Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Системный подход к построению модели данных эволюционных баз данных
Аннотация:
Abstract:
| Авторы: Дрождин В.В. (drozhdin@yandex.ru) - Пензенский государственный педагогический университет им. В.Г. Белинского, г. Пенза, Россия, кандидат технических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Всего комментариев: 1 Количество просмотров: 11888 |
Версия для печати Выпуск в формате PDF (2.31Мб) |
Автоматизированная информационная система (АИС) предназначена для удовлетворения информационных потребностей пользователей путем решения задач сбора, хранения, обработки и выдачи информации. АИС получили очень широкое распространение как самостоятельные системы, а также как основа для создания других автоматизированных систем. Наибольшую часть АИС составляет информация, оптимальность организации и эффективность обработки которой существенно влияют на эффективность всей системы. Традиционный способ построения баз данных (БД), систем управления БД (СУБД) и АИС базируется на проектировании и создании хорошей системы, способной осуществлять автоматизацию информационных процессов с требуемым уровнем качества. Гибкость системы обеспечивается реорганизацией БД, заменой СУБД на более новую версию и изменением программного обеспечения АИС. Такой подход вполне приемлем для автоматизации отдельных несложных информационных задач, требующих создания небольших локальных АИС. Однако это положение принципиально меняется, например, при комплексной автоматизации информационных процессов предприятия, требующей создания большой корпоративной АИС с распределенной БД. Использование CASE-средств на этапе проектирования, стандартизации интерфейса между подсистемами, многоплатформенной реализации, вычислительных средств большой мощности и компьютерных сетей, а также поэтапной разработки и внедрения систем позволяют создавать более сложные АИС, но не дают возможности принципиально решить проблемы создания и функционирования больших АИС с распределенными БД. Более полное решение проблем создания больших АИС возможно на основе эволюционного принципа, предполагающего длительное существование и постепенное развитие системы в процессе функционирования. При этом первоначально созданная АИС может быть достаточно простой, но она должна качественно отличаться от традиционных систем. Развивающаяся АИС должна быть принципиально ориентирована на свое постоянное изменение без потери качества функционирования (качества обслуживания пользователей), а при функционировании в постоянных условиях должна повышать это качество. Единственным методом, обеспечивающим такое поведение АИС, является адаптация. Адаптация заключается в приспособлении системы к изменениям внешней среды и внутренней организации на основе механизмов обучения и самообучения, то есть путем сбора информации, выявления новых зависимостей и использования их в дальнейшем функционировании. Наличие самообучения имеет два последствия. Первое заключается в том, что человек (администратор системы), выступающий в качестве внешней контролирующей и управляющей системы, не может управлять АИС в реальном времени, так как компьютер способен быстро порождать и использовать большое количество зависимостей. С другой стороны, именно самообучение делает систему существенно независимой от внешней среды и обеспечивает необратимый процесс ее эволюции. В данной работе предлагается формальная теоретико-системная модель данных, предназначенная для создания эволюционных БД (ЭБД) с сохранением информации. Основные принципы организации ЭБД: - открытость структур данных вниз до самых минимальных элементов (до байтов и битов) и вверх до построения единой структуры, включающей всю БД; - высокие гибкость и устойчивость структур данных (то есть структуры должны разрешать добавление и модификацию фактов, для которых подтверждена правильность, даже с нарушением поддерживаемых отношений). Модель данных – это совокупность допустимых структур данных и операций над ними. Структура данных – это взаимосвязанная совокупность элементов данных. Построение модели данных будем осуществлять на основе общей теории систем, разработанной Ю.А. Урманцевым (см. работы: Ю.А. Урманцев. Эволюционика. Пущино. 1988, а также «Система, симметрия, гармония». М. 1988). Объект-система (OS) – это композиция, или единство элементов Система объектов одного и того же i рода (R-система, или RS) – это закономерное множество OS одного и того же качества (рода i), означающая, что каждая OS построена: - из всех или части элементов - в соответствии со всеми или частью отношений rÍRi; - в соответствии со всеми законами композиции (или их частью) zÍZi. Поэтому RS представляется четверкой вида: R=. Любой объект есть OS и каждая OS принадлежит хотя бы одной RS. Далее будем считать, что каждая OS разрабатываемой модели строится на основе всех отношений Ri, удовлетворяет всем законам композиции Zi и принадлежит строго одной RS. Поэтому модель OS будет иметь вид: S=, а в случае известной RS: S=. Введем обозначения, более привычные в программировании и теории БД: Τ=U,val=m, Fi=Ri, Pi=Zi, VALi=<Τ,Ai>=Mi, где Τ – множество допустимых типов данных; F – зависимости между данными (ассоциации, отображения, классификации, многозначные, функциональные и др.), причем наиболее сильными (логическими) являются функциональные и многозначные зависимости, а наиболее слабыми – ассоциации, позволяющие ассоциировать между собой произвольные данные; P – предикат, задающий ограничения целостности на данные; VALi – множество элементов, составляющих RS. Тогда модели OS и RS будут иметь вид: Si= или Si=, Ri=. Будем считать R-системой 0-го рода любой абстрактный тип данных (см.: М. Нагао, Т. Катаяма, С. Уэмура. Структуры и базы данных. М. 1986) с атомарными значениями данных, представленный в виде: Τ={tg}, tg=(Dg, Qg), где g – имя типа; Dg – множество атомарных элементов данных типа g; Qg – множество операций, выполняемых над элементами данных типа g. Абстрактный тип данных задает самый низкий (синтаксический) уровень представления и обработки данных. Тогда OS и RS 0-го рода, реализующие тип данных g, будут иметь вид: S0=, R0= =, где A0=g; VAL0=Dg; val0ÎVAL0; F0=Æ; P0=Æ. На 0 уровне решается задача эффективной реализации абстрактного типа данных g, определяющей способ представления значений данных и операций их обработки. Для эффективного представления, обработки и организации взаимодействия OS введем абстрактный элемент id следующим образом: idºval. Элемент id будем называть идентификатором и считать, что он не зависит от типа и структуры val и принадлежит некоторому универсальному числовому типу. Тогда модели OS и RS примут вид: S= или S=, R=. Назовем R-системой 1-го рода упорядоченное множество атомарных элементов val и эквивалентных им идентификаторов id: S1=, R1=, где A1 = gR – имя системы объектов R0, объекты S0 которой преобразуются в val1; VAL1ÍVAL0; val1ÎVAL1; F1=Æ; P1= ={ Примерами R-систем 1-го рода являются домены реляционной модели данных: списки фамилий, имен, отчеств, дат рождения. На 1 уровне решаются задачи эффективного представления, хранения и доступа к объектам S1 в системе объектов R1. Следующие, более высокие уровни организации систем будут содержать сложные элементы val, структура которых будет задаваться набором отношений (устойчивых связей, взаимосвязей) F между компонентами val'Îval и ограничениями целостности P. При этом уровень системы будет определяться мощностью взаимосвязей (обязательностью участия в них компонентов val', допустимой степенью нарушений – количеством исключений, частотой совместного использования и обработки компонентов val') и допустимой степенью разнообразия val. Уровень системы будет тем ниже, чем выше мощность связей между компонентами val' и ниже степень разнообразия val. Будем называть R-системой 2-го рода упорядоченное множество объектов S2, существующих во времени T, в каждом из которых компоненты val'Îval2 жестко взаимодействуют между собой: S2=, R2=, где A2=[gR1,gR2,…,gRn] – последовательность имен систем объектов R1, из объектов S1 которых формируется элемент val2; VAL2Í Примерами R-систем 2-го рода являются отношения реляционной БД: человек (фамилия, имя, отчество, дата рождения, номер паспорта, адрес), предприятие (название, адрес, руководитель, телефон руководителя). На 2 уровне решаются задачи эффективного выявления и поддержки отношений между данными, представления и обработки исключений, поддержки схемы данных в оптимальной форме, а также ведение динамической информационной модели предметной области с предысторией. При этом для темпоральных данных целесообразно создавать подсистемы R2' вида: S2'=, R2'=, где val2'ÎVAL2' – значение компоненты в некоторый момент времени; tÎT – начальный момент времени существования компонента val2' в S2. Будем называть R-системой 3-го рода упорядоченное множество объектов S3, каждый из которых представляет собой совокупность объектов S2 и S3', в подавляющем случае обрабатываемых и используемых совместно: S3=, R3=, где A3=[gR1,gR2,…,gRn] – последовательность имен систем объектов R2 и R3', из объектов S2 и S3' которых формируется элемент val3; VAL3Í Примерами R-систем 3-го рода являются, например, ФИО и адрес в отношении человек или сотрудник и студент, являющиеся наследниками человека. Таким образом, R-система 3-го рода позволяет, с одной стороны, декомпозировать существующие системы объектов 2 и 3 рода на более мелкие системы, но с более сильно связанными элементами, а с другой – формировать из существующих систем 2 и 3 рода более крупные при усилении связей между элементами этих систем. На 3 уровне решаются задачи эффективного выявления и поддержки отношений совместного использования данных и формирования оптимальной схемы данных с учетом совместно используемых данных. Будем называть R-системой 4-го рода единственный объект S4, представляющий собой взаимосвязанную совокупность объектов S2 и S3 и существующий автономно: S4=, R3= =, где A4=[gR1,gR2,…,gRn] – последовательность имен систем объектов R2 и R3, из объектов S2 и S3 которых формируется элемент val4; VAL4Í Примерами R-систем 4-го рода являются автономные подсистемы больших систем, или самостоятельные автоматизированные системы. Таким образом, R-система 4-го рода задает автономную (самостоятельную, целостную и относительно независимую) систему организации данных, для которой может быть разработан эффективный метод ведения и обработки данных, позволяющий системе существовать длительное (потенциально бесконечное) время. На 4 уровне решаются задачи эффективного выявления и поддержки отношений автономности объекта и предоставления эффективного интерфейса взаимодействия с внешней средой. Предложенная модель данных позволяет создавать устойчивые многоуровневые БД, допускающие хранение фактов, нарушающих зависимости, что позволяет обоснованно проводить реорганизацию и оптимизацию БД в процессе функционирования АИС. |
 , построенная по отношениям (взаимодействиям)
, построенная по отношениям (взаимодействиям)  и ограничивающим их условиям или законам композиции
и ограничивающим их условиям или законам композиции 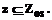 Поэтому в общем виде OS представляется тройкой: S=.
Поэтому в общем виде OS представляется тройкой: S=. , выделенных из универсума U
, выделенных из универсума U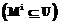 по основаниям
по основаниям  ;
; | β1 Î<ограничения на атомарные данные>} – ограничения, определяющие допустимое разнообразие объектов S1 в системе объектов R1.
| β1 Î<ограничения на атомарные данные>} – ограничения, определяющие допустимое разнообразие объектов S1 в системе объектов R1.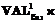
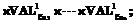 val2ÎVAL2; F2={
val2ÎVAL2; F2={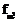 | a2Î <зависимости между элементами данных во всех val2>} – отношения (взаимосвязи) между данными типа функциональных и многозначных зависимостей, определяющие необходимое подобие всех объектов S2 в системе объектов R2; P2 = {
| a2Î <зависимости между элементами данных во всех val2>} – отношения (взаимосвязи) между данными типа функциональных и многозначных зависимостей, определяющие необходимое подобие всех объектов S2 в системе объектов R2; P2 = {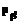 | β2Î<ограничения на сложные данные>} – ограничения, определяющие допустимое разнообразие объектов S2 в системе объектов R2; T={t} – физическое время; tн,tкÎT – начальный и конечный моменты времени, задающие интервал времени существования объекта S2.
| β2Î<ограничения на сложные данные>} – ограничения, определяющие допустимое разнообразие объектов S2 в системе объектов R2; T={t} – физическое время; tн,tкÎT – начальный и конечный моменты времени, задающие интервал времени существования объекта S2.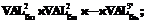 val3ÎVAL3; S3' – это объект уже существующей R3', который включается в val3 в качестве компонента; F3={
val3ÎVAL3; S3' – это объект уже существующей R3', который включается в val3 в качестве компонента; F3={ | a3Î<взаимосвязи компонентов val2 и val3' во всех val3>} – отношения, определяющие совместную обработку (возможные конфигурации) объектов S2 и S3' и задающие необходимое подобие всех объектов S3 в системе объектов R3; P3={
| a3Î<взаимосвязи компонентов val2 и val3' во всех val3>} – отношения, определяющие совместную обработку (возможные конфигурации) объектов S2 и S3' и задающие необходимое подобие всех объектов S3 в системе объектов R3; P3={ | β3Î<ограничения на совместную обработку объектов>} – ограничения на отсутствие и форму объектов S2 и S3', определяющие допустимое разнообразие объектов S3 в системе объектов R3; T={t} – физическое время; tн,tкÎT – начальный и конечный моменты времени, задающие интервал времени существования объекта S3.
| β3Î<ограничения на совместную обработку объектов>} – ограничения на отсутствие и форму объектов S2 и S3', определяющие допустимое разнообразие объектов S3 в системе объектов R3; T={t} – физическое время; tн,tкÎT – начальный и конечный моменты времени, задающие интервал времени существования объекта S3. val4ÎVAL4; F4={
val4ÎVAL4; F4={ | a4Î<взаимосвязи компонентов val2 и val3 в val4>} – отношения, определяющие автономную совокупность объектов S2 и S3 и формирующие целостный объект S4, являющийся единственным представителем системы объектов R4; P4={
| a4Î<взаимосвязи компонентов val2 и val3 в val4>} – отношения, определяющие автономную совокупность объектов S2 и S3 и формирующие целостный объект S4, являющийся единственным представителем системы объектов R4; P4={ | β4Î<ограничения на автономность объекта>} – ограничения на необходимость, объем и интенсивность обработки объектов S2 и S3, определяющие существование объекта S4, представляющего систему объектов R4; T={t} – физическое время; tн,tкÎT – начальный и конечный моменты времени, задающие интервал времени существования объекта S4.
| β4Î<ограничения на автономность объекта>} – ограничения на необходимость, объем и интенсивность обработки объектов S2 и S3, определяющие существование объекта S4, представляющего систему объектов R4; T={t} – физическое время; tн,tкÎT – начальный и конечный моменты времени, задающие интервал времени существования объекта S4.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=340 |
Версия для печати Выпуск в формате PDF (2.31Мб) |
| Статья опубликована в выпуске журнала № 3 за 2007 год. | Версия для печати с комментариями |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Информационная система управления деятельностью персонала
- О выборе числа процессоров в многопроцессорной вычислительной системе
- Инструментальные средства управления эффективностью использования инвестиционных ресурсов в процессе реализации проекта
- Построение маршрута с максимальной пропускной способностью методом последовательного улучшения оценок
- Правовая охрана программного обеспечения с точки зрения международного сотрудничества стран-членов СЭВ
Назад, к списку статей
Comments
автор: Роман [2010-01-02 17:26:45]Автор статьи В.В. Дрождин предложил принципиально новое решение проблем создания больших АИС, а именно: применение эволюционного принципа, предполагающего длительное существование и постепенное развитие системы в процессе функционирования. Автор указывает, что единственным методом, обеспечивающим такое поведение АИС, является адаптация. В.В. Дрождин, разработав формальную теоретико-системную модель данных, предназначенную для создания эволюционных БД (ЭБД) с сохранением информации, по сути, предложил новую модель данных - Эволюционную модель данных, открыв новую страницу в истории теоретической информатики.
Оценка пользователя: 10 баллов