Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Поддержка решения задачи идентификации сущности методами информационного поиска
Аннотация:
Abstract:
| Авторы: Бердник В.Л. () - , Заболеева-зотова А.В. (zabzot@vstu.ru) - Волгоградский государственный технический университет, доктор технических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 9623 |
Версия для печати Выпуск в формате PDF (1.17Мб) |
В данной статье рассматривается применение методов информационного поиска для задачи идентификации сущности. Необходимость решения задачи идентификации сущности встречается в маркетинговых исследованиях, когда требуется сопоставить между собой большие группы товаров конкурентов, единственной информацией о которых является строка с определенными лингвистическими особенностями. Под высказыванием идентификации сущности (далее – высказывание) будем понимать символьную строку конечной длины. Высказывание идентифицирует сущность либо группу семантически близких сущностей, воспринимаемых согласно предметной области как единое явление. Под термином «Издатель», будем понимать субъект общества, в котором группа людей пополняет БД высказываний идентификаций сущностей. Под термином «Потребитель» будем понимать компьютерную систему анализа и сопоставления высказываний различных Издателей. Введем следующие обозначения: · U – универсум высказываний, в данном случае – специальный корпус текстов; · S – универсум идентифицируемых сущностей; · U+ – множество высказываний U+ÌU, для которого известно Потребителю соответствие f:U+ÞS; · Ts+ – множество известных Потребителю синонимов идентификации заданной сущности s, так что "Ts+ Ì U+ & f:Ts+Þs; · D – коллекция документов D={d}, где d – конкатенация строк всех высказываний множества Ts+. Документ d идентифицирует заданную сущность s. Коллекция документов D соответствует множеству S+ÌS и является неполной. Дополнение множества Задача идентификации сущности – это поиск биективного соответствия между коллекцией документов D={d} и произвольным множеством высказываний {V| VÎU & VÏU+}. Для каждого высказывания V необходимо выбрать один из альтернативных вариантов сущностей S+, представленный документом из коллекции D. Высказывание V может недостаточно точно идентифицировать сущность. В этом случае ЛПР привлекает дополнительную информацию о сущности, например, из иллюстрированного каталога. Компьютерная система поддержки решения задачи идентификации сущности должна предложить оператору системы краткий список наиболее релевантных высказыванию V документов коллекции D. Существует три способа задания сущности. Экстенсиональное задание – высказывание содержит кодовое обозначение (модель изделия, уникальное название (например книги), код по классификатору (например ISBN) и тому подобное), однозначно идентифицирующее сущность. В этом случае задача сводится к детерминированному извлечению из высказывания и сопоставлению с образцом кодового обозначения. Допускаются высказывания, состоящие только из кодовых обозначений. Например, высказывание «МФУ HP LJ 3380 (Q2660A) лазерный + копир + сканер» имеет кодовое обозначение Q2660A, полностью идентифицирующее изделие. Интенсиональное задание – высказывание содержит задание предикатов сущностей семантически самостоятельными единицами. В этом случае возможны различные явления естественного языка: лексическая полисемия, синонимия, внелингвистическая пресуппозиция и т.д. Рассмотрим пример синонимии идентификации изделия «Устройство для подключения принтеров с разъемом LPT к порту USB компьютера с кабелем»: контроллер USB-LPT 2.0m; адаптер USB-LPT 2.0m; кабель USB-LPT 2.0m. В примере для идентификации «устройства с кабелем» используются термы: «контроллер» – сложное электронное устройство; «адаптер» – коробка с проводом; «кабель» – средство подключения принтера к компьютеру. Слова «контроллер», «адаптер», «кабель» не являются лексическими синонимами, каждому слову соответствует свое семантическое значение. В указанном примере между термами и предикатом сущности существуют нечеткие отношения, а именно используются элементы из группировки объектов с некоторым общим свойством (предикатом) сущности. Смешанное задание – высказывание содержит кодовое обозначение, которое неоднозначно идентифицирует сущность. Кодовое обозначение должно сочетаться с указанием дополнительных предикатов. Рассмотрим следующие модели информационного поиска: простейшую, булеву, а также векторные и вероятностные модели поиска. В простейших моделях поиска документ представляется в виде набора ассоциированных с ним внешних атрибутов. В простейших системах дескрипторного поиска представление документа описывается совокупностью слов или словосочетаний лексики предметной области, которые характеризуют содержание документа. Эти слова и словосочетания называются дескрипторами. Предположим, что имеется дескриптор, обладающий свойствами: ($wy $d+ "d¹d+[(wyÎd+)Ù(wyÏd)]), (1) где wy – дескриптор, описывающий документ d+ÎD; d – произвольный документ коллекции D. При истинном выражении (1) условие релевантности высказывания V документу d+ можно экстраполировать как ("V wyÎV)Þ("d¹d+[(VÎd+)Ù(VÏd)]). (2) Так как выражение (2) может оказаться ложным, при добавлении (например прочими методами) высказывания V в коллекцию D нарушается истинность выражения (1) и теряется актуальность дескриптора wy. Простейшие модели наиболее эффективны в случае экстенсионального задания сущности. Булева модель поиска является классической и широко используемой моделью представления информации, базирующейся на теории множеств, и, следовательно, моделью информационного поиска, базирующейся на математической логике. В булевой модели запрос пользователя представляет собой логическое выражение, в котором ключевые слова связываются операторами из теории множеств и соответствующими им логическими операторами AND, OR и NOT. Рассмотрим два примера. 1. Мат. плата Sock775 ASUS P5B DDR2-800+, FSB1066, PCI-E, Sound, USB 2.0. 2. Мат. плата Sock775 ASUS P5B Deluxe/WiFi-AP DDR2-800+, FSB1066, PCI-E, Sound, USB 2.0. Первое высказывание содержит условное кодовое обозначение «P5B», что указывает на определенное изделие из совокупности материнских плат производства ASUStek. Во втором примере содержится кодовое обозначение «P5B Deluxe/WiFi-AP», что указывает на модификацию исходного изделия. Определим состав и структуру предполагаемых запросов для представленных в примере высказываний. Изделию из примера № 2 соответствует булево выражение: “Мат. плата” & (“ASUS” Ú “ASUStek”) & “P5B Deluxe/WiFi-AP”. Базовое изделие из примера номер 1 должно содержать отрицание всех модификаций базового изделия: NOT(“P5B Deluxe/WiFi-AP”)& “Мат. плата” & (“ASUS” Ú “ASUStek”) & “P5B”. Если во время эксплуатации программной системы происходит разработка новых модификаций изделий, создать адекватное для идентификации сущности булево выражение невозможно. Булева модель обладает высоким быстродействием и позволяет эффективно отсекать нерелевантные документы коллекции D на основе анализа высказывания V. Возможно автоматическое построение булева выражения на основе анализа (встречаемости определенного терма) высказывания V и задание человеком-оператором булева выражения для каждого документа коллекции D. Векторно-пространственная модель является классической алгебраической моделью. В рамках этой модели документ описывается вектором в некотором евклидовом пространстве, в котором каждому используемому в документе терму ставится в соответствие его вес (значимость). Вес определяется на основе статистической информации об его встречаемости в отдельном документе или в коллекции документов. Таким образом, каждый документ и запрос могут быть представлены в виде k-мерного вектора: Если высказывание состоит из нескольких предложений, то для задания локального веса терма можно воспользоваться какой-либо из распространенных мер взвешивания локальных термов по частоте f, например:
Для высказываний идентификации сущности, состоящих из одного предложения, характерна однократная встречаемость терма, поэтому локальная частота терма в документе равна или меньше числа высказываний и характеризует типичность терма для идентификации сущности (меру включения подмножества высказываний с термом к множеству всех высказываний документа):
где nij – число высказываний документа dj, содержащего терм ti; Nj – общее количество высказываний в документе dj. Глобальные веса термов усиливают различие по степени важности между термами, основываясь на их распределении между всеми документами. Если терм встречается во всех документах коллекции D, он не несет никакой информации о различии сущностей, следовательно, его релевантность равна нулю. Терм, встречающийся только в одном документе, имеет наибольшую релевантность и, как правило, идентифицирует сущность. Вес терма в наиболее распространенной модели TFxIDF рассчитывается по формуле:
где |D| – количество документов в коллекции D; mi – число документов коллекции D, содержащий терм ti. Существует множество различных моделей взвешивания по локальной и глобальной частоте терма (TFxIDF, TFC, ITC, OKAPI и т.д.), которые в той или иной степени описывают (психологические) закономерности построения текста естественного языка. Вероятностная модель поиска базируется на теоретических подходах байесовских условных вероятностей. В канонической вероятностной модели используется упрощение, заключающееся в предположении независимости вхождения в документ любой пары термов. Будем обозначать: · W1 – событие, состоящее в том, что документ d релевантен высказыванию V; · W2 – событие, состоящее в том, что документ d не релевантен высказыванию V; · P(Wi|d) – вероятность того, что для документа d наступает событие Wi. Зная эту вероятность, можно использовать следующее правило: если P(W1|d)>P(W2|d), то документ d релевантен высказыванию V. Существуют различные способы получения этих оценок, а также дополнительные предположения и гипотезы на основе априорных сведений относительно документов коллекции, которые и определяют конкретную реализацию вероятностной модели поиска. Например, эта оценка может быть вычислена в соответствии с теоремой Байеса по некоторой функции вероятностей вхождения термов данного документа в релевантные и нерелевантные документы. Векторные и вероятностные модели, основанные на статистической информации о встречаемости терма в отдельном документе или в коллекции документов, не обеспечивают необходимой точности для идентификации сущности. Пусть согласно какому-либо методу высказывание VN получило оценку релевантности выше, чем высказывание VY (случай ошибки). Введем обозначения: Td – множество термов документа d, идентифицирующего сущность s1; TY – множество термов высказывания VY, идентифицирующего сущность s1; TN – множество термов высказывания VN, идентифицирующего сущность s2; Td ÇTYÇTN – участвующие в поиске термы, характерные для сущностей s1 и s2; TdÇTY\(TdÇTYÇTN) – участвующие в поиске термы, указывающие на верное соответствие между высказыванием VY и сущностью s1; TdÇTN\(TdÇTYÇTN) – участвующие в поиске термы, вносящие ошибку в оценку релевантности. Основные причины ошибок заключаются в следующем. 1. Между термами высказывания присутствуют функциональные зависимости, идентифицирующие сущность. Например, высказывания «принтер HP LJ1200 c картриджем С7115A» и «картридж С7115A для принтера HP LJ1200» имеют идентичные наборы термов. Предлоги «для» и «с» задают функциональные отношения между группами термов, но заведомо имеют малые значения глобального и локального веса терма. 2. Высказывание VY задано более кратко (например, использовано смешанное задание сущности), чем высказывание VN с большим количеством термов, имеющих высокую оценку. Экспериментальные данные подтверждают утверждения о причинах недостаточной точности векторных и вероятностных моделей для задачи идентификации сущности. При проведении экспериментов в коллекции D мощностью порядка 104 документов, при 279 случаях ошибок множество TdÇTY\(TdÇTYÇTN) было всегда пусто. Кроме того, был исследован режим обратной связи по релевантности, когда итеративным путем уточняется вес термов. Для каждого высказывания исходного множества (далее – обучающая выборка) было задано соответствие в коллекции D. В случае ошибки, вес термов множества TdÇTY\(TdÇTYÇTN) увеличиваем, а вес термов TdÇTN\(TdÇTYÇTN) уменьшаем. До и после уточнения весов термов проводился прогон программной системы на обучающей и тестовой выборке высказываний. В полученном ответе системы подсчитывалось число правильно найденных пар высказывание-документ. Таблица
После уточнения весов термов эффективность метода на «обучающей» выборке увеличилась (см. табл.). Увеличения эффективности на тестовой выборке зафиксировано не было. |
 невозможно задать в D из-за неопределенности (потенциальности) S.
невозможно задать в D из-за неопределенности (потенциальности) S. , где k – общее количество различных термов во всех документах.
, где k – общее количество различных термов во всех документах.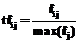 . (3)
. (3) , (4)
, (4)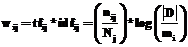 , (5)
, (5)| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=383 |
Версия для печати Выпуск в формате PDF (1.17Мб) |
| Статья опубликована в выпуске журнала № 2 за 2007 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Сравнение сложных программных систем по критерию функциональной полноты
- О выборе числа процессоров в многопроцессорной вычислительной системе
- Спецификация объектно-ориентированной модели данных с помощью отношений
- Правила построения автоматизированных информационных систем экспертной оценки и согласования
- Компьютерная технология проектирования перестраиваемых нерекурсивных фильтров
Назад, к списку статей