Авторитетность издания

Добавить в закладки
Следующий номер на сайте


О методе построения адаптивного агрегированного алгоритма кэширования
Аннотация:Рассматриваются проблемы построения алгоритмов кэширования данных применительно к архитектуре клиент-сервер. На сегодняшний день проблема построения алгоритмов кэширования весьма актуальна, предложено доста-точно много их реализаций, однако поле для исследований остается. Особенно актуальным является построение адаптивных алгоритмов кэширования. Авторы предлагают адаптировать алгоритмы путем ввода в агрегированную модель алгоритма кэширования дополнительного управляющего параметра, отвечающего за степень влияния агре-гируемых алгоритмов.
Abstract:The paper is focused on the problem of data caching in the client-server architecture. Today the problem of constructing caching algorithms is very relevant and a lot of implementations are proposed, but there is a field for further research. The construction of adaptive caching algorithms is especially important. In this paper we generalize adaptive algorithms by adding a control parameter in an aggregate model of the caching algorithm that is responsible for the degree of influence of aggregation algorithms.
| Авторы: Бурилин А.В. (aburilin@naumen.ru) - Тверской государственный университет (ст. преподаватель), Тверь, Россия, Шефова Н.А. () - Тверской государственный университет (ст. преподаватель), Тверь, Гордеев Р.Н. (rgordeev@naumen.ru) - Тверской государственный университет, Тверь, Россия, кандидат физико-математических наук | |
| Ключевые слова: кэш-память., свертка, агрегирование, кэширование, архитектура клиент-сервер |
|
| Keywords: the cache memory, convolution, aggregation, caching, client-server architecture |
|
| Количество просмотров: 8329 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
Построение распределенных информационных систем, работающих с БД, обусловливает необходимость широкого использования архитектуры клиент-сервер. Ее основу составляют принципы организации взаимодействия клиента и сервера при управлении БД. Согласно эталонной модели архитектуры открытых систем OSI функция управления БД относится к прикладному уровню. СУБД как программа, поддерживающая интерфейс с пользователем, реализует следующие основные функции: управление данными, находящимися в базе, обработка информации с помощью прикладных программ, представление информации в удобном для пользователя виде. При размещении СУБД в сети возможны различные варианты распределения функций по узлам сети. В зависимости от числа узлов сети, между которыми выполняется распределение функций СУБД, можно выделить двухзвенные и трехзвенные модели. Место разрыва функций соединяется коммуникационными элементами (средой передачи информации в сети). Двухзвенные модели соответствуют распределению функций СУБД между двумя узлами сети. Компьютер (узел сети), на котором обязательно присутствует функция управления данными, называют компьютером-сервером. Компьютер, близкий к пользователю и обязательно представляющий информациию, называют компьютером-клиентом [1]. Наиболее типичными вариантами разделения функций между компьютером-сервером и компьютером-клиентом являются следующие: 1) распределенное представление: компьютер-сервер – управление данными, обработка, представление; компьютер-клиент – представление; 2) удаленное представление: компьютер-сервер – управление данными, обработка; компьютер-клиент – представление; 3) распределенная функция: компьютер-сервер – управление данными, обработка; компьютер-клиент – обработка, представление; 4) удаленный доступ к данным: компьютер-сервер – управление данными; компьютер-клиент – обработка, представление; 5) распределенная БД: компьютер-сервер – управление данными; компьютер-клиент – управление данными, обработка, представление. Перечисленные способы распределения функций в системах с архитектурой клиент-сервер иллюстрируют различные варианты: от мощного сервера, когда практически вся работа производится на нем, до мощного клиента, когда большая часть функций выполняется на рабочей станции, а сервер обрабатывает поступившие к нему по сети SQL-вызовы. В отношении использования систем кэширования рассмотренные пять вариантов реализации двухзвенной модели архитектуры клиент-сервер далеко не равноценны. Первые две реализации практически полностью моделируются файл-серверной архитектурой в сочетании с терминальной системой. Отличительной особенностью клиент-серверных реализаций является поддержка многопользовательского режима внутри одного экземпляра СУБД на сервере, а не репликация полной СУБД на сервере для каждого клиента, как это делается с помощью терминальной системы. Следствием этого являются более рациональное использование ресурсов сервера и, следовательно, повышение эффективности кэш-систем. В следующих трех вариантах реализации двухзвенной модели клиент-сервер частично или полностью обработка выполняется на клиенте. В этом случае можно установить кэш-систему и на клиенте. Перенос обработки на сторону клиента повышает параллелизм в обработке информации, разделяя обработку между клиентом и сервером. Это приводит к сокращению времени обработки. Увеличение роли компьютера-клиента в обработке информации (четвертый и пятый варианты реализации двухзвенной модели) может привести и к увеличению сетевого трафика, что является фактором, уменьшающим общую скорость работы системы обработки и хранения информации. В этом случае эффективным решением, повышающим скорость обработки, является установка кэш-системы на клиенте, что приводит к распределенной БД. Недостатком такого решения, кроме усложнения клиентского приложения, является усложнение системы синхронизации центральной БД с репликациями на клиентах. Таким образом, проблемы кэширования весьма актуальны и их решения находят свое практическое применение в архитектуре современных информационных систем. Математическая модель алгоритма кэширования Следуя [2], сформулируем математическую модель алгоритма кэширования. Для этого введем следующие понятия: – множество объектов системы N={1, 2, ..., n}; – множество адресов кэш-памяти М={1, 2, ..., m}; – поток запросов (трасса) на доступ к объектам ω=(r1, r2, …, rt, ..., rT), где rt∈N – объект, запрошенный от кэш-системы в момент времени t; – множество подмножеств множества объектов N, которые могут быть расположены в кэш-памяти М: Ωm={S | S⊆N Ù | S |≤m}. Большинство алгоритмов кэширования для объектов, находящихся в кэш-памяти М, явно или неявно поддерживают некоторый рейтинг объектов. Данный рейтинг служит основанием для принятия решения об исключении некоторого объекта из кэш-памяти при кэш-промахе. В процессе ра- боты кэш-системы по некоторым законам изменяется и рейтинг объектов в кэше. Упорядоченную последовательность рейтингов в совокупности с некоторой дополнительной информацией об объектах из кэша будем называть вектором состояния управления алгоритма кэш-памяти, или просто состоянием управления (control state). Примером рейтинга объектов из кэша может быть частота появления в запросах соответствующего объекта. Чтобы алгоритм кэширования начал работу, вектор состояния управления должен быть проинициализирован. Обозначим через q0 начальное значение вектора состояния управления, через Q – множество состояний управления (set of control states). Определение 1. Алгоритмом кэширования будем называть упорядоченную тройку A=(Q, q0, g), где Q – множество состояний управления; q0ÎQ – начальное состояние управления; g – отображение перехода, обеспечивающее по состоянию кэш-памяти, состоянию управления и запрошенному объекту получение нового состояния кэш-памяти, содержащего запрошенный объект, и нового состояния управления. В этом случае g – есть отображение вида g: Ωm×Q×N→Ωm×Q;
d: Ωm×Q→N. Пара (S, q) в модели алгоритма кэширования называется конфигурацией алгоритма. Тогда d – отображение из конфигурации во множество объектов, позволяющее однозначно найти удаляемый из кэш-памяти объект (жертву) в случае кэш-промаха и заполненной кэш-памяти. Агрегированный алгоритм кэширования Рассмотрим построение математической модели агрегированного алгоритма на примере агрегирования двух базовых алгоритмов. Использование в модели только двух базовых алгоритмов не уменьшает общности решаемой задачи, и получить агрегированную модель более чем двух базовых алгоритмов несложно. Пусть имеется информационная система, объекты которой образуют множество N: N={1, 2, ..., n). В системе имеется кэш-система с множеством М адресов кэш-памяти: М={1, 2, ..., m). Кэш-система находится под воздействием потока запросов к объектам: ω=(r1, r2, ..., rt , ..., rT), где rt – объект, запрошенный у кэш-системы в момент времени t. Обозначим через Ωm множество подмножеств множества N объектов системы, которые могут быть расположены в кэш-памяти М: Ωm={S | S⊆N Ù | S |≤m}. Пусть кэш-система при решении задачи о выборе жертвы может использовать два базовых алгоритма кэширования А1 и А2: А1=(Q1, q10, g1), А2=(Q2, q20, g2), где Q1, Q2 – множества состояний управления алгоритмов А1 и A2; q10, q20 – начальные состояния управления алгоритмов А1 и A2; g1, g2 – отображения перехода алгоритмов А1 и А2, которые по состоянию кэш-памяти и соответствующим состояниям управления q1 и q2 позволяют получить новое состояние кэш-памяти и новое состояние управления q11 и q21 соответственно для алгоритмов A1 и A2: – отображение выбора жертвы по A1: g1: Ωm×Q1×N→Ωm×Q1,
d1: Ωm×Q1→N; – отображение выбора жертвы по A2: g2: Ωm×Q2×N→Ωm×Q2,
d2: Ωm×Q2→N. Агрегированным алгоритмом А базовых алгоритмов А1 и A2 будем называть упорядоченное множество A=(Q1, Q2, q10, q20, g), где g – отображение перехода агрегированного алгоритма; g1: Ωm×Q1×Q2×N→Ωm×Q1×Q2. При этом (S1, q11, q21)=g(S, q1, q2, x);
где x – объект, запрошенный у кэш-системы в момент t; S – состояние кэш-памяти в момент t; S1 – состояние кэш-памяти в момент времени t+1; qi – состояние управления алгоритма Аi в момент t; qi1 – состояние управления алгоритма Аi в момент t+1; R – отображение выбора жертвы: R: Ωm×Q1× ×Q2→N. Отображение R по состоянию кэш-памяти и состояниям управления q1 и q2 алгоритмов A1 и А2 позволяет выбрать объект-жертву y из состояния кэш-памяти S. Из данной модели видно, что основная проблема агрегирования заключается в выборе отображения R, которое обеспечивает выбор жертвы, опираясь на состояния управления q1 и q2 базовых алгоритмов А1 и А2. Понятно, что аналогичным образом можно получить свертки трех и более базовых алгоритмов. Адаптивный агрегированный алгоритм кэширования Рассмотрим проблему управления степенью влияния каждого из алгоритмов, участвующих в формировании свертки. Для этого введем понятие нормированного управления степенью влияния алгоритмов А1 и А2. Пусть безразмерная переменная λÎ[0, 1] отображает степень влияния алгоритмов A1 и A2 на принятие решения о выборе жертвы отображением R. Переменную λ будем называть параметром управления степенью влияния алгоритмов А1 и А2. Если единичный отрезок [0, 1] обозначить через I, I=[0, 1], тогда R примет вид R: Ωm×Q1× ×Q2×I→N, y=R(S, q1, q2, λ). Пусть при этом R обладает следующими свойствами: R(S, q1, q2, 0)=d2(S, q2), R(S, q1, q2, 1)=d1(S, q1), где d1 и d2 – отображения (1) и (2). В этом случае отображение перехода для свертки A базовых алгоритмов A1 и A2 имеет вид g1: Ωm×Q1× Q2×I×N→Ωm×Q1×Q2. Тогда (S1, q11, q21)=g(S, q1, q2, λ, x), где λ – значение параметра управления степенью влияния алгоритмов A1 и A2 в момент времени t:
Очевидно, что свертка A с функцией перехода g(S, q1, q1, λ, x) обобщает такие известные алгоритмы кэширования, как LRFU и ARC [3–5]. В работе предложены модели агрегированного алгоритма и адаптивного агрегированного алгоритма, которые позволяют получать свертки любого количества произвольных алгоритмов кэширования. Разработанная математическая модель, полученная методом стохастического агрегирования, является формализованной основой для создания новых алгоритмов кэширования и изучения их свойств. Так, остается вопрос дальнейшего исследования влияния параметра λ на полученные виды алгоритмов кэширования и их свойства. Предметом дальнейших исследований может стать и проблема рандомизации свертки путем введения функции распределения значений параметра λ и изучения свойств полученных в результате агрегатов. Литература 1. Подвальный C.Л., Сергеева Т.И., Гранков М.В. Базы данных: модели данных, SQL, проектирование: Учеб. пособие. Р-н-Д: Издат. центр ДГТУ, 2007. 202 с. 2. Aho A.V., Denning P.J. and Ullman J.D., J. ACM, 1971, Vol. 18, no. 1. 3. Lee D., Choi D., Kim J.-H., Noh S.H., Min S.L., Cho Y., Kim C.S., IEEE Trans. Computers, 2001, Vol. 50, no. 12. 4. Megiddo N., Modha D.S., IEEE Computer, 2004, Vol. 37, no. 4, pp. 58–65. 5. Megiddo N. and Modha D.S., Simple Adaptive Cache Outperforms LRU, 2003, IBM Research Report, Computer Science. |

 (1)
(1) (2)
(2)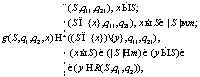
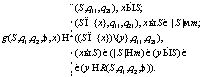
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3391 |
Версия для печати Выпуск в формате PDF (5.29Мб) Скачать обложку в формате PDF (1.21Мб) |
| Статья опубликована в выпуске журнала № 1 за 2013 год. [ на стр. 98-101 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: