Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Combining compile-time and run-time instrumentation for testing tools
Аннотация:Dynamic program analysis and testing tools typically require inserting extra instrumentation code into the program to test. The inserted instrumentation then gathers data about the program execution and hands it off to the analysis algorithm. Various analysis algorithms can be used to perform CPU profiling, processor cache simulation, memory error detection, data race detection, etc. Usually the instrumentation is done either at run time or atcompile time – called dynamic instrumentation and compiler instrumentation, respectively. However, each of these methods has to make a compromise between performance and versatil-ity when used in industry software development. This paper presents a combined approach to instrumentationwhich takes the best of the two worlds – the low run-time overhead and unique features of compile-time instrumentation and the flexibility of dynamic instrumentation. Wepresent modifications of two testing tools that benefit from thisapproach: AddressSanitizer and MemorySanitizer. We propose benchmarks to compare different instrumentation frameworks in conditions specific to hybrid instrumenta-tion. We discuss the changes we made to one of the state-of-the-art instrumentation frameworks to significantly improve the performance of hybrid tools.
Abstract:Dynamic program analysis and testing tools typically require inserting extra instrumentation code into the program to test. The inserted instrumentation then gathers data about the program execution and hands it off to the analysis algorithm. Various analysis algorithms can be used to perform CPU profiling, processor cache simulation, memory error detection, data race detection, etc. Usually the instrumentation is done either at run time or atcompile time – called dynamic instrumentation and compiler instrumentation, respectively. However, each of these methods has to make a compromise between performance and versatil-ity when used in industry software development. This paper presents a combined approach to instrumentationwhich takes the best of the two worlds – the low run-time overhead and unique features of compile-time instrumentation and the flexibility of dynamic instrumentation. Wepresent modifications of two testing tools that benefit from thisapproach: AddressSanitizer and MemorySanitizer. We propose benchmarks to compare different instrumentation frameworks in conditions specific to hybrid instrumenta-tion. We discuss the changes we made to one of the state-of-the-art instrumentation frameworks to significantly improve the performance of hybrid tools.
| Авторы: Iskhodzhanov T. (timurrrr@google.com) - Moscow Institute of Physics and Technology (аспирант), Dolgoprudny, Россия, Kleckner R. ( rnk@google.com) - нет (инженер), New York, Соединенные Штаты, Stepanov E. (eug enis@google.com) - нет (инженер), г. Москва, Россия | |
| Ключевые слова: dynamic testing tools., hybrid instrumen-tation, binary rewriting, binary instrumentation, security testing, stability testing, software testing |
|
| Keywords: dynamic testing tools., hybrid instrumen-tation, binary rewriting, binary instrumentation, security testing, stability testing, software testing |
|
| Количество просмотров: 15665 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
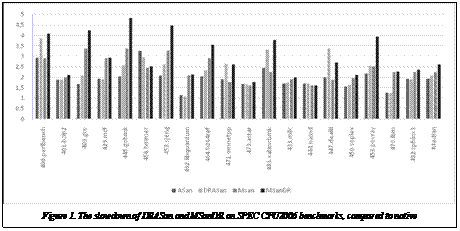
Many dynamic testing tools are based on dynamic instrumentation frameworks like Valgrind [1] (The name Valgrind is often used as a synonym to Memcheck, the memory error checking tool which runs by default when invoking Valgrind. In this paper, by Valgrind we mean the framework.), PIN [2] and DynamoRIO [3]. While using different tools for testing large applications like Chromium [4], we found these tools to be inefficient in some usage scenarios. During our experiments with AddressSanitizer [5], we found that compiler instrumentation can achieve better performance than similar tools based on dynamic instrumentation. However, compiler instrumentation adds requirements that can be hard to satisfy. For example, all the code should be built with compiler instrumentation in order to get full instrumentation coverage. This might be impossible (e.g. third party, proprietary or legacy libraries without available source code) or just hard in practice (e.g. system libraries), yet many error detection algorithms require instrumentation of all the program code in order to function correctly. The basic idea of hybrid instrumentation is simple – instrument whatever possible using a compiler, then instrument the rest of the program at run time. In theory, such a combined instrumentation should give us better performance than pure dynamic instrumentation and better flexibility than pure compiler instrumentation. Ideally, it should take the best from both worlds. Besides the well-known run time overhead of executing extra code added by instrumentation, we also found that the dynamic instrumentation process itself takes substantial amounts of time. In some scenarios where short-running tests are important (e.g. security fuzz testing [6]), tools based on dynamic instrumen- tation exhibited slowdowns orders of magnitude higher than they did on SPEC benchmarks. This slowdown does not show up when using compiler instrumentation as all the instrumentation is done at compile time. Contributions. In this paper we: – demonstrate the possibility of hybrid instrumentation by presenting modifications of two testing tools that use hybrid instrumentation; – show that by using hybrid instrumentation we can achieve the steady-state performance close to the performance of compiler-based instrumentation; – present new benchmarks that are well suited for assessing the startup performance of dynamic instrumentation frameworks and compare the state-of-the-art instrumentation frameworks on these benchmarks; – discuss optimizations we used to make DynamoRIO more efficient for hybrid instrumentation; – present a new approach which avoids redundant translation of modules instrumented by a compiler, specifically aimed at hybrid instrumentation. Related work Dynamic instrumentation frameworks. The standard heavyweight approach for dynamic instrumentation is called dynamic binary instrumentation (DBI), used by frameworks like Valgrind [1], PIN [2], and DynamoRIO [3]. When using DBI, the program’s code is processed before execution to insert instrumentation. Binary instrumentation frameworks usually provide an API for tools to read and modify the original code in some intermediate representation (e.g. expression trees or instruction lists), which is later transformed back into machine instructions. DBI usually does not require access to source code and the intermediate representation is usually quite simple. Therefore it is often used to write profilers, cache simulators, debuggers, error detectors etc. Some DBI frameworks perform optimizations during the program execution using the run-time data like basic block execution counts, merging frequent basic blocks together to form traces. Sometimes this kind of optimization actually improves the performance of the program over native execution [3]. Most DBI frameworks are capable of instrumenting self-modifying and JIT-generated code, which is a significant advantage over other instrumentation approaches. Unfortunately, DBI frameworks often incur significant run time overhead for a number of reasons: – decoding and encoding large amounts of code takes time during startup; – indirect branches require expensive emulation in software; – stealing registers required for instrumentation introduces slow register saves and restores; – instrumentation adds extra instructions, so the original code has to be moved, thus requiring updating relative offsets and making sure the uninstrumented version of the code is never called. These overheads can affect both startup time and steady state execution speed. Some instrumentation like adding red zones to stack variables might not be possible with DBI because not all the semantic information of the original code is put into compiled programs, especially when dealing with highly-optimized builds without debug information. Static instrumentation. Static binary instrumentation (SBI) tries to minimize the run-time cost of instrumentation by doing it before run (e.g. at link time or as a separate command). The main problem with static instrumentation is that it usually requires debug information in order to disassemble the program correctly [7, 8]. If the debug information is not available, the instrumenter cannot always tell where all the code in the program is and where functions begin. In most cases when debug information is available it should be possible to use compiler instrumentation described below. SBI is limited in transformation of stack variables for the same reason as DBI. Compiler instrumentation. Instrumentation can sometimes be added as a compiler pass which operates on source code or intermediate representation level rather than assembly. Probably one of the well-known examples are gcc extensions called gcov and mudflap [9, 10]. A similar source-to-source instrumentation technique is used in CCured [11]. Even though such instrumentation requires source code or intermediate code being available, it might sometimes be preferred. For example, for tools like AddressSanitizer [5] it allows to change the memory layout of data types or stack variables (like introducing red zones), thus making more functionality possible. As LLVM-based AddressSanitizer and ThreadSanitizer [12, 13] had shown, it is possible to create memory error detection tools based on compiler instrumentation writing less code yet achieving better performance compared to an equivalent DBI-based tool. Compiler instrumentation is usually performed before the low-level compiler passes like register allocation thus resulting in better run-time performance thanks to merging parts of instrumentation together, spilling fewer register etc. Compiler instrumentation operates at a higher level than DBI, so a single operation that needs to be instrumented might turn into multiple low-level memory operations that a dynamic tool will try to instrument individually. Also, compiler instrumentation can sometimes be improved by performing static analysis on source code level to avoid redundant checks for code that is obviously correct or just not interesting [14], thus achieving even better performance. Doing such optimizations at run time in a DBI-based tool looks impractical due to even higher startup time overhead. Hybrid instrumentation. There are a few different flavors of hybrid instrumentation. DynamoRIO provides persistent code cache API so tool writers can store the instrumented code onto disk to reuse on the next run [15]. Roy et al. [16] present a PIN-based tool which also writes the dynamically instrumented code into a persistent instrumentation cache (PIC) to save some time on next run. PIN API does not provide ways to work with persistent cache, so this was achieved by carefully crafted manual methods. By narrowing the scope of their paper to instrument only critical sections of the code surrounded by mutex acquire/release operations, they are able to efficiently detect all the possible transitions between uninstrumented and instrumented code, thus delivering near-native execution performance on programs that require little instrumentation. They also acknowledge the fact that their approach may not guarantee complete instrumentation of all the critical sections, which works well for their task, but might not suit everybody. Nanda et al. [8] present a technique which allows static instrumentation of binaries with neither debug information nor source code available. Usually this is rather complex as one needs to know the function boundaries etc. in order to correctly extract basic blocks. Their approach is somewhat similar to hybrid instrumentation as they first instrument as much as possible statically then fall back to run-time instrumentation when needed. However, they use a post-compile instrumentation for static processing rather than use a compiler plugin. Bernat et al. [17] advance this idea even further in the Dyninst instrumentation framework which allows one to add instrumentation before the run, as well as do all the instrumentation at run-time. Hybrid tools In this section, we present two tools based on hybrid instrumentation that we developed, in chronological order. These tools use different approaches which are beneficial when using hybrid instrumentation: increasing coverage and eliminating false positives. DRASan. The first hybrid tool we developed is DRASan, a hybrid version of AddressSanitizer for Linux [5]. AddressSanitizer is a memory error detector capable of detecting out-of-bounds memory accesses for globals, heap-allocated and stack-allocated memory, as well as accesses to freed heap memory. As many others memory error detection tools, AddressSanitizer uses shadow memory to store additional information about the data of the application. Aligned 8 bytes of application memory can be in one of three high-level states: available, partially available (e.g. only the first 4 bytes) or unavailable. All interesting states fit into a single shadow byte so simple instrumentation is used together with a continuous direct 8-to-1 address mapping. The AddressSanitizer algorithm requires one shadow memory lookup before each memory access. A custom memory allocator takes care of filling the shadow bytes for heap allocations accordingly, as well as red zones around the allocations to detect out-of-bounds accesses and memory quarantine to detect use-after-free bugs. Red zones and shadow memory for the stack memory are maintained by the compiler instrumentation. The original AddressSanitizer was implemented as an LLVM instrumentation pass to get high performance. Such instrumentation only applies to the code that is built with the pass enabled. The algorithm does not produce false reports if the program is partially instrumented, but may miss bugs in the uninstrumented code. In some cases, these bugs may be interesting to look at though. To increase code coverage with AddressSanitizer, we have decided to write a hybrid tool based on DynamoRIO that adds instrumentation to the dynamic libraries. The tool is about 700 LOC and its instrumentation is similar to that injected by the original AddressSanitizer. Unfortunately, it does not put red zones around stack or globals in the dynamic libraries due to the limitations of DBI. We successfully ran the Chromium browser under DRASan. We found a few memory error reports, most of which agree with the previously-known Memcheck reports on memory errors or aggressively optimized code in Ubuntu system libraries (For example, a function reading 8 bytes of buffer and applying a mask when given size equals to 4. One may argue it is a bug and consider not instrumenting functions or modules with such code.). MemorySanitizer. MemorySanitizer [18] is a new Linux tool for detecting use of uninitialized memory in C/C++ programs. It is similar to the Valgrind tool Memcheck [19], but with instrumentation code being added at compilation time. For each bit of the application memory MemorySanitizer keeps one bit of shadow memory which tells whether the corresponding application bit is undefined. To avoid false positive warnings when copying uninitialized data (e.g. memcpy), we propagate shadow values when copying memory or doing different arithmetic or logic operations in an operation-specific way. For example, copying application memory requires copying the shadow values and the result of most bitwise operations is a bitwise OR of the shadow values of the operands. An undefined memory error is reported only when an undefined value affects program control flow (i.e. used in a branch condition) or the environment (e.g. used as a system call argument), which is what Memcheck does as well. The nature of uninitialized memory requires all the memory store instructions in a program to be instrumented, otherwise false positive reports are possible. Indeed, if for some reason the tool does not observe a memory store that can potentially turn an uninitialized value into a fully initialized one, the shadow for that value is not updated and the tool may print a false report when such value is later used in some computation. One possible approach to achieve complete instrumentation is to rebuild most of the code of a program with MemorySanitizer instrumentation. Parts of the code that are difficult or impossible to rebuild from source (e.g. libc, kernel vsyscall page, dynamic loader) can be handled by wrapping the entry points and updating the shadow memory state in the wrappers. MemorySanitizer provides a large of set of wrappers for the C standard library. We successfully used a combination of recompiling and wrapping to test projects as large as the Clang compiler [20]. For most other projects, especially ones that depend on external libraries, rebuilding everything from source might be impractical or impossible. This is where hybrid instrumentation comes in. A simple DynamoRIO-based tool called MSanDR is used to observe all memory stores from external libraries not instrumented during compilation time and insert code to set the corresponding shadow bits to ”initialized”. The dynamic tool also intercepts all system calls in the program and updates the shadow for the memory written in the OS kernel. It is important to note that unlike with AddressSanitizer, we have decided to not implement full instrumentation in the MemorySanitizer dynamic tool. We successfully ran the Chromium browser as well as WebKit [21] DumpRenderTree test tool with the hybrid MemorySanitizer. We confirmed the previously-known Memcheck reports and found a few unique uninitialized memory bugs in WebKit. Performance and evaluation In this section, we evaluate the performance of our hybrid tools and different DBI frameworks. The performance characteristics of DBI-based tools consist of steady state execution slowdown and startup instrumentation overhead. We measure the steady state slowdown using SPEC benchmarks and suggest benchmarks to evaluate the startup overhead. Performance of DRASan and MSanDR. To evaluate the steady state slowdown of DRASan and MSanDR, we ran SPEC CPU2006 benchmarks. For the AddressSanitizer and DRASan runs we used the latest stable version of Clang [20] (which is Clang 3.2) as the compiler. For the MemorySanitizer and MSanDR runs we used the latest trunk version of Clang (r182754) as MemorySanitizer was not yet functional in version 3.2. The tests were run on HP Z600 with dual Intel Xeon E5620 CPUs, 24GB of RAM on Ubuntu 12.04 with power saving options disabled. Figure 1 shows the results of the benchmarks. The median slowdown of DRASan is 2.07x which is 8 % slower than the original AddressSanitizer. The median slowdown of MSanDR is 2.62x which is 17 % slower than the compiler-only MemorySanitizer. Startup overhead of dynamic instrumentation frameworks. State-of-the-art dynamic instrumentation frameworks increase the run time between 1x and 4x on SPEC tests [1, 2, 3]. However, we observed much higher overheads while doing security fuzz testing of the Chromium browser using DBI-based tools like Memcheck and early versions of hybrid tools. A typical scenario of security fuzz testing is to start a browser, load some generated HTML and see if the browser crashes. If it crashes, try to minimize the HTML and report it; otherwise, generate another HTML and repeat. A substantial part of this procedure is browser startup, which becomes the bottleneck. This is a problem in more typical testing scenarios as well, since integration tests for large applications often launch a new instance of the application for each test case in order to improve test isolation. Even when the absolute startup time is small, the high relative slowdown makes large-scale testing inefficient. To show the slowdown of di
For each of these files we ran “clang -cc1 -w -emit-obj ”. The “-cc1” flag avoids creating subprocesses, thus we do not measure the process startup overhead twice. The second program was DumpRenderTree r100089 (DRT), which is part of the test harness for WebKit [21]. It takes HTML files as an input and outputs the corresponding web page layout in a text representation, which is useful for conformance testing of WebKit-based browsers. DumpRenderTree-like tools are also very convenient for security and stability testing, thus its performance is important to us. The input files were a simple one-line ”Hello, world” in HTML and a 240KB BuildBot 0.7.2 manual as a single page. The tests were run on HP Z600 with dual Intel Xeon E5620 CPUs, 24GB of RAM, Ubuntu 12.04 with gcc 4.6.3 and power saving options disabled. Each instrumentation framework was run with the default options. For each combination, we ran three bursts of five runs each and chose the mean execution time in the fastest burst. We found such a method to give reproducible numbers across runs, even for short-running tests. The results are presented in the Table 1. Based on these results, most of the startup overhead comes from the DBI framework rather than from the instrumentation added by the ”count” tool. These numbers also show overhead of up to 700x, which is a lot more than 4x observed on SPEC tests. However, talking in terms of multiplicative slowdown is not very applicable when comparing performance on short run times. As can be seen from the Figure 2, the run time of an instrumented binary is approximately a linear function of native run time:
where ‘t‘ is the native run time, ‘T‘ is the instrumented binary run time, while ‘Instrumentation‘ and ‘Slowdown‘ are functions of the code being run ‘C‘ and the instrumentation framework ‘F‘ used. SPEC benchmarks have relatively little code and run for a long time, thus its run time is hardly affected by the performance of the instrumentation module; On the other extreme, large applications like DumpRenderTree or Chromium browser need to execute so much code just a few times during their startup that the instrumented code cache often does not help. As a result, the performance of the instrumentation module becomes a bottleneck. In some scenarios like automated minimization of test cases the startup performance and especially low startup-time/execution-time ratio matter more than just steady state execution speed. As a result, there is a compromise between startup time and steady state execution slowdown. We would like to emphasize the importance of the startup time for testing tools and note that only a few academic papers pay enough attention to this subject [8,15]. DynamoRIO optimizations for hybrid tools Based on the data, as we said earlier, DynamoRIO has the fastest instrumentation module and it provides the fastest steady-state execution of the three frameworks [3]. It is also open source, so we chose to use DynamoRIO for our hybrid tools. However, initilally we were not satisfied with the startup performance of DynamoRIO. In this section we present a few optimization techniques we applied to DynamoRIO trying to improve the performance of hybrid tools. Most of them are based on the idea of avoiding work for code that is already instrumented by a compiler. Fast decode for compiler-instrumented code. One of the major sources of startup overhead in DBI tools is from the decoder and encoder. ISAs like x86 in particular require expensive processing to create a representation that is usable for analysis and instrumentation. Typically, the overhead of DBI for each original instruction is on the order of thousands of instructions [24]. However, in the context of hybrid tools, that decoding is completely unnecessary for the parts of the program that are compiler-instrumented. Internally, DynamoRIO and other DBI frameworks still need to decode some instructions in order to function. For example, control flow instructions need to be modified to ensure that the framework maintains control of future execution. DynamoRIO has been deployed in security contexts at Determina, where only light instrumentation was needed. It therefore has a set of latent fast paths for skipping over uninteresting instructions and only decoding interesting instructions such as control flow. We made changes to DynamoRIO API to provide the tool writers a function to tell that a particular module will not be instrumented, thus allowing the framework to use the fast instruction decoder. Table 2 shows that using this function alone has improved the performance of the ”count” tool on our tests by 2.5–3.5x. The startup cost of building traces. The other major improvement came with disabling the trace optimizations in DynamoRIO. Even though such optimization is often used for running SPEC tests, we found it to negatively impact the startup performance of hybrid tools. This is probably related to the compromise between startup time and steady state execution slowdown we discussed earlier. Table 2 shows that disabling the traces optimization improved the performance by 1.25–2.5x on startup tests. The performance difference between DynamoRIO with a tool and without a tool became negligible. Using persistent code cache. We tried using the persistent code cache infrastructure that DynamoRIO provides, but only got negative impact on the performance of hybrid instrumentation. This might be caused by a Linux-specific bug as using the DynamoRIO persistent cache is known to improve startup times on Windows [15]. It is not clear if persistent code cache optimization is fully applicable to the code already instrumented by a compiler as reading the code cache and checking it for consistency may incur additional load on the memory bus or even hard drive and may outweigh the positive effect of caching. Native execution of compiler-instrumented code. Instead of storing the translated code cache on the disk, we have decided to remove the requirement of translating the compiler-instrumented modules. Executing the compiler-instrumented code natively is a conceptually simple but subtly complex approach to optimization. We implemented an experimental prototype of this idea in DynamoRIO to demonstrate its usefulness. Fundamentally, DBI frameworks are about maintaining control of the application in the face or arbitrary instructions and control flow. If any code is executed natively, there is no guarantee that it will return or behave correctly.
We contributed a prototype of a native execution system for DynamoRIO that can run ELF programs on Linux. The prototype can only switch between native execution and code cache interpretation at a module boundary. A module in this context is a dynamic shared object (DSO or DLL) or an executable. In order to stay in control, the native module must obey the following rules. · No system calls can be made from the native module. · All cross-module control flow must come from source level calls compiled in the usual manner. · All direct, cross-module calls must be resolved by the native loader. · All indirect calls have extra instrumentation to detect indirect cross-module calls. · The code must tolerate return address swapping at module boundaries. This implies the prototype does not support exceptions well. In particular, this means there can’t be assembly trampolines or uninstrumented object files in the module, or we will miss some control flow leaving the module. With these restrictions in place, our prototype hooks all module entrances and exits, and ensures that the execution is instrumented dynamically. This is implemented by inspecting the ELF program headers and finding the PLT GOT. The PLT GOT is a table of function pointers of resolved symbols. Our prototype swaps out each code pointer with a stub to code that saves the pointer and re-enters DynamoRIO for instrumentation. When control enters a native module, we simply swap the return address with a stub which will re-takeover execution at the application return address. Intercepting indirect calls is not yet implemented in our prototype. However, based on the performance benefits of native execution shown in Table 3, we expect the benefit of native execution will outweigh the cost of the extra static instrumentation checks at call sites, most of which will not be calling across module boundaries. We also wrote a dynamic tool to analyze clang that showed that it has few cross-module indirect calls. DumpRenderTree, on the other hand, has many cross-module calls, both direct and indirect. Therefore we chose not to benchmark DumpRenderTree with this prototype. Any missed cross-module indirect calls could interfere with DynamoRIO’s execution, making any performance numbers questionable at best. The results on clang represent best case estimation for native execution and should be interpreted as such. As shown in the Table 3, native execution has an enormous impact on startup performance for short running applications. The shortest clang runs are more than ten times faster than what we had with DynamoRIO before we applied the optimizations described in this section. As the program runs longer, however, we start to see the effect wear off as the code cache is populated and the cost of building it is amortized. The table also shows that native execution of AddressSanitizer instrumented code is particularly helpful for long running tests. One of the major characteristics of AddressSanitizer instrumentation is that it inserts a conditional branch before every memory access. We hypothesize that this is slowing DynamoRIO down by splitting up lots of basic blocks that would have been merged if compiled without instrumentation. While this may not characterize all compiler instrumentation tools, we expect many error detection tools will have many branches for error reporting. Future work We hope that further development of native execution support in DynamoRIO will eliminate much of the startup overhead for hybrid tools. In particular, to move beyond the prototype stage, indirect cross-module calls need to be caught as hybrid tools like MSanDR need to see all of the code in order to function properly. The initial prototype implementation also creates lots of extra unnecessary overhead on cross-module transitions which should be eliminated. Apps like DumpRenderTree have lots of cross-module calls in the hot path, and this optimization will be critical for making them run quickly. Another possible approach to hybrid instrumentation is to use SBI frameworks to instrument the dynamic libraries used by the application. We tried to write a ”count” tool for Dyninst [17] and evaluate its performance. However, we were not satisfied with both static and dynamic instrumentation time for Dyninst. For example, it took one hour of CPU time and 10GB of RAM to statically instrument just two dynamic libraries linked into DumpRenderTree and add an exit callback to print run-time stats. Nevertheless, this approach sounds promising in general and may be a good direction for future research on hybrid instrumentation. An interesting topic that we haven’t covered in this paper is a common instrumentation API for hybrid instrumentation. Currently, compilers and DBI frameworks provide completely different APIs for the instrumentation tool writers, which increases the complexity of developing tools that utilize both. Conclusions In this paper, we presented a new hybrid approach to instrumenting programs by combining compile-time and run-time instrumentation. We developed two dynamic testing tools that benefit from such instrumentation. We suggested benchmarks for performance evaluation of dynamic binary instrumentation frameworks and significantly improved the performance of the fastest state-of-the-art dynamic instrumentation framework. We believe that combining compile-time and run-time instrumentation can be used for a wide range of dynamic tools, which will be both faster and more useful that the current generation of such tools. References 1. Nethercote N., Seward J., Proc. of the ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI ’07), 2007, pp. 89–100. 2. Luk C.K., Cohn R., Muth R., Patil H., Klauser A., Lowney G., Wallace S., Reddi V.J., Hazelwood K., Proc. of the 2005 ACM SIGPLAN conf. on Programming language design and implementation (PLDI'05), 2005, pp. 190–200. 3. Bruening D., Efficient, Transparent, and Comprehensive Runtime Code Manipulation, PhD thesis, M.I.T., 2004. 4. The Chromium project, available at: http://dev.chromium.org (accessed 17 June 2013). 5. Serebryany K., Bruening D., Potapenko A., Vyukov D., Proc. of the 2012 USENIX conf. on Annual Technical Conf., 2012, pp. 28–28. 6. The Chromium Blog, available at: http://blog.chromium.org/2012/04/fuzzing-for-security.html (accessed 17 June 2013). 7. SyzyASan design document, available at: http://code.google.com/p/sawbuck/wiki/SyzyASanDesignDocument (accessed 17 June 2013). 8. Nanda S., Li W., Lam L.C., Chiueh T.C., Proc. of the Int. Symp. on Code Generation and Optimization (CGO'06), pp. 358–370. 9. Gcov – a Test Coverage Program, available at: http://gcc.gnu.org/onlinedocs/gcc/Gcov.html (accessed 17 June 2013). 10. Eigler F.C., GCC Developers Summit, 2003, p. 57. 11. Necula G.C., McPeak S., Weimer W., ACM SIGPLAN Notices, 2002, Vol. 37, pp. 128–139. 12. Serebryany K., Potapenko A., Iskhodzhanov T., Vyukov D., Proc. of the 2nd int. conf. on Runtime verification (RV'11), 2011, pp. 110–114. 13. Serebryany K., Iskhodzhanov T., Proc. of the Workshop on Binary Instrumentation and Applications (WBIA '09), 2009, pp. 62–71. 14. Hasabnis N., Misra A., Sekar R., Proc. of the Int. Symp. on Code Generation and Optimization (CGO ’12), 2012, pp. 135–144. 15. Bruening D., Kiriansky V., Proc. of the fourth ACM SIGPLAN/SIGOPS int. conf. on Virtual execution environments, 2008, pp. 61–70. 16. Roy A., Hand S., Harris T., Proc. of the 7th ACM SIGPLAN/SIGOPS int. conf. on Virtual execution environments (VEE ’11), 2011, pp. 227–238. 17. Bernat A.R., Miller B.P., Proc. of the 10th ACM SIGPLAN-SIGSOFT workshop on Program analysis for software tools (PASTE ’11), 2011, pp. 9–16. 18. MemorySanitizer, available at: http://code.google.com/p/memory-sanitizer (accessed 17 June 2013). 19. Seward J., Nethercote N., Proc. of the USENIX Annual Technical conf., 2005, p. 2. 20. Clang: a C language family frontend for LLVM, available at: http://clang.llvm.org (accessed 17 June 2013). 21. WebKit, an open source web browser engine, available at: http://www.webkit.org (accessed 17 June 2013). 22. Bzip2, a data compressor, available at: http://www.bzip.org (accessed 17 June 2013). 23. SQLite, an SQL database engine, available at: http://www.sqlite.org (accessed 17 June 2013). 24. Hu S., Smith J.E., ACM SIGARCH Computer Architecture News, 2006, pp. 277–288. |
 We have decided to avoid implementing the complete definedness checks and reporting for external libraries. The main reason for that is that it is a huge project and might significantly increase the execution overhead for the external libraries. Also, these libraries often have lots of false positives due to optimizations (For example, the Chromium project has Memcheck suppressions for uninitialized reads in all of libc and ld.so because of false positives that the user can do nothing about.), so the value of the full instrumentation is questionable. Instead, we expect that all interesting parts of code are instrumented at compilation time, and the dynamic tool merely helps us avoid false positives from the code that the user does not control.
We have decided to avoid implementing the complete definedness checks and reporting for external libraries. The main reason for that is that it is a huge project and might significantly increase the execution overhead for the external libraries. Also, these libraries often have lots of false positives due to optimizations (For example, the Chromium project has Memcheck suppressions for uninitialized reads in all of libc and ld.so because of false positives that the user can do nothing about.), so the value of the full instrumentation is questionable. Instead, we expect that all interesting parts of code are instrumented at compilation time, and the dynamic tool merely helps us avoid false positives from the code that the user does not control.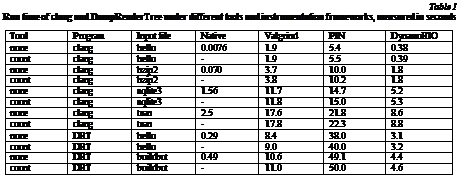 fferent instrumentation frameworks on a simpler setup, we wrote a ”count” tool for each of these three instrumentation frameworks. These tools count the number of memory reads/writes in some dynamic libraries (We chose libstdc++ and fontconfig as they are used in the programs we ran as benchmarks below.), one increment for every original instruction (Please note that many papers on dynamic instrumentation focus on the performance of basic block counting tool. We chose to use a different benchmark since it better reflects the instrumentation patterns of DRASan and MSanDR. Namely, it adds instrumentation to every memory access in contrast to only basic block entry points.). Ideally, the overhead should be proportional to the amount of instrumentation added, including zero overhead in case no instrumentation is added. To see what happens in reality, we made it easy to disable all the instrumentation for each tool, i.e. register as few instrumentation callbacks as possible, getting the ”none” tool for each framework. Then we compared their run time on two program with different inputs, with and without instrumentation. For each program, the first input file is very short, i.e. we intentionally exaggerate the startup overhead of instrumentation.
fferent instrumentation frameworks on a simpler setup, we wrote a ”count” tool for each of these three instrumentation frameworks. These tools count the number of memory reads/writes in some dynamic libraries (We chose libstdc++ and fontconfig as they are used in the programs we ran as benchmarks below.), one increment for every original instruction (Please note that many papers on dynamic instrumentation focus on the performance of basic block counting tool. We chose to use a different benchmark since it better reflects the instrumentation patterns of DRASan and MSanDR. Namely, it adds instrumentation to every memory access in contrast to only basic block entry points.). Ideally, the overhead should be proportional to the amount of instrumentation added, including zero overhead in case no instrumentation is added. To see what happens in reality, we made it easy to disable all the instrumentation for each tool, i.e. register as few instrumentation callbacks as possible, getting the ”none” tool for each framework. Then we compared their run time on two program with different inputs, with and without instrumentation. For each program, the first input file is very short, i.e. we intentionally exaggerate the startup overhead of instrumentation.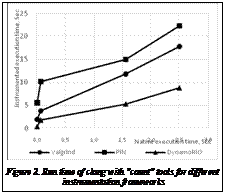 The first program was clang 3.2, an open-source C/C++ compiler [20]. We tested its performance on four different input files: a simple ”hello, world” program in C, a 176KB preprocessed bzip2.c from bzip2 1.0.6 [22], a 1.6MB preprocessed SQLite 3.7.15.2 [23] source code as a single file and a 1.0MB preprocessed thread_sanitizer.cc from the Valgrind-based ThreadSanitizer (tsan) source code [13]. In order to minimize the possible variable latency due to disk accesses, we used preprocessed source files for all these tests, except for the hello test where we just declared the printf function in the source file instead of including the “stdio.h” header.
The first program was clang 3.2, an open-source C/C++ compiler [20]. We tested its performance on four different input files: a simple ”hello, world” program in C, a 176KB preprocessed bzip2.c from bzip2 1.0.6 [22], a 1.6MB preprocessed SQLite 3.7.15.2 [23] source code as a single file and a 1.0MB preprocessed thread_sanitizer.cc from the Valgrind-based ThreadSanitizer (tsan) source code [13]. In order to minimize the possible variable latency due to disk accesses, we used preprocessed source files for all these tests, except for the hello test where we just declared the printf function in the source file instead of including the “stdio.h” header.
 most of the execution happens in the instrumented code cache. This is also the case for clang when the input file is large enough.
most of the execution happens in the instrumented code cache. This is also the case for clang when the input file is large enough.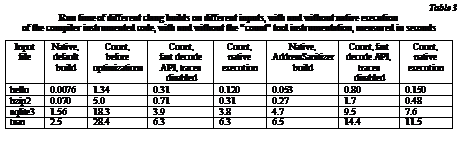 In the context of hybrid instrumentation, since the code we wish to execute is instrumented by a compiler, we can rely on the compiler to help the DBI framework stay in control.
In the context of hybrid instrumentation, since the code we wish to execute is instrumented by a compiler, we can rely on the compiler to help the DBI framework stay in control.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3593 |
Версия для печати Выпуск в формате PDF (13.63Мб) Скачать обложку в формате PDF (1.39Мб) |
| Статья опубликована в выпуске журнала № 3 за 2013 год. [ на стр. 224-231 ] |
Назад, к списку статей