Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Репрезентативность метрик на основе событий процессора Intel Sandy Bridge при анализе времени обработки данных в памяти
Аннотация:В данной работе выполнена оценка репрезентативности метрик на основе событий процессора Intel Sandy Bridge при анализе времени обработки данных в памяти. Приведены детальный обзор и анализ наиболее часто используемых при профилировании метрик, рекомендованных в документации Intel. Разработан синтетический тест, позволяющий измерить временные задержки при последовательном, случайном и постраничном доступах к памяти, различных размерах всего рабочего множества и отдельных его элементов, обрабатываемых тестовым приложением. Описан способ профилирования и получения числа событий процессора, основанный на использовании утилиты perf ОС Linux. С помощью теста получены временные характеристики работы с оперативной памятью и рассчитаны метрики на основе событий процессора. Экспериментально установлено, что при последовательном доступе к данным зависимость рекомендованных компанией Intel метрик CPI, SCPI, PSRC и частоты кэш-промахов от измеренных временных задержек имеет линейный характер. Кроме того, изменение данных метрик пропорционально изменению времени с коэффициентом, близким к единице. На основе полученных результатов для случайного доступа к памяти показано, что наиболее эффективной метрикой является число тактов, затраченных на ожидание шины данных, так как данная метрика хорошо описывает временные задержки в работе приложений, выполняющих обработку данных вне зависимости от их расположения в памяти. По мнению авторов, указанная метрика наиболее удобна для оценки эффективности оптимизации работы приложения с оперативной памятью. На основе полученных результатов показано, что рассматриваемые в работе метрики являются репрезентативными и могут быть использованы при анализе временных характеристик приложений, обрабатывающих данные в оперативной памяти компьютера.
Abstract:This paper examines the representativeness of metrics based on Intel Sandy Bridge performance event counters and memory access latencies for data processed in RAM. It contains detailed overview and analyses of frequently used metrics recommended by Intel documentation. The authors have implemented a synthetic test application, which allows measuring memory access latencies for serial, per-page and random memory accesses and different sizes of working set and its elements processed by test application. The paper describes an approach to access performance event counters based on Linux perf utility. The test presented memory access latencies and calculated metrics based on performance event counters. The experimental studies showed that CPI, SCPI and PSRC metrics recommended by Intel and cache-miss ratio with serial memory access have linear dependency with measured memory latencies. Besides, the metrics values change proportionally to the change of memory latencies with the coefficient close to one. The random access results showed that most efficient metric for performance is the number of cycles wasted on bus waiting for data, because it always has high representativeness of memory access latencies and does not depend on data location. According to authors’ analyses, this metric is the most useful to evaluate memory access performance optimization efficiency. The results showed that the metrics considered in this paper can be used to analyze memory characteristics of application, which process data in RAM.
| Авторы: Иванов Е.Ю. ( i@eivanov.com, eiva@tbricks.com) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики, «Тбрикс АБ» (аспирант, инженер-программист), Санкт-Петербург, Россия, Косяков М.С. (mkosyakov@gmail.com, mkosyakov@tbricks.com) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики, «Тбрикс АБ» (доцент), Санкт-Петербург, Россия, кандидат технических наук | |
| Ключевые слова: intel sandy bridge, кэш-память, быстродействие, оптимизация, профилирование, доступ к памяти, временные задержки, события процессора, счетчики производительности |
|
| Keywords: intel sandy bridge, cache-memory, speed, optimisation, profiling, memory access, memory access latencies, event processor, performance event counters |
|
| Количество просмотров: 8970 |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
При разработке ПО важным этапом оптимизации времени выполнения является профилирование. Процесс профилирования заключается в выявлении основных характеристик работы приложения, таких как наиболее часто выполняемые участки исходного кода и точки вызова системных функций, время работы отдельных функций, эффективность использования ресурсов процессора. Результаты профилирования позволяют найти исходный код, оказывающий наибольшее влияние на общее время выполнения программы или отдельных библиотечных функций, что помогает оптимизировать приложения. Некоторые типы профилирования могут оказывать влияние на быстродействие приложения, однако часто данное влияние можно свести к минимуму [1]. Для оценки эффективности использования ресурсов процессора обычно применяются метрики на основе его событий. Современные процессоры Intel предоставляют пользователю не менее 8 физических счетчиков производительности (от англ. performance counters) [2], которые можно запрограммировать на подсчет практически любых событий процессора, например кэш-промахов или числа выполненных микроопераций [3, 4]. Метрики на основе числа событий процессора позволяют обнаружить исходный код, неэффективный с точки зрения использования ресурсов процессора, причиной чего могут быть проблемы как в реализации на вы- сокоуровневом языке, так и при генерации машинных инструкций компилятором. При использовании таких метрик основная сложность заключается в сопоставлении их значений со временем выполнения профилируемого кода. Проанализируем репрезентативность наиболее часто используемых метрик на основе событий процессора Intel Sandy Bridge и временных характеристик работы приложений, выполняющих обработку данных, хранящихся в оперативной памяти компьютера. Результаты данного анализа могут быть использованы для оценки изменения времени обработки данных из оперативной памяти после оптимизации приложения исключительно по метрикам на основе счетчиков событий процессора. Обзор основных метрик на основе числа событий процессора Для общей оценки эффективности использования ресурсов процессора компания Intel в своей документации для инструмента Intel VTune Amplifier XE [5] предлагает следующие метрики: – CPI (cycles per instruction) – среднее число тактов процессора, затраченное на выполнение одной инструкции; – SCPI (stalled cycles per instructions) – среднее число холостых тактов процессора на одну инструкцию; – PSRC (pipeline slots retired per cycle) – среднее число освобожденных слотов конвейера процессора за один такт. CPI вычисляется как отношение числа следующих событий процессора: CPU_CLK_UNHALTED. THREAD / INST_RETIRED.ANY (здесь и далее мы используем названия событий процессора из документации Intel), где INST_RETIRED.ANY – число выполненных инструкций, а CPU_CLK_UNHALTED.THREAD – число тактов процессора, затраченных на их выполнение. Обычно референсные значения CPI измеряются с помощью различных синтетических тестов, после чего они используются при сравнении со значениями, полученными для профилируемого приложения. Благодаря параллелизму уровня инструкций значение CPI в общем случае должно быть меньше или равно единице. Однако это значение сильно зависит от нагрузки, поэтому обычно CPI используется для сравнения эффективности каждого шага оптимизации: уменьшение CPI свидетельствует об улучшении быстродействия, увеличение – о его ухудшении. SCPI часто применяется для оценки накладных расходов на доступ к оперативной памяти и рассчитывается как отношение значений счетчика UOPS_ISSUED.ANY, запрограммированного для подсчета тактов процессора, во время которых выполнение инструкций было блокировано (от англ. stalled cycles), к счетчику INST_RETIRED_ANY. Чем выше значение SCPI, тем больше временные задержки, поэтому при оптимизации приложения разработчики должны стремиться к снижению значения SCPI. Метрика PSRC показывает, насколько эффективен конвейер процессора. Согласно документации Intel, метрика рассчитывается по следующей формуле: UOPS_RETIRED.RETIRE_SLOTS / (4 * CPU_CLK_UNHALTED.THREAD), где UOPS.RETIRED.RETIRE_SLOTS – общее число выполненных микроопераций. Множитель 4 обусловлен тем, что в процессорах Intel на базе микроархитектуры Core второго поколения, куда относятся процессоры Intel Sandy Bridge, за один такт может быть выполнено до 4 микроопераций. Более высокие значения PSRC свидетельствуют о более эффективном использовании процессора. В дополнение к метрикам, описанным выше, оценим влияние частоты кэш-промахов и числа тактов, затраченных на доступ к шине данных (от англ. bus cycles) на время выполнения приложений, обрабатывающих данные, хранящиеся в оперативной памяти. Временные задержки при доступе к памяти на процессорах Intel Sandy Bridge Для измерения временных характеристик работы приложений при различных типах доступа к памяти, размерах рабочего множества (от англ. working set) и обрабатываемых данных авторами на основе популярных синтетических тестов [6] разработано тестовое приложение на языке С++. В приложении создается список из элементов, размер которых можно варьировать, и выполняется обход всех элементов списка. Число элементов в списке выбирается таким образом, чтобы размер списка соответствовал размеру рабочего множества, указанного при запуске приложения. Также при запуске указывается порядок обхода элементов: последовательный (элементы расположены в памяти последовательно), случайный или постраничный (каждый элемент расположен на своей странице виртуальной памяти). В случае, когда каждый элемент расположен на своей странице памяти, смещение к элементу списка внутри страницы случайно, что позволяет избежать так называемых ассоциативных промахов (от англ. associativity miss), вызванных особенностью кэш-памяти с множественным доступом [7]. Важно отметить, что при обходе считываются только первые 8 байт элемента, в которых хранится адрес следующего элемента. Результатом выполнения является среднее время t, затраченное на посещение одного элемента списка, измеренное в тактах процессора. Эксперименты выполнены на сервере с процессором Intel Xeon E5-2690 с тактовой частотой 2.9 GHz. С целью повышения точности результатов функция Hyper-Threading процессора отключена. Сервер работает под управлением операционной системы Oracle Linux 6.5 с ядром linux-3.8, размер страницы виртуальной памяти равен 4 Кб. Intel Xeon E5-2690 имеет следующие параметры: – размер кэша данных первого уровня – 32 Кб; – размер кэша второго уровня – 256 Кб; – размер кэша третьего уровня – 20 480 Кб; – длина кэш-линейки – 64 байта; – число записей DTLB первого уровня – 64 (для страниц виртуальной памяти размером 4 Кб); – число записей TLB второго уровня – 512 (для страниц виртуальной памяти размером 4 Кб).
Анализ репрезентативности метрик при оценке изменения временных задержек Для получения значений числа событий процессора и дальнейшего расчета метрик выполнено профилирование тестовой программы, описанной выше. Для профилирования использована утилита perf [12], которая позволяет активировать счетчики производительности во время выполнения программы для заданных событий процессора и по ее завершении получить их значения. В таблице приведены нормализованные значения времени t и значения числа событий. Результаты для случайного обхода включены в таблицу, но рассматриваются далее отдельно. Согласно полученным результатам, при последовательном и постраничном обходах (последовательном доступе к памяти) зависимость между средним временем t обработки одного элемента и всеми рассматриваемыми метриками имеет линейный характер. Более того, различия между нормализованными значениями находятся в пределах вычислительной погрешности, то есть можно считать их идентичными. Таким образом, в случае, когда обращение к данным осуществляется последовательно, при оптимизации программы следует ожидать изменения задержек времени во столько же раз, во сколько раз изменились значения метрик CPI, SCPI, PSRC, частоты кэш-промахов или числа тактов, затраченных на ожидание шины данных. При случайном доступе к памяти наиболее эффек- тивной метрикой является число тактов, затраченных на ожидание шины данных: данная метрика всегда имеет высокую степень репрезентативности временных характеристик работы приложений, выполняющих обработку данных, вне зависимости от их расположения в памяти. В заключение отметим, что в данной работе выполнена оценка репрезентативности метрик на основе событий процессора Intel Sandy Bridge при анализе временных характеристик приложений, обрабатывающих данные в оперативной памяти компьютера. Для этого авторами разработано тестовое приложение, позволяющее измерить временные задержки при последовательном, случайном и постраничном доступах к памяти, различных размерах всего рабочего множества и отдельных его элементов, обрабатываемых тестовым приложением. Последовательный, случайный и постраничный обходы элементов рабочего множества соответствуют различным вариантам доступа к произвольным данным в оперативной памяти. С целью получения числа событий процессора и расчета метрик на их основе с помощью утилиты perf операционной системы Linux выполнено профилирование тестового приложения. Установлено, что для программ, выполняющих обработку данных, хранящихся в оперативной памяти компьютера, при последовательном доступе к данным зависимость метрик CPI, SCPI, PSRC и частоты кэш-промахов от измеренных временных задержек имеет линейный характер. Более того, коэффициент пропорциональности данных метрик близок к единице. При случайном доступе к памяти наиболее эффективной метрикой является число тактов, затраченных на ожидание шины данных: данная метрика хорошо описывает временные задержки в работе приложений, выполняющих обработку данных, вне зависимости от их расположения в памяти. Литература 1. Иванов Е.Ю., Торопов А.В., Косяков М.С. Исследование влияния профилирования памяти средствами библиотеки jemalloc на время выполнения многопоточных приложений // Программные продукты и системы. 2015. № 2. С. 55–59. 2. Gregg B. Systems Performance: Enterprise and the Cloud. Pearson Education, 2013, 792 p. 3. Intel 64 and IA-32 Architectures Software Developer's Manual, vol. 3B: System Programming Guide, Intel, Inc. 2015, Part 2, 554 p. URL: http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-3b-part-2-manual.pdf (дата обращения: 25.06.2015). 4. Intel 64 and IA-32 Architectures Optimization Reference Manual. Intel, Inc. 2014, 642 p. URL: http://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-optimization-manual.html (дата обращения: 25.06.2015). 5. Using Intel VTune Performance Analyzer to Optimize Software for the Intel Core i7 Processor Family. Intel, Inc., 2010. URL: https://software.intel.com/en-us/articles/using-intel-vtune-performance-analyzer-to-optimize-software-for-the-intelr-coretm-i7-processor-family (дата обращения: 25.06.2015). 6. Drepper U. What every programmer should know about memory. Red Hat, Inc. 2007, vol. 11, 114 p. URL: https://people. freebsd.org/~lstewart/articles/cpumemory.pdf (дата обращения: 25.06.2015). 7. Ballabriga C., Casse H. Improving the first-miss computation in set-associative instruction caches. Real-Time Systems, 2008. ECRTS'08. Euromicro Conference on. IEEE, 2008, pp. 341–350. 8. Peng L. et al. Memory performance and scalability of Intel's and AMD's dual-core processors: a case study. Performance, Computing, and Communications Conf., 2007 (IPCCC 2007). IEEE Internationa. IEEE, 2007, pp. 55–64. 9. Zhong Y. et al. Miss rate prediction across program inputs and cache configurations. Computers, IEEE Transactions on, 2007, vol. 56, no. 3, pp. 328–343. 10. Солнушкин К.С. Анализ быстродействия ОЗУ и построение модели производительности ЭВМ // Науч.-технич. вестн. информ. технологий, механики и оптики. 2008. № 9 (54). С. 180–182. 11. Molka D. et al. Memory performance and cache coherency effects on an Intel Nehalem multiprocessor system. Parallel Architectures and Compilation Techniques, 2009. PACT'09. 18th International Conf. on. IEEE, 2009, pp. 261–270. 12. Утилита Linux perf. URL: https://perf.wiki.kernel.org/index.php/Main_Page, свободный. Яз. англ. (дата обращения: 05.10.2014). |
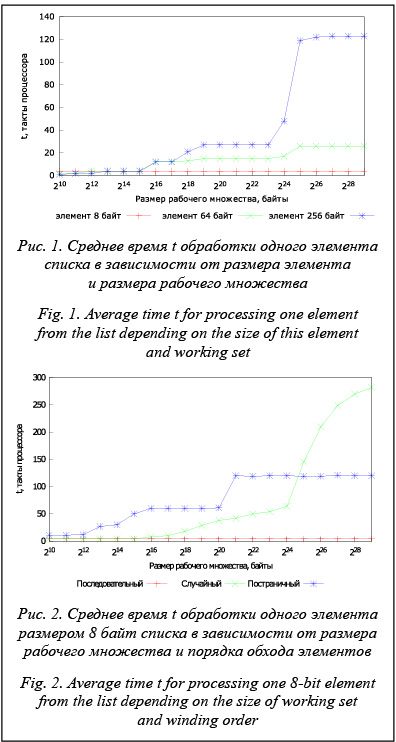
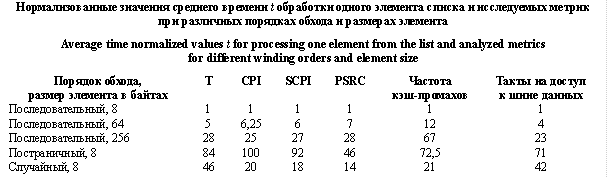 Для демонстрации влияния промахов кэша DTLB на рисунке 2 приведены графики для различных порядков обхода списка, состоящего из элементов размером 8 байт. Хорошо видно, что график для случая, когда каждый элемент расположен на своей странице виртуальной памяти, практически совпадает с графиком для последовательного об- хода элементов размером 256 байт. Но для списка с элементами размером 256 байт время t незначительно ниже, так как перед каждым промахом DTLB выполняется посещение 8 элементов, благодаря чему промахи DTLB случаются не так часто. При случайном порядке обхода промахи DTLB случаются реже, чем при постраничном, однако следует ожидать большого числа кэш-промахов, чем обусловлено значительно более высокое время t по сравнению с последовательным обходом [9]. Кроме того, при случайном доступе снижается быстродействие оперативной памяти [10]. Аналогичные результаты получены рядом исследователей для других современных процессоров с архитектурой x86_64 [6, 7, 11].
Для демонстрации влияния промахов кэша DTLB на рисунке 2 приведены графики для различных порядков обхода списка, состоящего из элементов размером 8 байт. Хорошо видно, что график для случая, когда каждый элемент расположен на своей странице виртуальной памяти, практически совпадает с графиком для последовательного об- хода элементов размером 256 байт. Но для списка с элементами размером 256 байт время t незначительно ниже, так как перед каждым промахом DTLB выполняется посещение 8 элементов, благодаря чему промахи DTLB случаются не так часто. При случайном порядке обхода промахи DTLB случаются реже, чем при постраничном, однако следует ожидать большого числа кэш-промахов, чем обусловлено значительно более высокое время t по сравнению с последовательным обходом [9]. Кроме того, при случайном доступе снижается быстродействие оперативной памяти [10]. Аналогичные результаты получены рядом исследователей для других современных процессоров с архитектурой x86_64 [6, 7, 11].| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4090 |
Версия для печати Выпуск в формате PDF (9.58Мб) Скачать обложку в формате PDF (1.29Мб) |
| Статья опубликована в выпуске журнала № 4 за 2015 год. [ на стр. 198-202 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Теоретический подход к управлению социально-техническими системами
- Системы автоматического управления объектами с запаздыванием: робастность, быстродействие, синтез
- Вопросы создания АСУ космическими полетами беспилотных аппаратов в околоземном пространстве
- Программный комплекс для расчета процесса нанесения покрытия в псевдоожиженном слое
- Алгоритмы оптимизации непрерывного процесса биосинтеза молочной кислоты
Назад, к списку статей