Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Искусственные миры: распределение данных
Аннотация:Рассматриваются вопросы организации распределенных неограниченно растущих БД, обслуживаемых коллективом программных агентов. Растущая сложность вычислительных сетей и приложений на их основе ставит вопрос о переходе к автономным системам, способным к самоадминистрированию, самооптимизации и саморазвитию. Подобные автономные системы можно рассматривать как искусственный мир, состоящий из искусственных организмов, реализованных как программные агенты, которые находятся между собой в различных отношениях и постепенно совершенствуются в процессе конкуренции и приспособления к среде. Каждый из организмов принадлежит к одному из видов, имеющих особое функциональное назначение. В целом сообщество искусственных организмов устроено по иерархическому принципу, при котором одни виды занимают подчиненное положение по отношению к другим. Нижние уровни иерархии отводятся искусственным организмам, организующим данные и обрабатывающим информационные запросы. Верхние уровни иерархии занимают цифровые организмы, решающие задачи управления сообществом. Принцип иерархической организации характерен для многих других известных архитектур, например для архитектуры Internet и Grid-систем. В соответствии с общей концепцией автономной мультиагентной системы, действующей на базе вычислительной сети, предполагается, что БД, используемые в такой системе, являются пространственно распределенными и не-ограниченно растущими в объеме. При этом предлагаетсясочетать покортежное пространственное распределение отношений с доменно-ориентированным принципом внутреннего представления отношений. Предложен алгоритм пополнения данными распределенной неограниченно растущей БД, построенной на указанных принципах. Выделен новый тип информационных запросов – так называемые расширенные запросы, которые могут быть реализованы по отношению к распределенным БД на основе доменно-ориентированной модели.
Abstract:The article considers conceptual organization of the unlimitedly growing distributed databases serviced by col-lective of software agents. Growing complexity of computer networks and their applications brings attention to creating the autonomic systems ca-pable to self-management, self-optimisation and self-development. Such autonomic systems can be considered as the artifi-cial worlds inhabited by artificial organisms constructedas software agents. The agents are in different relationswith each other and are gradually improving due to the competition and adaptation in computing environment. Each artificial organism belongs to one of the species possessing a special functional purpose. The community of artificial organisms is arranged by hierarchical principle, species occupy the subordinated position to another. The bottom levels of hierarchy are occupied by artificial organisms which are engaged in a data structures organization and processing of queries. The upper levels are pre-sented by the digital organisms managing the community. The principle of the hierarchical organization is intrinsic for other widely-known architectures, for example for Internet-architecture and Grid-systems. According to the general concept of autonomic multiagent system operating in computer network, it is supposed that used databases are spatially distributed and limitlessly growing in volume. It is offered to combine tuple-oriented spatial distribu-tion of database relations with domain-oriented principleof the internal representation of relations. The authors of the article offer an algorithm of data replenishment for based on above-stated principles limitlessly growing in volume databases. A new type of queries, the so-called expanded queries which can be realised to the distributed databases on the basis of the domain-oriented model is offered.
| Авторы: Кольчугина Е.А. (kea@pnzgu.ru) - Пензенский государственный университет (профессор кафедры математического обеспечения и применения ЭВМ), г. Пенза, Россия, доктор технических наук | |
| Ключевые слова: растущие бд., автономные мультиагентные системы, искусственная жизнь |
|
| Keywords: growing databases, autonomic multiagent software systems, artificial life |
|
| Количество просмотров: 8117 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
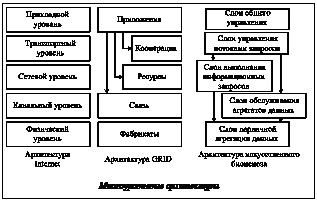
Проникновение в различные сферы жизни человека вычислительной техники и информационных технологий, в частности в виде компьютерных сетей, происходит все более быстрыми темпами. При этом сложность технических устройств, ПО и моделей вычислений неуклонно растет. Это, в свою очередь, делает задачу администрирования вычислительных сетей все более сложной, причем эффективность труда администраторов падает, а стоимость труда возрастает. Выходом из создавшейся ситуации является переход к частично, а затем и полностью автономным системам, которые способны сами поддерживать свою работоспособность [1]. Подобные идеи концептуально близки к моделям облачных вычислений, которые уже находят практическое применение, а также к моделям вездесущих и всепроникающих вычислений [2] и Интернета вещей (Internet of things). В статье предлагается модель построения распределенных растущих БД, которые могут стать основой для функционирования автономных программных систем, например, в виде самоорганизующегося коллектива конкурирующих программных агентов. Структура искусственного мира Автор предлагает рассматривать совокупность программного и аппаратного обеспечения ав- тономной самоорганизующейся системы как искусственный мир, в котором развиваются и совершенствуются программные агенты, реализованные в виде цифровых организмов. Как и их биологические прототипы, цифровые организмы принадлежат к определенным видам, образующим многоуровневую иерархию, подобную иерархии видов в живой природе. Отношения между видами могут быть различными, но, как правило, их можно охарактеризовать как «хищник–жертва» или «производитель–потребитель». Виды цифровых организмов с одинаковым назначением относятся к одному и тому же уровню, или слою иерархии. Каждый вид может относиться только к одному слою иерархии, но каждый слой может содержать бесконечное количество агентов бесконечно большого количества видов. Виды, относящиеся к нижним уровням иерархии, занимаются непосредственно обработкой данных, в то время как верхние уровни иерархии представлены видами, которые управляют нижними уровнями. Управление осуществляется благодаря тому, что цифровые организмы, принадлежащие к видам с более высоких уровней иерархии, подавляют или стимулируют активность цифровых организмов с более низких уровней иерархии. Иногда виды с вышележащих уровней иерархии играют роль хищников по отношению к видам с нижележащих уровней, непосредственно ограничивая численность цифровых организмов, принадлежащих к управляемым видам. Таким образом, предлагаемую совокупность программных агентов, или цифровых организмов, можно рассматривать как искусственный биоценоз. Если проводить аналогию с биоценозами живой природы, то БД и СУБД представляют собой аналог растений, или продуцентов. Результатом работы СУБД будут организованные структурированные совокупности данных, которые являются объектами информационных запросов, или исходными данными, для программных агентов, то есть цифровых организмов. Выполняя запросы, агент получает плату и увеличивает количество накопленных им баллов. Баллы являются ана- логом внутренней энергии, наличие которой обеспечивает существование агента. Трата энергии агентом происходит постоянно. При отсутствии внутренней энергии агент гибнет. Это может произойти, если агент долгое время не был востребован или оказался неконкурентоспособным. Благодаря постоянной борьбе за существование, смене поколений и выживанию наиболее приспособленных коллектив агентов эволюционирует. Иерархический способ построения присущ многим концепциям распределенных систем, в частности, архитектура вычислительных сетей является многоуровневой. Многоуровневый иерархический способ организации также положен в основу метакомпьютерных Grid-систем [3]. Примеры многоуровневых архитектур приведены на рисунке. Поскольку речь идет об автономной самоорганизующейся системе, желательно, чтобы самоорганизация присутствовала на всех уровнях иерархии искусственного биоценоза, в том числе и на уровне управления данными, в частности, чтобы задачи, связанные с ростом БД и пространственным распределением данных, решались автономно. Растущие БД Спецификой растущей БД является то, что данные из такой базы не удаляются либо удаляются крайне редко. Такими свойствами, например, отличаются темпоральные (временнЫе) БД, представляющие динамику развития предметной области во времени [4]. Модель построения распределенной СУБД на базе многопроцессорной вычислительной системы с обменом сообщениями была рассмотрена в [4]. В этой модели каждый процессорный элемент имеет собственную внешнюю память, в которой хранятся фрагменты отношений темпоральной БД. Отношения распределены по процессорным элементам покортежно по временному признаку: каждый процессорный элемент хранит кортежи всех отношений БД, относящиеся к некоторому временному интервалу [tb, te]. Один из процессорных элементов ведет архивную БД, содержащую уже неактуальные кортежи отношений. Рассмотрим модель самоорганизующихся растущих распределенных БД в многомерном пространстве вычислительных узлов. В частности, такое пространство может быть регулярным декартовым клеточным пространством.
Доменная модель позволяет легко производить как распределение отношений по вычислительным узлам благодаря разбиению на подмножества, так и сборку отношений. В то же время каждый вычислительный узел может хранить не весь домен и не все отношения БД целиком, а только их отдельные части. Таким образом, могут сочетаться доменный подход и покортежное распределение отношений. При этом пользователю, как и в случае облачных технологий, безразлично, где физически будут располагаться необходимые ему данные: их легко найти благодаря запросу, выполняемому коллективом мобильных программных агентов, посещающих все вычислительные узлы и ориентированных при выполнении поиска на номера доменов и внутридоменные номера значений. В случае растущих распределенных БД СУБД может быть реализована как приложение, сочетающее в себе свойства клиента и сервера, способное обмениваться данными и управляющей информацией с аналогичными СУБД, расположенными на других вычислительных узлах. Опишем алгоритм пополнения данными базы. Пусть вычислительный узел, на котором располагаются часть БД и соответствующая СУБД, связан с соседними узлами с помощью n+1 логических каналов {ch1, …, chn, chn+1}. СУБД, находящаяся в любом из вычислительных узлов, может функционировать в одном из трех режимов: холостого хода и ожидания инициации, пассивной обработки запросов, а также управления СУБД в смежных узлах. При поступлении новых данных СУБД выполняет следующие действия. 1. Если СУБД находится в режиме холостого хода, перейти в режим пассивной обработки запросов, выполнить шаг 2. 2. Пока не исчерпан допустимый для данного узла объем хранения, принимать данные и размещать их на локальном запоминающем устройстве. В противном случае установить i=1, перейти в режим управления СУБД в смежных узлах, выполнить шаг 3. 3. Если i=n+1, перейти к шагу 4. Иначе передать поступившие данные в направлении chi, чтобы на смежном узле была инициирована СУБД, которая начнет постепенное заполнение своей локальной памяти поступившими фрагментами БД. Присвоить i=i+1, повторять, пока i≤n. 4. Передать данные в случайно выбранном направлении в любой из логических каналов {ch1, …, chn}. СУБД вычислительного узла может снова перейти в режим холостого хода, если БД, хранящиеся на данном вычислительном узле, будут удалены. Канал chn+1 не используется для дальнейшего роста БД и рассматривается как материнский, связывающий данный экземпляр СУБД с управляющим по отношению к нему экземпляром из смежного вычислительного узла. Значение номера материнского канала определяется для СУБД на текущем узле при инициации и переходе в режим пассивной обработки запросов. В рассматриваемой модели организации БД СУБД также можно реализовать как программный агент, способный клонироваться и обладающий мобильностью, что позволит осуществлять перемещение между вычислительными узлами как самой СУБД, так и доменов и БД, находящихся под управлением данной копии СУБД. Расширенные запросы Предложенный подход к организации распределенных БД имеет еще одно преимущество: в системе могут быть реализованы не только обычные, но и расширенные запросы. В случае расширенного запроса пользователь может не указывать имя таблицы БД, в которой производится поиск, предполагая, что поиск возможен по всем таблицам. В результате должны быть выбраны все кортежи из всех таблиц, содержащие заданные номера значений из заданных доменов на уровне внутреннего представления. Таким образом, расширенный запрос строится исходя из ориентации на домен и значение в нем. Расширенный запрос с ориентацией на домен может, например, выглядеть так [6]: select * from* where ФИО=²Иванов И.И.². Здесь символ * в предложении from означает, что требуется провести поиск во всех имеющихся таблицах, в которых используется домен ФИО, безотносительно к имени связанного с доменом атрибута, и выбрать все записи из таблиц, содержащие значение ²Иванов И.И.² из домена ФИО. В данном случае имя домена и значение представлены в более удобной для пользователя символьной форме, однако при выполнении запроса СУБД и коллективом программных агентов должны использоваться внутрисистемные номера как доменов, так и значений в доменах. В заключение необходимо отметить, что предлагаемый в статье подход к организации распределенных БД позволит перейти к новому типу систем, реализующих концепцию SaaS (Software as a Service – программное обеспечение как услуга). Эти системы не только будут распределенными и обладающими прозрачной для пользователя структурой, но и смогут адаптироваться к конкретному пользователю и его задачам благодаря самоорганизации. Применение доменно-ориентированного подхода позволит приблизить поиск в распределенных БД к релевантному поиску в Интернете. Литература 1. IBM Autonomic Computing. URL: http://www-01.ibm. com/software/tivoli/autonomic/ (дата обращения: 30.05.2012). 2. Гофф М.К. Сетевые распределенные вычисления: достижения и проблемы; [пер. с англ.]. М.: КУДИЦ-ОБРАЗ, 2005. 320 с. 3. Foster I., Kesselman K., Tuecke S., The Anatomy of the Grid: Enabling Scalable Virtual Organizations, Lecture Notes in Comp. Sc., 2001, Vol. 2150, pp. 1–25. 4. Кольчугина Е.А. Системы управления временными базами данных для решения задач обработки информации в автоматизированных системах управления распределенными объектами: дис... канд. техн. наук. Пенза, 1998. 156 с. 5. Линьков В.М. Нумерационные методы в проектировании систем управления данными. Пенза: Изд-во Пенз. гос. техн. ун-та, 1994. 156 с. 6. Кольчугина Е.А. Организация баз данных и распределенный информационный поиск // Современные информационные технологии: тр. междунар. науч.-технич. конф. Пенза: Пенз. гос. технологич. акад., 2005. Вып. 2. С. 95–97. References 1. IBM Autonomic Computing, available at: http://www-01.ibm.com/software/tivoli/autonomic/ (accessed 30 May 2012). 2. Goff M.K., Network Distributed Computing: Fitscapes and Fallacies, Prentice Hall, 2004. 3. Foster I., Kesselman K., Tuecke S., Lecture Notes in Computer Science, Vol. 2150, 2001, pp. 1–25. 4. Kolchugina E.A., Sistemy upravleniya vremennymi bazami dannykh dlya resheniya zadach obrabotki informatsii v avtomatizirovannykh sistemakh upravleniya raspredelennymi objektami: dissertatsiya na soisk. uch. stepeni k.t.n. [Temporary databases control systems for solving data processing tasks in distributed objects automated control systems: Ph.D. thesis], Penza, PenzSTU Publ., 1998. 5. Linkov V.M., Numeratsionnye metody v proektirovanii sistem upravleniya dannymi [Numeric methods in data control systems design], Penza, PenzSTU Publ., 1994. 7. Kolchugina E.A., Sovremennye informatsionnye technologii: Trudy mezhdunar. nauchno-tekhnicheskoy konf. [Modern IT: proc. of int. computer-based conf.], Penza, PenzSTU Publ., 2005, iss. 2, pp. 95–97. |
 Прежде всего для растущих распределенных БД предлагается использовать доменную модель [5]. Любое отношение в этой модели может быть построено в результате сборки на основе множества областей пронумерованных значений (доменов) и таблицы внутреннего представления, каждая строка которой содержит описание кортежа отношения в виде последовательности номеров значений атрибутов. В свою очередь, каждый атрибут связан с доменом значений. Совокупность номера домена и номера внутри домена позволяет однозначно определить кодируемое значение атрибута кортежа.
Прежде всего для растущих распределенных БД предлагается использовать доменную модель [5]. Любое отношение в этой модели может быть построено в результате сборки на основе множества областей пронумерованных значений (доменов) и таблицы внутреннего представления, каждая строка которой содержит описание кортежа отношения в виде последовательности номеров значений атрибутов. В свою очередь, каждый атрибут связан с доменом значений. Совокупность номера домена и номера внутри домена позволяет однозначно определить кодируемое значение атрибута кортежа.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3585 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
| Статья опубликована в выпуске журнала № 3 за 2013 год. [ на стр. 185-189 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: