Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метод решения задач маршрутизации вызовов на основе новой оценки релевантности термов
Аннотация:Маршрутизация вызовов, основанная на обработке естественного языка, представляет собой сложную и перспек-тивную область исследований в интеллектуальных машинных методах и интерпретации языка. Эта сложность обусловлена трудностями в автоматической интерпретации естественного языка. В данной статье сделан акцент на разработку алгоритмов, по эффективности способных превзойти существующие методы на больших БД и не тре-бующих морфологического анализа или фильтра в виде стоп-слова. В предлагаемом подходе осуществляется деком-позиция задачи классификации, к которой сводится маршрутизация вызовов, на две стадии: обнаружение остаточного класса и отнесение объектов к значимым классам. К остаточному классу относятся объекты, которые нельзя отнести к значимым классам или же можно отнести сразу к нескольким значимым классам. Предлагается новая формула оценки релевантности термов при определении значимых классов, являющаяся модификацией оценки релевантности нечетких правил в нечетком классификаторе. Используя эту формулу только для 300 наиболее часто встречающихся слов для каждого класса, достигнута точность классификации 85,55 %.
Abstract:Call routing based on Natural Language Understanding remains a complex and challenging research area in machine intelligence and language understanding. This challenge is due to the difficulty in automated natural language understanding. This paper focuses on the design of algorithms which are able to outperform existing methods on large dataset and do not require morphological and stop-word filtering. The proposed approach decomposes the classification problem into two steps: detection the residual class and utterance categorization to meaningful classes. Class residual includes utterances which cannot be assigned to any useful class or which can be assigned to more than one class. We present the new formula for term relevance estimation which is a modification of fuzzy rules relevance estimation for fuzzy classifier. Using these formulae for only 300 frequent words for each class we achieve an accuracy rate of 85,55 %.
| Авторы: Гасанова Т.О. (tatiana.gasanova@uni-ulm.de) - Ульмский университет (аспирант ), Ульм, Германия, Сергиенко Р.Б. (romaserg@list.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева, г. Красноярск, Россия, Семенкин Е.С. (styugin@rambler.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева, г. Красноярск, Россия, Минкер В.М. (wolfgang.minker@uni-ulm.de) - Ульмский университет (доктор-инженер, профессор ), Ульм, Германия | |
| Ключевые слова: обработка естественного языка., оценка релевантности термов, классификация вызовов |
|
| Keywords: natural language processing, term relevance estimation, call classification |
|
| Количество просмотров: 7122 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
Задача маршрутизации вызовов на естественном языке близка к задачам категоризации (классификации) документов, однако имеются некоторые отличия. При категоризации документов, как правило, присутствует значительное число термов (слов), а при маршрутизации вызовов их гораздо меньше, причем зачастую экземпляр для классификации может быть представлен одним единственным словом. В [1–7] представлены различные методы решения подобных задач, основанные на использовании алгоритмов решения классических задач классификации с учетом специфики задач маршрутизации вызовов. Значительное число таких методов использует понятие релевантности термов, поэтому предлагаются различные методики оценки такой релевантности. В данной статье представлен новый метод оценки релевантности термов, основанный на модификации метода оценки релевантности нечетких правил в нечетком классификаторе [8] для задач маршрутизации вызовов. В работе также предлагается декомпозиция задачи маршрутизации вызовов на последовательное решение двух задач классификации. На первом этапе определяется принадлежность экземпляра вызова к остаточному (неинформативному) классу. В случае неподтверждения такой принадлежности на втором этапе осуществляется классификация, направленная на отнесение экземпляра вызова к одному из информативных классов. Такая декомпозиция имеет смысл, так как остаточный класс содержит значительное число термов, не встречающихся в других классах, и неоднороден по своему составу. Таким образом, цель настоящей работы – повышение эффективности решения задач маршрутизации вызовов за счет использования нового метода оценки релевантности термов, а также декомпозиции исходной задачи на два этапа с отдельным определением остаточного класса. Данная цель предопределила следующие задачи исследования: – поиск практической задачи маршрутизации вызовов и выполнение предобработки данных; – реализация предложенного подхода к решению задач маршрутизации вызовов; – проведение численных исследований, включающих сравнение предлагаемого подхода с известными методами. Описание рассматриваемой задачи маршрутизации вызовов и предобработка данных Данные для решения задачи маршрутизации вызовов были предоставлены компанией Speech Cycle (Германия). Это уже распознанные в виде текста записи телефонных звонков в сервисную службу. Вызовы относятся к одному из 20 классов: «оператор», «платеж», «телефон», «Интернет» и т.п. В числе этих классов и остаточный класс, к которому относятся бессмысленные или неоднозначные вызовы. Выборка представлена 24 458 записями, 90 % из которых используются в качестве обучающей выборки, 10 % – в качестве тестовой. Соответствие записей определенным классам проверялось экспертами. Предобработка данных в задачах маршрутизации вызовов заключается в формировании для каждого экземпляра вектора признаков, характеризующих наличие тех или иных слов или фраз в каждом вызове. В данном случае каждому экземпляру из обучающей и тестовой выборки была поставлена в соответствие бинарная строка, длина которой равна словарю задачи (числу всех слов, встречающихся в тестовой выборке). Ноль означает отсутствие слова, единица – его присутствие. В данной задаче объем словаря составил 3 294 слова. Отдельно следует отметить свойства остаточного класса. Данный класс является наиболее часто встречающимся (27 % элементов обучающей выборки). Кроме того, 45 % слов словаря встречаются только в остаточном классе и не появляются в информативных классах. Такая неоднородность остаточного класса и его заметные отличия от информативных обусловили использование в дальнейшем декомпозиции решения задачи маршрутизации вызовов. Обратим внимание, что в настоящей работе сделан акцент на автоматические процедуры решения задач маршрутизации вызовов, не требующие использования дополнительных лингвистических знаний (морфологического анализа слов, исправления орфографических ошибок, фильтров в виде удаления местоимений, предлогов и т.п.). Таким образом, при решении задачи используется весь словарь целиком, слова в словаре представлены в неизменном виде. Предлагаемый подход к решению задачи маршрутизации вызовов В качестве основы для нового метода оценки релевантности термов взята формула оценки релевантности нечетких правил в нечетком классификаторе [8, 9]. При этом проведена замена функции принадлежности нечетких термов на частоту встречаемости термов (слов) в каждом классе. Введем следующие обозначения: L – число классов; ni – число элементов i-го класса в обучающей выборке; Nij – число появлений j-го слова из словаря во всех элементах i-го класса в обучающей выборке; Оценка релевантности j-го терма будет определяться по формуле
Согласно этой формуле релевантность терма будет тем выше, чем характернее данное слово для своего класса (релевантность равна 1, если слово встречается только в своем классе и отсутствует в остальных; равна нулю, если слово одинаково часто встречается во всех классах). Решающее правило работает по следующему принципу. Для всех классов считаем показатель
Ввиду особенностей остаточного класса предложена декомпозиция задачи маршрутизации вызовов на последовательное решение двух задач классификации. На первом этапе определяется принадлежность экземпляра вызова остаточному (неинформативному) классу. В случае отсутствия подтверждения принадлежности на втором этапе осуществляется классификация, направленная на отнесение экземпляра вызова к одному из информативных классов. Целесообразность такого предложения подтверждена численными исследованиями (см. табл.).
Результаты численных исследований Предложенный метод был протестирован на рассматриваемой задаче маршрутизации вызовов с декомпозицией и без таковой. Также проведено сравнительное исследование со стандартными методами классификации, используемыми для решения задачи, а именно: – метод ближайших соседей (число соседей от 1 до 15); – Байесовский подход с коррекцией Лапласа; – Байесовский подход без коррекции Лапласа; – деревья решений; – решающая индукция; – персептрон. Результаты сравнительного исследования приведены в таблице, из которой можно сделать вывод об эффективности предлагаемого нового подхода при использовании декомпозиции задачи с отдельными выделением остаточного класса. Таким образом, авторами предложен и реализован новый алгоритм решения задач маршрутизации вызовов, отличительными особенностями которого являются новый метод оценки релевантности термов, основанный на использовании оценки релевантности нечетких правил в нечетком классификаторе с заменой значений функций принадлежности значениями относительной частоты встречаемости термов в классах, а также декомпозиция исходной задачи на два этапа с отдельным выделением остаточного класса, содержащего неинформативные экземпляры, ввиду специфичности и неоднородности этого класса. Сравнение со стандартными методами классификации, используемыми для решения указанной задачи маршрутизации вызовов, показывает преимущество предлагаемого подхода. Литература 1. Carpenter B., Chu-Carroll J., Proc. ICSLP-98, Sydney, Australia, Dec. 1998, pp. 2059–2062. 2. Chu-Carroll J., Carpenter B., Computational Linguistics, 1999, Vol. 25, no. 3, pp. 361–388. 3. Lee C.-H., Carpenter B., Chou W., Chu-Carroll J., Reichl W., Saad A., Zhou Q., Speech Communication, 2000, Vol. 31, no. 4, pp. 309–320. 4. Kuo H.-K., Lee C.-H., Proc. of ICSLP’00, 2000. 5. Gorin A.L., Riccardi G., Wright J.H., Speech Communication, 1997, Vol. 23, pp. 113–127. 6. Wright J. H., Gorin A. L., Riccardi G., Proc. Eurospeech-97, Sept. 1997, pp. 1419–1422. 7. Schapire R. E., Singer Y., Machine Learning, 2000, Vol. 39, no. 2/3, pp. 135–168. 8. Ishibuchi H., Nakashima T., Murata T., Transactions on Systems, Man, and Cybernetics, 1999, Vol. 29, pp. 601–618. 9. Sergienko R., Proc. of Advances in Swarm Intelligence: 3rd Int. Conference (ICSI 2012), Shenzhen, China, 2012, Part I, Springer, pp. 452–459. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
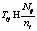 – относительная частота встречаемости j-го слова в i-м классе;
– относительная частота встречаемости j-го слова в i-м классе; 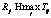 ;
; 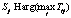 – номер класса, соответствующий j-му слову.
– номер класса, соответствующий j-му слову. .
.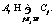 Далее определяется класс-победитель с наибольшим значением такого показателя:
Далее определяется класс-победитель с наибольшим значением такого показателя: 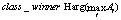 .
.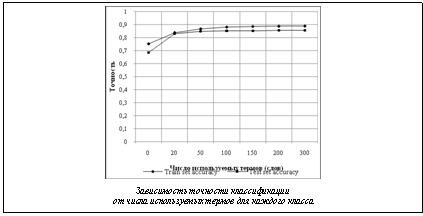 В ходе численных исследований было выяснено, что достаточно использовать ограниченное число слов при вычислении показателя Ai с наилучшими значениями произведения RjCj. Для данной задачи это использование 50 слов для каждого класса. Превышение такого числа используемых правил не приводит к существенному повышению точности классификации (см. рис.).
В ходе численных исследований было выяснено, что достаточно использовать ограниченное число слов при вычислении показателя Ai с наилучшими значениями произведения RjCj. Для данной задачи это использование 50 слов для каждого класса. Превышение такого числа используемых правил не приводит к существенному повышению точности классификации (см. рис.).| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3389 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
| Статья опубликована в выпуске журнала № 1 за 2013 год. [ на стр. 90-93 ] |
Назад, к списку статей