Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Восстановление эллипсиса как задача автоматической обработки текстов
Аннотация:Любому естественному языку присуще явление омонимии, когда одни и те же языковые знаки, помещенные в различные контексты, могут интерпретироваться по-разному. Это явление является главной причиной, обусловливающей сложность решения задач автоматического синтаксического анализа, актуальность и практическая значимость которых на сегодняшний день несомненна. Помимо омонимии, в естественных языках можно наблюдать еще одно явление, в рамках которого потенциальная неоднозначность языка проявляется не менее ярко. Речь идет об эллипсисе. Эти два явления имеют общую природу, однако омонимия изучается компьютерной лингвистикой на протяжении десятилетий, а эллипсис лишь вскользь упоминается в отдельных работах. Даже простейшие случаи эллипсиса являются в настоящее время труднопреодолимым препятствием для алгоритмов синтаксического анализа. В настоящей работе предложен подход к решению задачи автоматического синтаксического анализа, характер-ной особенностью которого является то, что корректная обработка эллиптических конструкций оказывается естественным элементом общей схемы синтаксического анализа, включающей три параллельно функционирующих механизма: предсказаний, слияний и оценочного механизма.
Abstract:Nowadays the importance of automatic syntactic analysis of natural language texts is obvious. Phenomenon of homonymy is a feature of any natural language. It is the main reason which explains complexity of the task of automatic syn-tactic analysis: the same language signs placed into different contexts can be interpreted differently. Note that in a natural languages there is one more phenomenon besides homonymy. Its potential ambiguity is shown also well. This phenomenon is ellipsis. Despite common nature of both phenomena and the fact that homonymy is studied by computer linguistics during decades, the ellipsis is mentioned in some papers only in passing. Nowadays even the simplest ellipsis cases are a hard obsta-cle for syntactic analysis algorithms. An approach to solve the problem of automatic syntactic analysis is proposed in the paper. Correct processing of elliptic constructions is a natural element of a general scheme of syntactic analysis including three parallel functioning mechanisms (mechanisms of predictions, mechanism of mergers and estimation mechanism) is the main feature of the approach.
| Авторы: Мальковский М.Г. (malk@cs.msu.su) - Московский государственный университет им. М.В. Ломоносова, Москва, Россия, доктор физико-математических наук, Миняйлов В.С. (malk@cs.msu.su) - Московский государственный университет им. М.В. Ломоносова (аспирант ), Москва, Россия, Старостин А.С. (malk@cs.msu.su) - Компания ABBYY, Москва, Россия | |
| Ключевые слова: механизм предсказаний., эллипсис, автоматический синтаксический анализ |
|
| Keywords: prediction mechanism, ellipsis, syntactic analysis |
|
| Количество просмотров: 9659 |
Версия для печати Выпуск в формате PDF (5.36Мб) Скачать обложку в формате PDF (1.03Мб) |
Актуальность и практическая значимость задачи автоматического синтаксического анализа текстов на естественном языке не вызывает сомнений. Ее часто приходится решать в рамках более крупных задач, таких как информационный поиск, извлечение информации, автоматическое реферирование, машинный перевод.
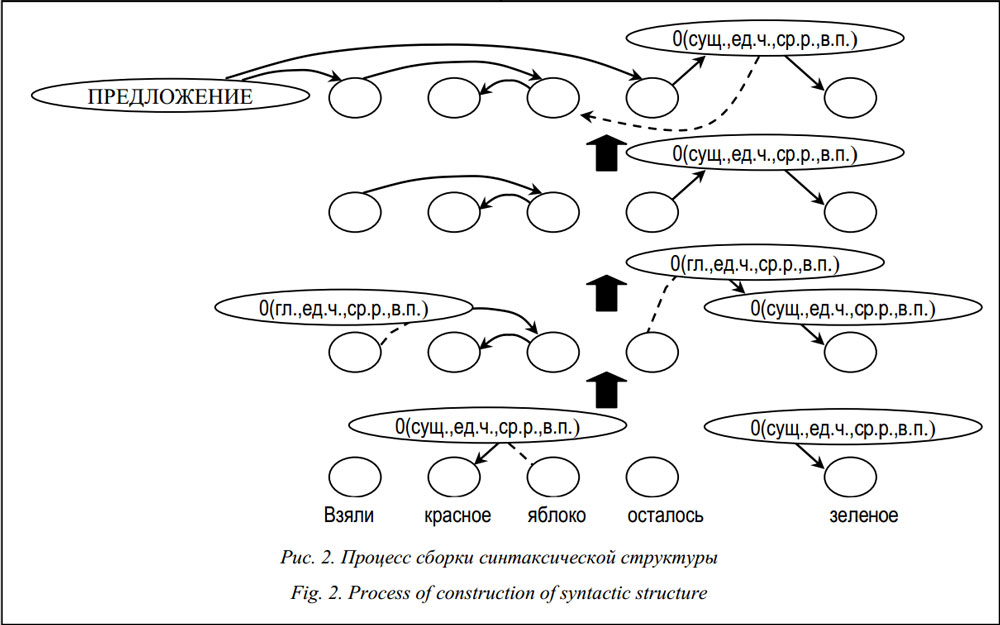
Главной причиной, обусловливающей сложность задачи автоматического синтаксического анализа, является присущее любому естественному языку явление омонимии: одни и те же языковые знаки, помещенные в различные контексты, могут интерпретироваться по-разному. В подавляющем большинстве текстов на естественном языке омонимия может быть без труда разрешена, то есть текст обычно строится так, что человек (если он является носителем соответствующего языка) способен воспринять его однозначно. Это происходит благодаря тому, что в момент восприятия каждой следующей единицы текста для разрешения неоднозначности человек способен привлекать разнообразные контексты: контекст слов текущего предложения, соседних предложений (в первую очередь для учета анафорических связей), текста в целом (например учет тематики текста), прагматический контекст (при каких условиях, в какой ситуации текст был порожден и др.). Для качественного автоматического синтаксического анализа необходимо уметь моделировать контексты всех перечисленных типов и учитывать их в процессе автоматического анализа. Заметим, что на сегодняшний день большинство синтаксических анализаторов умеют работать с контекстом только в рамках одного предложения. Лишь немногие анализаторы учитывают контексты соседних предложений и всего текста в целом (например [1]). Прагматический контекст не учитывает ни один из известных авторам синтаксических анализаторов. Способность воспринимать и динамически модифицировать систему контекстов в процессе коммуникации является, по-видимому, одной из важных составляющих языковой компетенции человека. Заметим, что в естественных языках, помимо омонимии, можно наблюдать еще одно явление, в рамках которого эта способность проявляется не менее ярко. Речь идет об эллипсисе. По определению, эллипсис – это пропуск в речи или тексте подразумеваемой языковой единицы. Естественный язык допускает пропуск слов в тех случаях, когда они могут быть восстановлены из контекста. Эллипсис широко распространен и встречается во всех известных естественных языках. В качестве примера приведем предложение «У отца был зеленый стол, а у сына синий». Здесь подразумевается, что у сына тоже был стол, но синего цвета. Итак, можно констатировать, что умение человека использовать контексты различных видов в процессе анализа текстов выражается в способности не только снимать омонимию, но и восстанавливать эллипсис. Однако, несмотря на общую природу этих двух явлений, омонимия являлась предметом изучения компьютерной лингвистики на протяжении десятилетий, а эллипсис лишь вскользь упоминается в отдельных работах. В теоретической лингвистике ситуация другая. Эллипсис достаточно хорошо изучен лингвистами [2, 3]. Даже простейшие случаи эллипсиса на сегодняшний день являются труднопреодолимым препятствием для алгоритмов синтаксического анализа. Эллипсис до сих пор рассматривается многими исследователями как нечто периферийное и незначительное (и вместе с тем, очевидно, сложное в моделировании). В данной работе предложен подход к автоматическому анализу естественного языка, в рамках которого разрешение омонимии и восстановление эллипсиса оказываются двумя сходными аспектами одного и того же процесса, выполняемого тремя взаимодействующими механизмами: механизмом предсказаний, механизмом слияний и оценочным механизмом. Все описанные механизмы функционируют в рамках алгоритма взвешенного chart parsing, основанного на идеях из [4]. Программная разработка предложенного подхода ведется в рамках исследовательской среды Treeton [5, 6]. Особенности предлагаемого подхода Для корректного описания эллипсиса при синтаксическом анализе необходимо допустить использование в дереве синтаксического анализа вершин специального типа. Эти вершины вир- туальны, в отличие от остальных вершин они не соотнесены явным образом со словами анализируемого предложения. Будем называть такие вершины нулевыми [6]. На рисунке 1 представлен пример синтаксического разбора предложения «У отца был зеленый стол, а у сына синий», который содержит нулевые вершины. В ряде работ по синтаксическому анализу понятие нулевого узла не используется. При работе с деревьями зависимостей строятся деревья, все узлы которых являются словами исходных предложений. Для систем составляющих аналогично принимается, что листовыми вершинами деревьев разбора могут быть только слова исходных предложений. Даже в тех случаях, когда системы синтаксического анализа способны работать с ну- левыми узлами, их порождение обычно осуществляется при помощи специальных механизмов, отделенных от основного механизма анализа (например [1]). Далее предлагается схема синтаксического анализа, базовые принципы которой обеспечивают корректную обработку эллиптических конструкций без использования дополнительных механизмов. В основе этой схемы лежит идея того, что в каждом анализируемом слове, даже без учета контекста окружающих слов, заложено много информации (ср. [7]). В качестве примера рассмотрим предложение «Взяли красное яблоко, осталось зеленое». · Слово «взяли» является глаголом. Оно может быть главным словом в некотором предложении: корнем дерева разбора или вершиной сочинительной клаузы. · Слово «красное» является прилагательным. Оно сочетается с управляющим существительным в именительном или винительном падеже (второй вариант соответствует рассматриваемому предложению). · Слово «яблоко» является существительным. Для него можно предположить наличие управляющего глагола (именно такой вариант соответствует рассматриваемому предложению). Кроме того, для этого существительного можно предположить, например, управляющий предлог (ср. «в яблоко»). · Слово «осталось» по характеристикам аналогично слову «взяли». · Слово «зеленое» по характеристикам аналогично слову «красное». Таким образом, просто по слову можно построить набор гипотез о свойствах слов, с которыми оно может быть синтаксически связано. Важно, что для построения гипотез не требуется наличие соответствующих им слов в исходном предложении. Заметим, что в ряде случаев гипотезы могут строиться на основе более чем одного слова. Например, для слова «яблока» по умолчанию не имеет смысла предполагать, что оно является дополнением при некотором глаголе (так как родительный падеж). Однако, если это слово модифицируется словом «два», такая гипотеза становится возможной. Сравним: «передал яблока» и «передал два яблока». Предлагаемая схема содержит специальный механизм предсказаний, с помощью которого можно строить предположения о синтаксической сочетаемости единиц входного предложения. Этот механизм дополняет уже построенные синтаксические структуры нулевыми вершинами и фиксирует некоторые характеристики этих узлов (грамматические признаки и согласования с другими элементами). В результате получаются новые синтаксические структуры с нулевыми вершинами. Знания о синтаксической сочетаемости фиксируются в системе в виде правил на формальном языке. Вторым механизмом предлагаемой схемы является механизм слияний. С помощью этого механизма синтаксические структуры, в которых есть нулевые вершины, могут соединяться с другими синтаксическими структурами. Соединяются всегда две структуры. Нулевые вершины одной структуры отождествляются с вершинами другой (воспринимаются как одно и то же). В процессе отождествления вершин механизм слияний контролирует то, что в результате слияния получается древесная структура (защита от циклов). Отождествление вершин возможно только в тех случаях, когда их грамматические признаки не противоречат друг другу. На рисунке 2 показан процесс сборки синтаксической структуры в виде последовательности предсказаний и слияний.
Синтаксические связи обозначены сплошными стрелками. Вершины, участвующие в слияниях, связаны пунктирными линиями без стрелок. Связь, оправдывающая нулевую вершину, обозначена пунктирной стрелкой. Заметим, что алгоритм слияний допускает построение непроективных конструкций. Параллельно с механизмами предсказаний и слияний функционирует еще один – механизм штрафов (или оценочный механизм). С его помощью каждой промежуточной структуре сопоставляется вектор вещественных чисел, называемый штрафным вектором. Норма такого вектора характеризует качество синтаксической структуры. Чем ближе ее значение к нулю, тем лучше (правдоподобнее) синтаксическая структура. Различные компоненты штрафного вектора соответствуют различным типам лингвистических явлений, наблюдаемых в синтаксических структурах и позволяющих делать выводы об их правдоподобности. К таким явлениям относятся, например, степень непроективности (количество пересекающихся стрелок в дереве) или наличие повторений связей, которые считаются неповторимыми. Основной набор лингвистических явлений, учитываемых при оценке синтаксических структур, взят из [5]. Для работы со структурами, включающими нулевые элементы, данный набор был расширен. Расширение нужно для обработки эллиптических конструкций. В результате действия механизма предсказаний получаются эллиптические конструкции, которые нужно разделять за счет штрафов на более правдоподобные и менее правдоподобные. Таким образом, предложенный алгоритм обрабатывает эллипсис естественным образом. >В заключение необходимо отметить, что в работе предложен подход к решению задачи синтаксического анализа. Характерная особенность подхода в том, что корректная обработка эллиптических конструкций не реализуется за счет стоящих особняком специальных механизмов, она является естественным элементом общей схемы синтаксического анализа, включающей три параллельно функционирующих механизма: механизм предсказаний, механизм слияний и оценочный механизм. На данный момент имеется базовая реализация предложенного подхода. Используются небольшой набор правил предсказаний и упрощенный механизм штрафов. В ближайшем будущем планируется развить предлагаемый подход, повысить эффективность созданного алгоритма, а также провести масштабное тестирование алгоритма на размеченном корпусе. Литература 1. Anisimovich K.V., Druzhkin K.Yu., Minlos F.R., Petro- va M.A., Selegey V.P., Zuev K.A. Syntactic and semantic parser based on ABBYY Compreno linguistic technologies // Компьютерная лингвистика и интеллектуальные технологии: по матер. ежегод. Междунар. конф. «Диалог» (Бекасово, 30 мая–3 июня 2012 г.) (докл. спец. секций). М.: Изд-во РГГУ, 2012. Вып. 11 (18). Т. 2. C. 91–103. 2. Адамец П. Семантическая интерпретация «значимых нулей» в русских предложениях // Язык и стих в России: сб. в честь Дина С. Ворта к его 65-летию. М.: Вост. лит-ра РАН, 1995. С. 9–18. 3. Вардуль И.Ф. К вопросу о явлении эллипсиса // Инвариантные синтаксические значения и структура предложения. М.: Наука, 1969. С. 59–70. 4. Eisner J. Bilexical Grammars and a Cubic-time Probabilistic Parser. Proc. 5th Intern. Workshop on Parsing Technologies, Cambridge, MA, September 1997. URL: ftp://ftp.cis.upenn.edu/ pub/jeisner/papers/eisner.iwpt97.pdf (дата обращения: 25.03.2014). 5. Мальковский М.Г., Старостин А.С. Система морфо-синтаксического анализа Treeton и мультиагентный синтаксический анализатор Treevial: принцип работы, система правил и штрафов // Интернет-математика 2007: сб. работ участников конкурса науч. проектов по информ. поиску. Екатеринбург: Изд-во Урал. ун-та, 2007. С. 135–143. 6. Мальковский М.Г., Старостин А.С. Система Treeton: анализ под управлением штрафной функции // Программные продукты и системы. 2009. № 1. С. 33–35. 7. Пинкер С. Язык как инстинкт; [пер. с англ.; общ. ред. В.Д. Мазо]. М.: Едиториал УРСС, 2004. 456 с. References 1. Anisimovich K.V., Druzhkin K.Yu., Minlos F.R., Petrova M.A., Selegey V.P., Zuev K.A. Syntactic and semantic parser based on ABBYY Compreno linguistic technologies. Kompyuternaya lingvistika i intellektualnye tekhnologii: po materialam ezhegodnoy Mezhdunar. konf. “Dialog” [Computer linguistics and intelligent technologies: proc. of annual int. conf. “Dialog”]. 2012, iss. 11 (18), vol. 2, Moscow, Russian State Univ. for the Humanities Publ., 2012, pp. 91–103 (in Russ.). 2. Adamec P. Semantic interpretation of “valuable zeros” in russian sentences. Yazyk i stikh v Rossii: sb. v chest Dina S. Vorta k ego 65-letiyu [Russian language and poem: miscellany in honour of 65th anniversary Din S. Vort]. Moscow, Vost. lit-ra RAN Publ., 1995, pp. 9–18 (in Russ.). 3. Vardul I.F. On ellipsis phenomenon. Invariantnye sintaksicheskie znacheniya i struktura predlozheniya [Invariant syntactic meaning and sentence structure]. Moscow, Nauka Publ., 1969, pp. 59–70 (in Russ.). 4. Eisner J. Bilexical grammars and a cubic-time probabilistic parser. Proc. of 5th Int. Workshop on Parsing Technologies. Cambridge, MA, 1997. Available at: ftp://ftp.cis.upenn.edu/pub/jeisner/ papers/eisner.iwpt97.pdf (accessed March 25, 2014). 5. Malkovskiy M.G., Starostin A.S. Treeton system of morphosyntactical analysis and Treevial multiagent syntactical detector: operation principle, system of rules and penalties. Internet-matematika 2007: sb. rabot uchastnikov konkursa nauch. proektov po inform. poisku [Internet-mathematics 2007: polygraph of information search scientific projects competition participants]. Ekaterinburg, Ural Uviv. Publ., 2007, pp. 135–143. 6. Malkovskiy M.G., Starostin A.S. Treeton system: penalty function based analysis. Programmnye produkty i sistemy [Software & Systems]. 2009, no. 1, pp. 33–35 (in Russ.). 7. Pinker S. The Language Instinct. New York, Harper Perennial Modern Classics Publ., 1994 (Russ. ed.: Mazo V.D. Yazyk kak instinct. Moscow, Editorial URSS Publ., 2004, 456 p.). |

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3855 |
Версия для печати Выпуск в формате PDF (5.36Мб) Скачать обложку в формате PDF (1.03Мб) |
| Статья опубликована в выпуске журнала № 3 за 2014 год. [ на стр. 32-36 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: