Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Способ построения защищенных от исследования систем информационной безопасности
Аннотация:В статье обозначена проблема исследования в конфликтных системах. Рассмотрены методы противодействия процессу исследования контрагента, а также противодействия противодействию процесса исследования. Определена модель исследователя в конфликте, включающая информационные ограничения при попытке исследовать объект конфликта. Представлены четыре класса, в которых может находиться исследователь с учетом его информационных ограничений. Приведен алгоритм проектирования защищенных от исследования информационных систем. Проблема исследования контрагента в конфликтной системе заключается в возможности использовать этот процесс с целью дезинформации. Это можно сделать, если знать принципы интерпретации исследователем получаемой информации и получить таким образом возможность рефлексивно управлять противником. Аналогично можно получить схему рефлексивного управления процессом рефлексивного управления. Реально управляющий в данный момент субъект находится в состоянии информационного превосходства. Для достижения состояния информационного превосходства субъект должен получить контроль над объектом конфликта, достаточный для корректировки классов модели исследователя контрагента. Корректируя классы модели исследователя, можно добиться состояния, когда дляконтр-агента станет невозможным сформулировать задачу исследования. Если субъект может получить такой контроль, то, используя алгоритм, предложенный в статье, он достигнет состояния информационного превосходства. Предполагается, что наиболее эффективно данный алгоритм можно применить на стадии разработки программных продуктов в области информационной безопасности. С использованием предложенных алгоритмов уже были разработаны системы анализа несанкционированных действий пользователей на интернет-ресурсах и в локальной сети предприятия (программы ReflexionWeb и ExLook).
Abstract:Conflict systems form the research area of our study describingthe methods of protecting counterparty against research, as well as the methods of counteracting the protection against research. The study determines the researcher model in conflict. This model imposes information restrictions when trying to research the object of the conflict. The studyde-scribes four classes of the researcher depending on his information restrictions. The algorithm for designing systems protect-ed against research is also described. The counterparty research problem in a conflict system is that there is an opportunity of using this process to disinform. This is possible, if you knowresearcher's principles of interpretative work on information re-ceived, what gives you the possibility to reflexively control the opponent. Similarly, you can get the scheme to reflexively control the reflexive control process. At the moment the subject that really controls the process has information supremacy. To obtain this information supremacy, the subject has to get conflict's object under control that is sufficient to correct coun-terparty researcher model classes. By correcting classes of the researcher model, you can achieve the point when it becomes impossible for the counterparty to define the research objective. If the subject can get the process under control of this kind, than using the described algorithm it obtains information supremacy. We assume this algorithm can be effectively applied to information security software development. Using the considered algorithm, the analysis system of unauthorized user activity on enterprise websites and enterprise networks (ReflexionWeb and ExLook software) have already been developed.
| Авторы: Стюгин М.А. (styugin@rambler.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева, г. Красноярск, Россия | |
| Ключевые слова: методы проек-тирования защищенных систем., информационная безопасность, модель конфликта, защита от исследования |
|
| Keywords: methods of designing protected systems, infosecurity, conflict model, protection against |
|
| Количество просмотров: 8264 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
В системах безопасности существенную роль играет возможность потенциального злоумышленника построить объективный образ атакуемой системы, а противоположной стороне конфликта, соответственно, построить объективный образ злоумышленника. Определить, кто в данный момент обладает информацией об объекте конфликта, достаточной для совершения адекватных действий, не всегда возможно. И проблема состоит в том, как строить системы безопасности с учетом затруднения их исследования для злоумышленника. Для построения модели представим, что два субъекта, A и B, находятся в конфликте. При этом субъект A пытается получить некую информацию о субъекте B. Активность в процессе исследования будем обозначать стрелкой, как показано на рисунке 1. При этом субъект B, зная, что его исследует субъект A, может предоставить ему заведомо ложную информацию, то есть активно повлиять на процесс исследования A (рис. 2). В результате субъект A получит недостоверные сведения о контрагенте. Однако данную схему можно расширить. Предположим, субъект A понял, что контрагент пытается управлять процессом его исследования, и смог снова восстановить исследование уже с учетом схем активной дезинформации B (рис. 3). В данном случае A активно влияет на процесс управления B исследованием (он использует информацию этого управления). B думает, что дезинформирует A, но на самом деле это не происходит. Субъект A в такой схеме находится в ситуации информационного превосходства. Эту цепочку можно продолжать бесконечно в соответствии с правилами рефлексивного анализа [1]. Однако данный анализ можно проводить только внешне. Сами участники конфликта не могут знать, кто из них сейчас находится в ситуации информационного превосходства и реально управляет конфликтом. Инструменты управления исследованием Необ Получаем исследование, характеризующееся кортежем áP, Sñ. Если рассматривать возможность управления этим процессом, то со стороны того, кого пытаются идентифицировать, можно ввести метод запутывания, который на основе схемы интерпретации S не даст получить объективную информацию. Для этого второму субъекту надо знать схему интерпретации агентом A полученной информации (S) и используемые им параметры. Владея этой информацией, он сможет сгенерировать данные (собственноручно или с помощью эмулятора клиента), по которым субъект A построит неверный образ, то есть он должен усложнить систему, введя еще свою схему интерпретации событий – S': áP, S, S'ñ.
Образ системы (множество элементов), получаемый при применении алгоритмов S к значениям параметров P, обозначим как T(P, S). Каждый образ, связанный с более высоким рангом рефлексии, всегда включает в себя более простую модель предыдущего ранга, то есть T(P, S)ÌT(P, S¢)ÌT(P, S²). Образ предыдущего ранга также можно получить с применением некого фильтра неразличимости, в котором находится субъект на данном ранге: T(P, S¢¢)\F¢=T(P, S¢), T(P, S¢¢)\F=T(P, S), … Модель защиты от исследования Для достижения информационного превосходства субъекту A необходимо защитить от B свои схемы интерпретации S, S'', S'''', … (которые он генерирует сам) и получить объективные схемы S', S''', S''''', … (которые генерирует контрагент). Чтобы разобраться, как это сделать, необходимо расшифровать понятие схемы интерпретации и фильтров. В данном случае субъект A имеет некое понятие о системе, представленной множеством S. Это множество можно рассматривать как параметры в функции прогнозирования изменения среды (если ничего нельзя прогнозировать, тогда зачем эти параметры?) – F(S). В реальности система меняет состояние не по функции F(S), а по функции F(Sr). И субъект A наблюдает либо опровержение гипотезы, либо ее подтверждение. Исходя из данной модели субъект A имеет следующие ограничения. 1. Не все параметры модели S являются наблюдаемыми для субъекта A. То есть можно выделить некое множество наблюдаемых параметров 2. Не все функции изменений системы являются наблюдаемыми, то есть аналогично можно ввести множество видимых значений функций 3. Существенным ограничением для исследователя является также невозможность формулировать гипотезы иным путем, кроме формального перебора. Данная модель исследователя может принадлежать к одному из четырех классов. Класс 1. S=Sr, Класс 2. S¹Sr, Класс 3. S¹Sr, Класс 4. S¹Sr, Процесс исследования мира всегда последовательно движется по классам от четвертого к первому. Если иметь возможность регулировать этот класс в конфликтных системах, можно усложнять контрагентам процесс получения объективной информации. Если иметь возможность перевести систему к четвертому классу, субъект просто не сможет обнаружить, что его модель мира неверна, и воспримет ее как истинную, а это является единственной гарантией достижения информационного превосходства в конфликте. Таким образом, субъект B, имея возможность управлять и модифицировать множество Sr так, чтобы перевести модель исследователя контрагента A к четвертому классу, может добиться условия информационного превосходства. Допустим, для такой модификации можно расширить исходное множество Sr, введя в систему дополнительные параметры S'. Таким образом, получим новую функцию системы:
В данном случае новые параметры выходят за область функциональной видимости субъекта A, то есть Теперь относительно субъекта A можно определить отношение эквивалентности на множестве параметрических значений:
В результате получаем отношение эквивалентности (неразличимости) на функции F':
Таким образом, субъект A в процессе исследования строит более простую модель системы и убеждается в ее истинности за счет неразличимости по множеству S'. Данный факт уклоняет его от дальнейшего исследования мира, что позволяет субъекту B достичь ситуации информационного превосходства.
Чтобы описанные выше схемы стали более понятными, приведем пример построения таких систем. Для этого возьмем упомянутые выше ме- ханизмы идентификации злоумышленников по клавиатурному почерку в таких системах, как ReflexionWeb и ExLook. Идентификация злоумышленника по клавиатурному почерку происходит по следующему алгоритму. 1. Получение эталонной сигнатуры по множеству параметров P – Sig(P). Здесь используются такие параметры, как последовательности нажатия клавиш и временная задержка между нажатием клавиш и задержка нажатия одной клавиши. Из-за объема эти данные нет смысла хранить в системе, поэтому используются некие обобщенные значения – их сигнатуры. 2. Получение новой сигнатуры Sig(P') и сравнение ее с эталонной по некоторому алгоритму Alg(Sig(P'), Sig(P)). То есть на каждого нового человека в системе получаем сигнатуру клавиатурного почерка и сравниваем ее со значениями, имеющимися в базе, по некоторому алгоритму. 3. Сравнение полученного значения отклонения с эталонным Alg(Sig(P'), Sig(P)) Теперь рассмотрим данный процесс со стороны злоумышленника. Допустим, злоумышленнику известно, что идентификация клавиатурного почерка происходит на основе запоминания времени между парами нажатых клавиш (сигнатура) и дальнейшего сравнения с эталонным вариантом с применением метода k-ближайших соседей (алгоритм). Зная эту информацию, злоумышленник легко может сгенерировать данные для возможной неверной идентификации, так как он находится в позиции первого класса модели исследователя. Чтобы перевести его ко второму классу, необходимо сделать схемы интерпретации неверными путем модификации системы с сохранением ее целевой функции. Здесь необходимо применить методологию защиты от исследования к используемому множеству параметров (принцип построения сигнатуры) и к алгоритму сравнения сигнатур. Для этих составляющих системы нужно ввести возможность структурного изменения с учетом некой концепции уникальности (реализация данной технологии применительно к системам защиты от исследования сайта была описана, например, в [3]). Схема защиты от исследования системы неявной идентификации злоумышленника приведена на рисунке 5. Например, концепция уникальности по структуре сигнатуры может использовать такие параметры, как скорость набора символов, количество символов в тексте, порядок набора и т.д. На основе этих параметров меняется структура сигнатуры. Например, если средняя скорость набора символов более 100 знаков в минуту, комбинируем данные из пар нажатых клавиш, если менее – комбинируем только интервалы. Порядок набора может быть параметром для объема символов для составления одной сигнатуры и пр. Если таких параметров более трех, то, как показывает практика, человек воспринимает такой процесс (в данном случае построение сигнатуры) как полностью хаотичный и может получить его только с применением специальных средств математического анализа на достаточно большом интервале времени. Аналогично строится концепция уникальности по структуре алгоритма. Дополнительными параметрами в этом случае могут выступать время, номер соединения, длина сигнатуры и пр. На основе этих данных можно менять сам алгоритм идентификации (метод k-ближайших соседей, Манхеттена, Махаланобиса и пр.). Алгоритм проектирования защищенной системы По мнению автора, единственный способ не дать контрагенту сформировать адекватные множества S', S''', S''''', … – это не дать ему определить исходные данные, такие как множества S, Sr, Рассмотрим построение защищенной от исследования системы на приведенном выше примере неявной идентификации злоумышленника по клавиатурному почерку. Исходя из всего вышесказанного можно сформулировать общий алгоритм построения за- щищенных от исследования информационных систем, находящихся в активной позиции на рисунке 1: 1. Определить множества S, Sr, 2. Определить возможный перечень дополнительных параметров. Их можно ввести в систему Sr, не изменяя ее целевой функции, при этом они делают схему интерпретации S' не соответствующей действительности. То есть осуществить диверсификацию процесса. 3. На основании предыдущего пункта сформировать концепцию уникальности, представляющую собой алгоритм работы системы в зависимости от исходных значений параметров. 4. Настроить концепцию уникальности таким образом, чтобы она соответствовала максимальному классу модели исследователя, но не ниже второго. Этого можно достичь комбинированием параметров алгоритма (если параметры выходят за область параметрической видимости, можно перевести систему ко второму классу) и его целевой функции (если область ее значений выходит за пределы множества функциональной видимости контрагента, можно перевести систему к четвертому классу). 5. Держать концепцию уникальности в месте, защищенном от несанкционированного доступа, или обеспечить автоматическую модификацию концепции при ее разовом чтении (второй способ предпочтительнее). Используя данный алгоритм, можно проектировать системы, которые в условиях конфликта контрагент не сможет спрогнозировать. То есть, используя некие шаблонные представления о системе, контрагент не сможет правильно построить ее функцию, а следовательно, правильно предсказать реакцию системы на его воздействия. Такими шаблонными представлениями в информационных системах могут быть, например, структура сетевого протокола и правила его обработки операционной системой, правило реакции програм- много кода на незащищенные уязвимости и т.п. На основании изложенного можно сделать следующие выводы. В настоящей статье сформулирован алгоритм построения защищенной системы, которая сама вынуждена заниматься исследованием в области конфликтных систем. В сфере информационной безопасности такими системами могут являться модули идентификации злоумышленников, совершаемых ими действий в системе, системы логирования, системы контроля доступа, системы IDS и пр. Данные механизмы были успешно апробированы на реальных прикладных задачах при разработке таких приложений, как ReflexionWeb и ExLook. Литература 1. Лефевр В.А. Рефлексия. М., 2003. 436 с. 2. Стюгин М.А. Методы защиты от исследования систем // Информационные войны. 2009. № 4. С. 23–29. 3. Семенкин Е.С., Стюгин М.А. Повышение информационной безопасности веб-сервера методом защиты от иссле- дования // Программные продукты и системы. 2009. № 3. С. 29–32. References 1. Lefevr V.A., Refleksiya [Reflection], Мoscow, 2003. 2. Styugin M.A., Informatsionnye voyny [Information wars], 2009, no. 4, pp. 23–29. 3. Semenkin E.S., Styugin M.A., Programmnye produkty i sistemy [Software & Systems], 2009, no. 3, pp. 29–32. |
 ходимо определить, каким образом могут происходить процессы, раскрываемые рефлексивным анализом в конфликте. Исследование всегда можно осуществить с наблюдением и интерпретированием некоторых параметров в системе. Наблюдаемые параметры обозначим через P, а схему интерпретации через S. В случае, например, задачи неявного распознавания злоумышленника по клавиатурному почерку, которая решалась при разработке таких приложений безопасности, как ReflexionWeb и ExLook, параметрами выступают наблюдаемые параметры, в частности, интервалы и последовательность нажатых клавиш, а также задержки во время нажатия клавиш. Схемой интерпретации в данном случае является алгоритм распознавания реального пользователя на основании этих данных. Такими алгоритмами могут являться, например, метод k-ближайших соседей, метод Манхеттена, Махаланобиса и пр., сравнивающие ранее известное значение сигнатуры и вычисленное в настоящий момент времени.
ходимо определить, каким образом могут происходить процессы, раскрываемые рефлексивным анализом в конфликте. Исследование всегда можно осуществить с наблюдением и интерпретированием некоторых параметров в системе. Наблюдаемые параметры обозначим через P, а схему интерпретации через S. В случае, например, задачи неявного распознавания злоумышленника по клавиатурному почерку, которая решалась при разработке таких приложений безопасности, как ReflexionWeb и ExLook, параметрами выступают наблюдаемые параметры, в частности, интервалы и последовательность нажатых клавиш, а также задержки во время нажатия клавиш. Схемой интерпретации в данном случае является алгоритм распознавания реального пользователя на основании этих данных. Такими алгоритмами могут являться, например, метод k-ближайших соседей, метод Манхеттена, Махаланобиса и пр., сравнивающие ранее известное значение сигнатуры и вычисленное в настоящий момент времени. Этот процесс можно продолжать бесконечно, как это показано на рисунке 4.
Этот процесс можно продолжать бесконечно, как это показано на рисунке 4. . Реальная среда может не принадлежать множеству этих видимых параметров:
. Реальная среда может не принадлежать множеству этих видимых параметров: 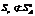 .
. , и, соответственно, не всегда реальные изменения могут быть наблюдаемыми для y:
, и, соответственно, не всегда реальные изменения могут быть наблюдаемыми для y:  .
.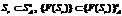 . Идеальная ситуация для исследователя A, так как он может получить объективную модель пространства Sr простым перебором входных значений. Это классическая модель черного ящика.
. Идеальная ситуация для исследователя A, так как он может получить объективную модель пространства Sr простым перебором входных значений. Это классическая модель черного ящика. . Субъект A сталкивается с невозможностью добиться информативной обратной связи, так как нужные параметры множества Sr не принадлежат множеству видимости A. Задача субъекта A – расширить множество видимых параметров и привести систему ко второму классу, так как исследование в данном случае бессмысленно.
. Субъект A сталкивается с невозможностью добиться информативной обратной связи, так как нужные параметры множества Sr не принадлежат множеству видимости A. Задача субъекта A – расширить множество видимых параметров и привести систему ко второму классу, так как исследование в данном случае бессмысленно.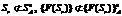 . Невозможность постановки задачи исследования. Как уже было описано в [2], исследователь в такой ситуации всегда может сопоставить с моделью черного ящика более простую функциональную структуру и убедиться в ее истинности. Субъект A не сможет изменить свою модель мира, пока система в силу каких-либо причин сама не перейдет к другому классу, позволив субъекту A сформулировать проблему исследования.
. Невозможность постановки задачи исследования. Как уже было описано в [2], исследователь в такой ситуации всегда может сопоставить с моделью черного ящика более простую функциональную структуру и убедиться в ее истинности. Субъект A не сможет изменить свою модель мира, пока система в силу каких-либо причин сама не перейдет к другому классу, позволив субъекту A сформулировать проблему исследования.
 .
.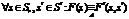 .
.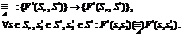
 Все описанное верно в случае, если поставить контрагента в позицию необходимости исследования наших систем. Тогда контрагент будет пытаться прогнозировать работу интересующей его системы и на основании этих прогнозов строить схемы интерпретации. Наблюдая обратную реакцию от системы, он может определять адекватность полученных схем (не во всех случаях, исключением является четвертый класс модели исследователя). В этом случае для того, чтобы склонить контрагента к построению понятных схем интерпретации, необходимо максимально диверсифицировать процессы в системе по уникальным параметрам, оставляя при этом функцию целевого назначения системы неизменной. Чтобы скрыть схемы интерпретации, необходимо сделать информацию о работе уникальных алгоритмов недоступной для контрагента, так как она фактически является «ключом» к функционированию системы (перевод системы к третьему классу исследования). Второе условие – сложность раскрытия концепции уникальности работы системы через обратную связь ее функционирования. То есть в концепции уникальности либо должно быть слишком много дополнительных параметров (тогда работа системы выглядит как хаотичная и крайне сложно распознать принципы ее работы), либо эти параметры должны быть для контрагента ненаблюдаемыми (четвертый класс исследователя).
Все описанное верно в случае, если поставить контрагента в позицию необходимости исследования наших систем. Тогда контрагент будет пытаться прогнозировать работу интересующей его системы и на основании этих прогнозов строить схемы интерпретации. Наблюдая обратную реакцию от системы, он может определять адекватность полученных схем (не во всех случаях, исключением является четвертый класс модели исследователя). В этом случае для того, чтобы склонить контрагента к построению понятных схем интерпретации, необходимо максимально диверсифицировать процессы в системе по уникальным параметрам, оставляя при этом функцию целевого назначения системы неизменной. Чтобы скрыть схемы интерпретации, необходимо сделать информацию о работе уникальных алгоритмов недоступной для контрагента, так как она фактически является «ключом» к функционированию системы (перевод системы к третьему классу исследования). Второе условие – сложность раскрытия концепции уникальности работы системы через обратную связь ее функционирования. То есть в концепции уникальности либо должно быть слишком много дополнительных параметров (тогда работа системы выглядит как хаотичная и крайне сложно распознать принципы ее работы), либо эти параметры должны быть для контрагента ненаблюдаемыми (четвертый класс исследователя).| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3592 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
| Статья опубликована в выпуске журнала № 3 за 2013 год. [ на стр. 219-223 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Функциональное сопоставление сложных систем информационной безопасности
- Повышение информационной безопасности веб-сервера методом защиты от исследования
- Алгоритм оценки значения остаточных рисков угроз информационной безопасности с учетом разделения механизмов защиты на типы
- Основные архитектурные и системные решения в технологии Интерин
- Прототип программного комплекса для анализа аккаунтов пользователей социальных сетей: веб-фреймворк Django
Назад, к списку статей