Авторитетность издания

Добавить в закладки
Следующий номер на сайте


An approach to data normalization in the internet of things for security analysis
Abstract:This paper analyzes a concept of the Internet of Things to develop a system for security incidents detection. System development requires effective methods and algorithms for preprocessing and storing high volumes of data from heterogeneous devices. The authors define a notion of a “thing”, formulate the basic information coming from the “thing” to an information system. In this paper the “thing” is considered as a data source with its own features. The authors apply the ETL (Extract Transfer Loading) technology to the Internet of Things data preprocessing. Heterogeneous devices provide a great number of different data types. To analyze this information in SIEM the system needs to show information and command messages from the Internet of Things in the event space. For this purpose it is necessary to adjust them to the same form, due to the fact that a researcher often needs to analyze various events together and one event may include various messages. This problem may be solved using metadata. The authors propose an approach that applies hierarchical directories to normalize high volumes of heterogeneous data from the Internet of Things. Hierarchical directories contain information about data source and their contents. The paper describes the basic metadata directories.
Аннотация:В данной статье авторы анализируют технологию Интернета вещей для разработки системы выявления инцидентов безопасности. Разработка системы требует создания эффективных методов и алгоритмов для предобработки и хранения больших объемов данных, поступающих от разнородных устройств. Авторы определили понятие «вещи», сформулировали, какая информация в общем случае поступает от «вещи» в информационную систему. В этой работе «вещь» определяется как источник данных, обладающий рядом свойств. Технология ETL (Extract Transfer Loading) была применена авторами к препроцессингу данных Интернета вещей. Разнородные устройства производят большое количество данных различного типа. Для анализа информации в SIEM-системе необходимо отобразить информационные и управляющие сообщения Интернета вещей в пространство событий. Для этого требуется привести их к единой форме, так как исследователю часто требуется анализировать различные события совместно, а одно событие может быть построено из различных сообщений. Эта задача может быть решена за счет использования метаданных. Авторы предлагают подход, использующий иерархические справочники для нормализации больших объемов гетерогенных данных, поступающих из Интернета вещей. Иерархические справочники содержат сведения об источниках данных и их содержимом. Основные справочники метаданных определены в работе.
| Авторы: Печенкин А.И. ( alexander.pechenkin@ibks.ftk.spbstu.ru) - Санкт-Петербургский политехнический университет Петра Великого (доцент), Санкт-Петербург, Россия, Ph.D, Полтавцева М.А. (maria.poltavtseva@ibks.icc.spbstu.ru) - Санкт-Петербургский политехнический университет Петра Великого (доцент), Санкт-Петербург, Россия, Ph.D, Лаврова Д.С. ( lavrova.daria@gmail.com) - Санкт-Петербургский политехнический университет Петра Великого (аспирант), Санкт-Петербург, Россия | |
| Keywords: etl, information security, etl, big data, normalization, internet of things |
|
| Ключевые слова: etl, информационная безопасность, etl, big data, нормализация, интернет вещей |
|
| Количество просмотров: 5107 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
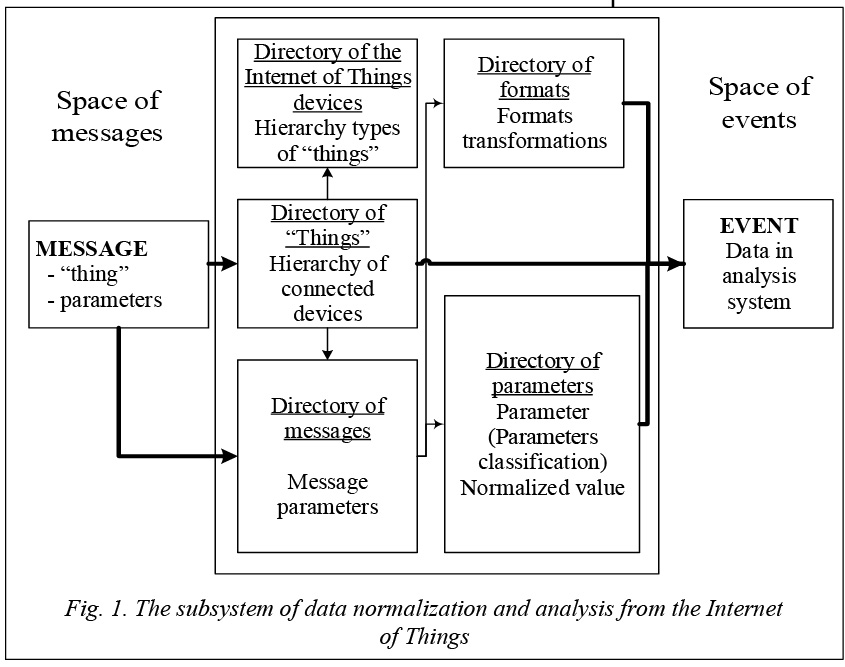
The Internet of Things is implemented everywhere. The number of devices intended for different purposes which can communicate over a network is constantly increases. The Internet of Things is an area that needs a close attention of security experts. Growing popularity of the Internet of Things has led to the fact that it is embedded in most areas of human activity so that its disruption of functioning may adversely affect life and health of many people. Heterogeneity of the Internet of Things does not allow development and integration of a unified cyber security solution. Also, applying of third-party mechanisms to ensure the security may not be possible in the case of the Internet of Things due to the fact that some “things” have little power and do not allow integration with third-party solutions. The most promising approach for providing cyber security in the Internet of Things is an approach that implements data analysis from heterogeneous devices. The complexity and heterogeneity of the subject area of the Internet of Things allow characterizing data from the “things” like Big Data. This complicates the requirements for the development of data analysis system to detect security incidents. The concept of Big Data in conjunction with high heterogeneity of the Internet of Things raises the problem of preprocessing and storage of analyzing data. The main contributions of this paper include analysis and selection of the most promising approaches to processing data from “things”. In order to solve this problem we define the concept of “thing” in the context of the Internet of Things, represent “things” as data sources, provide a processing circuit on the Internet of Things and select an approach based on the use of hierarchical directo- ries. Related work Many researchers and software vendors investigate and develop the technology of the Internet of Things. The concept of the Internet of Things is presented by the vendors of such systems as Oracle and Intel [1, 2]. Their solutions are aimed to collect data from a variety of connected objects and place them into storage for subsequent processing including ETL-packets. In accordance with [3], ETL stands for extracting, transforming and loading. This approach to data warehouse development is a traditional and widely accepted. In [3] the authors note that data are “extracted” from data sources (a line of business applications) using data extraction tools. It is then transformed using a series of transformation routines. This transformation process is mostly required by the data format of the output. Data quality and integrity checking is performed as a part of the transformation process, and corrective actions are built into the process. Transformations and integrity checking are performed in the data staging area. Finally, once data are in the target format, it is loaded into the data warehouse and then it is ready for presentation. Thus, according to the ETL process, a data warehouse architecture can be represented as the following components: - data source; - intermediate area; - data receiver (a storage or a database). The issue of using ETL for Big Data analysis and applying it in the Internet of Things is widely discussed. In [4] the authors claim that traditional technologies like ETL aren’t simply suited to handle the complexity and volumes inherent in Big Data. But for aggregation of the information from remote sensors into data warehouse or cloud-based data repository, it is better to reconsider whether ETL is truly needed. Authors note that in most situations where difficult transformations are not required, an ELT model is better for Big Data. In contrast, in [5] the authors itemize HP Big Data platforms where the ETL concept is applied, in particular, the HP Haven Big Data Platform and HP Vertica. Thus, we can conclude that for some problems associated with the Internet of Things, it is appropriate to use the concept of ETL. In this paper we also propose an approach using the ETL concept to preprocess data from the Internet of Things. The Internet and a “Thing” In accordance with a definition from [6], the objects of the Internet of Things are physical devices that have the following properties: - connection to the Internet; - ability to send messages in the Internet; - ability to receive messages from the Internet and to respond to them. The latter two aspects may be present in the general case, either individually or together in the Internet of Things.
· Rule-based correlation method of detection priori insecure events. · Both statistical and rule-based correlation method of potential security events detection. · Correlation and regression method of potential security events detection. · Event correlation method for investigation security incidents. The subject of considering is a part of the normalization and analysis subsystem which is responsible for “extraction, transformation and loading”. In this case, its function is mapping messages space from the Internet of Things to event space. For further work with data from the Internet of Things it is necessary to determine the concept of a “thing” in the context of this technology. In accordance with the definition [6], a “thing” is a physical device. However, to date this definition is inaccurate. Multiple applications working under different accounts, which should be identified by a system as separate “things”, can operate in one device. Considering an application as the basic concept of a “thing” may be wrong due to the fact that many devices can be operated without a dedicated set of applications, such as RFID sensor, garage door or others [7]. In fact we can say that some software also operates on these devices, but in our opinion, the identification of the concept of a “thing” with the term “software” is also contrary to the concept of the Internet of Things. This paper suggests defining a “thing” in the Internet of Things as an identifiable object that has a network connection to the Internet and is capable of sending or receiving messages. The concept of “things” is closely related to the concept of an “account”. Indeed, if we send an e-mail from an application, we use an e-mail account. But if we send a message from another account of the same application and same device, it must be interpreted as a message from another “thing”. In fact, the “account” is an identifier of the object “thing”. Moreover, for security challenges, when a message is received, we need to identify not only the “thing” which is a sender, but also the “thing” which the first one belongs to. For example, when sending messages from a smartphone, both the smartphone and the sending application should be identified as a “thing”. In general, each “item” generates the following types of information: - device information (status, measurements, etc.); - managing impact on other “things”; - error messages. In some cases, messages may implicitly refer to relevant categories. For example, an e-mail with a significant text refers more to status messages, while an e-mail message that launches a light or a fridge is a control action. In this vein, it is necessary to allocate error messages as mandatory, because this category may be critical for further analysis of security issues. An approach to normalization of large volumes of heterogeneous data coming from network distributed sources of the Internet of Things Basic steps of the proposed approach. The proposed approach includes the following steps: - processing incoming messages to retrieve their parameters; - the normalization of selected parameters of the message; - assigning metadata. The first step is to process incoming messages to retrieve their parameters, since parameters are significant characteristics of each device of the Internet of Things and can represent both performance and status of the device. The second step of the approach is normalization of the data from the devices of the Internet of Things. It is performed after a parsing format of messages received from the device. In order to select one of the formats of the analyzed segment it is advisable to analyze an investigated segment of the Internet of Things for prevalent data type, thereby to minimize the cost of pre-processing data. The third step of the proposed approach is metadata assigning. Metadata are structured data that represents characteristics of entities. Metadata is used for identification, search, evaluation, management of entities. Each device may generate a large number of different messages that can vary both in the submitted data format (although semantically carry the same information) and in the message format. In addition, each of these devices has its own format and sends messages to the Internet. However, processing these data is important for understanding the purpose of this indicator for a particular device (or, depending on the tasks of analysis, particular devices). Therefore, messages from each device should be recognized and placed in the storage based on the type of the device and data format. After analyzing the messages from the Internet of Things, we picked out the following features: - focus on a particular device (“thing”); - extensibility of formats and devices (but much less than the data flow); - diverse input format of the same physical parameter; - processing rules according to the input data from the device; - a large amount of input data; - AN intense data flow. In terms of future security analysis it is important to understand not only how the event occurred, but also what the “thing” that generated this event was. Where was the failure fixed or by whom and to whom was the control message sent. In the analysis of incoming messages we must highlight their common characteristics which are a subject to fix, evaluate and use. These common features include: - the data source (“thing”); - message format. All other information can be extracted from the message to different extent if the system knows the format in advance. Thus, the data processing system must store a list of formats which are associated with both specific parameters and specific devices. Moreover, a normalized value and the transformation rules of input data for this format must be stored for each indicator. To process the messages it is necessary to perform: - determination of a device that generates a message; - determination of a plurality of possible formats for a device; - a definition of a message format. In order to parse the message properly and allocate its parameters it is required to interpret the format automatically. There are the following groups of message formats: - marked messages; - messages with a separator; - fixed size messages; - mixed messages. The most common example of marked messages is an XML message format. This format is also used to represent data from RFID-readers. There are two ways for providing significant information for this format: in tags values and in tags attributes. Opening and closing tags are signs for values. In general, there may be several values under a single tag. There is a name of the tag to which the attribute belongs, as well as an attribute name because there can be several. Usually, opening and closing tags for a message (parameter) are the same, except the closing tag “/”, even if it contains nested parts. As a result, we need two text boxes in order to parse these messages: for an opening and a closing tag (the second can be used as a text field for the character-separator) and two marker fields. There is a common set of message formats in which parameters are separated from each other by different dividers. They belong to the family of formats “delimiter-separated values” (DSV) [8]. They are the formats that use delimiters as demarcation values. In particular, the common formats are CSV and TSV [9]. In case of messages with a delimiter we need two numeric fields which determine the order of parameter and the text box for delimiter storing. One of the most common variants of machine data are fixed size messages. ICMP (Internet Control Message Protocol) packages may be exemplified [10]. In this case the task of parsing the algorithm is to select a relevant field as a parameter. However, there may be situations when a format of a message part depends on the initial data. For example, in ICMP-packet data depends on the values of the parameters “code” and “type”. To retrieve such information it may be required to use more complex mechanisms discussed below in the section of mixed messages. In some cases messages may be referred to the mixed type and may include elements of several dimensions of standard formats. Despite the fact that they are extremely rare in the communications from machine devices, this approach could be applied more widely in the future in connection with the active development of description languages of different structures. It is necessary to consider it. As an example, XML-data messages may be taken as messages with a fixed size and language message YAML. YAML is a data serialization format that is conceptually close to markup languages. However, it focuses on ease of input-output typical data structures of many programming languages [11]. In fact, the format involves various combinations and nesting of typical elements: - sequence (block format); - sequence (one-line format); - comparison (block format); - comparison (one-line format). From the incoming message we extract and classify information about “things” that generate the message and its parameters. Then, on the basis of reference data about a “thing” we carry out the message type (format) and the required parameter normalization of the received data. The resulting information is provided to the system of analysis as an event. The normalization of selected parameters of the message and metadata assigning. Here we consider normalization as an adduction of values to the normalized, standardized mean for that particular type (parameter). Normalization of messages is closely related with the selected direction for further security analysis of messages. Speaking of safety analysis of data, we assume the development of security incidents detection system that is based on the event analysis, where the messages generated by “things” are represented as events. This approach is inspired by the concept of SIEM-systems, which are tools for managing security information and security events [12]. These systems are capable of detecting security incidents using data analysis. Standard SIEM-systems work with events from various network security solutions using different variations of event correlation. There are no integrated solutions for cyber security in the Internet of Things. Thus, it is advisable to collect data from devices (“things”) and to form events for further analysis. In general, it is required to use a special language tool that transforms parameters or develop simple ETL procedures for each transformation. ETL is a set of methods that implements the process of transferring raw data from various sources to analytical applications or to the data warehouse. In this case, a field can be isolated for the procedure’s name. If there is a need in transformation parameters, this procedure can be called. Such approach would create an extensible library of procedures without using new language means. Metadata are used to organize effective work with normalized data. By analogy with the ETL-processes, metadata structuring can be implemented based on the patterns of incoming messages and hierarchical directories. It is proposed to use the following directories: - a directory of “things”; - a directory of Internet of Things devices; - a directory of messages from the Internet of Things devices; - a directory of messages' parameters; - a directory of formats of messages' parameters. A directory of “things” is intended to identify each particular “thing”. Thus, in order to process messages from the device it is necessary to understand at least two facts: - the type of the device for the analysis of the possible formats of messages; - the geographic and/or organizational positioning of the device for the analysis of input data. A device type is required. This will allow avoiding mistakes when searching a type of a message using formats enumeration. An incorrect identification format may be the cause of loss or misinterpretation of the data. When types of devices are different, there is no guarantee that there are disjoint sets of message formats for each of them. A geographical (organizational) position is not necessary to determine. However, this fact may be necessary for further safety analysis. Such reference may not be required for the system that conducts an analysis only on aggregated data. Generally, references should have a hierarchical structure, because “things” can be “embedded” in other facilities that also act as a thing. For some security analysis tasks it may be critical to identify not only the “thing”, but also its container. Min addition, problems can be identified by comparison of a geographical position, for example, if two “things” from one device show different location. This may indicate both an error in their functioning and a security breach. A directory of Internet of Things devices can be used for rapid typification of new connected devices or the devices, details of which are recorded in a system of data processing and analysis. The main tasks in relation to directories are supposed task of searching directories path from the root to the node directory and the task of the withdrawing all descendants of the node directory. Apart from these main tasks, there can also be tasks of data adding and data updating. Moreover, each device (“thing”) is associated with a list of messages; each list is associated with a set of parameters extracted from this message. This creates a directory of messages from the Internet of Things devices, as several “things” can send messages of the same type and store their description several times for each particular thing.
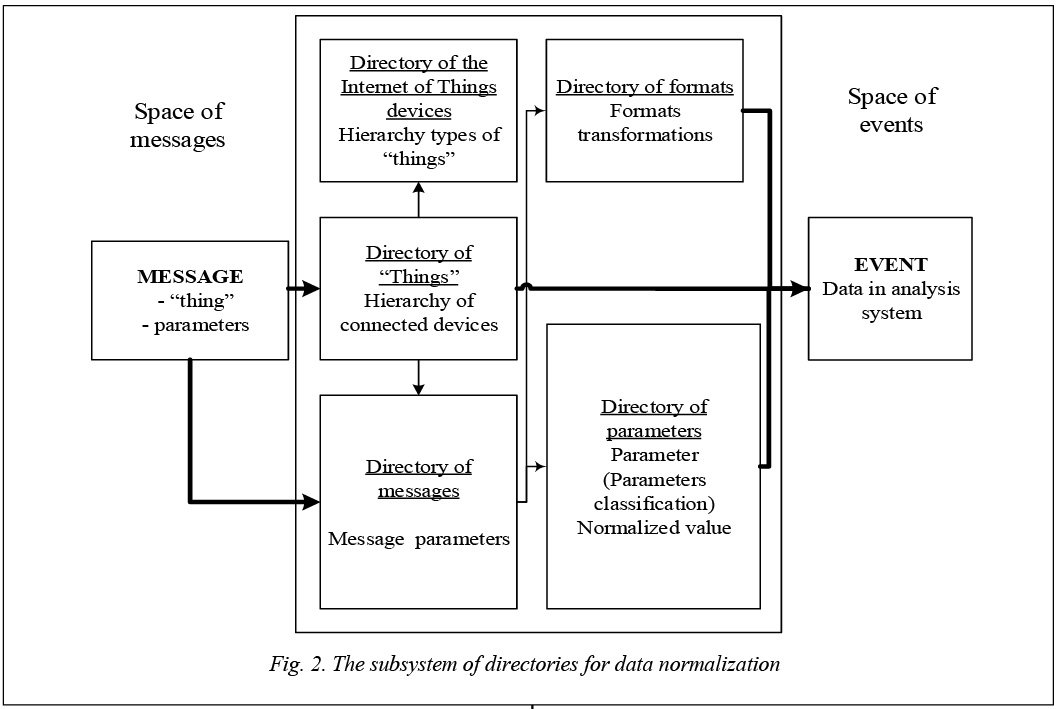
Each parameter of message has a certain format. A directory of formats should contain information about possible formats for each parameter, as well as about types of changes required to bring the received in this format data to a normalized form. Figure 2 represents the subsystem of directories for data normalization. Thus, the space of messages incoming to the system of analysis is displayed in the event space. In this paper we propose an approach to normalization and storing data from the Internet of Things. This approach aims to a future security analysis of data that are represented as events. The novelty of the proposed approach is in applying ETL concepts to the Internet of Things, in particular, in application of hierarchical directories. As a result, we defined the architecture of the Internet of Things for an information security analysis system. We also formulated the notion of a “thing” as a source of messages in the Internet of Things. We defined the main characteristics of the information flow coming from “things” or from message space. The paper allocated significant structural data, such as messages with a particular format that is generated by a device and as information about a “thing”. We proposed architecture of the normalization of messages system based on a set of directories and classifiers. The main directories and their purposes were defined. Our further work assumes developing architectural elements and their optimization for the subject area. References 1. Oracle Internet of Things. Solutions for a Connected World. Available at: http://www.oracle.com/us/solutions/internetofthings/ overview/index.html (accessed October 12, 2015). 2. The Intel® IoT Platform: Secure, Scalable, Interoperable. Available at: http://www.intel.eu/content/www/eu/en/internet-of-things/iot-platform.html?_ga=1.235825473.1342233398.1439457 129 (accessed October 12, 2015). 3. ETL vs ELT. Available at: http://www.dataacademy.com/ files/ETL-vs-ELT-White-Paper.pdf (accessed October 12, 2015). 4. Releasing the Value Within the Industrial Internet of Things. Available at: http://www.odbms.org/wp-content/uploads/ 2014/04/Releasing-the-Value-Within-the-Industrial-Internet-of-Things-_WP.pdf (accessed October 12, 2015). 5. Capitalize on Big Data in financial services. Available at: http://www8.hp.com/h20195/V2/getpdf.aspx/4AA4-8165ENW. pdf?ver=1.0 (accessed October 12, 2015). 6. Internet of Things. Available at: http://blogs.gartner.com/ it-glossary/internet-of-things/ (accessed October 12, 2015). 7. Lavrova D.S., Pechenkin A.I. Security incidents detection in the Internet of Things. Problemy informatsionnoy bezopasnosti. Kompyuternye sistemy [Information Security Problems. Computer Systems]. 2015, no. 2, pp. 80–85. 8. Delimiter Separated Values. Available at: http://c2.com/ cgi/wiki?DelimiterSeparatedValues (accessed October 12, 2015). 9. Tab Separated Values. Available at: https://www.cs.tut.fi/ ~jkorpela/TSV.html (accessed October 12, 2015). 10. Internet control message protocol. Available at: https:// www.ietf.org/rfc/rfc792.txt (accessed October 12, 2015). 11. YAML. Available at: http://yaml.org/ (accessed October 12, 2015). 12. Security information and event management (SIEM). Available at: http://searchsecurity.techtarget.com/definition/security-information-and-event-management-SIEM (accessed October 12, 2015). |
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4152 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
| Статья опубликована в выпуске журнала № 2 за 2016 год. [ на стр. 83-88 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик: