Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Система автоматического извлечения информативных признаков для распознавания эмоций человека в речевой коммуникации
Аннотация:В процессе человеко-машинной коммуникации возникает ряд задач, связанных с обработкой голосовых сигналов. Помимо распознавания речи говорящего, актуальными остаются идентификация личности, пола, возраста пользователя диалоговой системы, а также его эмоционального состояния. При этом число акустических характеристик, которые могут быть извлечены в ходе анализа звуковой записи, достигает сотен или даже тысяч: атрибуты могут коррелировать друг с другом, содержать зашумленные данные или иметь низкий уровень вариации, что снижает точность работы привлекаемых классификаторов. Поэтому важной задачей является автоматический отбор информативных признаков, используемых алгоритмами распознавания. В рамках данной статьи рассматриваются два подхода, основанные на использовании адаптивного многокритериального генетического алгоритма, настройка пара-метров которого осуществляется автоматически в ходе решения задачи. Выбор данной эвристической процедуры для оптимизации критериев качества обусловлен простотой кодирования информативной подсистемы признаков, а также возможностью оптимизации как дискретных, так и непрерывных критериев. Вероятностная нейронная сеть используется в качестве классификационной модели. Исследование эффективности разрабатываемых подходов проводилось на множестве задач распознавания эмоций человека: БД содержали голосовые записи на английском и немецком языках. В ходе тестирования было установлено, что на указанном множестве задач применение описанной процедуры извлечения информативных признаков приводит к повышению точности результатов (относительное улучшение до 22,7 %), получаемых вероятностной нейронной сетью. Кроме того, становится возможным существенное снижение размерности вектора признаков, описывающих голосовой сигнал (в ряде случаев в среднем с 384 до 64,8 атрибута). Предложенные схемы демонстрируют высокую эффективность по сравнению с методом главных компонент. Описываемые процедуры могут быть применены для идентификации личности говорящего, распознавания его пола, возраста и других персональных характеристик, что также является предпосылкой их использования в качестве алгоритмического ядра интеллектуальных модулей диалоговых систем.
Abstract:During the human-machine communication a number of problems related to voice processing should be solved. In addition to the speech recognition problem, there are several important issues such as a speaker, gender or age identification and speech-based emotion recognition. The amount of acoustic characteristics extracted from the signal is tremendously high (hundreds or even thousands): features may correlate with each other, contain noisy data or have low variation level that decrease the accuracy of involved classifiers. Therefore it is vitally important to select informative features automatically during the recognition process. This paper considers two feature selection techniques. Both of them are based on using the self-adaptive multi-objective genetic algorithm that is adjusted while the problem is being solved. The main advantages of this heuristic optimization procedure are the simplicity of coding the informative feature subsystem and the opportunity to optimize both discrete and continuous criteria. The probabilistic neural network is used as a classifier. Effectiveness investigation of the developed approaches was conducted on the set of emotion recognition problems: data bases contained speech signals in English and German languages. During the experiments it was revealed that application of the described feature selection procedures might lead to increasing of the classification accuracy (relative improvement was by up to 22,7 %). Moreover, it became possible to reduce the dimension of the feature vector significantly (from 384 to 64,8 attributes at the average). The proposed schemes demonstrate higher effectiveness compared with Principal Component Analysis. The described methods might be applied for solving the speaker identification problem, recognizing speaker’s gender, age or other personal characteristics that also implies the opportunity to use them as the algorithmic core in the intellectual modules of dialogue systems.
| Авторы: Брестер K.Ю. (christina.bre@yandex.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева (младший научный сотрудник), Красноярск, Россия, Семенкин Е.С. (styugin@rambler.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнева, г. Красноярск, Россия, Сидоров М.Ю. (maxim.sidorov@uni-ulm.de) - Ульмский университет, аллея им. Альберта Эйнштейна (научный сотрудник), Ульм, Германия | |
| Ключевые слова: распознавание эмоций по речи, извлечение информативных признаков, многокритериальный генетический алгоритм, самоадаптация |
|
| Keywords: speech-based emotion recognition, feature selection, multi-objective genetic algorithm, self-adaptation |
|
| Количество просмотров: 7807 |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
Качество распознавания устной речи интеллектуальными диалоговыми системами (ИДС) стремительно повышается, однако использование ИДС в повседневной жизни затруднено в связи с предъявляемыми к ним требованиями. Диалоговая система должна не просто отвечать на вопросы шаблонными фразами, но и вести беседу на естественном языке, подстраиваясь под пользователя.
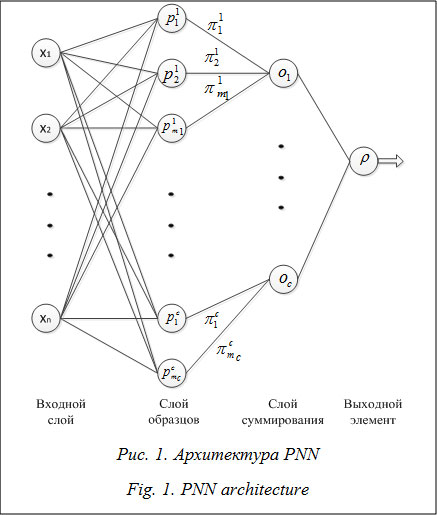
Сфера применения ИДС обширна: автоматизированные службы поддержки, системы диагностирования и проверки знаний, индустрия развлечений и т.д. При этом ориентация на конечного пользователя является ключевым моментом в процессе взаимодействия системы и человека: пол, возраст, эмоциональные особенности личности определяют формат ответа, синтезируемый ИДС. Распознавание пользователя ИДС, его эмоционального состояния, других персональных черт и т.п. осуществляется на основе акустических характеристик голосового сигнала [1, 2]. При этом количество извлекаемых из звукозаписи параметров достигает нескольких сотен, что затрудняет работу привлекаемых алгоритмов (ввиду взаимной корреляции признаков, их зашумленности). Поэтому важной задачей в процессе идентификации пользователя и его персональных характеристик (в том числе эмоций) является извлечение информативной системы признаков, используемых в дальнейшем алгоритмами распознавания. В данной статье для решения поставленной задачи предлагается использовать подходы, основанные на привлечении эвристической оптимизационной процедуры, а именно адаптивного многокритериального генетического алгоритма (ГА). Разработанные методики могут служить алгоритмическим ядром при реализации модулей ИДС. Модели извлечения информативных признаков При решении задач классификации целесообразно осуществлять предобработку данных, используемых алгоритмом обучения, поскольку атрибуты могут иметь низкий уровень вариации, коррелировать друг с другом или содержать зашумленные измерения, снижающие точность классификатора. В случае, когда стандартные методы извлечения информативных признаков (метод главных компонент, факторный анализ) не демонстрируют приемлемую эффективность, для решения данной задачи могут быть применены алгоритмические схемы, основанные на эвристических процедурах оптимизации. В статье рассматриваются два подхода: согласно первому, процедура отбора признаков осуществляется с привлечением классификатора, с помощью которого оценивается релевантность извлеченных атрибутов; второй подход соответствует этапу предобработки данных и для сравнения различных вариантов подсистем информативных признаков использует статистические характеристики, что требует меньше вычислительных ресурсов. В качестве классификатора в обоих случаях была использована вероятностная нейронная сеть PNN (Probabilistic Neural Network) [3]. PNN реализует статистические методы: осуществляется параллельная оценка функции плотности вероятности для каждого класса.
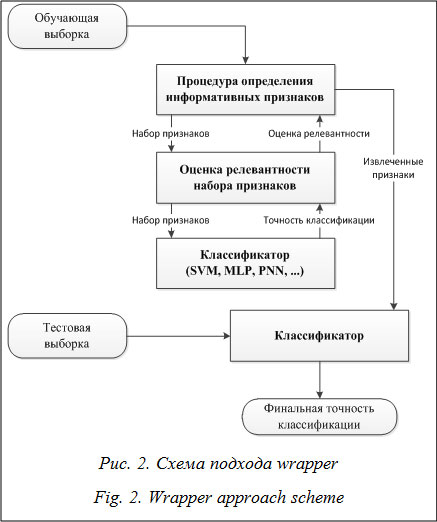
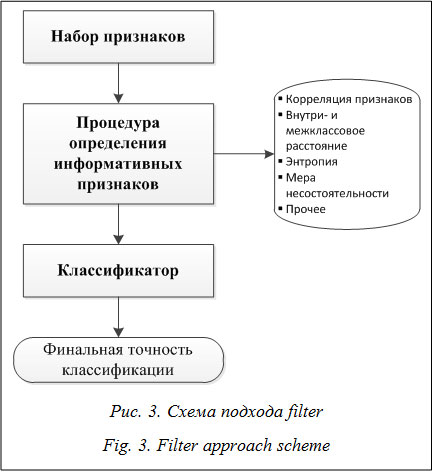
где x – новый входной образ, который необходимо классифицировать. Значение s в (1) задает ширину функции активации, чаще всего оно подбирается в ходе эксперимента. Далее следует слой суммирования: для каждого класса имеется свой нейрон-сумматор. К элементам данного слоя идут связи от нейронов второго слоя, принадлежащих соответствующему классу. Весовые значения связей фиксируются равными 1. Сумма по каждому классу представляет собой оценку значения функции плотности распределения вероятностей для экземпляров данного класса. Выходной элемент указывает на элемент слоя суммирования с максимальным значением на выходе (определяет номер класса). В работе [4] описаны основные алгоритмические схемы, в рамках которых осуществляется отбор признаков из БД. Подход wrapper – это комбинация оптимиза- ционного алгоритма и классификатора, использующегося для оценки качества извлеченной подсистемы признаков (рис. 2). В данной работе предлагается использовать многокритериальную оптимизационную процедуру, оперирующую двумя функционалами: относительная ошибка классификации, оцениваемая по валидационной выборке, и число отобранных атрибутов. Привле- чение данных критериев позволяет не только улучшить качество получаемых решений, но и сократить объемы используемых данных, а значит, и время, затрачиваемое на их обработку. Извлечение атрибутов с помощью технологии filter основано на оценке статистических характеристик наборов данных (рис. 3). Для отыскания информативной подсистемы признаков также используется двухкритериальная оптимизационная процедура. Функционалами качества выступают внутриклассовая дисперсия и расстояние между классами. В качестве метода отбора информативных признаков был выбран ГА многокритериальной оптимизации, оперирующий бинарными строками, где 1 соответствует информативному признаку, а 0 – неинформативному. Кроме того, для обеспечения гарантированного уровня эффективности работы целесообразно использование модифицированных многокритериальных ГА, основанных на идее самоадаптации. Их применение позволяет избежать настройки генетических операторов экспертом, что, в свою очередь, обусловливает более широкие возможности использования алгоритма для задач различного характера. Описание модификации алгоритма SPEA
1. Инициализировать начальную популяцию P0 (t = 0). 2. Скопировать в промежуточное внешнее множество индивидов, чьи векторы решений недоминируемые относительно Pt. 3. Удалить из промежуточного внешнего множества ( 4. Если мощность 5. Сформировать внешнее множество из индивидов 6. Применить генетические операторы: селекция, скрещивание, мутация. 7. Проверить выполнение критерия останова: если выполняется, завершить работу алгоритма, иначе – перейти к п. 2. На шаге 6 требуется настройка генетических операторов: необходимо выбрать один из вариантов скрещивания, определить вероятность мутации. В данном методе применяется турнирная селекция (причем отбор индивидов производится не только из текущей популяции, но и из внешнего множества), поэтому выбор типа селекции не требуется. В статье [6] предложен следующий вариант адаптивной мутации:
где t – номер текущего поколения, для которого рассчитывается вероятность мутации. Для реализации адаптивного оператора скрещивания были применены идеи коэволюционного ГА [7]. На каждом поколении генерирование новой популяции осуществляется всеми типами скрещивания: вариантам оператора выделяются ресурсы (доля индивидов популяции, генерируемых конкретным типом скрещивания на текущем поколении) в зависимости от числа индивидов во внешнем множестве, сгенерированных при помощи данного варианта скрещивания:
где Pi – число индивидов во внешнем множестве, сгенерированных при участии i-го типа оператора скрещивания; Для каждого варианта оператора скрещивания вычисляется его пригодность qi по формуле
где T – интервал адаптации; k = 0 соответствует последнему поколению в интервале адаптации, k = 1 – предыдущему и т.д. Через каждые T поколений осуществляется попарное сравнение «пригодности» вариантов скрещивания с целью перераспределения ресурсов согласно правилу
где si – размер ресурса (количество индивидов), отдаваемого i-м алгоритмом каждому победившему его алгоритму; hi – число поражений алгоритма в попарных сравнениях; social_card – минимально допустимый размер популяции; penalty – размер штрафа для проигравших алгоритмов. Параметр social_card предназначен для поддержания разнообразия вариантов оператора, penalty – для перераспределения ресурсов. Результаты исследования разработанных методик Для тестирования предложенных алгоритмических схем были использованы три БД: Berlin [8], SAVEE [9] и VAM [10], содержащие характеристики голосовых записей на немецком, английском и немецком языках соответственно (табл. 1). Каждый звуковой файл описывался 384 признаками, представляющими собой максимальное, минимальное, среднее значения или среднеквадратическое отклонение акустических характеристик, описывающих речевой сигнал, его высоту, вибрации, интенсивность и т.п. Таблица 1 Описание используемых БД Table 1 Description of used databases
Для анализа эффективности реализованных подходов для каждой задачи была оценена точность классификации на полном наборе признаков, на информативной подсистеме атрибутов, извлеченной SPEA в рамках подходов wrapper и filter, а также на наборе признаков, полученных с помощью метода главных компонент (PCA) (табл. 2). В скобках указано усредненное количество атрибутов, извлеченных из БД для обучения классификатора. Таблица 2 Результаты решения задач распознавания эмоций Table 2 The results of solving emotions recognition tasks
Полученные результаты усреднялись по 20 прогонам, выборка делилась на обучающую и тестовую в пропорции 70 на 30 %. Как известно, результатом работы метода SPEA является множество не доминируемых по Парето точек, поэтому финальное решение выбиралось с помощью многократных прогонов классификатора на обучающем множестве примеров, часть которых составляла валидационную выборку (20 % от обучающей). Анализ полученных результатов показал, что применение метода SPEA для извлечения информативных признаков позволяет не только сократить число атрибутов, используемых для обучения классификатора, но и повысить точность получаемых моделей для всех БД, представленных в эксперименте. Более того, разрабатываемые подходы оказались эффективнее метода главных компонент, применение которого приводит к снижению точности распознавания. При сравнении алгоритмических схем filter и wrapper было выявлено, что первый подход позволяет получить лучшие результаты в смысле точности решения, а то время как второй существенно сокращает число признаков, используемых классификатором. В заключение отметим, что в данной работе описываются подходы, позволяющие осуществлять автоматический отбор информативных признаков из БД. Представленные алгоритмические схемы предлагается использовать в качестве основы для реализации модулей интеллектуальных диалоговых систем. В рамках проведенного исследования была продемонстрирована высокая эффективность разработанных подходов при решении задач распознавания эмоций человека по речи. В дальнейшем планируется применить описанные методы для решения задач идентификации пользователя ИДС и определения его пола по речи. Кроме того, для повышения качества решения поставленной задачи целесообразным является привлечение более точных классификаторов и поиск других эффективных эвристических оптимизационных процедур, их реализация и исследование с целью дальнейшей модификации, кооперации и прочего. Литература 1. Boersma P. Praat, a system for doing phonetics by computer. Glot international, 2002, no. 5 (9/10), pp. 341–345. 2. Eyben F., Wöllmer M., and Schuller B. Opensmile: the munich versatile and fast opensource audio feature extractor. Proc. of the Intern. Conf. on Multimedia, 2010, ACM, pp. 1459–1462. 3. Specht D.F. Probabilistic neural networks. Neural networks, 1990, vol. 3, no. 1, pp. 109–118. 4. Kohavi R., John G.H. Wrappers for feature subset selection. Artificial Intelligence-97, 1997, pp. 273–324. 5. Zitzler E., Thiele L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. Evolutionary Computation, IEEE Transactions on, 1999, vol. 3, no. 4, pp. 257–271. 6. Daridi F., Kharma N., and Salik J. Parameterless genetic algorithms: review and innovation. IEEE Canadian Review, 2004, vol. 47, pp. 19–23. 7. Sergienko R., Semenkin E. Competitive cooperation for strategy adaptation in coevolutionary genetic algorithm for constrained optimization. IEEE Congress on Evolutionary Computation, 2010, pp. 1–6. 8. Burkhardt F., Paeschke A., Rolfes M., Sendlmeier W.F., and Weiss B. A database of german emotional speech. In Interspeech, 2005, pp. 1517–1520. 9. Haq S., Jackson P. Machine Audition: Principles, Algorithms and Systems, chapter Multimodal Emotion Recognition. IGI Global, Hershey PA, Aug. 2010, pp. 398–423. 10. Grimm M., Kroschel K., and Narayanan S. The vera am mittag german audio-visual emotional speech database. In Multimedia and Expo, IEEE Intern. Conf. on, IEEE, 2008, pp. 865–868. References | |||||||||||||||||||||||||||||||||||||||
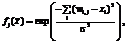 (1)
(1)
 ) индивидов, доминируемых относительно
) индивидов, доминируемых относительно 
 (2)
(2)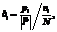 (3)
(3)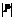 – мощность внешнего множества; ni – число индивидов в текущей популяции, сгенерированных с помощью i-го типа оператора; N – мощность популяции.
– мощность внешнего множества; ni – число индивидов в текущей популяции, сгенерированных с помощью i-го типа оператора; N – мощность популяции. (4)
(4)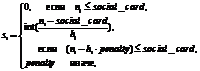 (5)
(5)| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3909&lang= |
Версия для печати Выпуск в формате PDF (6.61Мб) Скачать обложку в формате PDF (0.95Мб) |
| Статья опубликована в выпуске журнала № 4 за 2014 год. [ на стр. 127-131 ] |
Назад, к списку статей