Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Применение современных средств параллельных вычислений для анализа балансовой надежности электроэнергетических систем при планировании их развития
Аннотация:При составлении перспективных балансов мощности и электроэнергии для территориальных зон (объединенные электроэнергетические системы (ЭЭС) – ОЭС, региональные ЭЭС – РЭС и т.п.) единой энергетической системы (ЕЭС) России неотъемлемой частью является задача оценки показателей их надежности. Она требует большого объема вероятностной информации о работе генерирующего и сетевого оборудования (нормы аварийности, ремонтов и т.п.) и, следовательно, большого количества вычислений, весьма продолжительных по времени, а для задач обоснования средств обеспечения надежности порой достигающих нескольких суток. Это обстоятельство приводит к необходимости рассмотрения возможности применения средств параллельных вычислений для эффективного решения данных задач. Существует большое разнообразие аппаратных средств, позволяющих распараллелить вычислительные процессы. Для решения вычислительных задач большой размерности, как правило, применяют различные по своей конфигурации кластерные системы, однако для рассматриваемой задачи более целесообразно использование широкодоступных устройств, входящих в состав настольных систем, а именно ПЭВМ, таких как многоядерные центральные процессорные устройства, а также графические процессорные устройства. Основой для рассмотренных экспериментов послужил хорошо зарекомендовавший себя за несколько лет эксплуатации программно-вычислительный комплекс «ОРИОН-М», разработанный в отделе энергетики Коми НЦ УрО РАН.
Abstract:One of the main issues for the future planning of the power for different regions (regional or interconnected power systems) of the United power system of Russia is the adequacy analysis. It requires large amounts of probabilistic in-formation about the work of lasing and и network equipment (damage rate, repair rate and so on) and a lot of longtime calcu-lations. Some calculations for reliability engineering reasons could take up to several hours or even days. One of the ways to speed up the whole analysis process is the usage of modern hardware based on parallel data processing. Nowadays there is large variety of such devices suitable for different platforms and applicable to solve different calculation tasks. It is necessary to decide which of them is possible to use with high level of the performance for the adequacy analysis and how to adapt se-quential algorithms on the parallel architecture. This paper describes different strategies for the adequacy analysis parallelization on such modern device as multithreaded central processing units. Several aspects of graphics processing units usage is also considered. The base of described experiments is programming and computing suite «ORION-M» developed by the Komi SC UrD RAS department of energy. It proved itself as a good device for several years of using.
| Авторы: Чукреев Ю.Я. () - Институт социально-экономических и энергетических проблем Севера, Коми научный центр, УрО РАН, г. Сыктывкар, Россия, доктор технических наук, Полуботко Д.В. (polubotko@energy.komisc.ru) - Институт социально-экономических и энергетических проблем Севера, Коми научный центр, УрО РАН, г. Сыктывкар, Россия, кандидат технических наук, Чукреев М.Ю. (mchukreyev@gmail.com) - Институт социально-экономических и энергетических проблем Севера, Коми научный центр, УрО РАН (научный сотрудник ), г. Сыктывкар, Россия, кандидат технических наук | |
| Ключевые слова: показатели надежности., статистическое моделирование, параллельные вычисления, электроэнергетическая система |
|
| Keywords: reliability indices, statistical modeling, parallel computing, power system |
|
| Количество просмотров: 12330 |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
Тенденция развития аппаратных вычислительных средств путем увеличения количества параллельно работающих вычислительных единиц, по мнению авторов, будет приоритетным направлением в ближайшей и среднесрочной перспективе. Это относится как к крупным вычислительным средствам, производительность которых оценивается десятками и сотнями Тфлопс, так и к компактным средствам, доступным для использования в составе настольных систем – ПЭВМ. Использование первых неразрывно связано с существенными финансовыми затратами как на создание всей необходимой инфраструктуры для запуска и работы вычислительной системы, так и на последующее ее сопровождение. В то же время доступные компактные средства параллельных вычислений предоставляют все более и более широкие вычислительные возможности и не требуют серьезных финансовых и организационных затрат. Задачи оценки показателей режимной и балансовой надежности (БН) электроэнергетических систем (ЭЭС) требуют многократного повторения определенных процедур, связанных с оценкой параметров ее режима при моделировании теми или иными методами различного набора аварийных ситуаций для повторяющихся дискретных интервалов изменения электропотребления. Их решение, как правило, возлагается на разветвленные управленческие структуры, работающие с многочисленным ПО, использующим единую информационную базу, ограниченные в использовании крупных вычислительных ресурсов и ориентированные на доступные персональные компьютеры. Приведенные обстоятельства подтверждают актуальность создания новых вычислительных алгоритмов, пригодных для адаптации к архитектурам компактных вычислительных систем. Задачи оценки показателей БН ЭЭС и средств ее обеспечения – резервов мощности территориальных зон и запасов пропускной способности связей между ними – всегда были востребованы при разработке вариантов перспективного развития электроэнергетических объектов. В соответствии с Федеральным законом «Об электроэнергетике» всю полноту ответственности за надежную генерацию и поставку заданных объемов мощностей и электроэнергии в определенные территориальные зоны ЭЭС несет ОАО «Системный оператор ЕЭС» (г. Москва), что обусловило разработку его специалистами проекта технологических правил работы, в соответствии с которым оценка БН должна проводиться ежегодно на предстоящий планируемый период. Это предполагает решение данной задачи без серьезных временных ограничений на выполнение расчетных процедур. Тем не менее следует заметить, что время решения задачи оценки показателей БН схемы ЭЭС средней размерности может составлять десятки минут, а задачи обоснования средств обеспечения надежности – несколько суток. Все это в совокупности приводило к необходимости введения каких-либо упрощений, так или иначе отражающихся на получении достоверных результатов. Таким образом, актуальность разработки алгоритмов параллельной обработки информации является достаточно острой.
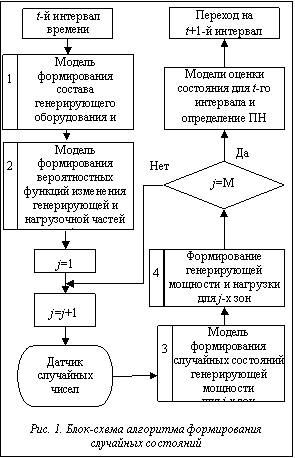
Аналитические методы основаны на последовательном преобразовании рядов вероятностей избытков и дефицитов мощности двух соседних узлов – от одной вершины расчетного графа сети до другой. Данный метод получил название «свертка». Расчет показателей надежности в объединении ЭЭС аналитическими методами позволяет увеличить вычислительную эффективность моделей. Но, с другой стороны, модели, основанные на методах свертки, имеют два существенных недостатка: – не позволяют получать ПН для отдельных территориальных зон, что важно для решения задачи обоснования средств обеспечения надежности; – ограничены применением только для радиально-магистральных схем объединения ЭЭС. Число возможных случайных состояний ЭЭС, вызванных ненадежностью ее элементов, достаточно велико. Эти состояния должны подвергаться определенному анализу на предмет обеспечения потребителей электроэнергией должного объема и требуемого качества. Их полный перебор не представляется возможным, поэтому прибегают к методам статистического моделирования состояний, используя законы распределения, характеризующие состояния элементов и колебания нагрузок, что позволяет значительно сократить число рассматриваемых состояний. Моделирование случайных состояний осуществляется следующим образом (рис. 1). Сначала аналитическими методами строятся функции вероятностей изменения мощностей, вызванных аварийностью генерирующего оборудования и ошибками прогноза нагрузки, для всех j-х зон надежности (блок 2). Для этого производится суммирование всего однородного генерирующего оборудования, входящего в рассматриваемую j-ю зону (блок 1). На аналитически построенных функциях вероятностей снижения мощностей j-х зон надежности методами статистического моделирования определяются детерминированные значения мощностей в них (блок 3). Далее проводится оценка случайного состояния системы, по ее завершении определяются показатели БН. Данная процедура повторяется многократно для некоторого интервала времени. В проектной практике рассматривается некий интервал времени, разбиваемый на еще более мелкие, для каждого из которых определяются ПН.
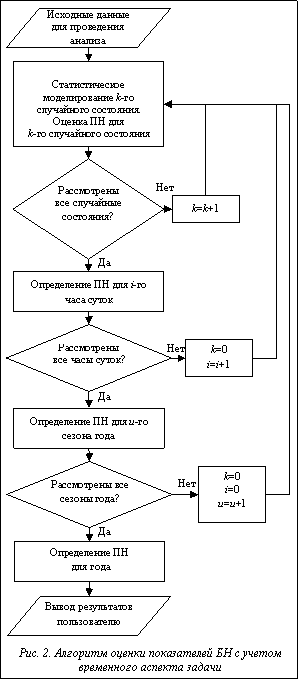
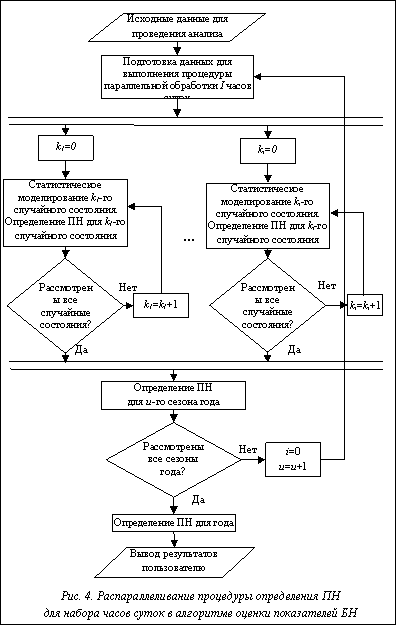
Современные компактные аппаратные средства параллельных вычислений. Развитие современных компактных средств вычислений направлено в сторону увеличения производительности за счет роста числа вычислительных элементов (ядер, потоков и т.п.). Среди наиболее доступных для использования в составе настольных систем, а именно ПЭВМ, следует отметить многоядерные центральные процессорные устройства (ЦПУ), а также графические процессорные устройства (ГПУ). Вопреки названию ГПУ позволяют выполнять вычисления общего назначения, кроме того, обладают собственной оперативной памятью, размер которой во многом сопоставим с размером оперативной памяти, доступной для центрального процессора (ЦП). Немаловажным является и то, что данные устройства представляют собой независимые вычислительные элементы, работа которых может выполняться асинхронно по отношению к другим компонентам персонального компьютера. Кроме того, количество ГПУ, входящих в состав конфигурации компьютера, может быть увеличено по крайней мере до двух, а в некоторых случаях и больше. Рассмотрение вычислительных возможностей упомянутых устройств позволяет говорить о том, что ГПУ развиваются более интенсивно, чем ЦПУ. Так, удвоение производительности ГПУ достигается за 6 месяцев, в то время как для ЦПУ на это требуется порядка 18 месяцев. Абсолютные числа производительности ГПУ на примере NVidia GeForce 580GTX для чисел с одинарной точностью достигают пиковых значений на уровне 1 500 Гфлопс при пропускной способности памяти в 192 ГБ/с и количестве вычислительных потоков, равном 512. Производительность ЦПУ на примере Intel Core i7 3960x составляет 170 Гфлопс при пропускной способности памяти в 51 ГБ/с и числе вычислительных потоков, равном 8. Производительность современных ГПУ и темпы ее роста впечатляют, однако разработка параллельных алгоритмов и их последующая адаптация на данные устройства сталкиваются с рядом сложностей, основной из которых является то, что, несмотря на существенное доступное количество вычислительных потоков, не всегда удается получить соответствующий прирост скорости. Основной помехой в этом являются значительные задержки при обращении к оперативной памяти ГПУ, что обусловлено достаточно простой архитектурой построения мультипроцессоров, входящих в их состав, и небольшими объемами кэш-памяти. Данное обстоятельство особенно заметно при сравнении с суперскалярной архитектурой ЦПУ, имеющей в наличии сложные механизмы повторного использования инструкций и операндов, а также существенно большие по сравнению с мультипроцессорами ГПУ объемы кэш-памяти. Все перечисленные особенности устройств необходимо учитывать при создании новых алгоритмов обработки данных, пригодных для реализации на параллельных архитектурах. Кроме того, немаловажным фактором является выбор того или иного средства реализации, а именно языка/технологии, при помощи которой будет реализован соответствующий алгоритм. Параллельный алгоритм оценки показателей БН. Опишем более детально каждую из возможных стратегий адаптации алгоритма оценки ПН к различным аппаратным архитектурам. В качестве первого варианта рассмотрим распараллеливание алгоритма, представленного на рисунке 2, по случайным состояниям. Общий вид алгоритма в упрощенной форме изображен на рисунке 3. Как видно из блок-схемы, в параллельном алгоритме снизилось число циклов до двух, внутри которых процедура моделирования множества случайных состояний K={K1, K2, …, Kk} выполняется параллельно. Отметим важный фактор, играющий существенную роль при практической реализации подобной схемы распараллеливания вычислительного процесса, а именно то, что размерность множества K может достигать величин порядка 103–105. Чем выше размерность K, тем более точные результаты получаются на выходе работы алгоритма. При малых размерностях анализируемой схемы эта величина может быть значительно снижена, однако при проведении практических расчетов верхняя граница размерности множества K принимается, как правило, на уровне 104. С точки зрения адаптации к тем или иным параллельным архитектурам данное обстоятельство имеет важное значение. Во-первых, на этапе подготовки всех необходимых данных для проведения последующей параллельной процедуры моделирования случайных состояний системы и определения показателей БН для каждого состояния необходимо выделить значительный объем оперативной памяти M, который должен быть проинициализирован исходными данными для выполнения анализа. Объем M в общем случае пропорционально зависит прежде всего от размерности K, а также от размеров моделируемой системы (в меньшей степени) и может достигать нескольких Гб. В случае возможных аппаратных ограничений при выделении такого объема памяти можно разбить K на подмножества с соответствующим сокращением M. Во-вторых, большая размерность K подразумевает возможность организации вычислений с высоким уровнем параллелизма. Данное обстоятельство, как и ограничение по объему M, связано с аппаратными характеристиками конкретной целевой архитектуры. Если то или иное средство компактных параллельных вычислений содержит большое количество вычислительных единиц и оборудовано достаточным объемом оперативной памяти с должным уровнем пропускной способности, то алгоритм, представленный на рисунке 3, наиболее эффективен для реализации на подобном устройстве.
Помимо представленных двух вариантов распараллеливания алгоритма, показанного на рисунке 2, возможен третий вариант, заключающийся в рассмотрении цикла, идущего по множеству U={U1, U2, …, Uu} сезонов года. С точки зрения возможных требований к архитектуре аппаратных средств вычислений этот вариант во многом будет сходным с вариантом алгоритма, представленного на рисунке 4, поскольку |U|=1–12, поэтому останавливаться на нем нет необходимости. Таким образом, на основе рассмотренных подходов распараллеливания алгоритма оценки показателей БН можно отметить следующее: первый вариант распараллеливания наиболее подходит для компактных устройств класса ГПУ, так как данные устройства в настоящий момент обладают значительным количеством параллельно выполняемых потоков, большими объемами оперативной памяти и прочими особенностями, способствующими проведению массивно-параллельных вычислений; второй вариант (как, впрочем, и третий) более подходит для многоядерных ЦПУ, обладающих большими объемами кэш-памяти и невысоким на данный момент уровнем параллелизма вычислений. Практическая реализация. Для примера рассмотрим адаптацию алгоритма, представленного на рисунке 4, для реализации на многоядерном ЦПУ. В качестве критерия эффективности адаптации алгоритма используем коэффициент ускорения расчетов, который, согласно закону Амдала, вычисляется следующим образом:
где С практической точки зрения процесс адаптации того или иного алгоритма к целевой архитектуре заключается в построении программы с использованием функций, входящих в состав различных вспомогательных библиотек. Применительно к многоядерным ЦПУ в настоящее время наиболее эффективно с точки зрения затраченного времени на выполнение процедуры адаптации использование библиотеки OpenMP [4], входящей в поставку ряда компиляторов, а также более универсального средства – библиотеки OpenCL [5]. Перечисленные средства являются универсальными для использования различных марок ЦП, не зависят от их производителя и спецификаций. Более того, OpenCL – новый стандарт для разра- ботки приложений гетерогенных систем. Он используется для написания приложений, которые должны исполняться в системе, где установлены различные по архитектуре ЦПУ, ГПУ и платы расширения. Вследствие этого отпадает необходимость в использовании различных алгоритмов для систем, основанных на платформах Intel, AMD и др. Для проверки эффективности при практической реализации алгоритма, представленного на рисунке 4, проведен ряд тестовых расчетов на тестовых схемах ЭЭС различной размерности и конфигурации. В качестве программного средства параллельных вычислений использовались библиотеки OpenCL и OpenMP. Полученные результаты для данных программных средств во многом идентичны. Оценочные расчеты проводились для двух вариантов: при |K|=103 и |K|=104; следует отметить, что |U|=1, хотя на практике рассматривается большее число сезонов, что требует пропорционально больших затрат времени. В таблице 1 приведены сравнительные результаты для различных типов ЦП, схем ЭЭС, их конфигураций. Результаты позволяют сравнить скорость выполнения расчетов как при использовании всех ядер (потоков) ЦПУ, так и при последовательной обработке информации. Таблица 1 Показатели БН для ЦП (время, сек.)
В таблице 2 приведены характеристики использованных ЦПУ. Расчеты проводились путем 5-кратного выполнения расчетной процедуры при неизменных параметрах для каждой схемы. В качестве конечного результата бралось среднее значение по проведенным экспериментам. Разница между результатами однотипных расчетов обусловлена различным уровнем загрузки ЦП в разные моменты времени. Таблица 2 Характеристики использованных ЦП
Полученные сравнительные результаты времени проведения расчетов позволяют вычислить коэффициент h для рассмотренных ЦП при оценке показателей БН для различных схем ЭЭС и их конфигураций (при |K|=103, |K|=104 соответственно h1000/h10000). Результаты вычислений сведены в таблицу 3. Таблица 3 Коэффициент ускорения расчетов (h1000/h10000) для различных ЦП, тестовых схем ЭЭС и их конфигураций
На основании приведенных практических результатов можно сделать вывод о том, что распараллеливание традиционного алгоритма оценки показателей надежности согласно первой стратегии (с использованием многоядерных ЦПУ) достаточно эффективно и с успехом может применяться при решении практических задач оценки надежности сложных объединенных энергетических систем. Дальнейшие исследования в рамках данной задачи необходимы для анализа возможного использования и эффективности реализации алгоритма оценки показателей БН на иных аппаратных архитектурах параллельных вычислений с рассмотрением других предложенных в работе стратегий распараллеливания. Развитие программно-вычислительных средств в этом направлении позволит существенно ускорить процесс получения результата, с одной стороны, и уйти от ряда оптимизационных упрощений – с другой. Последующая работа по улучшению производительности за счет использования возможностей современных вычислительных средств даст возможность существенно уменьшить временной интервал принятия решений. Авторы статьи выражают благодарность директору Института точных наук и информационных технологий Сыктывкарского государственного университета В.В. Миронову за предоставленное для проведения вычислительного эксперимента оборудование. Литература 1. Волков Г.А. Оптимизация надежности электроэнергетических систем. М.: Наука, 1986. 117 с. 2. Руденко Ю.Н., Ушаков И.А. Надежность систем энергетики. М.: Наука, 1986. 252 с. 3. Чукреев Ю.Я. Модели обеспечения надежности электроэнергетических систем. Сыктывкар: Коми НЦ УрО РАН, 1995. 176 с. 4. OpenMP Quick Reference Sheet. URL: http://www.plutospin.com/files/OpenMP_reference.pdf (дата обращения: 21.09.2012) 5. NVIDIA OpenCL Best Practices Guide, Version 2.3, USA, NVIDIA Corpor., 2009. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

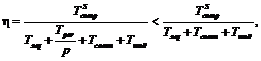
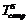 =Tseq+Tpar – общее время расчетной процедуры; Tseq, Tpar – время выполнения последовательного и параллельного участков в алгоритме соответственно; Tcomm – время на передачу данных; Twait – время ожидания при синхронизации; p – число процессоров. Применительно к рассматриваемой задаче Tpar должно в процентном от- ношении превышать Tseq, а Tcomm и Twait при при- менении многоядерных ЦПУ должно быть незначительным. Для современных многоядерных ЦП величина p=2–12, а в ближайшее время вырастет еще больше. В связи с этим предварительно можно оценить h в 1,7–7,5 (при p=2–8).
=Tseq+Tpar – общее время расчетной процедуры; Tseq, Tpar – время выполнения последовательного и параллельного участков в алгоритме соответственно; Tcomm – время на передачу данных; Twait – время ожидания при синхронизации; p – число процессоров. Применительно к рассматриваемой задаче Tpar должно в процентном от- ношении превышать Tseq, а Tcomm и Twait при при- менении многоядерных ЦПУ должно быть незначительным. Для современных многоядерных ЦП величина p=2–12, а в ближайшее время вырастет еще больше. В связи с этим предварительно можно оценить h в 1,7–7,5 (при p=2–8).| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3499 |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
| Статья опубликована в выпуске журнала № 2 за 2013 год. [ на стр. 225-231 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Параллельные вычисления при моделировании процесса растворения на микроуровне
- Использование графических процессоров в задачах оперативного управления режимами электроэнергетических систем
- Программный комплекс для решения задач теории потенциала методом граничных элементов
- Параллельная генерация пространства состояний дискретных детерминированных моделей
- Разработка графической оболочки для параллельных расчетов на базе платформы OpenFOAM
Назад, к списку статей