Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Концептуальные основы построения анализатора безопасности программного кода
Аннотация:Рассмотрены вопросы автоматизации процедур аудита безопасности исходных текстов программ и поддержки эксперта в принятии решений о наличии дефектов безопасности в исследуемом программном обеспечении. Проведен сравнительный анализ известных статических анализаторов программного кода. Обосновывается применимость статического сигнатурного анализа (по шаблону) для выявления дефектов и уязвимостей программ. Предложены принципы построения и структура анализатора безопасности программного кода, сочетающего синтаксический и семантический анализ кода. Определены требования к базе сигнатур. Приведен алгоритм функ-ционирования анализатора безопасности программного кода. Показана эффективность предложенного решения с точки зрения добавления новых языков и сред программирования, а также новых классов дефектов безопасности. Приведен пример работы анализатора программного кода, демонстрирующий его эффективность при выявлении широкого класса дефектов и уязвимостей.
Abstract:The problems of software security audit automation and support of decisions about software defects are considered. A comparative analysis of known static code analyzers is done. The applicability of static signature analysis (on pattern) to identify defects and vulnerabilities are justified. The principles of construction and structure of the security code analyzer that combines syntactic and semantic code analysis are proposed. The requirements for the signature database are described. The algorithm of the operation of the security code analyzer is given. The efficiency of the proposed solution in terms of adding new languages and programming environments as well as new classes of security defects is shown. The example of the security parser code that demonstrates its effectiveness in identifying a broad class of defects and vulnerabilities is done.
| Авторы: Марков А.С. (mail@cnpo.ru) - НПО «Эшелон» (доцент, генеральный директор), Москва, Россия, кандидат технических наук, Фадин А.А. (a.fadin@cnpo.ru) - НПО «Эшелон» (руководитель департамента разработки), Москва, Россия, Цирлов В.Л. (vz@cnpo.ru) - НПО «Эшелон» (доцент, исполнительный директор ), Москва, Россия, кандидат технических наук | |
| Ключевые слова: недекларированные возможности., уязвимости, дефекты безопасности, сигнатурный анализ, статический анализ, аудит безопасности кода, безопасность программ |
|
| Keywords: undeclared possibilities, attack, security flaws, signature analysis, static analysis, security code review, security software |
|
| Количество просмотров: 15028 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
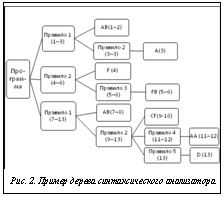
Противоречие между затратами на блокирование критических уязвимостей ПО и требованиями по безопасности применения информационных систем определяет задачу внедрения эффективных средств аудита безопасности программ на начальных стадиях их проектирования и разработки. Опыт испытаний программных средств защиты информации и аудита безопасности программного кода показал, что наиболее эффективным подходом к выявлению дефектов безопасности программ является использование средств автоматизации статического анализа (инспектирования) безопасности кода [1]. Применение статического анализа кода также регламентировано рядом стандартов, включая руководящий документ Гостехкомиссии России. К сожалению, популярные статические анализаторы программного кода позволяют автоматизировать выявление ограниченного подмножества ошибок (например некорректности кодирования, мертвый код, ошибки портирования), не касаясь явно вопросов безопасности программных систем. В данной работе рассматри- ваются реализационные основы анализатора бе- зопасности программного кода, сочетающего синтаксический и сигнатурный (шаблонный) анализ текста программ с целью выявления всевозможных дефектов, влияющих на безопасность системы. Средства статического анализа программного кода Подходы к аудиту безопасности программ можно разделить на две основные категории: статический анализ и динамическое тестирование. Динамические методы наиболее востребованы при исследовании программ методом черного ящика, когда имеется доступ лишь к отдельным интерфейсам ПО. Указанные методы популярны при тестировании корректности и устойчивости функционирования программ, но малоэффективны при поиске ошибок, связанных с комбинациями редко используемых входных данных, например ошибок, внесенных преднамеренно. В случае полного доступа к программной системе и ее исходным текстам чаще всего применяются методы статического анализа, использующие исходные и загрузочные модули программного приложения и дополнительную информацию, связанную, как правило, со средой компиляции и выполнением программных компонентов. Достоинствами статического анализа кода являются отсутствие необходимости в астрономических прогонах программ при разных условиях функционирования и возможность добиться большей степени автоматизации проверок на наличие дефектов программ исходя из их конструктивных признаков. Среди наиболее популярных анализаторов исходного кода выделим следующие: Qstudio, Understand for C, doxygen, Rational Rose, PVS-Studio, «АИСТ-С», «АК-ВС», Fortify, rats, FindBugs, которые можно классифицировать по их целевому назначению: – расчет метрик и оценка качества кода; – структурный анализ и документирование исходных текстов; – метапрограммирование и содействие в портировании кода; – анализ соответствия исходных текстов требованиям нормативных документов по контролю отсутствия недекларированных возможностей; – анализ дефектов и уязвимостей програм- много обеспечения. Две последние категории анализаторов кода рассмотрим более подробно, так как их использование явно или неявно регламентировано российской нормативной базой. Такие анализаторы на основе проверки исходных текстов программ и различной проектной метаинформации, связанной с архитектурой приложений (зависимости, проектные файлы), позволяют эксперту получить перечень позиций в коде программы, где предположительно находятся потенциально опасные конструкции (ПОК). Это могут быть архитектурные ошибки (например недостатки проектирования механизмов безопасности), некорректности кодирования (например ошибки переполнения буфера), а также ошибки, искусственно внесенные по халатности (фрагменты отладочного кода или фазинга) или целенаправленно (программные закладки). Заметим, что фрагмент кода с ПОК подлежит ревизии со стороны тестировщика, который окончательно идентифицирует дефект программы и возможность его реализации. Основным недостатком известных анализаторов является не столько ограниченность применения (поддержка ограниченного множества языков, как правило, С/C++), сколько неспособность учитывать результаты собственного синтаксического анализа языка исходных текстов при поиске сигнатур. Этот недостаток не позволяет обеспечить открытую масштабированную архитектуру анализатора с точки зрения добавления новых языков и сред программирования, а также новых классов дефектов безопасности. Следует отметить, что в литературе статический анализ программ часто понимают в узком смысле, а именно как синтаксический анализ кода. Наиболее известные примеры такого анализа – анализ дерева кода, потока управления, потока данных, потока данных с выбором пути [2, 3]. При этом достаточно часто недооценивается роль сигнатурного анализа (по шаблону [1]) в исследовании кода, который позволяет преодолеть ряд недостатков, присущих перечисленным выше подходам. Главная проблема в том, что подавляющий пласт дефектов безопасности выявляется не на уровне, например, абстрактного дерева синтаксиса кода, а на уровне семантики, когда необходимо проверить такие высокоуровневые положения, как, например, было ли в этой области кода обращение к устаревшей функции API с указанием жестко прописанного пути к файлу. Данное утверждение можно легко и достаточно надежно проверить с помощью сигнатурного анализа. Попытка ориентироваться лишь на содержимое абстрактного синтаксического дерева кода приведет к сложности учета всех вариаций синтаксических конструкций, содержащих подобную ПОК. Кроме того, современные динамические языки программирования (Python, Perl) дают возможность менять дерево кода «на лету», что позволяет довольно эффективно бороться с подобным подходом к анализу. Направления, связанные с анализом потоков команд, достаточно часто пасуют перед современными сложными многопоточными программами, которым присущи метапрограммирование, полиморфизм, динамические объекты. Они эффективны лишь при решении ограниченного круга задач поиска, например поиска упомянутых ранее некорректностей кодирования, ошибок портирования и т.д. Именно поэтому для преодоления недостатков, описанных выше, был разработан и апробирован анализатор безопасности кода, имеющий модульную структуру и реализующий преимущества совмещения результатов синтаксического и сигнатурного анализов исходных текстов с целью выявления ПОК. Принципы работы анализатора безопасности кода Разберем принципы работы данного анализатора, совмещающего результаты синтаксического и семантического анализа кода. Совмещение результатов осуществляется на основе сравнения позиций элементов иерархического представления программы, полученных в результате лексического и синтаксического анализа, с позициями паттернов (шаблонов) конструкций, обнаруженных при сигнатурном анализе. Зная позиции (в файлах исходных текстов) каждого из элементов, эксперт может сопоставить узлы абстрактного синтаксического дерева найденным сигнатурам и на основе правил логического вывода оценить возможность нахождения в этом фрагменте исходных текстов потенциально опасных конструкций. Для реализации указанных принципов был предложен анализатор безопасности кода со следующей структурой: CSA=áSDB, HDB, MLA, MSA, MSY, MLO, MRPñ, где SDB – БД сигнатур (паттернов) ПОК; HDB – БД структурной информации о коде (иерархического представления программы); MLA – программный модуль лексического анализа; MSA – программный модуль синтаксического анализа; MSY – программный модуль сигнатурного анализа; MLO – программный модуль логического вывода; MRP – программный модуль построения отчетов. Рассмотрим алгоритм работы анализатора безопасности кода. Модули лексического и сигнатурного анализа принимают на вход исходные тексты программ, их бинарный код, а также общие сведения о декомпозиции ПО. На выходе генерируется отчет о ПОК, состоящий из перечня участков кода, где они предположительно находятся, и необходимые комментарии. Для классификации и группировки различных видов потенциально опасных конструкций используется международная таксономия CWE (Common Weakness Enumeration), где наиболее полно перечислены дефекты в области безопасности ПО [4]. На рисунке 1 показана функциональная схема анализатора безопасности кода, решающего сформулированные выше задачи. Прокомментируем функциональную схему анализатора. Задача лексического анализатора состоит в распознавании лексем в коде программы, файлах конфигурации и бинарных файлах различ Задача синтаксического анализатора заклю- чается в том, чтобы на основе цепочки распознанных лексем сформировать в базе структурной информации дерево структурной декомпозиции программы, одной из ветвей которого является абстрактное синтаксическое дерево (дерево Канторовича [5]). Данный модуль, как правило, содержит в себе конечный автомат для распознавания цепочек лексем, который может быть реализован, к примеру, с помощью LR(1)-парсера, то есть синтаксического анализатора, выполняющего восходящий синтаксический разбор с предосмотром текста на один символ вперед. Надо сказать, что компилятор любого языка программирования содержит подобный модуль синтаксического разбора. К сожалению, большинство из этих модулей замкнуто и не позволяет выдать результат своей работы в унифицированном для обмена с другими программами виде. Кроме того, у средств аудита безопасности кода несколько иные требования к синтаксическому анализатору, например, он должен быть более толерантным к структуре исходных текстов и, встретив незнакомую лексему, попытаться продолжить анализ файла насколько это возможно, а не остановиться, выдав ошибку, как это сделает синтаксический анализатор из состава компиляторов. Сигнатурный анализатор осуществляет сквозной поиск в исходных текстах программы паттернов ПОК, используя базу сигнатур, которая представляет собой набор следующих кортежей: SDB=áPE, DLñ, где PE – описание фрагмента ПОК (например, используя регулярные выражения); DL – оценка степени их опасности (например числовая шкала 1–10). Модуль логического вывода сравнивает структурную информацию кода и данные сигнатурного анализа, на основе чего формирует заключение о возможности присутствия ПОК в том или ином участке кода. Пример работы анализатора безопасности кода Проиллюстрируем предложенный подход к поиску ПОК на следующем примере. Пусть имеется исходный текст абстрактного языка программирования: Obj1() >> [func2(),1602-3] Obj2() << [!MAX_ALLOWED_VALUE), Obj3.func1(), NULL] В лексическом анализаторе заданы некоторые определения лексем, причем для наглядности в виде текстовых описаний, а не как регулярные выражения, к тому же из них исключены разделители конструкций. Лексема A – название идентификатора программы (переменная, функция и т.п.). Лексема B – класс различного вида операций (+|*/>>). Лексема C – класс префиксных операций (инверсия, разыменование и др. (!*~)). Лексема D – пустой литерал (нулевое значение). Лексема F – числовой литерал (значение). При таких условиях исходный текст будет преобразован лексическим анализатором в цепочку лексем: ABAFFBABCFAAD В данном случае требуется найти потенциально опасные фрагменты кода, содержащие возможные дефекты безопасности. Пусть синтаксический анализатор содержит некоторый набор правил вывода для построения дерева: Правило 1: AB <Правило 2> Правило 2: A Правило 2: CF <Правило 4><Правило 5> Правило 2: F <Правило 3> Правило 3: FB Правило 4: AA Правило 5: D Пример некоторого содержимого базы сигнатур (паттернов сигнатурного анализа): Сигнатура № 1: Если в коде встречается последовательность CB, то, вероятно, здесь находится потенциально опасная конструкция № 2, опасность которой оценивается как 7 (по шкале 1–10). Сигнатура № 2: Если в коде встречается последовательность FB, то, вероятно, здесь находится потенциально опасная конструкция № 3 (использование побитовых операндов вместо логических), опасность которой оценивается как 7 (по шкале 1–10). Зададим пример правила вывода, содержащегося в модуле логического вывода: Уязвимость № 1: Если внутри узла дерева типа «Правило 4» будет найдена сигнатура № 2, то выдаем на выход информацию о найденной уязвимости № 1 с коэффициентом 0,7. Уязвимость № 2: Если внутри узла дерева типа «Правило 2» будет найдена сигнатура № 2, то выдаем на выход информацию о найденной уязвимости № 2 с коэффициентом 0,8. Если итоговый коэффициент уязвимости превысит 5, то эта информация попадает в отчет. <…> Рассмотрим работу анализатора безопасности кода (см. рис. 1) на входных условиях приведенного примера. 1. Для заданной последовательности лексем синтаксический анализатор сформирует соответствующее ей дерево структурной декомпози- ции программы в базе структурной информации (рис. 2). На рисунке 2 показана иерархическая структура разобранной программы, в каждом из узлов которой будет содержаться либо номер правила, либо непосредственно распознанная цепочка символов. В скобках указаны номера символов во входной последовательности, которым соответствует данный узел иерархии. Эта информация необходима для сопоставления результатов синтаксического и сигнатурного анализа; например, в случае настоящей программы координата задается в виде номера столбца и строки в коде либо как смещение от начала файла с исходными текстами. 2. Модуль сигнатурного анализа в 5-м и 6-м символах входной последовательности на основе базы сигнатур, представленной выше, обнаружит ПОК № 1 с оцениваемой опасностью 7. 3. Модуль логического вывода выполнит следующие действия: – определит, что найденная ПОК № 1 относится к узлу дерева FB по ее координатам (5–6) (см. ранее содержимое цепочки выходных лексем); – определит, что сработало правило для уязвимости № 55, то есть ПОК № 1 находится внутри узла «Правило 2»; – вычислит итоговый коэффициент уязвимости (5,6), умножив степень ее опасности 7 на коэффициент правила по уязвимости 0,8; – сформирует строку отчета, поскольку итоговый коэффициент (5,6) превышает пороговое значение фильтра 5. 4. Модуль построения отчета сформирует адрес участка (5–6) предполагаемой уязвимости № 2.
Данный подход реализован при разработке средства анализа безопасности программного кода «АК-ВС», которое было апробировано при сертификационных испытаниях 73 программных средств защиты информации. В процессе работы со средством анализа и последующего рецензирования кода экспертами успешно выявлены множество уязвимостей программных систем (в основном связанных с переполнениями буфера, гонками, загрузкой недоверенных файлов) и программные закладки (парольные закладки, генераторы паролей, временные бомбы). Литература 1. Марков А.С., Миронов С.В., Цирлов В.Л. Выявление уязвимостей в программном коде // Открытые системы. СУБД. 2005. № 12. С. 64–69. 2. Глухих М.И., Ицыксон В.М. Программная инженерия. Обеспечение качества программных средств методами статического анализа. СПб: Изд-во политехн. ун-та, 2011. 150 с. 3. Колосов А.П., Рыжков Е.А. Применение статического анализа при разработке программ // Изв. Тульского гос. ун-та. Сер.: Технич. науки. 2008. № 3. С. 185–190. 4. Марков А.С., Фадин А.А., Цирлов В.Л. Систематика дефектов и уязвимостей программного обеспечения // Безопасные информационные технологии: сб. тр. II НТК. М.: МГТУ им. Н.Э. Баумана, 2011. С. 83–87. 5. Канторович Л.В., Петрова Л.Т., Яковлева М.А. Об одной системе программирования // Пути развития советского математического машиностроения и приборостроения: Всесоюз. конф. M.: ВИНИТИ. 1956. Ч. III. С. 30–36. |
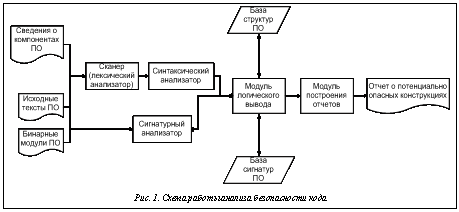
 Рассмотренный в данной работе анализатор безопасности программного кода обеспечивает автоматизацию процедур аудита исходных текстов и поддержку эксперта в принятии решения о наличии дефекта безопасности в исследуемом программном приложении. Предложенный подход по сопоставлению результатов сигнатурного и синтаксических анализаторов позволяет, с одной стороны, оперативно обнаруживать типовые кон- струкции в коде на основе пополняемой базы паттернов, с другой – учитывать особенности синтаксических конструкций того или иного языка программирования.
Рассмотренный в данной работе анализатор безопасности программного кода обеспечивает автоматизацию процедур аудита исходных текстов и поддержку эксперта в принятии решения о наличии дефекта безопасности в исследуемом программном приложении. Предложенный подход по сопоставлению результатов сигнатурного и синтаксических анализаторов позволяет, с одной стороны, оперативно обнаруживать типовые кон- струкции в коде на основе пополняемой базы паттернов, с другой – учитывать особенности синтаксических конструкций того или иного языка программирования.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3379 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
| Статья опубликована в выпуске журнала № 1 за 2013 год. [ на стр. 47-52 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Методический аппарат анализа и синтеза комплекса мер разработки безопасного программного обеспечения
- Методика оценки реального уровня защищенности автоматизированных систем
- Информационная технология верификации специального программного обеспечения автоматизированных систем военного назначения
- Безопасность баз данных: проблемы и перспективы
- Модель выбора мероприятий по обеспечению информационной безопасности на основе нечетких автоматов
Назад, к списку статей