Journal influence
Bookmark
Next issue
The basic concepts of a semantic libraries formal model and its integration process formalization
Abstract:Modern technology development leads to redefinition of the library content concept, which may be not only a traditional description of printed publications, but also other types of objects. The content of digital libraries and physical objects can be linked in various ways. This article considers the library as a structured data repository suitable for integration with other data sources. The paper presents a thesaurus structure to determine their thematic scope, as well as basic concepts to describe such libraries. Such concepts as information resources, attributes sets, information and other associated objects form a conceptual basis for a generated semantic library subject domain. Thesaurus, in its turn, provides terminology support for these concepts, facilitates information system navigation, supports the process of user query qualification and completion. The article also describes the concepts for detailed data integration work; the emphasis is on the concepts used in the process of data reduction. An important characteristic of any data set regardless of its structure is data quality. Based on data quality assessment it is possible to give an objective assessment of the semantic library process efficiency, where the most important process is data integration with other sources. A formal model of concepts described in the article is used to describe a library ontology.
Аннотация:Развитие современных технологий подталкивает к переопределению понятия контента библиотеки, в качестве которого могут выступать и традиционные описания печатных изданий, и любые другие типы объектов. При этом контент цифровых библиотек и физические объекты могут быть связаны различными способами. В работе рассматриваются библиотеки как хранилища структурированных разнообразных данных с возможностью их интеграции с другими источниками данных. Приведены структура тезауруса для возможности определения их тематической направленности и основные понятия, необходимые для описания таких библиотек. Определяя такие понятия, как информационные ресурсы, наборы атрибутов, информационные объекты и другие, связанные с ними, формируют понятийную основу для некоторой предметной области создаваемой семантической библиотеки. Тезаурус же, в свою очередь, обеспечивает терминологическую поддержку этих понятий, облегчая навигацию по информационным объектам системы, поддерживает процесс уточнения и расширения запросов пользователей к системе. Также в статье описаны понятия, необходимые для детализации работ по интеграции данных, основной упор делается на понятия, используемые в процессе приведения данных. Важной характеристикой любого набора данных независимо от его структуры является понятие качества данных. Опираясь на оценку качества данных, можно давать объективную оценку эффективности процессов, происходящих в семантической библиотеке, важнейшим из которых является интеграция данных с другими источниками. Формальная модель понятий, описанная в данной части работы, используется в дальнейшем для описания онтологии такой библиотеки.
| Authors: Ataeva O.M. (oli@ultimeta.ru) - A.A. Dorodnitsyn Computing Centre of RAS (Junior Researcher), Moscow, Russia, Serebryakov V.A. (serebr@ultimeta.ru) - A.A. Dorodnitsyn Computing Centre of RAS (Professor, Head of Department), Moscow, Russia, Ph.D | |
| Keywords: Data Model, data reduction, data quality, semantic library |
|
| Page views: 7838 |
Print version Full issue in PDF (9.58Mb) Download the cover in PDF (1.29Мб) |
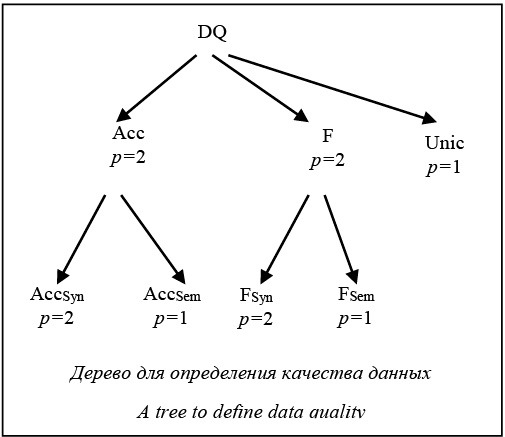
Цифровые библиотеки воспринимаются обычными пользователями как электронные версии каталогов традиционных библиотек, которые содержат описания физических объектов библиотеки, обычно книг или других печатных изданий. Определения тематики, содержания и структуры объектов рассматриваются и воспринимаются ими как дополнительные, но необязательные функции таких библиотек. Развитие Интернета и семантических технологий вносит свои коррективы [1], позволяет более широко взглянуть на понятие цифровых библиотек и обобщить накопившийся опыт реализации информационных систем в разных областях знаний для библиотек. Само понятие библиотеки в контексте Интернета [2] приобретает совершенно другой смысл, обозначает, как минимум, активное вовлечение пользователя в процессы, предлагаемые библиотеками, и предполагает участие пользователей в процессе создания, поиска и классификации того контента библиотеки, который необходим этому конкретному пользователю. Развитие современных технологий также подталкивает к переопределению понятия контента библиотеки, в качестве которого могут выступать не только традиционные описания печатных изданий, но и любые другие типы объектов [3], например мультимедийные: видео, звук, фотографии, музейные экспонаты, коллекции минералов, архивные материалы и многое другое. При этом необходимо четко понимать, что кон- тент цифровых библиотек и физические объекты могут быть связаны различными способами. Это происходит из-за того, что физически объект существует в реальном мире в одном экземпляре, а в цифровой библиотеке всего лишь используется его описание. При этом описаний может быть несколько, они могут быть различными по структуре и смыслу, и каждое описание, ссылаясь на реальный объект, имеет собственный уникальный идентификатор, который позволяет идентифицировать конкретное описание объекта со ссылкой на него в реальном мире. Фактически цифровой ресурс может определяться как конгломерат разных описаний одного реального ресурса, представляя его общую объединенную модель данных. В этом смысле Интернет также может рассматриваться как библиотека, стихийно наполняемая пользователями без видимого порядка и структуры. Каждая страница имеет собственный идентификатор в виде URL и относится к некоторому объекту реального мира, и таких страниц могут быть тысячи. Чаще всего автоматическая обработка таких страниц для выявления полезной информации и взаимосвязей является сложной задачей и предполагает большие трудозатраты на извлечение реально нужной информации по узкой предметной области. Предпосылки работы Для облегчения процесса автоматической обработки информации в сети некоторое время назад была предложена концепция Linked Open Data (да- лее LOD) [4] для размещения и описания данных, опирающаяся на уже имеющиеся наработки парадигмы Semantic Web [5]. Основные принципы LOD призывают использовать для идентификации реальных ресурсов, их цифровых описаний и взаимосвязей уникальные идентификаторы URI. Причем эти URI должны обеспечивать доступ к описаниям объектов по протоколу HTTP, представлять описание в виде RDF [6], которое дает возможность автоматической обработки информации, и содержать в своем описании ссылки в виде URI на другие взаимосвязанные ресурсы и их описания. При соблюдении этих принципов обеспечивается стандартизированный механизм доступа к данным и поддерживается глобальный обмен данными независимо от модели данных конкретного узла, предоставляя возможность их интеграции, основываясь на URI. Парадигма Semantic Web позволяет структурировать описания ресурсов и представлять их в виде RDF, основываясь на онтологиях [7]. Онтология любой предметной области определяет ее понятия, тип, структуру, совокупность словарей и классификаторов, которые представляют тезаурус предметной области, обеспечивает доступ к знаниям предметной области в разных источниках. Онтологии позволяют вырабатывать и фиксировать общее понимание области знания, представлять знания в виде, удобном для их автоматизированной обработки, обеспечивать возможность получения и накопления новых знаний, а также возможность их многократного использования. Тезаурус же обеспечивает терминологическую поддержку предметной области, облегчает навигацию по информационным объектам системы, поддерживает процесс уточнения и расширения запросов пользователей к системе. Все это послужило предпосылками для лавинообразного роста источников данных, интегрированных в LOD, и традиционные библиотеки, являясь по сути центрами данных, с одной стороны, не могли игнорировать этот процесс, с другой – не только получили импульс к развитию и обогащению своих данных, но и стали трансформироваться и превращаться в хранилища ресурсов самых разнообразных типов, поддерживая их взаимосвязи с другими источниками из LOD. Основная проблема, возникающая в связи с этим, – гетерогенность онтологий разных источников, которая может препятствовать связыванию данных [8]. Однако существует множество исследований, с разным успехом преодолевающих эту проблему. В частности, одним из распространенных способов является активное использование и анализ связей как на уровне источников, так и на уровне самих данных. Таким образом, авторы статьи рассматривают библиотеки как хранилища структурированных разнообразных данных с возможностями их интеграции в облако LOD и определения их тематической направленности. При этом подразумевается, что поддерживается вся традиционная для электронных библиотек функциональность: создание, редактирование, поиск, идентификация ресурсов. В дальнейших работах планируется представить онтологию такой библиотеки, архитектуру приложения и описать реализацию прототипа этого приложения на примере данных библиотеки «Научное наследие России» [9]. При этом пока опускается описание процессов взаимодействия пользователя с этой библиотекой, а основное внимание уделяется ее основным понятиям, которые необходимы для описания модели данных и процессов поступления (обогащения) и поиска данных для цифровой библиотеки определенной тематики, интегрированной с различными источниками данных. Основные понятия Семантические библиотеки активно развиваются на протяжении последнего десятилетия [10], но их понятийная структура еще не устоялась. Концептуальная модель электронных библиотек с определениями важнейших представлений об архитектуре, ресурсах и их функциональности была определена в программном документе DELOS (Digital Library Reference Model) [11]. С другой стороны, эффективность исследований в этой области зависит от стандартизации и формализации собственно описаний ресурсов таких библиотек и процессов их представления. Остановимся на определениях для построения формальной модели любых типов ресурсов рассматриваемой семантической библиотеки, которые лежат в основе ее построения. Фактически понятия делятся на две категории: первая включает опре- деления понятий контента семантической биб- лиотеки, а вторая – определения понятий, необ- ходимых для определения процессов интеграции контента этих ресурсов (здесь под интеграцией подразумевается весь спектр задач, например, определение отображения разных наборов атри- бутов одного ресурса, отображение ресурсов источника на ресурсы семантической библиотеки, качество данных, процесс «очистки данных» с выявлением дубликатов, например, связывание с источником данных, классификация ресурсов средствами тезауруса предметной онтологии, распределенный поиск по источникам). На основе этих определений описываются основные процессы, например, интегрирование данных из разных источников, категоризация/классификация, выявление дубликатов на уровне данных, отображение разных моделей данных источников на заданную предметную область и т.д. Роль тезауруса в семантической библиотеке. Определяя информационные ресурсы, наборы атрибутов и информационные объекты, можно формировать понятийную основу конкретной предметной области для семантической библио- теки. Тезаурус же, в свою очередь, обеспечивает терминологическую поддержку понятий, помогая решать разнообразные задачи. Одна из таких актуальных задач – поддержка классификации ресурсов в библиотеке. Зачастую направлений классификации бывает несколько, в некоторых случаях классификаторы могут динамически меняться в процессе жизнедеятельности системы. Более того, со временем могут потребоваться новые классификаторы, которые в идеале должны безболезненно и с минимальными трудозатратами внедряться в библиотеку, не требуя внесения изменений в систему и не затрагивая структуру данных хранилища системы. При этом часто возникают ситуации, когда классификацию необходимо применить к различным типам ресурсов, причем классифицируемые типы ресурсов могут определяться также по ходу развития системы. Мы называет такую поддержку процедуры классификации гибкой классификацией. Основные определения для описания структуры контента библиотеки: o – информационный объект, OB = {o1, ..., on} – множество информационных объектов; r – информационный ресурс, R = {r1, ..., rm} – множество информационных ресурсов (типов информационных объектов); TYPE(o)= r каждому объекту соответствует информационный ресурс; IsRe(r1, r2) определяет иерархию ресурсов, то есть r2 подресурс r1, ресурс может иметь 0 и более подресурсов. Атрибуты: A = {a1, …, ak} – множество атрибутов информационных ресурсов, Z(a) – значение атрибута a. Тип атрибутов: AD – множество атрибутов, значением которых может являться любое значение из некоторого множества D, в котором не может быть информационных ресурсов системы: "ai, aiÎAD: Z(ai) = d, dÎD, D∉OB. AI – множество атрибутов, значением которых может являться любой объект из IO: "ai, ai AI: Z(ai) = o, oÎOB; AD ˅ AI = A, AD ˄ AI = Ø. Вид атрибутов: V = {v1, …, vt}. Атрибут a может быть нескольких видов: "a , a Î A : VIEW(a) = {vk}, vkÎV, 1≤k≤t, далее для простоты будем обозначать вид атрибута VIEW(a) = vk. Для атрибутов определены область значений DОМ(a)=R’, R’ÎR, и область определения RAN(a)= = X: XÎD или XÎOB. Наборы атрибутов: SA – множество таких подмножеств атрибутов, в каждое из которых входят хотя бы по одному атрибуту каждого вида, каждое такое подмножество называется набором атрибутов: " v, A’ vÎV, A’ÎSA $ a, aÎA’ VIEW(a)=v, vÎV. SET(r) = A’’ – соответствие информационного ресурса некоторым наборам атрибутов A’’ = {A’}, A’ÎSA. Если информационному ресурсу r соответствует некоторый набор атрибутов A’= {a1, …, at}, то все объекты o Î OB, такие что TYPE(o)= r, представляются как набор значений этих атрибутов (Z(a1), …, Z(at)). По своим функциям атрибуты можно разделить на следующие пересекающиеся виды: идентифицирующие, озаглавливающие, обязательные, классифицирующие, поисковые, описательные. В процессе обработки данных каждая задача в системе использует определенный тип атрибутов. Например, идентифицирующими атрибутами ресурса будем называть подмножество атрибутов набора атрибутов, необходимых и достаточных для однозначного определения каждого из его информационных объектов. Классифицирующие атрибуты обеспечивают поддержку задач классификации объектов и сохранения ее результатов. В соответствии с типом значений атрибуты делятся на однозначные, многозначные, имеющие множество однотипных значений, которые могут составлять мультимножество, множество, список, массив. Для описания формальной общей картины эти тонкости пока можно опустить, полагая, что мы можем включить в набор атрибутов столько однотипных атрибутов, сколько требуется. Представление информационного ресурса P(A’, v) определяется типом используемых в нем атрибутов, соответствующих ресурсу (используется, например, для автоматической генерации описания объекта для пользователя или какого-то агента). Фактически представляет выборку значений атрибутов объекта некоторого ресурса для заданного вида атрибутов. Определения для описания основных процессов обработки контента библиотеки. Модель данных источника: SX = {(rx, Ar)}, где rx и Ar – ресурсы и их атрибуты, представленные в этом источнике; G – функция отображения элементов модели данных источника на информационные ресурсы системы и их набор атрибутов: G(rx, Ar) = = (r, A’), SET(r) = A’, A’ÎSA. Источник данных: X = (SX, G). Тезаурус предметной области: Th = (P, T, R), P – набор понятий, T – набор вербальных терминов для понятий, R – набор горизонтальных и вертикальных связей между понятиями и терминами. F – функция сопоставления каждому информационному объекту из OB соответствующих терминов из T: F(oi) = {t}, t Î T, oi Î OB. Качество данных – это набор характеристик Q=(q1, ..., qm). DQ – функция, оценивающая информационные объекты на соответствие условиям характеристик качества и ставящая в соответствие некоторое число k из диапазона от 0 до 1, где значения, близкие к 1, считаются более качественными. DQ(oi)=k=Ʃqj(oi)/m; если объект oi удовлетворяет характеристике qj, то qj(oi)=1, в противном случае qj(oi)=0. Основные утверждения 1) Aтрибут ai может быть только одного типа: " aiÎA, AD ˄ AI = Ø, Þ ai Î AD ˅ ai Î AI. 2) Множеству атрибутов информационного ресурса соответствует хотя бы один набор атрибутов: " r = {a1, …, ak}, rÎR, $ A’ÌS : SET(r)=A’, ajÎA’, 1 ≤ j ≤ k. 3) Любому информационному объекту соответствует определенный набор атрибутов: " oiÎOB $ A’ = SET(r), A’ Ì S: r = TYPE(oi). 4) Если атрибуты информационного ресурса входят в разные наборы атрибутов, то этому ресурсу соответствуют несколько наборов атрибутов: " r, r Î R,: ai Î A1’, aj Î A2’ , aj, ai Ï A1’ ˄ A2’, aj ≠ ai, $ A1’ = SET(r), A2’ = SET(r). 5) Тип атрибута позволяет определить область значений этого атрибута: " aiÎAD, $ DD=DОМ(ai), DDÌD, Z(ai)=dD, dDÎDD, " ajÎAI , $ DI = DОМ(aj), DI Ì OB, Z(aj) = oi, oiÎDI. 6) Область определения атрибутов задается ресурсами наборов атрибутов, в которые они входят: " aiÎA’, $ r: SET(r) =A’ÛRAN (ai)= r, SET(r1) = A’, SET(r2) = A’’ Û RAN (ai)= r1 ˅ r2. 7) Если область значений атрибута состоит из объектов, то соответствующий им информационный ресурс также является ресурсом системы: " aj Î AI , $ r = TYPE(oi), Z(aj) = oi. 8) Если некоторый ресурс является подклассом информационного ресурса, то он сам является ресурсом системы: " r2 , IsRe(r1, r2), r1 Î R Þ r2 Î R. 9) Если представление описывает некоторый ресурс, то это также представление для любого объекта соответствующего информационного ресурса: " oiÎOB $ P(A’, v) = P(SET(r), v) = = P(SET(TYPE(oi)), v). 10) Если некоторому ресурсу соответствует набор атрибутов, то этот набор также соответствует любому его подресурсу: " r1, r2ÎIR , IsRe(r1, r2), $ A’ÌS A’ = SET(r1) = SET(r2). 11) Если представление описывает некоторый ресурс, то это также представление для любого его подресурса: " r1, r2 Î R, IsRe(r1, r2), $ P(A’, vi) = = P(SET(r1), vi) = P(SET(r2), vi). 12) Если представление описывает некоторый ресурс, то это также представление для любого объекта его подресурса: " oiÎOB, TYPE(oi) = r2, IsRe(r1, r2), $ P(A’, vi) = = P(SET(r1), vi)=P(SET(r2), vi)=P(SET(TYPE(oi)), vi). 13) Если представление определено для некоторого набора атрибутов, то оно определено для любого информационного ресурса, соответствующего этому набору: " A’, A’ = SET(r1) = SET(r2) Þ P(A’, vi) = P(SET(r1), vi) = P(SET(r2), vi). 14) Если некоторые ресурсы источника невозможно отобразить на ресурсы системы, то можно добавить новый информационный ресурс в систему и определить его набор атрибутов без ущерба для имеющихся ресурсов и объектов. Обратный процесс в данной постановке задачи невозможен. 15) Так как представлению объекта определенного ресурса всегда можно сопоставить определенную характеристику качества, то по этой оценке всегда можно определить качество отдельного представления объекта: – оценка всех представлений объекта (для одного набора атрибутов) позволяет оценить «качественность» объекта; – оценка представления определенного вида для объектов некоторого типа ресурсов позволяет оценить на «соответствие определенной характеристике качества» набора объектов этого ресурса. Примеры построения запросов 1) Извлечь все объекты определенного информационного ресурса из системы: ∃ oi: oi Î OB ˄ TYPE(oi)= r ˄ r Î R . 2) Извлечь все объекты определенного информационного ресурса, у которых задано значение oi атрибута aj и oi является информационным объектом: ∃ oi: oi OB ˄TYPE(oi)=r ˄ rÎR ˄ ai Î AI ˄Z(aj) = =oi ˄ oiÎDI ˄ DI = DОМ(aj) ˄ DI Ì OB. 3) Извлечь все объекты определенного информационного ресурса, у которых задано определенное значение oi атрибута aj и при этом oi не является информационным объектом: ∃ oi: oiÎOB ˄ ˄ TYPE(oi)= r ˄ r Î R ˄ aiÎAD ˄ Z(aj) = oi ˄ oi Î DD ˄ ˄ DD = DОМ(aj) ˄ ¬(DD Ì OB). 4) Извлечь все объекты определенного информационного ресурса из источника: ∃ oi: TYPE(oi ) = = r ˄ rÎR ˄ SET(r) =A’ ˄ G -1(r, A’) = SX . 5) Извлечь все объекты определенного информационного ресурса из источника со значением oi атрибута aj, при этом oi является информационным объектом: ∃ oi: TYPE(oi)= r ˄ rÎR ˄ SET(r) = = A’˄G-1(r, A’) = SX ˄ aiÎAI ˄ Z(aj) = oi ˄ oiÎDI ˄DI = = DОМ(aj) ˄ DI Ì OB . 6) Извлечь все объекты определенного информационного ресурса из источника со значением oi атрибута aj, при этом oi не является информационным объектом: ∃ oi: TYPE(oi)= r ˄ rÎR ˄ SET(r) = = A’ ˄ G-1(r, A’)=SX ˄ aiÎAD ˄ Z(aj)=oi ˄oiÎDD˄DD = = DОМ(aj) ˄ ¬(DD Ì OB). 7) Запрос на представление данных о некотором объекте информационного ресурса, информация о котором может быть извлечена из разных источников: ∃ oi : TYPE(oi)= r ˄ rÎR ˄ SET(r) = A’ ˄ ˄ G1-1 (r, A’) = SX1 ˄ ... ˄ Gn-1(r, A’) = SXn. Рассмотрим подробнее запросы из пункта 7. Эти запросы, предназначенные для нескольких ис- точников, возвращают {(oi, SX)} – множество пар информационных ресурсов и соответствующих им источников данных. Один из вариантов представления данных пользователю предполагает просмотреть это множество в явном виде. В некоторых случаях пользователь может захотеть увидеть консолидированный объект, сформированный из результатов поиска, в таком случае решается в самом простом виде задача очистки данных: удаление дублирующих значений, объединение пересекающихся значений и т.д. Изменять структуру данных не приходится, так как эта задача решается на уровне возврата результатов с помощью функций Gi-1. Как можно понять даже из такого беглого обзора, хотя ранее задача приведения и очистки явно не обозначалась, это необходимый этап при работе с источниками данных. О задаче приведения данных Для формального определения общей задачи приведения данных [12] вводится понятие базиса процесса приведения W как тройки W = (OB, ТW, U), где OB – поток данных, TW – множество действий, U – множество условий. Как было сказано, OB состоит из объектов вида oi = (Z(a1), ..., Z(an)), типами значений атрибутов ai могут быть как элементарные базовые типы, так и другие объекты из OB. Множество TW = Tv U Ts, где Tv={t1, ..., tn} состоит из действий ti, которые могут менять структуру или значения объектов oi Î OB, а множество Ts = {ε} состоит из одного действия ε, которое никак не влияет на объекты из OB. Множество U = ULexU USynU USem состоит из непересекающихся подмножеств лексических ULex, синтаксических USyn и семантических USem – условий, накладываемых на OB согласно структуре ресурсов, и дополнительных условий, определяемых экспертом. Для каждого условия u Î U определена пара (ε, t) Î Tv X Ts, где ε определяет выполнение условия u для объектов oi Î OB, а действие t Î Tv приводит те объекты из OB, для которых условие u не выполняется, в соответствие условию u. Для построения концептуальной модели задачи приведения данных вводятся дополнительные сущности для оценки эффективности приведения и ее оптимизации, определяются связи между введенными сущностями, вводятся ограничения на допустимые сочетания компонентов модели и некоторые их свойства. Определяются условия для выделения допустимого порядка применения действий для множества рассматриваемых условий, при котором достигается лучший результат. Эффективное решение задач приведения прямым образом оказывает влияние на качество данных и их оценку. В свою очередь, оценка качества данных позволяет определить, насколько эффективно будут выпол- няться задачи, решаемые в рамках семантической библиотеки, например, задачи поиска идентичных ресурсов в источниках данных для связывания данных. При этом сохранение для пользователя данных об объектах информационного ресурса из разных источников может быть выполнено двумя способами: 1) связывание – этот способ идентичен по смыслу проставлению связи «смотри также» и означает, что на одном конце содержится более полная и обширная информация по ресурсу, а на другом – либо уже находящийся в системе информационный объект, либо вновь создаваемый; при этом сохраняются как минимум значения идентифицирующих свойств; 2) идентификация означает, что на одном конце содержится точно такой же по качеству информации объект, как и на другом; при этом информационный объект может уже находиться в системе до выявления идентичного в источнике данных либо просто создается новый объект, который фактически представляет собой ссылку на объект источника. Качество данных Качество данных является важной характеристикой любого набора данных независимо от его структуры. Опираясь на оценку качества данных, можно давать объективную оценку эффективности процессов, происходящих в семантической библиотеке, наиважнейшим из которых является интеграция данных с другими источниками, необязательно являющимися библиотеками. Исходя из определения атрибутов и их видов при решении, например, задач связывания данных из разных источников, необходимо предварительно оценить как минимум качество значений идентифицирующих атрибутов. В противном случае сложно объективно проанализировать полученные результаты. Поэтому используем формальное определение качества, удовлетворяющее в контексте данной задачи. Если данные пригодны для предназначенных для них целей, то можно сказать, что эти данные качественные [13]. Качество данных определяется связанными характеристиками, каждая из которых определяет наличие тех или иных недостатков во множестве данных [14]. Если OB – множество объектов, используем обозначения: o1, o2 Î OB, где TYPE(o1) =r, TYPE(o2) = r, ai – атрибут из набора SET(r)=A’.val(Z(a1i), Z(a2i))= = true, если значения атрибутов a1i и a2i объектов o1 и o2 совпадают, f(aj)=true, i ≤ n, если задан формат значений aj, которые могут быть представлены в виде последовательности символов из непустого конечного алфавита L, то есть для таких значений aj существует грамматика GJ, которая задает значе- ния атрибута aj, U={u1, …, un} – множество условий, накладываемых на объекты, u(ai, …, ak) будем обозначать как g(oi, us) – функцию, принимающую значения true в случае выполнения условия us для объекта и false в противном случае. Будем говорить о наличии на уровне данных [13, 14]: а) синтаксических ошибок (обозначим через MSyn), если для Z(ai) = null, при этом не существует условия вида u(ai, aj), когда от ai нет зависимых значений, Z(ai) ∉ RAN(ai), f(aj) ≠ true, aj Î AD и aj ∉ L(GJ). б) семантических ошибок (обозначим через MSem), если выполняется Z(ai) = null, при этом существует условие вида u(ai ,aj), такое что Z(aj) ≠ null, g(ai, uj) ≠ true, aj ÎA, если для любого o1 существует o2 Î OB и val(o1, o2) = ˄ val(Z(a1i), Z(a2i)) = true; в) ошибок на уровне схем данных [1, 2, 4, 7], если G(rX, Ar) ≠ (r, A’), то есть не существует функции отображения ресурсов источника на ресурсы системы. Определим основные характеристики качества уровня данных. Точность (Acc). Точные данные не содержат никаких ошибок, кроме, может быть, дублирования и недостающих значений. Синтаксическая точность (или согласованность – AccSyn). Если " aj Î AD и aj Î L(GJ) выполняется f(aj)= = true, то oi – синтаксически точный объект или AccSyn(oi)= true. Если " ok ÎOB выполняется AccSyn(ok) = true, то есть все объекты синтаксически точны, то множество OB называется синтаксически точным множеством данных: AccSyn(OB) = ˄ AccSyn(ok) = true. Семантическая точность (или достоверность AccSem). Если " uj выполняется g(ok, uj) = true, то ok – семантически точный объект или AccSem(oi)= true. Если " ok ÎOB выполняется AccSem(ok) = true, то есть все объекты семантически точны, то множество OB называется семантически точным множеством данных: AccSem(OB) = ˄AccSem(ok)=true. Если ok – точный объект, то Acc(ok) = AccSyn (ok) ˄ AccSem (ok)=true. Если OB – точное множество, то Acc(OB) = = AccSyn(OB) ˄ AccSem(OB)=true. Полнота (F). Полные данные не содержат недостающих значений и объектов. Синтаксическая полнота (FSyn). Если " okÎOB выполняется Z(ai) Î RAN(ai) и Z(ai) ≠ null, при этом не существует условия вида u(ai ,aj), то ok – синтаксический полный объект или FSyn(ok)=true. Если " okÎOB выполняется FSyn(ok)=true, то есть все объекты синтаксически полные, то множество OB называется синтаксически полным множеством данных: FSyn(OB) = ˄ FSyn(ok)=true. Семантическая полнота (FSem). Если " ok Î OB выполняется Z(ai) Î RAN(ai) и Z(ai) ≠ null, при этом существует условие вида u(ai, aj), то ok – семантически полный объект или FSem(ok)=true. Если " ok Î OB выполняется FSem (ok)=true, то есть все объекты семантически полные, то множество OB называется семантически полным множеством данных: если ok – полный объект, то F(ok) = FSyn (ok) ˄ FSem (ok)=true, если OB – полное множество, то F(OB) = FSyn (OB) ˄ FSem (OB)=true. Уникальность (Uniq). Если " o1 не существует o2ÎOB и val(o1, o2) = ˄val(Z(a1i), Z( a2i)) = true, то o1 называется уникальным объектом или Uniq(o1) = = true. Если все объекты уникальны, то множество OB называется уникальным множеством данных. Таким образом, определены ошибки только двух типов. Далее будем использовать обозначения: М – ошибки, MSyn – синтаксические ошибки и MSem – семантические ошибки, такие что MSem ⊆ M, MSyn ⊆ M, MSyn ⊆¬ MSem, каждый тип ошибок разбивается на подтипы в зависимости от того, какому критерию качества они соответствуют. Зависимость уровня качества данных от порядка обработки ошибок Уровень качества данных определяется степенью их соответствия характеристикам, используемым при определении понятия «качество данных». Наилучшее качество достигается при полном соответствии всем характеристикам. Для достижения высокого уровня качества данных прежде следует обрабатывать синтаксические ошибки, а затем семантические. При определении синтаксических ошибок при их обработке происходит анализ отдельных значений атрибутов объектов независимо от других значений, объектов и их связей, тогда как из определения семантических ошибок при их обработке происходит анализ значений атрибутов, зависимых также от других условий. Поэтому синтаксическая корректность значений влияет на качество обработки семантических ошибок, так как часть ошибок могут оказаться «невидимыми». Последовательность обработки ошибок разных подтипов во множествах MSyn, MSem определяется в зависимости от уровня вложенности соответствующей характеристики качества и приоритетов, присвоенных характеристикам одного уровня (чем меньше значение приоритета, тем позже обрабатывается соответствующая ошибка). Причем, если некоторым характеристикам одного уровня присвоен одинаковый приоритет, предпочтение отдается той характеристике, приоритет предка которой выше. Если же приоритеты предков совпадают, определение порядка обработки не может существенно повлиять на результат (то есть порядок обработки ошибок в каждом подобном случае может меняться), так как значения, используемые при обработке соответствующих ошибок, не могут зависеть от значений друг друга по определению. Определение порядка обработки ошибок происходит в несколько шагов: – order(M) = (MSyn ® MSem), – order(MSyn) = ((p1® … ® pk)1, …, (p1 ® … ® ph)m), – order(MSem) = ((p1 ® … ® pl)1, …, (p1 ® … ® ps)m), где pi – приоритет характеристик качества данных, соответствующих обрабатываемым ошибкам, 1≤i≤k, 1≤i≤h, 1≤i≤l, 1≤i ≤s, где k, h, l, s – количество используемых характеристик качества данных одного уровня; (p1 ® … ® pt)i – порядок обработки ошибок, соответствующих характеристикам, расположенным на одном уровне согласно приоритету, где 1≤i ≤m, m – наибольший уровень вложенности используемых характеристик в дереве, корень дерева имеет уровень 0. Если обрабатывается несколько ошибок, соответствующих одной характеристике в одном подмножестве потока данных, то порядок их обработки в рамках этой характеристики определяется произвольно, так как зависимости между значениями, участвующими в анализе этих ошибок, не влияют на результат по определению. Для используемого определения качества данных построим соответствующее ему дерево (см. рисунок).
В следующей работе планируется описать онтологию, основанную на этих понятиях, и подробнее остановиться на задачах описания, интеграции и обработки данных в терминах этой онтологии. Возможность описания понятийной модели ресурсов библиотеки в терминах этой онтологии в совокупности с поддержкой тезауруса этой предметной области является, на взгляд авторов, необходимым условием для создания гибких семантических библиотек, интегрируемых в LOD и использующих все возможные преимущества взаимосвязанных данных из его источников. Литература 1. Антопольский А.Б., Каленкова А.А., Каленов Н.Е., Серебряков В.А., Сотников А.Н. Принципы разработки интегрированной системы для научных библиотек, архивов и музеев // Информационные ресурсы России. 2012. № 1. С. 2–7. 2. Горный Е., Вигурский К. Развитие электронных библиотек: мировой и российский опыт, проблемы, перспективы // Интернет и российское общество; [под ред. И. Семенова]. М.: Гендальф, 2002. С. 158–188. 3. Серебряков В.А., Атаева О.М. Персональная цифровая библиотека Libmeta как среда интеграции связанных открытых данных // RCDL. 2014. 4. Bizer C., Heath T., and Berners-Lee T. Linked data – the story so far. Int. J. Semantic Web Inf. Syst., 2009, no. 5 (3), pp. 1–22. 5. Semantic Web. URL: http://www.w3.org/standards/semanticweb/ (дата обращения: 10.06.2015). 6. Resource Description Framework URL: http://www.w3. org/RDF/ (дата обращения: 10.06.2015). 7. Gruber T.R. A translation approach to portable ontologies. Knowledge Acquisition, 1993, no. 5 (2), pp. 199–220. 8. Lihua Zhao. Ontology Integration for the Linked Open Data. 2013 URL: http://ri-www.nii.ac.jp/~lihua/PhD.Thesis.LihuaZhao.pdf (дата обращения: 10.06.2015). 9. Электронная библиотека «Научное наследие России». URL: http://e-heritage.ru/index.html (дата обращения: 10.06.2015). 10. Sebastian Ryszard Kruk • Bill McDaniel. Semantic Digital Libraries. Springer-Verlag Berlin Heidelberg, 2009. 11. Candela L., Castelli D., Dobreva M., Ferro N., Ioannidis Y., Katifori H., Koutrika G., Meghini C., Pagano P., Ross S., Agosti M., Schuldt H., Soergel D. The DELOS Digital Library Reference Model Foundations for Digital Libraries. IST-2002 2.3.1.12. Technology-enhanced Learning and Access to Cultural Heritage. Version 0.98, December 2007. URL: http://www.delos.info/files/pdf/ReferenceModel/DELOS_DLReferenceModel_0.98.pdf (дата обращения: 10.06.2015). 12. Rahm E., Hai Do H. Data Cleaning: Problems and Current Approaches. 2000. 13. Scannapieco M., Missier P., Batini C. Data Quality at a Glance. Datenbank-Spektrum, 2005, vol. 14, pp. 6–14. 14. Singh R., Dr. Singh K. A Descriptive Classification of Causes of Data Quality Problems in Data Warehousing. IJCSI Intern. Journ. of Computer Sc. Issues, 2010, vol. 7, iss. 3, no. 2. |
| Permanent link: http://swsys.ru/index.php?page=article&id=4088&lang=&lang=en&like=1 |
Print version Full issue in PDF (9.58Mb) Download the cover in PDF (1.29Мб) |
| The article was published in issue no. № 4, 2015 [ pp. 180-187 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Открытость структур в эволюционной модели данных
- Система корпус-менеджер: архитектура и модели корпусных данных
- Об одном подходе к реализации системы управления мастер-данными об активах
- Модели как основные артефакты архитектуры информации
- Особенности работы с документами в информационных системах управления данными
Back to the list of articles