики точности (precision), полноты (recall), правиль-ности (accuracy) и F1 меры (F1 measure). Значение F1 меры для предлагаемого метода составляет 79 %, что на два процента превосходит лучший результат, полученный в рамках упомянутого семинара.
Abstract:The article is devoted to the problem of automatic text sentiment analysis. Sentiment analysis is used for many important applications, for example, the research for a commercial organization of the relations of customers to its production, or the development of a recommendatory system for the customers of specified groups of goods or services. The new method of text sentiment analysis which combines the results of work of Support Vector Machines (SVM) and Keywords method is suggested in the article. The SVM is a well-known classification method which shows good results on text analysis. The Keywords method is based on the counting of weights of features which the text contains. Words and word combinations, the importance of which is evaluated on the base of Relevance Frequency (RF), are used as features. The combined method contains two phases – training and recognition. On the first phase SVM-classifier and Keywords-classifier are trained on the labeled collection of texts. On the second phase the results of recognition by both classifiers for a new text are combined and the final decision is formed; confidence levels of both classifiers are taken into account. Each of the used methods (SVM, Keyword, combined methods) has its set of parameters. The selection of optimal values of parameters is accomplished with the help of cross-validation. The effectiveness of the combined method is proved experimentally on the text collections of seminar ROMIP-2011. The metrics of precision, recall, accuracy and F1 measure are used for the assessment. F1 measure of the suggested method is equal to 79 %, what is two per cent more than the best result achieved on the seminar ROMIP-2011.
| Авторы: Котельников Е.В. (Kotelnikov.EV@gmail.com) - Вятский государственный гуманитарный университет, г. Киров, Россия, доктор технических наук | |
| Ключевые слова: ромип., метод опорных векторов, текстовая классификация, анализ тональности текста |
|
| Keywords: romip, support vector machines, text categorization, text sentiment analysis |
|
| Количество просмотров: 12262 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
Тональность текста – это выраженное в тексте эмоциональное мнение относительно некоторого объекта (объектов). Тональность можно измерять при помощи шкалы в диапазоне от положительного отношения до отрицательного. Шкала обычно (но необязательно) является дискретной и в зависимости от задачи включает определенное количество значений (классов).
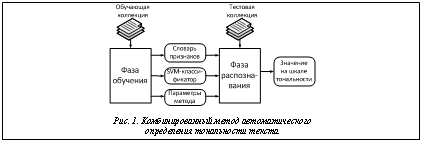
Проблема автоматического анализа текста для определения выраженных в нем эмоциональных отношений (англоязычные термины – Sentiment Analysis, Opinion Mining) оказалась в числе активных научных исследований в начале 21 века [1, 2]. Подробный обзор этого направления исследований дается в [3]. В России публикаций по данной тематике пока крайне мало; правда, в конце 2011 года в рамках семинара по оценке методов информационного поиска РОМИП [4] состоялось тестирование систем по анализу мнений, результаты которого обсуждались на конференции по компьютерной лингвистике Диалог-2012 [5]. В данной работе предлагается комбинированный метод автоматического определения тональности текста, основанный на методе опорных векторов (SVM, Support Vector Machine) и методе ключевых слов. Общая схема метода. Комбинированный метод автоматического определения тональности текста объединяет результаты работы классификатора на основе опорных векторов [6] и классификатора на базе ключевых слов [7]. До начала его применения необходимо задать дискретную шкалу измерения тональности, содержащую M классов. Метод включает две основные фазы – обучение и распознавание (классификацию) (рис. 1). Фаза обучения подразумевает наличие обучающей текстовой коллекции, каждый текст которой помечен определенным значением из диапазона используемой шкалы, то есть задана принадлежность текста к одному из классов. Фаза обучения. Схема фазы обучения показана на рисунке 2 и включает типичные этапы процесса текстовой классификации [8]: предобработку, формирование словарей признаков, взвешивание признаков, формирование векторной модели, обучение SVM-классификатора, настройку параметров. 1. На этапе предобработки все тексты подвергаются одинаковым преобразованиям: выделяются отдельные слова, исключаются однобуквенные слова. Для оставшихся слов определяется словарная форма (в данной работе используется морфологический анализатор mystem от компании Яндекс [9]). В итоге после предобработки каждый текст представляется в виде набора слов в словарной форме. 2. На следующем этапе выделяются множества признаков для задачи определения тональности и на их основе формируется словарь признаков. В качестве признаков в предлагаемом методе используются отдельные слова и словосочетания. В словарь входят все слова и словосочетания, которые встречаются не менее чем в трех текстах после предобработки; длина словосочетаний составляет от двух до пяти слов. (Вопрос о необходимости использования словосочетаний в качестве признаков и их максимальной длины решался в рамках отдельного исследования. Установлено, что введение в словарь словосочетаний повышает качество классификации на 4–8 % (F1‑мера, см. далее); словосочетания длиной более 5 слов встречаются редко и не оказывают влияние на качество классификации.) 3. На этапе взвешивания для каждого признака из словаря вычисляется и сохраняется глобальный вес, определяющий значимость признака для решения задачи анализа тональности. В результате исследований [7] установлено, что для данной задачи наиболее эффективен способ вычисления весов RF (Relevance Frequency – релевантная частота), предложенный в [10], в котором для вычисления глобального веса признака используется информация о распределении этого признака по текстам обучающей коллекции с учетом принадлежности текстов к классам. Обозначим a количество текстов, содержащих j-й признак и относящихся к классу С; b – количество текстов, содержащих j-й признак и не относящихся к классу С. Тогда значимость (вес) j-го признака для класса С будет выражаться формулой
Отметим, что для каждого признака в словарь заносятся веса по каждому классу отдельно.
4. На следующем этапе формируется векторная модель текстов [11] для дальнейшего обучения SVM-классификатора. В векторной модели текст представляется в виде вектора, количество компонентов N которого совпадает с количеством признаков в словаре. Каждый компонент является весом соответствующего признака в данном тексте. Для вычисления весов используется подход TF.IDF [11]: wjt=Ljt ×Gj ×Dt, (2) где wjt – вес j-го признака в t-м тексте; Ljt – локальный вес j-го признака в t-м тексте, отражающий значимость признака для данного текста; Gj – глобальный вес j-го признака, отражающий значимость признака для всей коллекции; Dt – нормализация для t-го текста (обычно используется косинусная нормализация). Для вычисления локального веса в соответствии с результатами [7] применяется бинарный способ:
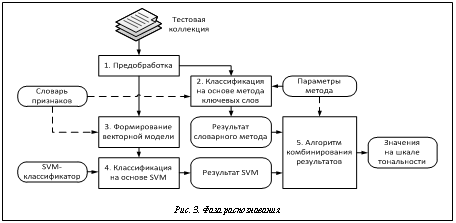
Глобальный вес не вычисляется, а извлекается из словаря для j‑го признака. 5. Этап обучения SVM-классификатора – стандартная процедура построения в N-мерном пространстве признаков гиперплоскости, разделяющей векторы двух классов [6]. При этом выделяются так называемые опорные векторы, находящиеся ближе всего к разделяющей гиперплоскости. Если задача является многоклассовой (количество классов M>2), то обычно независимо строятся M различных гиперплоскостей, каждая из которых отделяет векторы своего класса от всех остальных. Существует множество программных библиотек, реализующих обучение SVM-классификаторов; в данной работе используется библиотека LIBSVM [12]. 6. Заключительный этап фазы обучения – подбор параметров комбинированного метода определения тональности текста. При этом осуществляется поиск оптимальных параметров для метода ключевых слов и для алгоритма комбинирования результатов классификации. Для подбора используется известный подход скользящего контроля по Q блокам (Q-fold cross-validation) на основе обучающей коллекции [13]. При этом обучающая коллекция случайным образом разделяется на Q частей и проводится Q циклов обучения и тестирования, причем в каждом цикле одна из частей (каждый раз новая) выступает в роли тестовой, а остальные части являются обучающими. После этого Q полученных тестовых результатов усредняются. Таким образом, в результате выполнения фазы обучения формируются, во‑первых, словарь признаков, включающий слова и словосочетания (общим количеством N) с глобальными весами для каждого класса отдельно, во-вторых, SVM-классификатор, состоящий из M гиперплоскостей в N-мерном пространстве, в-третьих, набор оптимальных параметров комбинированного метода определения тональности текста. Фаза распознавания. Схема фазы распознавания (рис. 3) включает пять этапов, два из которых совпадают с уже рассмотренными в фазе обучения (этап предобработки и этап формирования векторной модели).
На этапе классификации на основе метода ключевых слов для каждого текста из тестовой коллекции возвращается и один из M классов. На завершающем этапе объединяются результаты классификации SVM-классификатором и методом ключевых слов при помощи алгоритма комбинирования результатов. Таким образом, после выполнения фазы распознавания каждому тексту из тестовой коллекции присваивается класс – значение на шкале измерения тональности. Множество таких значений для всех текстов тестовой коллекции составляет итоговый результат работы комбинированного метода автоматического определения тональности. Метод ключевых слов. На основе данного метода возможно независимое определение тональности текста, но его применение совместно с SVM позволяет получать более высокие результаты. Метод ключевых слов предложен в [7] и основан на подходе, примененном, например, в [1]. Идея метода ключевых слов заключается в том, что тональность текста определяется на основе подсчета весов входящих в него признаков (ключевых слов) – слов и словосочетаний. Веса могут задаваться по‑разному, например, устанавливаться экспертом вручную или вычисляться автоматически с использованием статистических или каких-либо других методов. Предлагаемый метод ключевых слов отличается от существующих, во‑первых, использованием в качестве веса релевантной частоты RF [10], хорошо зарекомендовавшей себя в текстовой классификации, во‑вторых, введением ряда настраиваемых параметров и процедуры их нахождения. Для каждого класса C вес j-го признака Параметры метода ключевых слов объединяются в две группы. В процессе его разработки исследовалось влияние количества признаков на качество распознавания. Оказалось, что наилучшее качество достигается при удалении из словаря всех признаков с весами, ниже определенного оптимального порога, причем такой порог для каждого из M классов свой. Таким образом, первая группа параметров метода ключевых слов представляет собой M пороговых значений весов признаков. При решении задачи определения тональности текста нужно учитывать, что в человеческом общении преобладает позитивная лексика [14], вследствие чего решения автоматических классификаторов оказываются ошибочно смещенными в сторону положительной тональности. Существующие системы пытаются учитывать это обстоятельство за счет введения фиксированных повышающих коэффициентов для классов, расположенных ближе к отрицательной границе шкалы тональности [15]. В предлагаемом методе ключевых слов вводится вторая группа параметров, которая включает коэффициенты ki (i=1, …, M) для каждого из M классов, но не фиксированные, а настраиваемые (на практике можно ограничиться M–1 коэффициентом, поскольку коэффициент для одного класса можно принять равным единице). Помимо двух групп параметров, в предлагаемом методе ключевых слов применяется процедура настройки этих параметров, представляющая собой реализацию метода скользящего контроля по Q блокам на основе обучающей коллекции. Решение об отнесении текста T к одному из классов в методе ключевых слов принимается следующим образом. Для каждого класса Ci вычисляется вес текста Wi путем простого суммирования весов входящих в текст признаков с учетом коэффициентов ki:
где Затем среди полученных весов определяется максимальный:
Текст T относится к тому классу, для которого получен максимальный вес Wmax. Алгоритм комбинирования результатов классификации. В предлагаемом комбинированном методе определения тональности для объединения результатов классификации, полученных методом опорных векторов и методом ключевых слов, используется специальный алгоритм. На вход алгоритма поступают результаты классификации для некоторого текста T, представляющие собой значения на шкале тональности (классы): CSVM – класс, выданный SVM-классификатором, и CKW – класс, выданный классификатором на основе ключевых слов (Key Words). Вместе с обоими классами должны поступать степени уверенности (Confidence) классификаторов: Conf(CSVM) и Conf(CKW). Степень уверенности SVM-классификатора Conf(CSVM) представляет собой расстояние от вектора, обозначающего заданный текст, до соответствующей гиперплоскости. Степень уверенности метода ключевых слов Conf(CKW) равна разности между максимальным весом Wmax и ближайшим меньшим весом Wi (iÎ[1, …, M]). В алгоритме используются три группы параметров, вычисляемых во время фазы обучения на этапе настройки параметров. Первая группа включает M параметров Вторая группа также содержит M параметров В третью группу входит единственный параметр, обозначающий приоритетный, – SVM-классификатор, или классификатор на основе ключевых слов. Класс, выданный приоритетным классификатором, присваивается тексту в том случае, если не удается принять решение на основе оценки степеней уверенности классификаторов. Алгоритм комбинирования результатов классификации для текста T включает следующие шаги. 1. Если решения классификаторов совпадают, то есть CSVM=CKW=C, то текст T относится к классу C. 2. Если один из классификаторов сильно уверен в своем решении, а другой слабо, то текст T относится к классу, который выдал классификатор с сильной уверенностью. 3. Если оба классификатора сильно уверены в своих решениях или оба слабо уверены, а решения не совпадают, выбирается решение приоритетного классификатора. Таким образом, алгоритм комбинирования результатов классификации позволяет эффективно разрешать конфликты двух классификаторов за счет найденных на этапе обучения оптимальных параметров. Проведенные эксперименты Коллекция. В ходе экспериментов с предлагаемым комбинированным методом в качестве обучающей коллекции использовалась одна из коллекций семинара РОМИП – набор отзывов пользователей рекомендательного портала Imhonet.ru на различные фильмы [4, 5]. Каждый отзыв оценивался по шкале тональности от 1 до 10. В данном исследовании авторы проводили эксперименты в рамках задачи классификации с двумя классами, поэтому десятибалльная шкала отображалась в двухбалльную: отзывы с оценками от 6 до 10 обозначались как положительные, с оценками от 1 до 5 – как отрицательные. Общее количество отзывов – 14 813, из них положительных 11 680, отрицательных 3 133. Тестовая коллекция в задаче анализа мнений на семинаре РОМИП-2011 представляет собой набор из 329 отзывов на фильмы, оцененных независимо двумя экспертами. Каждый эксперт оценивал отзыв как положительный или отрицательный. Для 312 отзывов оценки совпали, и именно эти отзывы использовались в данной тестовой коллекции (так называемая схема оценки AND). Метрики оценки. Для оценки эффективности предложенного метода и его сравнения с другими подходами использовались те же метрики, что и на семинаре РОМИП-2011 – точность (precision), полнота (recall), F1‑мера (F1‑measure) и правильность (accuracy) [5]. Для усреднения результатов по классам применялся подход макроусреднения (macro-averaging) [5, 8]. В качестве основной метрики, используемой, в частности, для выбора оптимальных параметров в процедуре скользящего контроля, применялась F1-мера. Для дальнейшего сравнения с авторскими результатами в таблице 1 приводятся значения указанных метрик для тестовой коллекции отзывов на фильмы, полученные на семинаре РОМИП-2011 [5]. В таблице представлены результаты лучшего участника, средние результаты по всем участникам, результаты простого базового классификатора (baseline), относящего все отзывы к наиболее часто встречающемуся классу. Таблица 1 Результаты семинара РОМИП для тестовой коллекции отзывов на фильмы
Заметим, что в семинаре РОМИП-2011 использовались 3 коллекции (кроме отзывов на фильмы, еще отзывы на книги и фотокамеры); коллекция отзывов на фильмы оказалась в среднем наиболее сложной для участников, поэтому и была выбрана в данной работе в качестве основной. Оценка метода. На коллекции отзывов по фильмам проводились тестирование и оценка SVM‑классификатора, классификатора на основе ключевых слов и предлагаемого метода, комбинирующего результаты этих классификаторов. Перед тестированием во время фазы обучения были подобраны оптимальные параметры на основе обучающей коллекции и скользящего контроля по Q блокам. Например, в качестве приоритетного метода выбран метод ключевых слов как показывающий несколько лучшие результаты для данной обучающей коллекции, чем SVM-классификатор. Значение повышающего коэффициента для от- рицательных весов в методе на основе ключевых слов по результатам подбора оказалось рав- ным 3,1. Значения метрик, выявленные в ходе экспериментов, приведены в таблице 2. Таблица 2 Результаты тестирования предлагаемого метода
Из таблицы 2 видно, что результаты, полученные на тестовой коллекции с использованием комбинированного метода, существенно превосходят результаты SVM-классификатора, классификатора на основе ключевых слов и в некоторой степени результаты лучшего участника РОМИП-2011, что подтверждает применимость разработанного метода для определения тональности текстов. Таким образом, комбинированный метод автоматического определения тональности текста, объединяющий результаты двух мощных классификаторов (SVM и на основе ключевых слов), позволил добиться повышения качества классификации по сравнению не только с этими клас- сификаторами, но и с лучшими результатами других подходов. Возникновение такого эффекта обеспечивается за счет учета степеней уверенности классификаторов в своих решениях и подбора оптимальных параметров на основе скользящего контроля. В дальнейшем предполагается провести экспериментальное исследование предложенного метода на других коллекциях (русско- и англоязычных), в том числе с использованием большего количества классов, а также разработать обобщенный метод, позволяющий комбинировать K различных классификаторов. Литература 1. Pang B., Lee L., Vaithyanathan S. Thumbs up? Sentiment classification using machine learning techniques // Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2002. pp. 79–86. 2. Turney P. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews // Proceedings of the Association for Computational Linguistics (ACL), 2002, pp. 417–424. 3. Pang B., Lee L. Opinion Mining and Sentiment Analysis // Foundations and Trends® in Information Retrieval. 2008. no. 2, pp. 1–135. 4. Российский семинар по оценке методов информационного поиска РОМИП URL: http://romip.ru (дата обращения: 01.07.2012). 5. Chetviorkin I., Braslavskiy P., Loukachevitch N. Sentiment Analysis Track at ROMIP 2011 // Computational Linguistics and Intellectual Technologies: Annual International Conf. «Dialogue», CoLing&InTel, 2012, no. 11 (18), pp. 739–746. 6. Vapnik V. Statistical learning theory. NY: Wiley, 1998. 7. Котельников Е.В., Клековкина М.В. Автоматический анализ тональности текстов на основе методов машинного обучения // Компьютерная лингвистика и интеллектуальные технологии: по матер. ежегодн. Междунар. конф. «Диалог». 2012. № 11 (18). С. 753–762. 8. Sebastiani F. Machine learning in automated text categorization // ACM Computing Surveys, 2002, Vol. 34, no. 1. pp. 1–47. 9. Морфологический анализатор Mystem от компании Yandex. URL: http://company.yandex.ru/technologies/mystem (дата обращения: 01.07.2012). 10. Lan M. A New Term Weighting Method for Text Categorization. PhD Theses, 2007. 11. Salton G., Buckley C. Term-weighting approaches in automatic text retrieval // Information Processing & Management, 1988, Vol. 24, no. 5. pp. 513–523. 12. LIBSVM – A Library for Support Vector Machines URL: http://www.csie.ntu.edu.tw/~cjlin/libsvm (дата обращения: 01.07.2012). 13. Kohavi R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection // Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, 1995, no. 2 (12), pp. 1137–1143. 14. Boucher J.D., Osgood Ch.E. The Pollyanna hypothesis // Journal of Verbal Learning and Verbal Behaviour, 1969, no. 8, pp. 1–8. 15. Taboada M., Brooke J., Tofiloski M., Voll K., Stede M. Lexicon-Based Methods for Sentiment Analysis // Computational Linguistics, 2010, no. 37, pp. 1–41. |
 В настоящее время Интернет открыл доступ к огромному количеству текстов, которые аккумулируются, например, на специализированных сайтах отзывов, в социальных сетях и блогах, в разделах комментариев новостных изданий. Автоматическое определение тональности текстов может использоваться для решения многих важных прикладных задач: исследования для коммерческой организации отношения потребителей к ее продукции; разработки рекомендательной системы для покупателей определенных групп товаров или услуг; введения в человеко-машинный интерфейс компьютерной системы функции, отвечающей за адаптацию поведения системы к текущему эмоциональному состоянию человека, и т.д.
В настоящее время Интернет открыл доступ к огромному количеству текстов, которые аккумулируются, например, на специализированных сайтах отзывов, в социальных сетях и блогах, в разделах комментариев новостных изданий. Автоматическое определение тональности текстов может использоваться для решения многих важных прикладных задач: исследования для коммерческой организации отношения потребителей к ее продукции; разработки рекомендательной системы для покупателей определенных групп товаров или услуг; введения в человеко-машинный интерфейс компьютерной системы функции, отвечающей за адаптацию поведения системы к текущему эмоциональному состоянию человека, и т.д. . (1)
. (1)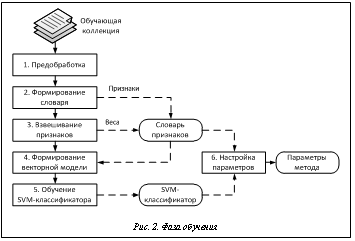 В [7] указывается, что, несмотря на высокую эффективность, применение способа RF для взвешивания признаков, формирования векторной модели текстов и дальнейшего обучения SVM-классификатора нецелесообразно вследствие того, что он вычислительно сложный, а более простые способы дают близкие по точности результаты. Однако в предлагаемом в настоящей работе комбинированном методе применение взвешивания RF оправдано, поскольку результативно используется в методе ключевых слов, а не только при обучении SVM-классификатора. При этом более простые подходы к взвешиванию не позволяют получить хорошие результаты для метода ключевых слов.
В [7] указывается, что, несмотря на высокую эффективность, применение способа RF для взвешивания признаков, формирования векторной модели текстов и дальнейшего обучения SVM-классификатора нецелесообразно вследствие того, что он вычислительно сложный, а более простые способы дают близкие по точности результаты. Однако в предлагаемом в настоящей работе комбинированном методе применение взвешивания RF оправдано, поскольку результативно используется в методе ключевых слов, а не только при обучении SVM-классификатора. При этом более простые подходы к взвешиванию не позволяют получить хорошие результаты для метода ключевых слов.
 (3)
(3) Этап классификации на основе SVM заключается в применении обученного SVM-классификатора для распознавания векторов, сформированных по тестовой коллекции. При этом для каждого тестового вектора SVM-классификатор возвращает один из M классов, к которому отнесен данный вектор, вместе с расстоянием до соответствующей гиперплоскости: чем больше это расстояние, тем выше степень уверенности в результате распознавания.
Этап классификации на основе SVM заключается в применении обученного SVM-классификатора для распознавания векторов, сформированных по тестовой коллекции. При этом для каждого тестового вектора SVM-классификатор возвращает один из M классов, к которому отнесен данный вектор, вместе с расстоянием до соответствующей гиперплоскости: чем больше это расстояние, тем выше степень уверенности в результате распознавания. вычисляется независимо по формуле (1). Признаки с весами для всех классов сохраняются в словаре признаков.
вычисляется независимо по формуле (1). Признаки с весами для всех классов сохраняются в словаре признаков. (4)
(4)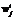 – вес j-го признака в тексте T по отношению к классу Ci.
– вес j-го признака в тексте T по отношению к классу Ci.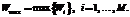 (5)
(5) (i=1, …, M) представляющих собой пороговые значения степеней уверенности SVM-классификатора для i-го класса. Превышение степени уверенности Conf(CSVM) порогового значения
(i=1, …, M) представляющих собой пороговые значения степеней уверенности SVM-классификатора для i-го класса. Превышение степени уверенности Conf(CSVM) порогового значения  (i=1, …, M), которые являются пороговыми значениями для классификатора на основе ключевых слов. Сильная и слабая уверенности этого классификатора определяются по аналогии с SVM.
(i=1, …, M), которые являются пороговыми значениями для классификатора на основе ключевых слов. Сильная и слабая уверенности этого классификатора определяются по аналогии с SVM.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3240 |
Версия для печати Выпуск в формате PDF (7.64Мб) Скачать обложку в формате PDF (1.33Мб) |
| Статья опубликована в выпуске журнала № 3 за 2012 год. [ на стр. 189-195 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Параллельная система автоматической текстовой классификации
- Модуль для полуавтоматического извлечения и обработки данных в области нанокомпозитов
- Сравнительный анализ методов построения математических моделей функционирования объекта с применением машинного обучения
- Определение весов оценочных слов на основе генетического алгоритма в задаче анализа тональности текстов
Назад, к списку статей