Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Methode zur Lösung von Aufgaben beim Rufrouting auf der Grundlage einer neuen Bewertung der Termrelevanz
Аннотация:Маршрутизация вызовов, основанная на обработке естественного языка, представляет собой сложную и перспек-тивную область исследований в интеллектуальных машинных методах и интерпретации языка. Эта сложность обусловлена трудностями в автоматической интерпретации естественного языка. В данной статье сделан акцент на разработку алгоритмов, по эффективности способных превзойти существующие методы на больших БД и не тре-бующих морфологического анализа или фильтра в виде стоп-слова. В предлагаемом подходе осуществляется деком-позиция задачи классификации, к которой сводится маршрутизация вызовов, на две стадии: обнаружение остаточного класса и отнесение объектов к значимым классам. К остаточному классу относятся объекты, которые нельзя отнести к значимым классам или же можно отнести сразу к нескольким значимым классам. Предлагается новая формула оценки релевантности термов при определении значимых классов, являющаяся модификацией оценки релевантности нечетких правил в нечетком классификаторе. Используя эту формулу только для 300 наиболее часто встречающихся слов для каждого класса, достигнута точность классификации 85,55 %.
Abstract:Das Call Routing, das auf der Verarbeitung von natürlicher Sprache basiert, stellt einen komplizierten und perspektivreichen Forschungsbereich auf dem Gebiet der intelligenten Verfahren zur maschinellen Verarbeitung und Interpretation von Sprache dar. Die Schwierigkeit ist bedingt durch die Komplexität bei der automatischen Interpretation von natürlicher Sprache. In diesem Artikel wird Schwerpunkt auf die Entwicklung von Algorithmen gelegt, die in der Lage sind, über die Effizienz der bestehenden Methoden in großen Datenbanken hinaus zu gehen, und die keine morphologische Analyse oder Filter der Art «Stoppwörter» erfordern. Bei der vorgeschlagenen Methode erfolgt eine Dekomposition der Klassifizierungsaufgabe, in der das Rufrouting auf zwei Stadien zurückgeführt wird: Feststellen der «residuellen» Klasse und Zuordnen der Objekte zu signifikanten Klassen. Zur «residuellen» Klasse gehören Objekte, die keiner signifikanten Klasse oder aber die nicht per se mehreren signifikanten Klassen zugeordnet werden können. Wir stellen eine neue Formel zur Bewertung der Termrelevanz bei der Bestimmung der signifikanten Klassen vor, die eine Modifizierung der Bewertung der Relevanz von fließenden Regeln in einem Fuzzy-Klassifikator ist. Wenn diese Formel nur für 300 der am meisten verbreiteten Worte für jede Klasse zur Anwendung kommt, kann eine Genauigkeit bei der Klassifizierung von 85,55 % erreicht werden.
| Авторы: Gasanova Т.О. (tatiana.gasanova@uni-ulm.de) - Ульмский университет (аспирант ), Ульм, Германия, Sergienko R.B. (romaserg@list.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева (ст. преподаватель), Красноярск, Россия, кандидат технических наук, Semenkin E.S. (eugenesemenkin@yandex.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева (профессор ), Красноярск, Россия, доктор технических наук, Minker V.M. (wolfgang.minker@uni-ulm.de) - Ульмский университет (доктор-инженер, профессор ), Ульм, Германия | |
| Ключевые слова: verarbeiten von natürlicher sprache., einschätzung der relevanz von terms, rufklassifizierung |
|
| Keywords: natural language processing, term relevance estimation, call classification |
|
| Количество просмотров: 5474 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
Die Aufgabenstellung beim Rufrouting bei natürlich gesprochener ist ähnlich den Aufgaben der Kategorisierung (Klassifizierung) von Dokumenten. Es gibt allerdings etliche Unterschiede. Im Gegensatz zur Kategorisierung von Dokumenten, bei der in der Regel eine erhebliche Anzahl von Terms (Wörtern) vorhanden ist, gibt es beim Rufrouting wesentlich weniger Terms. Häufig kann das Exemplar aus der Klassifizierung aus einem einzigen Wort bestehen. In [1–7] werden diverse Methoden zur Lösung analoger Aufgaben vorgestellt, diese beruhen auf Algorithmen zur Lösung klassische Klassifizierungsaufgaben, berücksichtigen jedoch die Spezifizität des Call Routings. Eine erhebliche Anzahl solcher Methoden verwendet den Begriff der Termrelevanz. Es werden Diverse Methodiker zur Bewertung einer solchen Relevanz angeboten. In dieser Arbeit wird eine neue Methode zur Bewertung der Termrelevanz vorgestellt, die auf einer Modifizierung der Methode zur Bewertung der Relevanz von fließenden Regeln im Fuzzy-Klassifikator [8] für die Aufgabenstellung beim Rufrouting beruht. In der Arbeit wird ebenfalls eine Dekomposition der Aufgabenstellung beim Rufrouting auf die konsekutive Lösung von zwei Klassifizierungsaufgaben vorgestellt. In der ersten Etappe wird die Zugehörigkeit des Anrufes zur «residualen» (nicht informativen) Klasse definiert. Sollte eine solche Zugehörigkeit nicht bestätigt werden, erfolgt in der zweiten Etappe eine Klassifizierung, die darauf gerichtet ist, das Anrufe einer informativen Klassen zuzuordnen. Eine solche Dekomposition ergibt einen Sinn, denn die «residuale» Klasse enthält eine erhebliche Anzahl an Terms, die nicht in den anderen Klassen anzutreffen und die in ihrer Zusammensetzung inhomogen sind. Somit besteht das Ziel der vorliegenden Arbeit darin, die Effizienz der Lösung von Aufgaben beim Rufrouting durch die Anwendung der neuen Methode zur Bewertung der Termrelevanz zu erhöhen, sowie in der Dekomposition der ursprünglichen Aufgabenstellung in zwei Etappen mit individueller Definition der «residualen» Klasse. Das genannte Ziel wird durch die folgenden Aufgabenstellung der Untersuchung vorbestimmt: – Findung der praktischen Aufgaben beim Rufrouting und Vorverarbeitung der Daten; – Umsetzung der vorgestellten Methode zur Lösung von Aufgaben beim Rufrouting; – Durchführung von numerischen Untersuchungen, die einen Vergleich der vorgestellten Methode mit konventionellen Methoden beinhaltet. Beschreibung der untersuchten Aufgabenstellung beim Rufrouting und Vorverarbeitung der Daten Die Daten zur Lösung der Aufgabenstellung beim Rufrouting wurden von der Firma «Speech Cycle» (Deutschland) zur Verfügung gestellt. Die Daten bestehen in bereits in Textform übertragene Aufzeichnungen von Telefonaten mit der Servicestelle. Die Anrufe können zu einer von 20 Klassen zugeordnet werden: «Mitarbeiter», «Zahlungen», «Telefon», «Internet» usw. Unter diesen 20 Klassen ist ebenfalls eine «residuale» Klasse vertreten, zu der sinnlose oder nicht eindeutige Anrufe gehören. Die Auswahl besteht aus 24 458 Aufzeichnungen, von denen 90 % als Trainings Material verwendet wird, und 10 % für Prüfungszwecke. Die Zuordnung der jeweiligen Aufzeichnung zu einer bestimmten Klasse ist von Experten vorgenommen worden. Die Vorverarbeitung der Daten in der Aufgabenstellung beim Rufrouting besteht darin, für jeden Anruf einen Vektor von Merkmalen zu bilden, die Wörter oder Sätze in jedem Anruf charakterisieren. In diesem Falle wurde jedes Rufexemplar aus der Schulungs- und der Prüfungsauswahl ins Verhältnis zu einem Zeilenbinär gesetzt, dessen Länge gleich dem Vokabular der Aufgabenstellung ist (gleich der Zahl aller Wörter, die in der Textauswahl anzutreffen sind). Null bedeutet das Nichtvorhandensein von Wörtern, eins bedeutet dementsprechend deren Vorhandensein. In dieser Aufgabenstellung lag der Umfang des Vokabulars bei 3 294 Wörtern. Gesondert sind die Eigenschaften der «residualen» Klasse zu betrachten. Diese Klasse ist am häufigsten anzutreffen (27 % der Elemente der Schulungsauswahl). Zudem sind 45 % der Wörter des Vokabulars nur in der «residualen» Klasse anzutreffen und erscheinen nicht in den informativen Klassen. Eine solche Inhomogenität der «residualen» Klasse und deren merkbare Unterschiede zu den informativen Klassen haben die Anwendung der Dekomposition für die Lösung der Aufgabenstellung beim Rufrouting erforderlich gemacht.
Vorgeschlagene Methode zur Lösung der Aufgabenstellung beim Rufrouting Als Grundlage für die neue Methode zur Bewertung der Termrelevanz wurde die Formel zur Bewertung der Relevanz von fließenden Regeln im Fuzzy-Klassifikator genommen [8, 9]. Dabei wurde die Funktion der Zugehörigkeit von nicht exakten Terms gegen die Häufigkeit des Antreffens der Terms (Wörter) in jeder Klasse ersetzt. Führen wir die folgenden Bezeichnungen ein: L – Anzahl an Klassen; ni – Anzahl der Elemente der i. Klasse in der Schulungsauswahl; Nij – Anzahl des Vorkommens des j. Worts aus dem Vokabular in allen Elementen der i. Klasse in der Schulungsauswahl; Die Bewertung der Relevanz des j. Terms erfolgt nach der Formel:
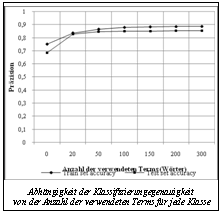
Nach dieser Formel ist die Relevanz des Terms umso höher, je charakteristischer das betreffende Wort für seine Klasse ist (Relevanz gleich 1, wenn das Wort nur in seiner Klasse anzutreffen ist und in den übrigen Klassen fehlt; Null, wenn das Wort gleich oft in allen Klassen anzutreffen ist). Die entscheidende Regel funktioniert nach dem folgenden Prinzip. Für alle Klassen sei der Parameter Im Verlauf der numerischen Untersuchungen stellte sich heraus, dass es ausreicht, eine begrenzte Anzahl von Wörtern bei der Berechnung des Parameters Ai с mit den besten Produktwerten für RjCj zu verwenden. Zur Lösung dieser Aufgabe erschient es ausreichend, 50 Wörter für jede Klasse zu verwenden. Eine Erhöhung der angewandten Regeln über diese Zahl hinaus führt nicht zu einer wesentlichen Erhöhung der Klassifizierungegenauigkeit (s. Abb.). Angesichts der Besonderheiten der «residualen» Klasse wurde vorgeschlagen, eine Dekomposition der Aufgabenstellung beim Rufrouting auf die konsekutive Lösung von zwei Klassifizierungsaufgaben vorzunehmen. In der ersten Etappe wird die Zugehörigkeit des Rufexemplars zur «residualen» (nicht informativen) Klasse definiert. Sollte eine Bestätigung für eine solche Zugehörigkeit fehlen, erfolgt in der zweiten Etappe einer Klassifizierung, die darauf ausgerichtet ist, das Rufexemplar einer der informativen Klassen zuzuordnen. Die Zweckmäßigkeit dieser Überlegung wird durch zahlenmäßige Untersuchungen bestätigt (s. Tab.). Ergebnisse der numerischen Untersuchungen
Ergebnisse der numerischen Untersuchungen Die vorgeschlagene Methode wurde anhand der untersuchten Aufgabenstellung für das Rufrouting mit und ohne Dekomposition getestet. Ebenso wurde eine vergleichende Untersuchung mit Standardklassifizierungsmethoden vorgenommen, die für die Lösung der Aufgabenstellung zur Anwendung kommen können, wie: – Methode der nächsten Nachbarn (Anzahl der Nachbarn von 1 bis 15); – Bayessche Methode mit Laplace-Korrektur; – Bayessche Methode ohne Laplace-Korrektur; – Lösungsbaum; – auflösende Induktion; – Perzeptron. Die Ergebnisse der vergleichenden Untersuchungen sind in der Tabelle dargestellt. Aus der Tabelle wird die Effizienz der vorgeschlagenen neuen Methode bei Nutzung der Dekomposition der Aufgabenstellung mit gesonderter Herausstellung der «residualen» Klasse ersichtlich. Somit konnte ein neuer Algorithmus zur Lösung von Aufgaben beim Rufrouting vorgeschlagen und umgesetzt werden, dessen Unterscheidungsmerkmale sind: neue Methode zur Bewertung der Termrelevanz, die auf der Nutzung von Werten der relativen Antreffhäufigkeit der Terms in den Klassen zur Bewertung der Relevanz von fließenden Regeln im Fuzzy-Klassifikator mit Ersetzen der Funktionswerte für die Zugehörigkeit basiert; Dekomposition der Ausgangsaufgabenstellung in zwei Etappen mit gesonderter Herausstellung der «residualen» Klasse, die nicht informative Rufexemplare enthält, unter Berücksichtigung der Spezifik und der Inhomogenität dieser Klasse. Der Vergleich mit den für die Lösung der genannten Aufgabenstellung beim Rufrouting verwendeten Standardklassifizierungsmethoden, demonstriert den Vorteil der vorgeschlagenen Methode. Referenzen 1. Carpenter B., Chu-Carroll J., Proc. ICSLP-98, Sydney, Australia, Dec. 1998, pp. 2059–2062. 2. Chu-Carroll J., Carpenter B., Computational Linguistics, 1999, Vol. 25, no. 3, pp. 361–388. 3. Lee C.-H., Carpenter B., Chou W., Chu-Carroll J., Reichl W., Saad A., Zhou Q., Speech Communication, 2000, Vol. 31, no. 4, pp. 309–320. 4. Kuo H.-K., Lee C.-H., Proc. of ICSLP’00, 2000. 5. Gorin A. L., Riccardi G., Wright J.H., Speech Communication, 1997, Vol. 23, pp. 113–127. 6. Wright J.H., Gorin A.L., Riccardi G., Proc. Eurospeech-97, Sept. 1997, pp. 1419–1422. 7. Schapire R.E., Singer Y., Machine Learning, 2000, Vol. 39, no. 2/3, pp. 135–168. 8. Ishibuchi H., Nakashima T., Murata T., Transactions on Systems, Man, and Cybernetics, 1999, Vol. 29, pp. 601–618. 9. Sergienko, R. Proc. of Advances in Swarm Intelligence: 3rd Int. Conference (ICSI 2012), Shenzhen, China, 2012, Part I, Springer, pp. 452–459. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Wir möchten die Aufmerksamkeit darauf richten, dass in der vorliegenden Arbeit der Schwerpunkt auf das automatische Verfahren zur Lösung der Aufgaben beim Rufrouting gelegt wurde Dadurch sind keine zusätzlichen linguistischen Kenntnisse (morphologische Wortanalyse, Korrektur von orthographischen Fehlern, Filter in der Art der Löschung von Pronomen oder Vorsilben usw.) erforderlich. Somit wird bei der Lösung der Aufgabe das gesamte Vokabular verwendet, und die Wörter im Vokabular bleiben in unveränderter Form enthalten.
Wir möchten die Aufmerksamkeit darauf richten, dass in der vorliegenden Arbeit der Schwerpunkt auf das automatische Verfahren zur Lösung der Aufgaben beim Rufrouting gelegt wurde Dadurch sind keine zusätzlichen linguistischen Kenntnisse (morphologische Wortanalyse, Korrektur von orthographischen Fehlern, Filter in der Art der Löschung von Pronomen oder Vorsilben usw.) erforderlich. Somit wird bei der Lösung der Aufgabe das gesamte Vokabular verwendet, und die Wörter im Vokabular bleiben in unveränderter Form enthalten. – relative Häufigkeit des Vorkommens des j. Worts in der i. Klasse;
– relative Häufigkeit des Vorkommens des j. Worts in der i. Klasse;  ;
;  – Nummer der Klasse, die dem j Wort entspricht.
– Nummer der Klasse, die dem j Wort entspricht.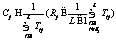 .
.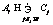 gegeben. Weiter wird die Klasse der Sieger bestimmt, in der dieser Parameter die höchste Relevanz hat:
gegeben. Weiter wird die Klasse der Sieger bestimmt, in der dieser Parameter die höchste Relevanz hat:  .
.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3388 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
| Статья опубликована в выпуске журнала № 1 за 2013 год. [ на стр. 88-90 ] |
Назад, к списку статей