Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Анализ связанности сложно-структурированных текстовых данных, характеризующих процессы формирования, размещения и исполнения государственных заказов в научно-технической сфере
Аннотация:Проведен анализ существующих актуальных задач информационной поддержки административных государственных структур, отвечающих за реализацию федеральных и региональных целевых программ в научно-технической сфере. Описаны основные проблемы используемых способов накопления данных, характеризующих процессы формирования, размещения и исполнения государственных заказов (выполняемых в рамках целевых программ). Для решения данных задач предлагаются разработанные средства смыслового содержательного анализа исходного набора данных государственных контрактов с целью последующего установления связей между ними на основе методов семантического анализа. Проведен сравнительный анализ основных алгоритмов классификации и кластеризации текстовых данных, описано тестовое применение алгоритма LSA/LSI (Latent Semantic Analysis/Indexing) к имеющимся данным государственных контрактов научно-технической сферы, приведены необходимые сведения об их исходных характеристиках и о полученных результатах выявления тематически связанных групп (алгоритм реализован на базе разложения исходной диагональной матрицы употребляемости слов в документах по сингулярным значениям). Рассматриваются процедура морфологической обработки исходных текстовых описаний, проведенная с использованием библиотеки морфологического анализа Pymorphy, и процедура исключения стоп-слов, а также наиболее редко и наиболее часто встречающихся слов. Из-за отсутствия в алгоритме LSA/LSI поддержки пересекающихся кластеров обоснованно предложено и описано использование алгоритма нечеткой кластеризации FCM (Fuzzy Classifier Means). Подчеркивается научная новизна ожидаемых результатов, а также определена целевая аудитория конечных пользователей инструментальных программных средств, в которых в перспективе могут быть реализованы результаты работы
Abstract:This article shows the analysis of current pressing problems of information support for administrative state structures, which are responsible for implementation of federal and regional programs actions in science and technology. The main problems of data accumulation patterns are shown. This data characterizes the processes of state orders formation, placement and performance (carried out under the program). To solve these problems, the authors propose to develop the method of semantic content analysis of state orders original data set in order to establish links between them based on semantic analysis techniques. Comparative analysis of the basic classification and text data clustering algorithms are shown, test application of the LSA/LSI (Latent Semantic Analysis/Indexing) algorithm for existing reports of state contracts in scientific and technical areas are described, the necessary information about their baseline characteristics and the results with identifying case-related groups are also shown (the algorithm is based on decomposition of the original coined in documents words diagonal matrix by singular value). The morphological processing of raw text descriptions procedure are described in article. It was carried out using Pymorphy, the morphological analysis library. Also this article shows the stop words and the most rare and most commonly used exclusion procedure. The use of FCM (Fuzzy Classifier Means) algorithm are proposed and described, because there are no any support for overlapping clusters in LSA/LSI algorithm. The expected results scientific novelty and end-users target groups of perspective software tools are shown.
| Авторы: Пономарев С.А. (sytnik@complexsys.ru) - ООО «Комплексные системы», г. Тверь, Россия, Корецкий М.В. (info@complexsys.ru) - ООО «Комплексные системы», г. Тверь (м.н.с.), Тверь, Россия, Сытник Д.А. (sytnik@complexsys.ru) - ООО «Комплексные системы», г. Тверь, кандидат технических наук, Горюнов И.Г. (info@complexsys.ru) - ООО «Комплексные системы», г. Тверь, Россия | |
| Ключевые слова: fcm-алгоритм., lsa, морфологический анализ, семантический анализ, кластеризация, классификация текстовых данных, государственный заказ, федеральная целевая программа, сложно-структурированные текстовые данные |
|
| Keywords: fcm-algorithm, lsa, morphological analysis, semantic analysis, clusterization, text data classification, state orders, federal program, complex-structured text data |
|
| Количество просмотров: 10635 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
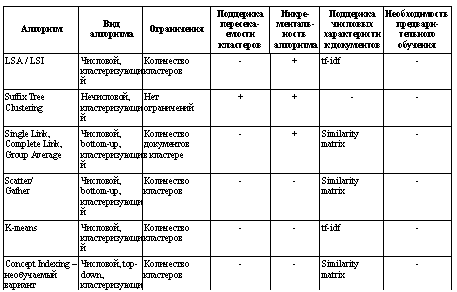
Для административных структур государственных заказчиков-координаторов и специализированных дирекций, отвечающих за реализацию мероприятий федеральных и региональных целевых программ в научно-технической сфере, в условиях постоянно растущего объема массива сложно-структурированных данных государственных контрактов (ГК) все более актуальным становится наличие средств информационной поддержки для решения следующих практических задач: – классификация имеющегося объемного массива данных об информационных объектах процессов размещения и реализации ГК (далее – Объектах) по отраслям науки и техники, а также по прикладному назначению с последующим формированием соответствующих тематических кластеров знаний; – анализ ретроспективной информации массива данных об Объектах с целью принятия рациональных управленческих решений по реализации мероприятий федеральных и региональных целевых программ в научно-технической сфере; – анализ ретроспективной информации массива данных об Объектах с целью прогнозирования хода реализации мероприятий федеральных и региональных целевых программ в научно-технической сфере; – выявление схожих или идентичных по содержанию материалов различных ГК (дублирование документов или фрагментов документов). В решении вышеуказанных практических задач следует выделить две основные проблемы. 1. Используемые принципы накопления данных ГК на сегодняшний день не позволяют при необходимости сгруппировать Объекты по их отраслевому и прикладному назначению, обобщить данные ГК по какому-либо специализированному направлению науки или техники. Например, на сегодняшний день отсутствует тематическая классификация контрактов, связанных даже с достаточно широкими техническими областями (микроэлектроника, полупроводниковая электроника, квантовая электроника и т.п.). Существующая классификация позволяет группировать данные только на уровне целевых программ, програм- мных мероприятий и приоритетных направлений (в рамках конкретных программ) (Положение об управлении реализацией ФЦП «Исследования и разработки по приоритетным направлениям развития научно-технологического комплекса России на 2007–2012 гг.»). 2. Постоянное увеличение объема массива данных ГК обусловливает необходимость развития средств поиска Объектов по настраиваемым критериям, а также поиска связей между Объектами с целью выявления схожих и связанных Объектов (например, заявок на участие в конкурсе со схожим содержанием, контрактов по схожим тематикам одного и того же исполнителя, организаций, являющихся наиболее активными устоявшимися исполнителями контрактов по определенным тематикам, и т.д.). Для решения вышеописанных научно-технических задач авторами статьи выбраны методики исследований и разработки средств смыслового содержательного анализа исходного набора Объектов (с целью последующего установления связей между ними) на основе методов семантического анализа. Рассмотрим основные алгоритмы классифи- кации и кластеризации текстовых данных на предмет применения к данным государственных контрактов Федерального государственного бюджетного научного учреждения «Дирекция научно-технических программ» и проведем их сравнительный анализ по следующим характеристикам: - возможность работы алгоритма в инкрементном режиме – тематическая рубрикация документов одновременно с поступлением их из источника без выполнения каждый раз всего цикла вычислений; - пересекаемость – возможность попадания одного документа в несколько смежных тематических рубрик; - возможность использования характеристик о множестве документов, вычисленных заранее, до основного процесса обработки (к таким характеристикам относятся матрица близости между документами similarity matrix, матрица весов документов TF-IDF); - необходимость обучения алгоритма. Перечислим наиболее распространенные на сегодняшний день алгоритмы классификации и кластеризации текстовых данных. LSA/LSI – Latent Semantic Analysis/Indexing. С использованием факторного анализа множества документов выявляются латентные (скрытые) факторы, которые в дальнейшем являются основой для образования кластеров документов. STC – Suffix Tree Clustering. Кластеры образуются в узлах специального вида дерева – суффиксного дерева, которое строится из слов и фраз входных документов. Single Link, Complete Link, Group Average. Данные алгоритмы разбивают множество документов на кластеры, расположенные в древовидной структуре, получаемой с помощью иерархической агломеративной кластеризации. Scatter/Gather. Итеративный процесс, сначала разбивающий множество документов на группы, а затем представляющий эти группы пользователю для дальнейшего анализа. Далее процесс повторяется, но уже над указанными пользователем группами. K-means. Относится к неиерархическим алгоритмам. Кластеры представлены в виде центроидов, являющихся «центром массы» всех документов, входящих в кластер. CI – Concept Indexing. Разбивает множество документов методом рекурсивной бисекции, то есть разделяет на две части на каждом шаге рекурсии. Метод может использовать информацию, полученную на этапе обучения. Сравнительный анализ алгоритмов классификации и кластеризации текстовых данных по основным характеристикам приведен в таблице. Поясним характеристики рассматриваемых в таблице алгоритмов: – классификация – это отнесение каждого документа к определенному классу с заранее известными параметрами, полученными на этапе обучения; число классов строго ограничено; – кластеризация – это разбиение множества документов на кластеры – подмножества, параметры которых заранее неизвестны; количество кластеров может быть произвольным или фиксированным; – числовые алгоритмы – алгоритмы, использующие для работы числовые характеристики документов (например матрицу TF-IDF или матрицу близости документов Similarity matrix); нечисловые алгоритмы – алгоритмы, использующие непосредственно слова и фразы, составляющие текст. Матрица TF-IDF (term frequency, inverse document frequency) вычисляется следующим образом:
где N – количество документов; nt – количество документов, в которые входит термин t (термин – это слово, которое непосредственно влияет на отнесение документа к какой-либо категории); mdt – число вхождений термина t в документ d; md – maxd mdt. Координаты документов в пространстве терминов записываются в матрицу TF-IDF. Числовым алгоритмам кластеризации присущи два способа выполнения кластеризации множества документов – top-down и bottom-up. При top-down весь имеющийся объем документов изначально рассматривается как единый кластер, далее происходит его деление на более мелкие составляющие. При bottom-up изначально каждый документ рассматривается как отдельный кластер. В процессе работы наиболее близкие документы объединяются в кластеры, включающие все больше и больше документов. Из вышеперечисленных алгоритмов первоначально был рассмотрен алгоритм LSA/LSI (алгоритм латентно-семантического анализа, или ЛСА), являющийся одним из наиболее известных алгоритмов, изначально разработанных для выявления семантических структур текстов, фактов смысловой связанности и представления баз знаний. Реализация алгоритма заключается в сравнении множества всех контекстов, в которых употребляются слова или группы слов, и контекста, в которых они не употребляются, что позволяет сделать вывод о степени близости смысла этих слов или групп слов. Также данный алгоритм позволяет успешно преодолевать проблемы синонимии и омонимии, основываясь только на статистической информации о множестве документов и терминов.
Пусть А – матрица, где элемент (i, j) отображает употребление слова i в отрывке j [1]. Матрица А будет иметь следующий вид:
Элемент xi,j представляет собой количество употреблений i-го слова в j-м отрывке. Каждая строка в этой матрице – это вектор, соответствующий слову и отражающий его употребляемость в каждом документе Аналогично каждый столбец представляет собой вектор, соответствующий отрывку и отражающий употребляемость слов в этом отрывке:
Таким образом, расположение имеет следующий вид:
Числа w1, …, wl называются сингулярными числами, а u1, …, ul и v1, …, vl правыми и левыми сингулярными векторами соответственно. Следует заметить, что единственная часть матрицы V, которая влияет на элементы вектора ti, – это ее i-я строка. Аналогично на di влияет только j-й столбец Если из всех сингулярных значений отобрать k наибольших, получим аппроксимацию исходной матрицы векторами ранга k. Такое разложение обладает следующей особенностью: если в матрице W оставить только k наибольших сингулярных значений, а в матрицах U и V – только соответствующие этим значениям столбцы, произведение получившихся матриц W, U и V будет наилучшим приближением исходной матрицы A к матрице В рамках НИР была проведена экспериментальная проверка использования алгоритма ЛСА для анализа имеющихся данных о заключенных контрактах научно-технической сферы. Каждый документ был представлен идентификатором и текстовым описанием, включающим следующие поля: наименование контракта, общее описание выполняемой работы по контракту, описания работ на отдельных этапах выполнения контракта. В этой структуре очевидными недостатками исходных данных являются периодически встречающееся дублирование данных в описаниях, разнородность описаний контрактов по объему текста и наличие незаполненных полей. В качестве исходных данных были взяты 4 212 анализируемых контрактов, 1 561 контракт с пустыми общими описаниями работ, 1 283 контракта с пустыми описаниями работ по этапам выполнения контракта. На первом этапе проводилась морфологическая обработка исходных текстовых описаний: – все слова, встречающиеся в описаниях контрактов, были приведены к нормальной форме с использованием библиотеки морфологического анализа Pymorphy, реализованной на языке программирования Python (распространяется по лицензии свободного программного обеспечения MIT); – после получения таблицы вхождений конкретных слов в конкретные документы для упрощения дальнейшего анализа были исключены слова, не несущие в тексте смысловой нагрузки (союзы, предлоги, междометия, частицы – так называемые стоп-слова, или «шумовые» слова). С учетом проведенной морфологической обработки анализируемые тексты имели следующие характеристики (в символах): минимальная длина текста – 10, максимальная длина текста – 1 118, средняя длина текста – 149, дисперсия длин текстов – 11 207,26. На следующем этапе исключались наиболее редко и наиболее часто встречающиеся слова. Например, если слово встречается в 3 736 документах (максимальное выявленное значение, составляет 88 % от общего числа документов), то оно не влияет на классификацию документов по тематикам. Далее приводится список найденных слов с максимальной частотой вхождений (указывается количество документов, в которые слово вошло не менее одного раза): исследование – 3 736, разработка – 3 727, провести – 3 597, разработать – 3 533, проведение – 3 314, анализ – 2 699, патентный – 2 467, результат – 2 389, метод – 2 371, основа – 2 194, работа – 2 188, методика – 2 103, создание – 2 090, материал – 1 966, система – 1 932, экспериментальный – 1 912, оценка – 1 902, использование – 1 899, технический – 1 883, документация – 1 866. В документах научно-технической сферы данные слова не влияют на классификацию. Слова, встречающиеся крайне редко, тоже следует исключить из исходных текстов. Подбор верхней и нижней границ частот осуществляется эмпирически экспертом и индивидуален для каждой тематики документов. Для исследуемых данных были отобраны слова, значения частот вхождения которых составили от 10 до 600. Изначально в документах содержалось 34 516 слов, исключение редко и часто встречающихся слов сократило объем слов, используемых при классификации, до 4 200. Далее была заполнена и нормализована (методом TF-IDF) матрица употребляемости отобранных слов в документах, проведено ее сингулярное разложение. Подбор ранга для полученных в результате разложения ортогональных и диагональной матриц (понижение ранга) осуществлялся также эмпирически: 1 000 – хорошо находит похожие тексты, но не выявляет тематическое сходство; 600 – выявляется тематическое сходство, но заметно существенное влияние «шумов»; 300 – наиболее успешно выявляются тематически связанные группы слов и текстов; 50 – наблюдается ухудшение качества результатов (по сравнению с рангом 300); группы слов становятся больше, но уровень их смыслового, тематического сходства снижается. В итоге при наиболее успешном варианте понижения ранга до 300 было выявлено 60 тематических групп слов. В каждой из групп содержалось от 4 до 15 слов. Группы, включающие менее 4 слов, не рассматривались, так как не имели смысловой практической значимости. Приведем примеры найденных тематических групп слов, подтверждающих возможность применения метода ЛСА для поставленных задач. Группа 1: преподаватель, рассмотрение, совет, ученый, школа, молодой. Группа 2: жилой, сооружение, энергопотребление, отопление, здание. Группа 3: больной, лечение, ранний, мозг, пациент, патология, аппаратно-программный. Группа 4: сервис, облако, высокоскоростной, трафик, реальный, сетевой, атака, облачный. Одним из главных недостатков метода ЛСА является отсутствие поддержки пересекающихся кластеров, то есть при кластеризации текстов отсутствует потенциальная возможность включения документа в несколько кластеров. Таким образом, в рамках исследуемой предметной области отсутствует возможность отнести контракт к нескольким тематикам одновременно (что встречается на практике). По этой причине, помимо алгоритма ЛСА (и других методов, приведенных в таблице), был рассмотрен наиболее распространенный FCM-алгоритм нечеткой кластеризации (Fuzzy Classifier Means, Fuzzy C-Means), обеспечивающий обработку данных ситуаций. Найденные алгоритмом кластеры представляются нечеткими множествами, границы между кластерами также являются нечеткими. FCM-алгоритм кластеризации предполагает, что объекты принадлежат всем кластерам с определенной степенью принадлежности. Степень принадлежности определяется расстоянием от объекта до соответствующих кластерных центров. Данный алгоритм итерационно вычисляет центры кластеров и новые степени принадлежности объектов. Для заданного множества К входных векторов хk и N выделяемых кластеров сj предполагается, что любой хк принадлежит любому сj с принадлежностью mjk интервалу [0, 1], где j – номер кластера; k – номер входного вектора [2]. Принимаются во внимание следующие условия нормирования для mjk: Цель алгоритма – минимизация суммы всех взвешенных расстояний
Для достижения вышеуказанной цели необходимо решить следующую систему уравнений:
Совместно с условиями нормирования µjk данная система дифференциальных уравнений имеет такое решение: На каждом итерационном шаге выполнения алгоритма осуществляются: 1) регулирование позиций 2) корректировка значений принадлежности µjk; учитывая известные 3) проверка условия остановки алгоритма. Алгоритм нечеткой кластеризации останавливается при выполнении следующего условия: На данный момент проводятся экспериментальные исследования использования алгоритма применительно к имеющимся данным ГК. Научная новизна ожидаемых результатов будет заключаться в следующем: – применение алгоритмов классификации и кластеризации текстовой информации для классификации имеющегося объемного массива данных ГК по отраслям науки и техники (включая построение классификатора); - реализация анализа связанности данных ГК на основе семантического анализа, обеспечивающей возможность выявлять схожие или идентичные по содержанию материалы различных контрактов (документов), а также группировать и фильтровать классифицированную информацию об Объектах по настраиваемым семантическим факторам. Результаты работ, реализованные в виде инструментального программного средства, могут использоваться административными структурами государственных заказчиков-координаторов и специализированных дирекций, отвечающих за реализацию мероприятий федеральных и региональных целевых программ в научно-технической сфере, в качестве инструмента поддержки принятия управленческих решений и прогнозирования хода реализации мероприятий целевых программ в научно-технической сфере, а также выявления схожих или идентичных по содержанию мате- риалов различных ГК; представителями инвестиционных организаций для информационного обеспечения выбора направлений инвестиций в научно-технической сфере; участниками проектов в научно-технической сфере для систематизации и классификации массива данных ГК по интересующему отраслевому и прикладному назначению. Литература 1. Михайлов Д.В. Семантическая кластеризация текстов предметных языков (морфология и синтаксис) // Компьютерная оптика. 2009. Т. 33. Вып. 4. С. 473–480. 2. Miyamoto S., Ichihashi H., Honda K. Algorithms for Fuzzy Clustering: Methods in C-Means Clustering with Applications. Springer 2008, 247 p. |
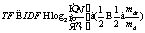 ,
, Технически метод заключается в разложении исходной диагональной матрицы употребляемости слов в документах по сингулярным значениям.
Технически метод заключается в разложении исходной диагональной матрицы употребляемости слов в документах по сингулярным значениям.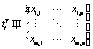 .
.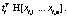
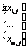 .
.
 .
. ранга k.
ранга k.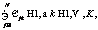
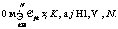
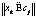 :
: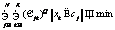 , где Q – фиксированный параметр, задаваемый перед итерациями.
, где Q – фиксированный параметр, задаваемый перед итерациями.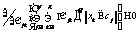 ,
,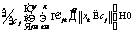 .
.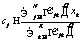 (взвешенный центр гравитации) и
(взвешенный центр гравитации) и  .
.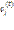 центров кластеров;
центров кластеров; , если
, если 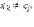 в противном случае
в противном случае 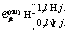
 где
где 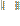 – матричная норма (например Евклидова норма), e – заранее задаваемый уровень точности.
– матричная норма (например Евклидова норма), e – заранее задаваемый уровень точности.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3355 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
| Статья опубликована в выпуске журнала № 4 за 2012 год. [ на стр. 263-268 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Принципы и инструментальные программные средства визуализации и анализа данных исполнения государственных контрактов в научно-технической сфере
- Метод автоматического синтеза нечетких регуляторов
- Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
- Информационно-коммуникационная технология комплексного управления деятельностью студентов
- Применение технологии CUDA для обучения нейронной сети Кохонена
Назад, к списку статей