Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Комплекс программ для индуктивного формирования баз медицинских знаний
Аннотация:В статье представлено описание комплекса программ InForMedKB (Inductive Formation of Medical Knowledge Bases), позволяющего создавать обучающие выборки (состоящие из историй болезни различных разделов медицины) и на их основе (в форме, принятой в медицинской литературе) индуктивно формировать базы медицинских знаний, содержащие описания заболеваний, а также объяснение этих баз знаний. В разработанном комплексе реализован алгоритм обучения (решающий задачи классификации и кластеризации в их новых постановках, представленных как частный случай задачи оценки значений параметров модели зависимости, которая обусловливает качество разработанного для нее алгоритма обучения) для практически полезной и хорошо интерпретируемой математической модели зависимости с параметрами, являющейся онтологией медицинской диагностики, приближенной к реальной (заданной системой логических соотношений с параметрами). Этот алгоритм по обучающей выборке находит значения параметров (базу медицинских знаний) указанной модели, близкие к значениям, характеризующим предметную область медицинской диагностики. При помощи данного комплекса на основе обучающей выборки реальных данных, содержащей истории болезни из раздела медицины «острый живот», индуктивно сформирована база медицинских знаний, обладающая высоким уровнем интерпретируемости для практикующего врача. Входящие в полученную базу знаний описания заболеваний, по оценке эксперта, соответствуют знаниям, имеющимся в научной и учебной медицинской литературе, а в ряде случаев дополняют их описанием динамики клинических проявлений. Формальное представление баз медицинских знаний, получаемых при помощи разработанного комплекса, позволяет использовать их в экспертных системах медицинской диагностики.
Abstract:The article provides the description of InForMedKB (Inductive Formation of Medical Knowledge Bases) software package.It allows creating training sets (consisting of clinical histories from various branches of medicine) and forming medical knowledge bases inductivly. These knowledge bases are presented in the form accepted in the medical literature and contain descriptions of diseases (from specified branches of medicine), as well as explanations of these knowledge bases. The developed software package implements training algorithm which solves classification and clustering problems in their new definitions w hich are presented as a special case for problem of estimating the parameters of a reliability model that affects the quality of the training algorithm. This learning algorithm is developed for the useful and easily interpretable mathematical reliability model with parameters. It is a near real-life ontology of medical diagnostics (defined by a system of logical relationships with parameters). Presented algorithm finds parameter values for given model (medical knowledge base), which are close to the values that characterize the object domain of medical diagnostics. Using this software package and real data training set (containing clinical histories from "Acute abdomen" branch of medicine), a medical knowledge base is inductively formed. It has a high level of interpretability for a practicing physician. Descriptions of diseases included in the inductively formed knowledge base (expert evaluation) correspond to knowledge from scientific and academic medical literature. And sometimes they add descriptions of clinical implications dynamics. The formal representation of medical knowledge bases obtained using the software package allows using them in medical diagnostics expert systems.
| Авторы: Смагин С.В. (sergey.v.smagin@gmail.com) - Институт автоматики и процессов управления ДВО РАН, Владивосток, Россия, кандидат технических наук | |
| Ключевые слова: интеллектуальный анализ данных, машинное обучение, индуктивное формирование баз знаний, онтология медицинской диагностики, модель зависимости с параметрами, алгоритм обучения |
|
| Keywords: data intelligent analysis, machine learning, inductive formation of knowledge bases, medical diagnostics ontology, reliability model with parameters, learning algorithm |
|
| Количество просмотров: 8585 |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
Индуктивное формирование баз знаний (БЗ) на основе эмпирических данных является основным способом получения новых эмпирических знаний. Этот способ заключается в получении общего знания о некоторой совокупности объектов на основании анализа единообразного описания конечного множества отдельных представителей этой совокупности – обучающей выборки (данных). Моделирование такого способа познания лежит в основе многих направлений исследований, получивших в англоязычной литературе названия: Data Mining (интеллектуальный анализ данных), Machine Learning (машинное обучение), Knowledge Discovery in Databases (обнаружение знаний в БД), Pattern Recognition (распознавание образов), Knowledge Extraction (извлечение знаний), Information Discovery (обнаружение информации), Information Harvesting (сбор информации), Data Archaeology (археология данных) и т.д., каждое из которых характеризуется собственным подходом к проблеме индуктивного формирования БЗ, собственными постановками задач и многообразием методов их решения. В основополагающих публикациях по данной тематике сформулированы общие постановки основных задач индуктивного формирования БЗ (задач классификации и кластеризации), изучены разнообразные модели зависимости между классами и объектами, а также разработано большое число алгоритмов обучения (классификации и кластеризации), решающих поставленные задачи на этих моделях [1–3].
В традиционной постановке задачи классификации дано конечное множество объектов (образов, ситуаций, прецедентов), называемое обучающей выборкой, по каждому из которых собраны (измерены) некоторые данные. Данные об объекте называют также его описанием, при этом наиболее распространенным способом описания объектов является признаковое описание. Также дано конечное множество возможных классов (ответов, откликов, реакций). Предполагается, что существует некоторая зависимость между классами и объектами, но она неизвестна, а также то, что для каждого объекта обучающей выборки задан его (единственный) правильный класс. При этом описание объектов обучающей выборки в той или иной степени отражает эту зависимость [4]. На основе этой информации требуется для некото- рого класса моделей зависимости (класса моде- лей некоторой предметной области), к которому относится эта неизвестная зависимость (между классами и объектами), разработать алгоритм классификации, по обучающей выборке строящий решающее правило, вероятность правильной классификации которым любых новых объектов является как можно более высокой [2]. Традиционные постановки задач классификации (относящейся к типу «Обучение с учителем») и кластеризации (относящейся к типу «Обучение без учителя») отличаются тем, что в последней разбиение множества объектов на классы не- известно и поэтому для объектов обучающей выборки правильные классы не могут быть заданы. Задача кластеризации заключается в разбиении обучающей выборки на непересекающиеся подмножества (называемые кластерами) таким образом, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались (при этом также строятся описания кластеров, позволяющие относить к ним любые новые объекты [1, 2]. Проблема интерпретируемости индуктивно сформированных БЗ Как отметил Д. Мики, автоматически (индуктивно) сформированные БЗ (описания классов или кластеров) могут быть использованы в интеллектуальных системах только тогда, когда они понятны экспертам соответствующих предметных областей [5]. В этом случае эксперты смогут не только сами пользоваться такими БЗ в своей профессиональной деятельности, но и будут доверять экспертным системам, использующим модели этих знаний, а также смогут проверять выводы таких систем, сформированные подсистемами объяснений [6]. Проведенный анализ показывает, что степень интерпретируемости описаний классов и кластеров, которые формируют существующие алгоритмы обучения (решающие задачи классификации и кластеризации в их традиционных постановках) для практически полезных предметных областей, не позволяет экспертам предметных областей использовать эти описания в своей практической деятельности. В работе [7] рассмотрен класс моделей зависимости, имеющих вид необогащенных систем логических соотношений с параметрами. Если система логических соотношений – это реальная онтология предметной области, полученная как результат формализации представлений экспертов о ней (то есть взята из практики), то модель зависимости является хорошо интерпретируемой. В этой модели описание классов или кластеров (которое формирует алгоритм обучения) представляет собой набор значений параметров, названный БЗ. Такое описание хорошо интерпретируемо по построению, что является важным достоинством подобных моделей зависимости. При этом неявно предполагается, что существуют объективные значения параметров (БЗ), характеризующие предметную область. Описание объектов для таких моделей зависимости имеет внутреннюю логическую структуру, одна часть которой известна (включает в себя значения наблюдаемых неизвестных и неинтересных параметров), другая – нет (включает в себя значения ненаблюдаемых неизвестных и интересных параметров) [6]. Цель алгоритма обучения для таких моделей зависимости – найти значения интересных параметров, которые вместе со значениями неинтересных параметров образуют БЗ. Из этого следует, что качество алгоритма обучения зависит от выбранной модели зависимости. Однако среди предлагаемых в литературе постановок задач классификации и кластеризации [1–3, 8–10] не рассматриваются их специфические постановки для моделей зависимости с параметрами, которые требуют от алгоритмов обучения (классификации или кластеризации) формирования описаний (соответственно классов или кластеров), обладающих определенным уровнем качества. Поэтому актуальной проблемой является разработка алгоритмов обучения для практически полезных, хорошо интерпретируемых и адекватных математических моделей зависимости с параметрами, являющихся реальными онтологиями важных предметных областей и формирующих такие описания классов или кластеров (наборы значений параметров этих моделей зависимости, то есть БЗ), которые эксперты этих предметных областей оценивают как достаточные для решения в них практических задач. Новые постановки основных задач индуктивного формирования БЗ и решающий их алгоритм обучения В работе [11] предложены новые постановки основных задач индуктивного формирования БЗ (классификации и кластеризации) для моделей зависимости, имеющих вид необогащенных систем логических соотношений с параметрами [7]. Эти постановки лишены недостатков традиционных постановок и представлены как частный случай задачи оценки значений параметров модели зависимости. При этом критерием качества обучения является близость получаемых оценок значений параметров к значениям, характеризующим предметную область, а не традиционно используемая вероятность правильной классификации решающим правилом, получаемым в результате обучения, и не качество используемой метрики. Также в [11] представлен алгоритм обучения (алгоритм индуктивного формирования баз медицинских знаний (БМЗ), решающий задачи классификации и кластеризации в их новых постановках) для практически полезной, хорошо интерпретируемой и адекватной математической модели зависимости, являющейся онтологией медицинской диагностики, приближенной к реальной. Эта модель является важным частным случаем онтологии, опубликованной в работе [12]. БМЗ – это совокупность описаний клинических проявлений заболеваний, являвшихся диагнозами в историях болезни (ИБ), входящих в обучающую выборку, на основе которой эта БЗ была сформирована. В [11] приведены результаты экспериментального исследования (в рамках общего для таких исследований подхода, описанного в работе [13], и по той же схеме, что в работе [14]) свойств разработанного алгоритма на наборах модельных данных. Этот алгоритм в первую очередь ориентирован на обработку ИБ с диагнозами тех заболеваний, признаки которых обладают динамикой (значения признаков изменяются во времени). Описание клинических проявлений таких заболеваний наиболее трудоемко и сложно с точки зрения экспертов, а потому наиболее востребовано. Условием применимости алгоритма является хорошая обследованность ИБ, входящих в обучающую выборку. Если обучающая выборка содержит также и плохо обследованные ИБ, качество индуктивно сформированной БМЗ (качество описаний клинических проявлений заболеваний) зависит исключительно от доли хорошо обследованных ИБ в этой обучающей выборке. В экспериментах на модельных данных [11, 14] обычно имеется возможность генерации выборок, удовлетворяющих данному условию. Но для обучающих выборок реальных данных оно может не соблюдаться, поэтому перед работой алгоритма такая выборка при помощи эксперта должна быть разделена на две части – на хорошо и плохо обследованные ИБ. В качестве входных данных алгоритма должна быть использована только первая ее часть, а для ИБ из второй части (после формирования БМЗ) предпринята попытка отнесения их к одному из сформированных описаний клинических проявлений заболеваний. Не отнесенные ни к одному описанию ИБ ввиду их неинформативности следует удалить из обучающей выборки.
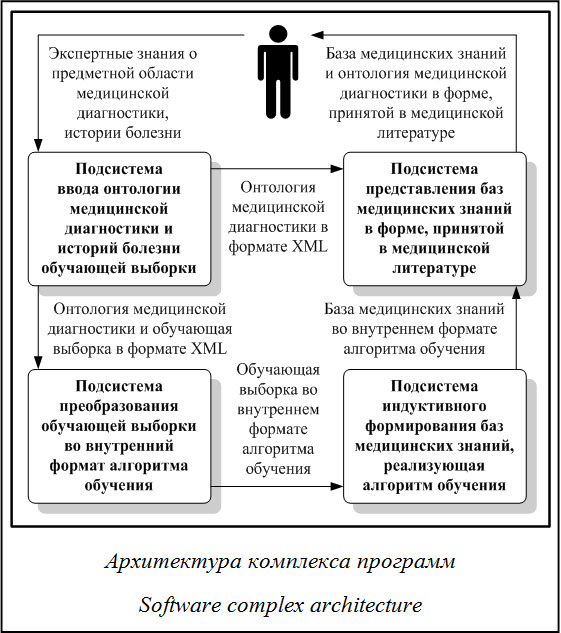
Функциональное описание комплекса программ В настоящей работе представлено описание комплекса программ InForMedKB v1.1 (INductive FORmation of MEDical Knowledge Bases), позволяющего создавать обучающие выборки (состоящие из ИБ различных разделов медицины) и на их основе в форме, принятой в медицинской литературе, индуктивно формировать БМЗ высокого уровня интерпретируемости и такого уровня качества, который эксперты предметной области медицинской диагностики оценивают как достаточный для решения практических задач, а также формировать объяснения этих БЗ на основе информации из используемых обучающих выборок. Комплекс программ InForMedKB предназначен для решения следующих задач: – создание онтологии (модели зависимости, заданной системой логических соотношений с параметрами) медицинской диагностики в структурной форме с возможностью представления этой онтологии в виде, удобном для использования ее в качестве медицинского стандарта; – создание обучающей выборки, состоящей из сформированных на основе онтологии медицинской диагностики ИБ по набору заболеваний некоторого раздела медицины (для каждого заболевания формируется своя обучающая выборка как часть целого); – формирование подвыборки обучающей выборки в зависимости от ряда критериев отбора ИБ, которые могут быть числовыми, логическими, перечислимыми; – индуктивное формирование на основе алгоритма обучения из [11] БМЗ (которая представляет собой совокупность описаний клинических проявлений заболеваний, сформированных на основе соответствующих этому заболеванию обучающих выборок) в структурной форме, а также формирование объяснения этой БЗ (на основе информации из тех же обучающих выборок); – преобразование сформированной БЗ в форму, принятую в медицинской литературе и понятную практикующему врачу. Структура комплекса программ и технология его применения Комплекс программ InForMedKB включает в себя следующие подсистемы (см. рис.): подсистему ввода онтологии медицинской диагностики и ИБ обучающей выборки; подсистему преобразования обучающей выборки во внутренний формат алгоритма обучения; подсистему индуктивного формирования БМЗ, реализующую алгоритм обучения; подсистему представления БМЗ в форме, принятой в медицинской литературе. Подсистема ввода онтологии медицинской диагностики и ИБ обучающей выборки представляет собой структурный редактор информации и используется в комплексе программ в качестве сторонней компоненты (описание подсистемы дано в работе [15]). Онтология медицинской диагностики, приближенная к реальной, является формализацией экспертных знаний о предметной области медицинской диагностики и содержит следующие разделы: дата поступления пациента, анатомо-физиологические особенности, диагноз, история настоящего заболевания, жалобы, данные объективного обследования, лабораторные и инструментальные методы исследования, сопутствующие заболевания. Каждый раздел, кроме даты поступления и диагноза, содержит структурированный набор признаков числового (может быть целочисленным или вещественным интервалом), логического или перечислимого типа. В случае последних двух типов для признака также указывается набор его возможных значений. Структура и внутренний формат онтологии и ИБ совпадают. Различие их в том, что онтология содержит типы, интервалы и нумерованные наборы возможных значений признаков, а в ИБ указываются их номера или конкретные значения (в случае числовых значений – конкретное число или интервал, логических значений – номер одного из них, перечислимых значений – номера возможных значений из онтологии). Набор ИБ, введенный при помощи данной подсистемы, образует обучающую выборку (то есть совокупность обучающих выборок для каждого заболевания), все ИБ которой представлены в формате XML. Подсистема преобразования обучающей выборки во внутренний формат алгоритма обучения из [11], используя онтологию медицинской диагностики, приближенную к реальной, преобразует обучающую выборку во внутренний формат этого алгоритма. Ввиду того, что в данной онтологии признаки считаются независимыми и в любой момент наблюдения любой признак имеет единственное значение, обрабатываются они также не- зависимо. Поэтому каждая обучающая выборка, содержащая ИБ по конкретному заболеванию, реорганизуется в набор описаний тех признаков, которые наблюдались в ее ИБ. Описание каждого признака содержит его внутренний номер, количество ИБ, в которых он хотя бы единожды наблюдался, общее количество моментов наблюдения признака (суммарное количество по всем ИБ, где он наблюдался), а также таблицу со столбцами: номер ИБ, момент наблюдения признака (количество часов с момента начала заболевания), значение признака в момент наблюдения. После преобразования обучающей выборки может быть сформирована подвыборка, удовлетворяющая или не удовлетворяющая ряду критериев отбора ИБ, которые могут быть числовыми (диапазон возрастов пациентов), логическими (пол пациентов) или перечислимыми (набор анатомо-физиологических особенностей пациентов). На основе таких подвыборок возможно формирование специализированных БМЗ, учитывающих особенности конкретных групп пациентов. Подсистема индуктивного формирования БМЗ, реализующая алгоритм обучения из [11], на основе обучающей выборки (совокупности обучающих выборок для каждого заболевания) во внутреннем формате алгоритма обучения индуктивно формирует описания клинических проявлений соответствующих заболеваний. Их совокупность образует БМЗ в структурной форме, которая имеет следующий формат. Для каждого заболевания существует набор признаков, входящих в его клиническую картину. Это означает, что каждый из таких признаков хотя бы в одном из своих периодов динамики имеет хотя бы одно значение, отличное от нормы. Описания заболеваний, входящих в БМЗ, состоят из описаний клинических проявлений признаков, входящих в клинические картины этих заболеваний. В таком описании для каждого признака указываются количество ИБ, в которых он наблюдался, число вариантов его клинического проявления (ВКП), а также описание этих вариантов. ВКП соответствует типу реакций организма на данное заболевание по данному признаку. Описание ВКП содержит информацию о числе периодов динамики в нем, о значениях признака в этих периодах и о границах длительности этих периодов. При этом для каждого ВКП формируется его объяснение: указываются количество поддерживающих его ИБ, в которых этот ВКП проявился, а также номера ИБ, входящих в определяющее подмножество данного ВКП (исключение этих ИБ из обучающей выборки не позволит сформировать данный ВКП). Совокупность объяснений всех сформированных ВКП образует объяснение заболевания. Совокупность объяснений всех заболеваний образует объяснение БМЗ. Также описание может включать дополнительную информацию об ИБ обучающей выборки (если эта информация содержится в ней): количество часов, прошедших с момента начала заболевания до поступления пациента в клинику, была ли проведена операция (и, если да, то через сколько часов после поступления), а также количество дней, проведенных пациентом в клинике. Подсистема представления БМЗ в форме, принятой в медицинской литературе, осуществляет преобразование БЗ, сформированной предыдущей подсистемой, на основе грамматики преобразования БЗ из внутреннего формата алгоритма обучения в форму, принятую в медицинской литературе. При этом формальное представление БМЗ позволяет конвертировать его в любой формат, необходимый для использования в экспертных системах медицинской диагностики. Предлагаемая грамматика преобразования, созданная на основе анализа принятых в медицинской литературе описаний заболеваний, может быть изменена непосредственно в комплексе программ или же задана внешним файлом, что позволяет гибко настраивать вид результата для различных групп пользователей. Преобразованная БМЗ, а также используемая при ее формировании онтология медицинской диагностики сохраняются в формате MS Word. Пример применения комплекса программ и экспертное заключение по сформированной БМЗ На основе обучающей выборки реальных данных индуктивно сформирована при помощи разработанного комплекса программ InForMedKB БМЗ, получившая в работе экспертную оценку. Использованная обучающая выборка содержит 69 хорошо обследованных ИБ заболеваний из раздела медицины «острый живот»: аппендицит (22, все с операциями), холецистит (17, из них 8 с операциями), панкреатит (16, все без операций), перфоративная язва желудка (14, все с операциями). Представим два примера описания клинических проявлений заболеваний по наиболее важным признакам из сформированной БМЗ. Пример 1. Фрагмент описания клинического проявления «Боли в животе (локализация)» при аппендиците. Количество историй болезни, в которых наблюдался признак, равно 22. Число вариантов динамики равно 9. 1-й вариант: число периодов динамики = 2: – эпигастральная область, затем через 5–7 часов – правая подвздошная область. Вариант поддерживают истории болезни количеством 6. Номера историй болезни, входящих в определяющее подмножество варианта: 5, 18. 2-й вариант: число периодов динамики = 1: – правая подвздошная область. Вариант поддерживают истории болезни количеством 3. Номера историй болезни, входящих в определяющее подмножество варианта: 2, 3, 6. 3-й вариант: число периодов динамики = 2: – весь живот, затем через 3–12 часов – правая подвздошная область. Вариант поддерживают истории болезни количеством 6. Номера историй болезни, входящих в определяющее подмножество варианта: 7, 20. Пример 2. Описание клинического проявления «Анализ крови (скорость оседания эритроцитов)» при холецистите. Количество историй болезни, в которых наблюдался признак, равно 12. Число вариантов динамики равно 3. 1-й вариант: число периодов динамики = 1: – значительно ускорена (21–50). Вариант поддерживают истории болезни количеством 5. Номера историй болезни, входящих в определяющее подмножество варианта: 1, 2, 3, 9, 10. 2-й вариант: число периодов динамики = 2: – ускорена (15–20), затем через 5–6 суток – норма (2–10 (м), 3–15 (ж)). Вариант поддерживают истории болезни количеством 1. Номера историй болезни, входящих в определяющее подмножество варианта: 4. 3-й вариант: число периодов динамики = 1: – норма (2–10 (м), 3–15 (ж)). Вариант поддерживают истории болезни количеством 6. Номера историй болезни, входящих в определяющее подмножество варианта: 5, 12, 13, 14, 15, 17. По мнению эксперта, индуктивно сформированная БМЗ представлена в форме, понятной практикующему врачу, так, как зачастую (причем с некоторыми упрощениями) она бывает представлена в медицинской литературе. При этом полученные описания заболеваний соответствуют знаниям, имеющимся в научной и учебной медицинской литературе, а в ряде случаев дополняют их описанием динамики клинических проявлений. При этом полученные описания заболеваний подтверждены (и объяснены) реальными ИБ из обучающей выборки. Кроме того, формальное представление БМЗ, формируемых комплексом программ InForMedKB, позволяет использовать их в экспертных системах медицинской диагностики. По мнению эксперта, ввиду высокой степени интерпретируемости полученных в работе описаний заболеваний сформированная БЗ может быть использована при обучении студентов медицинских вузов, а в случае обработки обучающей выборки большого объема (десятки тысяч ИБ), состоящей из хорошо обследованных ИБ, индуктивно сформированная на ее основе БМЗ может быть использована и врачами в их профессиональной деятельности. Литература 1. Вагин В.Н., Головина Е.Ю., Загорянская А.А., Фоми- на М.В. Достоверный и правдоподобный вывод в интеллектуальных системах. М.: Физматлит, 2004. 704 с. 2. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. Н.: Изд-во Ин-та математики, 1999. 270 с. 3. Ryszard S. Michalski, Kenneth A. Kaufman. Data Mining and Knowledge Discovery: A Review of Issues and a Multistrategy Approach. Machine learning and Data mining: Methods and applications, 1997, pp. 71–112. 4. Лбов Г.С., Бериков В.Б. Устойчивость решающих функций в задачах распознавания образов и анализа разнотипной информации. Н.: Изд-во Ин-та математики, 2005. 218 с. 5. Michie D. Expert Systems. The Computer Journ., 1980, vol. 23, no. 4, pp. 369–376. 6. Клещев А.С. Задачи индуктивного формирования знаний в терминах непримитивных онтологий предметных областей // Научно-техническая информация. Сер. 2. М.: Изд-во ВИНИТИ РАН, 2003. № 8. С. 8–18. 7. Клещев А.С., Артемьева И.Л. Необогащенные системы логических соотношений. В 2-х ч. // Научно-техническая информация. Сер. 2. М.: Изд-во ВИНИТИ РАН, 2000. № 7. С. 18–28; № 8. С. 8–18. 8. Финн В.К. О роли машинного обучения в интеллектуальных системах // Научно-техническая информация. Сер. 2. М.: Изд-во ВИНИТИ РАН, 1999. № 12. С. 1–3. 9. Витяев Е.Е. Извлечение знаний из данных. Компьютерное познание. Модели когнитивных процессов: моногр. Н.: Изд-во Новосиб. гос. ун-та, 2006. 293 с. 10. Профессиональный информационно-аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных. URL: http://machinelearning.ru/ (дата обращения: 20.10.2013). 11. Клещев А.С., Смагин С.В. Задачи индуктивного формирования знаний для онтологии медицинской диагностики // Научно-техническая информация. Сер. 2. М.: Изд-во ВИНИТИ РАН, 2012. № 1. С. 9–21. 12. Клещев А.С., Черняховская М.Ю., Москаленко Ф.М. Модель онтологии предметной области «Медицинская диагно- стика». В 2-х ч. // Научно-техническая информация. Сер. 2. М.: Изд-во ВИНИТИ РАН, 2005. № 12; 2006. № 2. 13. Клещев А.С., Смагин С.В. Общий подход к проведению компьютерных экспериментов по индуктивному формированию знаний // Программные продукты и системы. 2008. № 1. С. 56–58. 14. Клещев А.С., Смагин С.В. О роли внешних и внутренних оценок свойств методов индуктивного формирования знаний // Научно-техническая информация. Сер. 2. М.: Изд-во ВИНИТИ РАН, 2011. № 4. С. 22–35. 15. Грибова В.В., Тарасов А.В., Черняховская М.Ю. Система интеллектуальной поддержки обследования больных, управляемая онтологией // Программные продукты и системы. 2007. № 2. С. 49–51. References |
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3906&lang= |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
| Статья опубликована в выпуске журнала № 4 за 2014 год. [ на стр. 108-113 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка модификации метода опорных векторов для решения задачи классификации с ограничениями на предметную область
- Применение машинного обучения для прогнозирования времени выполнения суперкомпьютерных заданий
- Выделение областей интереса на основе классификации изолиний
- Моделирование поведения интеллектуальных агентов на основе методов машинного обучения в моделях конкуренции
- Рекомендательная система на основе интеллектуального анализа наукометрического профиля исследователя
Назад, к списку статей