Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Исследование влияния профилирования памяти средствами библиотеки jemalloc на время выполнения многопоточных приложений
Аннотация:Для проведения экспериментов на основе популярных синтетических тестов реализовано многопоточное приложение, позволяющее варьировать различные параметры, связанные с выделением памяти. Предложен критерий для оценки результатов профилирования памяти. На примере системы алгоритмической торговли Tbricks показано, что синтетические тесты не обладают достаточной степенью адекватности для анализа влияния профилирования памяти на характеристики оперативности реального приложения. Установлено, что неактивное профилирование не влияет на рассматриваемые характеристики, в то время как при активном профилировании наблюдаемые значения зависят от интервала выборки и могут ухудшаться в несколько раз. Проведен анализ исходного кода библиотеки jemalloc, отве-чающего за профилирование памяти, что помогло определить сбор стеков как основную причину накладных расхо-дов при профилировании. Выполнено сравнение рассматриваемых характеристик оперативности при использовании библиотек для сбора стеков libunwind и prof-libgcc: результаты экспериментов, выполненных с использованием би б-лиотеки для сбора стеков libunwind, в среднем на 20 % хуже, чем при использовании библиотеки prof-libgcc. На ос-нове проведенных экспериментов авторами рекомендован интервал выборки, при котором результаты профилирова-ния содержат информацию не менее чем о 90 % всей выделенной памяти. При этом увеличение времени выполнения приложения с высокой степенью параллелизма составляет порядка 5 % по сравнению с отключенным профилированием, что позволяет анализировать выделение памяти в приложениях в процессе их работы в промышленных условиях.
Abstract:This paper examines the performance impact of jemalloc memory profiler on execution time of multithreaded applications. Using popular synthetic tests the authors implemented a multithreaded application which allows varying different parameters related to memory allocation. A special criteria is suggested to com-pare and estimate profiling results. Tbricks algorithmic trading system is used to demonstrate that popular syn-thetic tests are not adequate enough to analyze memory profiling impact on operational characteristics of the ap-plication. Studies have shown that inactive profiling doesn’t affect the characteristics while with active profiling its values depend on sampling interval and can decrease manyfo ld. According to our analyses of jemalloc library source code related to memory profiling, the part which takes stacktraces is the main reason of extra overhead during profiling. Thus, we compare performance impact on operational characteristics of the app lication using libunwind and prof-libgcc stacktrace libraries: results of experiments made with libunwind stacktrace library are in average 20 % worse than with prof-libgcc. Based on experimental study we recommend using sampling inte r-val which allows of capturing information of at least 90 % of all allocated memory, while execution time of highly multithreaded applications decreases by less than 5 % in comparison with the disabled profiling. This al-lows analyzing memory allocations of applications while executing in production environment.
| Авторы: Иванов Е.Ю. ( i@eivanov.com, eiva@tbricks.com) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики, «Тбрикс АБ» (аспирант, инженер-программист), Санкт-Петербург, Россия, Торопов А.В. (tav@tbricks.com) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики, «Тбрикс АБ» (аспирант, руководитель отдела), Санкт-Петербург, Россия, Косяков М.С. (mkosyakov@gmail.com, mkosyakov@tbricks.com) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики, «Тбрикс АБ» (доцент), Санкт-Петербург, Россия, кандидат технических наук | |
| Ключевые слова: интервал выборки, стек вызовов, jemalloc, многопоточность, характеристики оперативности, профилирование, память |
|
| Keywords: sampling interval, stacktrace, jemalloc, multithreading, operational characteristics, profiling, memory |
|
| Количество просмотров: 8022 |
Версия для печати Выпуск в формате PDF (4.84Мб) Скачать обложку в формате PDF (0.35Мб) |
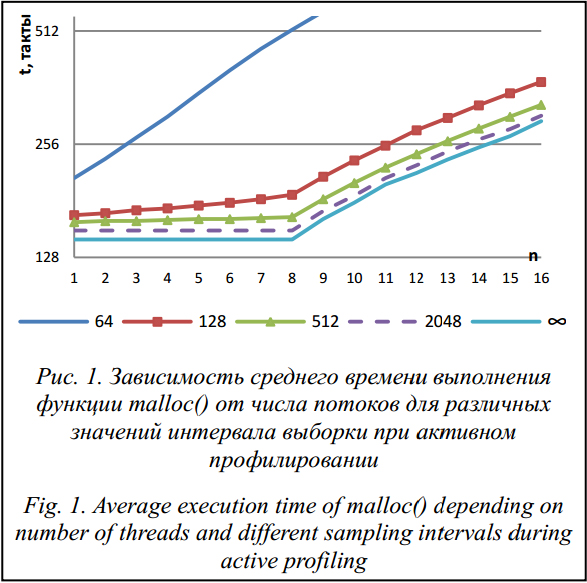
Необходимым условием хорошей масштабируемости многопоточных приложений при увеличении числа процессоров является использование специализированных программных библиотек выделения памяти. В противном случае одновременное выделение памяти несколькими потоками становится узким местом при работе с динамическими структурами данных [1–3]. При этом хорошая библиотека обычно предоставляет возможность профилирования памяти, то есть позволяет выявлять основные характеристики работы с памятью, такие как общий объем выделенной и освобожденной приложением памяти, информация о фрагментации памяти, стеки вызовов, приводящие к выделению наибольшего объема памяти (далее – стеки выделения памяти). Результаты профилирования помогают оптимизировать приложения. Рассматриваемая в данной работе библиотека выделения памяти jemalloc [4] является одной из наиболее популярных библиотек для многопоточных приложений, разрабатываемых под платформу Linux. Свою известность она получила благодаря реализованным в ней механизмам работы с памятью, обеспечивающим лучшую производительность приложения, и, как следствие, ее активному внедрению в серверные компоненты платформы Facebook [4, 5]. Jemalloc реализует функцию malloc() согласно стандарту POSIX и дает возможность профилирования памяти. Одно из преимуществ библиотеки в том, что при запус- ке приложения профилирование может быть включено (опция opt.prof=true), но неактивно (opt.prof_active=false). Это делает возможным запуск и остановку профилирования прямо во время работы приложения. Стоит отметить, что другие популярные средства профилирования, такие как valgrind [6] и TCMalloc [7], такой возможности не предоставляют. При активном профилировании информация о выделении памяти сохраняется при выделении каждых x Кб, называемых интервалом выборки. Интервал выборки x является настраиваемым параметром, его увеличение уменьшает влияние профилирования на характеристики оперативности приложения, но при этом результаты показывают не все стеки выделения памяти. Согласно документации jemalloc, размер интервала выборки по умолчанию составляет 512 Кб. При работе приложений в промышленных условиях возникают ситуации, когда объем выделяемой памяти резко возрастает. Опыт показывает, что для систем алгоритмической торговли рост может составлять десятки гигабайт за несколько минут. Подобные случаи легко отслеживать без существенных накладных расходов [8], однако возникает необходимость поиска стеков, приводящих к выделению наибольшего объема памяти. Одним из решений является использование возможностей jemalloc запускать и останавливать профилирование памяти прямо во время работы приложения. При этом важно определить интервал выборки, позволяющий получить необходимую информацию при сохранении предоставляемых приложением гарантий к его временным харак- теристикам, что критично для широкого класса систем, включающих в себя системы алгоритмической торговли [9] и большинство встроенных систем, работающих в условиях дефицита ресурсов [10]. Основные цели данной работы – исследование изменения характеристик оперативности приложения и оценка получаемых результатов при активном профилировании и включенном сборе стеков выделения памяти (opt.prof_accum=true) на различных интервалах выборки. Кроме того, проверяется, оказывает ли влияние включенное, но неактивное профилирование памяти средствами jemalloc на время выполнения многопоточных приложений. Синтетические тесты Для анализа влияния активного профилирования и размера интервала выборки на среднее время t выполнения функции malloc() на основе популярного синтетического теста malloc-test [11] реализовано многопоточное приложение. В целях минимизации накладных расходов и повышения точности время t измеряется в тактах центрального процессора посредством чтения аппаратного счетчика TSC (Time Stamp Counter): операция чтения этого счетчика составляет всего одну машинную команду и не требует выполнения системного вызова. Во время выполнения приложения каждый поток в цикле выделяет и освобождает память блоками по 512 байт, глубина стека при этом варьируется в пределах десяти функций, что принято считать средней глубиной [12]. Доступ к выделенной памяти отсутствует, что исключает накладные расходы на операции со страницами виртуальной памяти. Так как функция malloc() вызывается в цикле одновременно несколькими потоками, это соответствует предельному случаю состязания (от англ. contention) за выделение памяти, что позволяет оценить наихудшие значения временных характеристик. Тест выполнен для случаев, когда профилирование отключено и когда оно выполняется с разными интервалами выборки. В качестве тестового стенда для проведения всех экспериментов в данной работе использован сервер с двумя восьмиядерными процессорами Intel Xeon E5-2690 с тактовой частотой 2,9 GHz. Функция Hyper-Threading процессора отключена в целях повышения точности измерений. Сервер работает под управлением операционной системы Oracle Linux 6.5 с ядром linux-3.8 и библиотекой jemalloc-3.4.1, использующей для сбора стеков библиотеку prof-libgcc. Результаты синтетического теста приведены на рисунке 1, график «∞» соответствует отключенному профилированию.
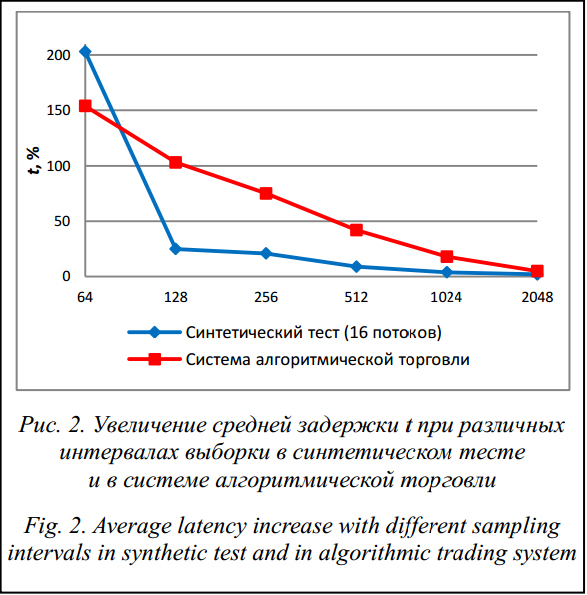
Временные характеристики приложения в значительной степени зависят от объема выделенной памяти и характера работы с ней, числа используемых страниц виртуальной памяти и после- довательности доступа к ним, эффективности использования кэша процессора [13]. Поэтому на практике результаты синтетических тестов могут значительно отличаться от результатов, характерных для реальных приложений. В связи с этим дальнейшие эксперименты выполнены на базе промышленной системы. Профилирование памяти в системе алгоритмической торговли В экспериментах использовано приложение для системы алгоритмической торговли Tbricks [9], которое при получении с биржи котировок на ценные бумаги выполняет их обработку и отправляет соответствующий заказ на покупку или продажу. Для данного приложения основной характеристикой оперативности является задержка между получением котировок и отправкой заказа. В качестве времени получения котировок и отправки заказа используется время получения/отправки соответствующего сетевого пакета. В отличие от синтетических тестов масштаб времени составляет порядка десяти микросекунд, кроме того, приложение состоит из нескольких процессов, что делает использование счетчика TSC непрактичным для измерений времени. Поэтому отметки времени получаются с помощью метода аппаратного захвата (от англ. hardware capture), позволяющего измерять время получения/отправки сетевых пакетов без влияния на характеристики оперативности системы [14]. Аппаратный захват осуществляется с помощью специальной сетевой карты Emulex Endace DAG 7.5G2 [15]. Тестовая система настроена таким образом, что приложение непрерывно получает котировки, выполняет их обработку и в ответ отсылает заказы. Все измерения выполнены и усреднены для ста тысяч отправленных заказов. Результаты экспериментов показали, что при запуске приложения с включенным, но неактивным профилированием величина задержки не изменяется. При активном профилировании наблюдается увеличение средней задержки в зависимости от значения интервала выборки. Приведем значения увеличения средней задержки относительно случая, когда профилирование выключено:
Согласно полученным результатам, активное профилирование может значительно влиять на быстродействие приложения: так, при выборке на интервале в 64 Кб задержка составляет порядка 150 % от времени, измеренного без профилирования памяти; на интервалах в 1024 Кб и 2048 Кб ухудшение составляет 18 % и 5 % соответственно. Дальнейшее увеличение интервала выборки приводит к уменьшению накладных расходов, связанных с профилированием. На рисунке 2 приведены графики увеличения задержки t для синтетического теста при выполнении 16 потоков и эксперимента, выполненного на приложении для системы алгоритмической торговли. Как видно из графиков, влияние профилирования на быстродействие приложения при интервалах выборки от 128 Кб до 2048 Кб гораздо выше, чем показали синтетические тесты. Это связано с тем, что в синтетическом тесте увеличение времени выполнения определяется исключительно накладными расходами на сбор стеков, в то время как в реальном приложении сбор стеков вызывает дополнительную задержку в полезных вычислениях приложения, обусловленную снижением эффективности использования кэша процессора и виртуальной памяти. Однако при интервале в 64 Кб ухудшение быстродействия в синтетическом тесте значительно существеннее. Это свидетель- ствует о том, что выделение памяти в реальном приложении в среднем не достигает ситуации предельного состязания. Данные результаты ука- зывают на необходимость проведения подобных экспериментов на системах, где планируется выполнять профилирование.
Для оценки качества результатов, полученных при профилировании, использован следующий критерий: общий объем памяти по всем выявленным стекам должен составлять не менее 90 % от всей памяти, выделенной приложению во время профилирования. Согласно полученным результатам, данное условие выполняется на интервалах, меньших или равных 2048 Кб. На интервалах, больших 2048 Кб, качество результатов профилирования резко снижается, что не позволяет эффективно использовать их для оптимизации приложения. Поэтому авторы рекомендуют взять интервал выборки в 2048 Кб. Таким образом, в данной работе исследовано влияние профилирования памяти средствами библиотеки jemalloc на время выполнения многопоточных приложений. Для этого разработан синтетический тест и выполнены эксперименты с использованием приложения, реализованного для системы алгоритмической торговли Tbricks. При сравнении полученных результатов установлено, что популярные синтетические тесты не обладают достаточной степенью адекватности для анализа влияния профилирования памяти на характеристики оперативности реального приложения. С помощью приложения алгоритмической торговли в данной работе показано, что использование jemalloc с включенным, но неактивным профилированием памяти позволяет работать с приложением во время промышленной эксплуатации без ухудшения его быстродействия. Это дает возможность в случае необходимости запускать и останавливать профилирование без перезапуска приложения, например, при резком увеличении используемой им памяти. При активном профилировании быстродействие приложения зависит от интервала выборки: уменьшение интервала приводит к снижению быстродействия. Согласно полученным результатам, при использовании рекомендованного авторами значения интервала выборки в 2048 Кб результаты профилирования содержат информацию не менее чем о 90 % всей выделенной памяти, а снижение оперативности приложения составляет порядка 5 % по сравне- нию с отключенным профилированием, благодаря чему можно анализировать выделение памяти в приложениях, работающих в промышленных системах. Авторы выражают признательность коллегам Святухиной М.А., Осипову Е.В. и Шубину Д.С. за плодотворное сотрудничество по тематике работы и полезные замечания. Литература 1. Kahan S., Konecny P. "MAMA!": a memory allocator for multithreaded architectures. Proc. 11th ACM SIGPLAN Sym- posium on Principles and Practice of Parallel Programming (PPoPP'06). 2006, pp. 178–186. 2. Gidenstam A., Papatriantafilou M., Tsigas P. Allocating memory in a lock-free manner. Proc. 13th Annual European Conf. on Algorithms (ESA'05). 2005, pp. 329–342. 3. Berger E., Zorn B., McKinley K. Composing high-performance memory allocators. ACM SIGPLAN Notices, 2001, vol. 36, no. 5, pp. 114–124. 4. Evans J. A scalable concurrent malloc (3) implementation for FreeBSD. Proc. of the BSDCan Conf., 2006. 5. Evans J. Scalable memory allocation using jemalloc, Notes by Facebook Engineering, 2011. URL: https://www.facebook.com/ notes/facebook-engineering/scalable-memory-allocation-using-jemalloc/480222803919 (дата обращения: 13.12.2014). 6. Valgrind (home page). URL: http://valgrind.org (дата обращения: 13.12.2014). 7. Google gperftools (home page). URL: https://code.google. com/p/gperftools (дата обращения: 13.12.2014). 8. Gregg B. Systems Performance: Enterprise and the Cloud. Pearson Education, 2013, 792 p. 9. Tbricks Company. URL: https://www.tbricks.com (дата обращения: 13.12.2014). 10. Малиновский А.С., Шмырев Н.В., Костюхин К.А. Организация профилирования сложных систем в условиях дефицита ресурсов // Программные продукты и системы. 2008. № 4. С. 17–20. 11. Lever C., Boreham D. Malloc() performance in a multithreaded Linux environment. Proc. Annual Conf. on USENIX Annual Technical Conf. (ATEC'00). 2005, pp. 56–56. 12. Perks O., Hammond S., Pennycook S., and Jarvis S. WMTrace – A Lightweight Memory Allocation Tracker and Analysis Framework. Proc. of the UK Performance Engineering Workshop (UKPEW’11). Bradford, UK, 2011, pp. 6–24. 13. Molka D. et al. Memory performance and cache coherency effects on an Intel Nehalem multiprocessor system. Parallel Architectures and Compilation Techniques, 2009. PACT'09. Proc. 18th Intern. Conf., IEEE, 2009, pp. 261–270. 14. Schneider F., Wallerich J., Feldmann A. Packet capture in 10-gigabit ethernet environments using contemporary commodity hardware. Passive and Active Network Measurement, Springer Berlin Heidelberg, 2007, pp. 207–217. 15. Emulex (EndaceDAG data capture cards). URL: http://www.emulex.com/products/network-visibility-products-and-services/endacedag-data-capture-cards/specifications (дата обращения: 13.12.2014). 16. Libunwind library (home page). URL: http://www.nongnu. org/libunwind (дата обращения: 13.12.2014). |
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3998 |
Версия для печати Выпуск в формате PDF (4.84Мб) Скачать обложку в формате PDF (0.35Мб) |
| Статья опубликована в выпуске журнала № 2 за 2015 год. [ на стр. 55-59 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Репрезентативность метрик на основе событий процессора Intel Sandy Bridge при анализе времени обработки данных в памяти
- Сравнительный анализ реализаций спин-блокировок
- Сетевые и многопоточные аспекты архитектуры распределенных СУБД
- Генератор текста программ в исходном виде для систем реального времени
Назад, к списку статей