Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Разработка системы разрешения анафоры на основе методов машинного обучения
Аннотация:В работе предложен и реализован метод разрешения анафоры местоимений третьего лица в текстах на русском языке. Задача нахождения искомых пар «анафор–антецедент» рассматривается как задача бинарной классификации. Предварительно осуществляется морфологический и синтаксический анализ текста. Для морфологического анализатора использовалась библиотека pymorphy2. Синтаксический анализ производился при помощи MaltParser. Непосредственно сам алгоритм разрешения анафоры состоит из трех этапов. Сначала происходит поиск всех местоимений, затем составляется множество потенциальных антецедентов и осуществляется выбор наиболее подходящего кандидата. Компонент создания множества кандидатов в антецеденты основан на применении дистанционного, морфологического и синтаксического фильтров. В качестве алгоритма классификации выбран алгоритм машинного обучения Random Forest. Классификатор выбора наиболее вероятного кандидата учитывает 78 различных признаков. Проведены исследования по проверке эффективности данного метода, доказывающие применимость разрабо-танного подхода. По результатам тестирования можно заметить, что качество анализатора улучшается, когда не учитывается морфологический фактор падежа. Также можно отметить, что на наборе признаков, не содержащем падежи, меньшее влияние на конечный результат оказывает количество взятых для расчета деревьев. При создании систем разрешения анафоры основные проблемы заключаются в следующем. Во-первых, поиск анафорических отношений лежит в области семантики и поэтому трудно поддается формализации. Во-вторых, существуют особенности русского языка, такие как развитая морфология, морфологические и синтаксические неоднозначности, которые отрицательно сказываются на результате.
Abstract:The paper proposes and implements a method for the anaphora resolution of third person pronouns in Russian texts. The problem of finding the true pairs “anaphor-antecedent” is considered as a binary classification problem. Initially, the authors perform morphological and syntactic analysis of the text. The morphological analyzer used the pymorphy2 library. The parsing has been performed using MaltParser. The algorithm of anaphora resolution itself consists of three stages. First stage includes searching for all pronouns, then there is a compilation of many potential antecedents, and finally the most suitable candidate is selected. The component of creating a set of candidates for antecedents is based on using distance, morphological and syntactic filters. Classification uses the Random Forest algorithm. The anaphoric classifier takes into account 78 different features. The authors performed a series of experiments in order to prove the effectiveness of the proposed method. They showed that that the quality of the analyzer improves if we do not take into account the morphological case. It can also be noted that the number of trees taken for calculation has a lesser effect on the final result when taking a feature set without cases. The paper considers the main difficulties in developing the anaphora resolution systems. First, the search for anaphoric relations is in the semantic domain, and therefore it is difficult to formalize. Second, there are some features of the Russian language, such as developed morphology, morphological and syntactic ambiguities, which adversely affect the result.
| Авторы: Соколов А.В. (a23sokolov@gmail.com) - Новосибирский государственный университет (магистрант), Новосибирск, Россия, Батура Т.В. (tatiana.v.batura@gmail.com) - Институт систем информатики им. А.П. Ершова СО РАН (старший научный сотрудник), г. Новосибирск, Россия, кандидат физико-математических наук | |
| Ключевые слова: анализ текстовой информации, анафорический классификатор, машинное обучение, методы классификации, антецедент, анафора |
|
| Keywords: analysis of text information, anaphoric classifier, machine learning, classification methods, antecedent, anaphora |
|
| Количество просмотров: 8573 |
Статья в формате PDF Выпуск в формате PDF (21.91Мб) Скачать обложку в формате PDF (0.59Мб) |
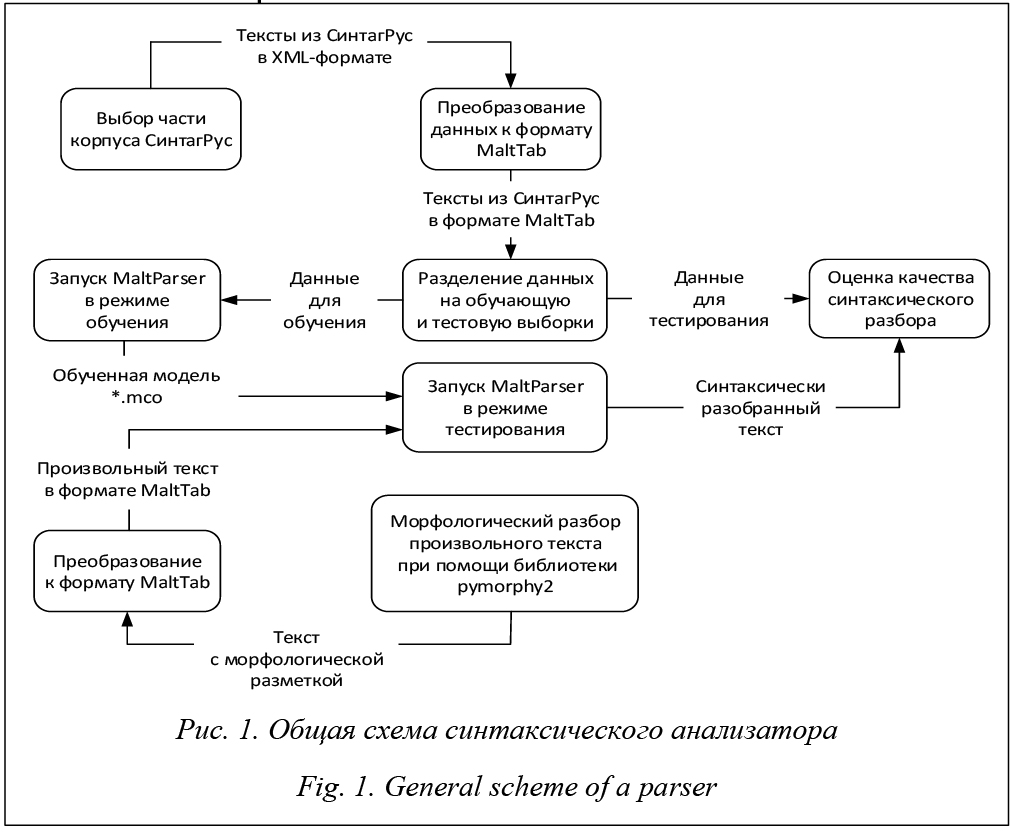
Из-за увеличивающихся объемов информации большую значимость приобретают такие задачи, как извлечение информации, машинный перевод и информационный поиск, для которых важна автоматизация тех или иных аспектов референции. Но, несмотря на актуальность данной темы, развитых разработок для русского языка существует не так много, и они значительно уступают по качеству ручной работе лингвистов. В связи с этим необходимо создание новых, более эффективных методов решения данной проблемы. Анафора – использование языковых выражений, которые могут быть проинтерпретированы лишь с учетом другого, как правило предшествующего, фрагмента текста. В данном случае речь идет не о повторе всего выражения в целом, а о сокращенном воспроизведении в тексте того, что было представлено ранее в виде полного языкового выражения. Например, Космонавт вернулся на борт станции. Он сообщил, что чувствует себя нормально. Антецедентом называется первый член анафорического отношения, а анафóром (или анафорическим элементом) – второй. В приведенном примере антецедентом является слово «космонавт», а анафором – местоимение «он». На основании того, какой частью речи выражен анафор, выделяют именную и местоименную анафоры. В случае именной анафоры анафор выражен именной группой. Например, Юрий Гагарин вер- нулся на борт станции. Космонавт сообщил, что чувствует себя нормально. Если анафор выражен местоимением или местоименным словом, то такой вид анафоры является местоименным. Пример местоименной анафоры уже был приведен. Процесс создания системы разрешения анафоры трудоемкий, так как существуют несколько проблем: во-первых, поиск анафорических отношений лежит в области семантики и поэтому трудно поддается формализации; во-вторых, русский язык имеет такие особенности, как развитая морфология, морфологические и синтаксические неоднозначности и прочее. Как справедливо отмечено в работе [1], при анализе текстов наибольшую трудность представляет не разбор слов по отдельности, с этим отлично справляются большинство морфологических анализаторов для большинства естественных языков, а анализ отношений, то есть связей между словами. В настоящее время ведется работа над созданием системы автоматического разрешения анафоры для местоимений третьего лица, поскольку именно этот вид является наиболее распространенным. Обработка текста в данной системе осуществляется в несколько этапов: морфологический анализ, синтаксический анализ и непосредственно раз- решение анафоры. Существующие средства автоматического разрешения анафоры Один из подходов к разрешению анафоры, основанный на правилах, предложен в работе [2]. Основная идея состоит в том, чтобы, помимо разметки частей речи, учитывать информацию об именных группах, предшествующих анафоре на расстоянии двух предложений. Выбираются только те именные группы, которые согласуются с анафорой в роде и числе. Далее к ним последовательно применяется набор правил. Для русского языка принцип обнаружения анафорических отношений с использованием правил описан в работе [3]. Однако исследование в основном направлено на изучение типов замещения, использующихся в различных видах общественно-политических текстов, а не на сравнение точности определения анафорических связей. Для решения задачи определения анафоры в работах [4–6] описаны эксперименты с применением методов машинного обучения, в частности метода опорных векторов. Так, в работе [5] отмечается: если, помимо SVM, дополнительно использовать набор правил, то достигается наилучшая точность 0,52–0,59. В исследовании [6] обнаружено, что дополнительные знания о семантических ролях анафоры и антецедента способны улучшить качество решения задачи на 0,1–6,6 %. В [7] описан подход к разрешению местоименной анафоры при анализе мнений пользователей на основе машинного обучения. Авторы использовали 16 признаков, разделив их на три категории: анафорическое местоимение, кандидат в антецеденты и характеристика отношения. Исследование проводилось для баскского языка на сравнительно небольшом корпусе, содержащем 50 000 слов и 249 анафорических местоимений. В эксперименте сравнивались различные методы машинного обучения: метод опорных векторов (SVM), многослойный перцептрон (MLP), метод Байеса (NB), метод k-ближайших соседей (kNN), ансамбль решающих деревьев (RF), комбинированный подход на основе метода Байеса и деревьев решений (NB-Tree). Сложность автоматического разрешения анафоры заключается в том, что процесс предварительной обработки текста, как правило, включает в себя последовательность действий: определение частей речи и морфологических характеристик слов, выделение именных групп, синтаксический и поверхностно-семантический разбор. Каждый шаг удается автоматизировать с определенной точностью, погрешности накапливаются, а это, в свою очередь, плохо сказывается на конечном результате. Поэтому повышение качества работы подобных алгоритмов затруднительно. В то же время интерес к данной проблеме в последние годы не ослабевает как в зарубежной, так и в отечественной научной среде. Авторами данной статьи предложен и реализован метод разрешения анафоры местоимений третьего лица, проведено экспериментальное исследование для оценки эффективности предложенного метода. Построение частей системы, отвечающих за морфологический и синтаксический анализ Для морфологического анализатора была использована распространенная библиотека pymorphy2 [8], написанная на языке Python (версии 2.7 и 3.3+). Решающими факторами при выборе библиотеки были поддержка русского языка, высокая скорость работы (100 000 слов/сек.) и использование словаря OpenCorpora для реализации. Библиотека предоставляет широкий функционал: - приводит слово к нормальной форме, например, «люди ® человек», «гулял ® гулять»; - ставит слово в нужную форму, например, заменяя форму единственного числа на множественное, меняет падежные формы слова и т.д.; - возвращает грамматическую информацию о слове (число, род, падеж, часть речи и т.д.). Опишем процесс построения синтаксического анализатора подробнее. Построение синтаксического анализатора. Существуют два основных подхода к созданию синтаксических парсеров: подход, основанный на правилах (rule based), и машинное обучение с учителем (supervised machine learning). Рассмотрим каждый из них подробнее. Метод, в основе которого лежат правила, дает наибольшую точность, вследствие чего он применяется в большинстве коммерческих систем. Основная идея заключается в создании набора правил, позволяющих определить, как проставлять связи в предложении. Например, в предложении Папа мыл машину можно применять следующие правила (предположим, что мы уже сняли все неоднозначности и точно знаем грамматические категории слов). 1. Слово «мыл» имеет характеристики: единственное число, прошедшее время, мужской род. Вершина предложения (в английской терминологии – root). 2. Слово «папа» имеет характеристики: именительный падеж, мужской род, единственное число. Должно зависеть от глагола «мыл», тип связи между словами должен быть «субъект». 3. Слово «машину» имеет характеристики: винительный падеж, женский род, единственное число. Должно зависеть от глагола «мыл», тип связи должен быть «объект». В системе может быть множество подобных приведенному выше правил, а также антиправил, указывающих, когда не нужно проставлять связи. Например, если у существительного и глагола раз- личаются род или число, то между ними нет связи. Также существуют правила третьего типа, которые указывают, какую пару слов следует предпочесть, если возможны несколько вариантов. Например, в предложении Папа мыл окно и «папа», и «окно» могут выступать в качестве субъекта, однако мы можем предпочесть предстоящее глаголу слово, а не последующее. Из описанного выше можно заметить, что такой подход очень ресурсоемок, так как для создания парсера необходима хорошая команда лингвистов, которой потребуется буквально описать весь русский язык. Поэтому в работе будем применять второй подход – машинное обучение с учителем. Идея парсера, использующего машинное обучение, заключается в следующем. На вход классификатору подается много примеров с правильными ответами, на которых система должна обучиться самостоятельно. Чтобы обучить синтаксические классификаторы, в качестве данных для обучения используют специально размеченные корпуса, коллекции текстов, в которых размечена синтаксическая структура. Предложение, взятое для примера, может быть размечено так: 1 Папа сущ.им.ед.муж. 2 субъект 2 мыл глаг.ед.муж.прош. 0 – 3 машину сущ.вин.ед.жен. 2 объект В этом формате каждая строка описывает отдельное слово в виде записей. Для каждого слова нужно хранить следующие данные: - номер слова в предложении (1); - словоформа (папа); - грамматические категории (сущ.им.ед.муж.); - номер главного слова (2); - тип связи (субъект). Существует несколько открытых парсеров, которые можно обучить для работы с русским языком. Был выбран один из них, а именно MaltPar- ser [9, 10]. Этот пакет включает в себя различные алгоритмы синтаксического анализа, в том числе алгоритмы Нивре и Ковингтона, а также реализации нескольких методов машинного обучения для предсказателей переходов. Благодаря своей эффективности и производительности MaltParser на данный момент является одним из наиболее широко используемых синтаксических анализаторов. Исследования по применению MaltParser проводились для многих языков, в том числе и для русского [11, 12]. Пакет может использоваться с различными алгоритмами обучения, с версии 1.3 по умолчанию поддерживаются два встроенных алгоритма обучения: LIBSVM [13] и LIBLINEAR [14]. По результатам обучения и тестирования второй алгоритм проявил себя заметно лучше, поэтому впоследствии все вычисления производились с ним. Для обучения синтаксического классификатора использовался размеченный корпус СинТагРус, который входит в состав НКРЯ (данный корпус за- крыт и предоставляется только для исследователь- ских целей). Корпус представляет собой набор текстов, размеченных в формате XML, с информацией о принадлежности каждого слова к части речи, соответствующих грамматических признаках, нормальной форме слова, синтаксических связях внутри предложения. Для обучения синтаксичского анализатора необходимо перевести размеченные данные в формат malttab. Для этих целей был написан скрипт, который читает XML и выдает нужный формат, при этом нормализуя грамматические категории. Результат преобразования следующий: Здесь ADV 4 обст уместнее ADV.comp 4 обст всего S.gen.n.sg 2 сравнит провести VINF 0 ROOT аналогию S.acc.f.sg 4 1-компл с PR 5 1-компл законами S.ins.m.pl 6 предл физики S.f.gen.sg 7 квазиагент
Одним из ключевых факторов, влияющих на оценку качества синтаксического анализатора, является результат морфологического парсера с использованием pymorphy2. Например, слово «ученый» в зависимости от контекста может быть как прилагательным, так и существительным, то есть является субстантивированным прилагательным (когда прилагательные переходят в разряд существительных). В подобных случаях неправильно определенная часть речи на уровне морфологического анализа влечет за собой ошибки на синтаксическом уровне. Также есть вероятность встретить в текстах слова-омонимы, частным случаем которых являются омоформы. Яркий пример – слово «печь», которое в зависимости от контекста выступает как существительное или глагол. Приняв ошибки такого рода, на основе предложенной модели получим результаты, представленные в таблице 1. В таблице показаны результаты синтаксического анализатора MaltParser, обученного на 1/7 части корпуса СинТагРус. Для оценки качества результатов произведено несколько замеров, в таблице отражены усредненные значения. Для оценки полученной модели произведены замеры на морфологической разметке СинТагРус, которые дали неплохие результаты. Затем произведены замеры с использованием морфологической разметки из pymoprhy2. На основании результатов, отраженных в таблице 1, можно сделать вывод, что точ- ность синтаксической разметки ухудшается.
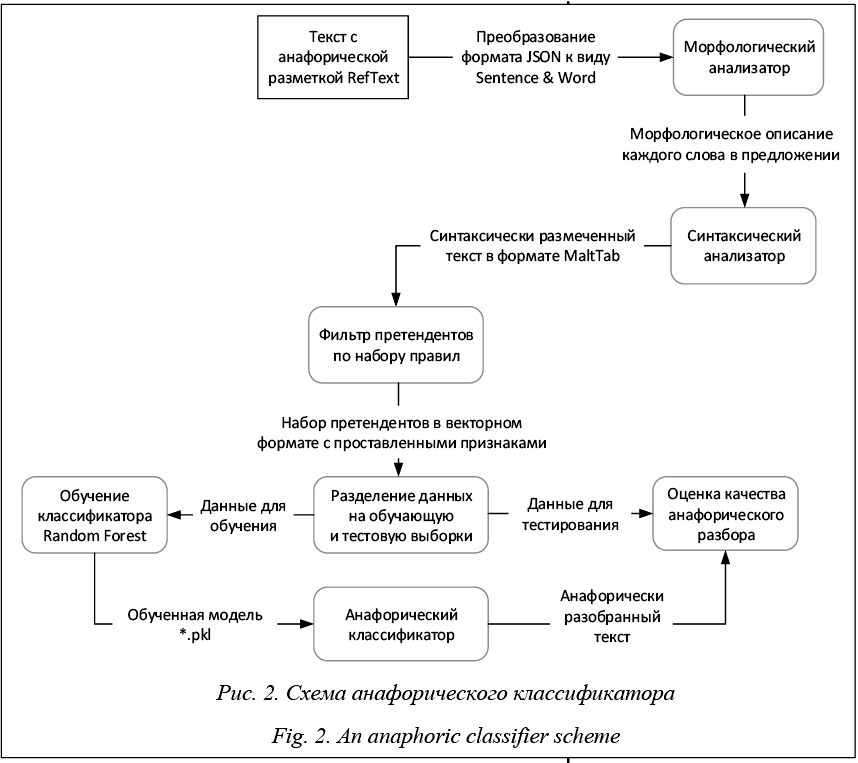
Построение анафорического классификатора В первую очередь происходит предобработка входного текста: он разбивается на предложения, после этого каждое предложение анализируется морфологическим и синтаксическим парсерами, результаты анализа для предложений сохраняются в файл и используются на следующих этапах. Затем анализатор просматривает текст слева направо, останавливаясь на каждом найденном местоимении. Для каждого местоимения текст просматривается в обратном направлении, в процессе чего составляется множество потенциальных антеце- дентов (кандидатов). В качестве кандидатов высту- пают морфологические интерпретации слов, то есть само слово и его морфологические характеристики. Как только такое множество составлено, анализатор продолжает просмотр текста в поисках следующего местоимения, затем анализатор выбирает из набора признаков единственного кандидата, которого считает верным антецедентом для данного местоимения. Таким образом, описываемый метод состоит из следующих этапов: - поиск местоимения; - составление множества потенциальных антецедентов; - выбор наиболее подходящего кандидата. Создание множества кандидатов. Основная цель данного этапа – создание множества морфологических интерпретаций, которые могут при некоторых условиях быть антецедентом для данного местоимения. Из полученного множества на следующих этапах выбирается единственный антецедент, он и будет признан верным. Такое множество должно удовлетворять критерию полноты, содержать в себе верный антецедент, чтобы у алгоритма выбора на последующих этапах была возможность его выбрать. В то же время представляется разумным ограничить пространство выбора и не включать в множество заведомо неподходящих кандидатов. Данный этап будем рассматривать как набор фильтров, которые будут применяться ко всем морфологическим интерпретациям, предшествующим в тексте местоимению. Каждый из фильтров должен либо отфильтровать кандидата, либо оставить его в рассматриваемом множестве. Фильтр расстояния. Зачастую местоимение и антецедент находятся достаточно близко друг к другу. Хотя при тестировании и написании этого правила были зафиксированы случаи, когда антецедент и местоимение находились на расстоянии 8 предложений, тем не менее, большинство антецедентов укладываются в довольно маленькую окрестность местоимения. После проведения ряда экспериментов было решено ограничить рассматриваемое множество предложений на поиск претендентов до трех. Морфологический фильтр. Морфологический фильтр, реализованный в данной работе, можно сформулировать с помощью набора правил: - претендентами могут стать только существительные; - кандидат и претендент должны быть согласованы в роде и числе. Синтаксический фильтр. Синтаксический фильтр, реализованный в данной работе, основан на обобщенных синтаксических ограничениях из статьи [15]. В работе показана их эффективность. Ограничения сформулированы как набор условий на взаимное расположение в синтаксическом дереве местоимения и кандидата. Условия описывают невозможные для местоимения и антецедента отношения, то есть, если хотя бы одно из условий выполняется, кандидат отвергается. Для упрощения работы фильтра было решено объединить эти правила в одно. Чтобы претендент удовлетворял условиям фильтра, нужно, чтобы антецедент и местоимения принадлежали к разным Root-группам. Пример, удовлетворяющий условиям фильтра: Маша любит мороженое. Потому что оно вкусное. 1) Глагольная группа любит. 2) Root-группа вкусное. Пример, не удовлетворяющий условиям фильтра: Маше она нравится. 1) Глагольная группа нравится. 2) Root-группа нравится. На этом этапе получен набор претендентов, удовлетворяющих условиям фильтра, это множество имеет небольшие размеры для конкурентоспособной работы классификатора. Преобразование набора признаков к векторному виду. Затем на полученном множестве кандидатов ставится задача преобразования множества признаков в векторную форму. Набор признаков переводится в векторный формат по определенным правилам. Расстояние в словах. Для каждого претендента высчитывается расстояние в словах до местоимения. В зависимости от этого расстояния вектор заполняется единицами. Были выделены три расстояния для фиксации их в векторе: - от 10 слов включительно; вектор [1, 0, 0]; - от 10 до 30 слов включительно; вектор [0, 1, 0]; - от 30 слов; вектор [0, 0, 1]. Претенденту может соответствовать только один вектор с описанием в векторной форме. Морфологические признаки. Из морфологических признаков, используемых в модели, для классификации учитывается только падеж: - именительный [1, 0, 0, 0, 0, 0]; - родительный [0, 1, 0, 0, 0, 0]; - дательный [0, 0, 1, 0, 0, 0]; - винительный [0, 0, 0, 1, 0, 0]; - творительный [0, 0, 0, 0, 1, 0]; - предложный [0, 0, 0, 0, 0, 1]. Синтаксические признаки. В СинТагРус представлены четыре группы синтаксических отношений (СинтОтн) [16]. 1. Актантные СинтОтн. Главной особенно- стью актантных СинтОтн является то, что они связывают предикатное слово [X] со словом [Y], заполняющим некоторую синтаксическую валентность этого предикатного слова. Всего 25 вариантов отношений. 2. Атрибутивные СинтОтн. Главной особенностью атрибутивных СинтОтн является то, что они связывают некоторое слово [X] со словом [Y], которое выражает при X значение невалентного атрибута – в самом широком смысле этого слова. Всего 31 вариант отношений. 3. Сочинительные СинтОтн. В принятой в данном корпусе системе синтаксических отношений сочинительные отношения принципиально не отличаются от подчинительных – и те, и другие связывают главный член конструкции с зависимым. Всего 5 вариантов отношений. 4. Служебные СинтОтн. Служебные СинтОтн связывают два элемента, синтаксически тесно связанные друг с другом. Часто члены таких конструкций – фактически части одного сложного слова. Всего 8 вариантов отношений. Суммарно мы получаем набор из 69 видов отношений. Так как каждое слово может иметь только один тип отношений в предложении, вектор синтаксических признаков X будет иметь вид X = [x1, x2, … x69], где xi Î {0, 1} и Порядковый номер i определяется с помощью позиции в массиве отношений для каждого слова в зависимости от его синтаксических отношений внутри предложения. Далее ставится задача комбинирования всех перечисленных признаков путем конкатенации векторов. Итоговый вектор Z представляется в виде Z = [z1, z2, …, z78], где zi Î {0, 1} и Таким образом, суммарное количество рассматриваемых признаков равно 78. Описание работы классификатора. Для обучения анафорического классификатора использовался анафорически размеченный корпус текстов на русском языке, разработанный в Институте системного анализа ФИЦ ИУ РАН [6]. На основе размеченного корпуса текстов составляется обучающая выборка и строится бинарный классификатор, относящий с некоторой вероятностью кандидата к одному из двух классов: является антецедентом, не является антецедентом. Обучающая выборка составляется следующим образом. Размеченные тексты просматриваются анализатором, для каждого местоимения составляется множество потенциальных антецедентов, для каждого кандидата из множества вычисляются описанные выше признаки. Далее вектор признаков каждого из кандидатов заносится в обучающую выборку с классом 1, если данный кандидат является антецедентом, и с классом 0 в противном случае. В качестве алгоритма классификации был выбран алгоритм машинного обучения «решающий лес» (Random Forest) [17], основанный на деревьях принятия решений. Сам по себе процесс построения каждого дерева можно описать следующим образом. Рассмотрим выборку X. Пусть xj – j-й признак; t – порог значения признака; xj £ t Решающий лес (Random Forest) – ансамблевый алгоритм, представляющий собой множество решающих деревьев. Идея случайного леса состоит в том, чтобы выбрать наилучший признак j не из всех возможных признаков, а из случайного подмножества признаков некоторой заданной размерности. Выбор этого подмножества признаков осуществляется каждый раз при очередном разбиении вершины. Таким образом, каждое дерево gk(x) строится на своей обучающей выборке X¢. В задаче классификации решение о выборе лучшего признака, по которому будет происходить разбиение, выбирается голосованием по большинству: Данный подход к построению ансамбля моделей иногда называют бэггингом (bagging от Bootstrap Aggregating). Основная сложность его применения заключается в том, чтобы построенные модели действительно оказались независимыми.
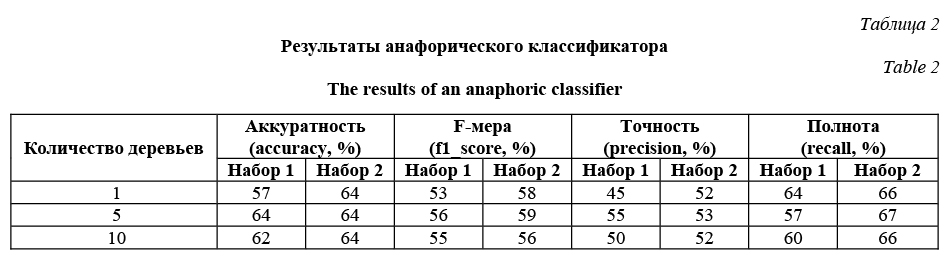
Полученные результаты и выводы Суммарная точность считалась как процент правильно предсказанных антецедентов для местоимений, на которых производилось тестирование (табл. 2). Исследования проводились на следующих наборах признаков: Набор 1. Все признаки; Набор 2. Без падежей. Проведенное тестирование показало, что описанный в работе метод может успешно применяться для разрешения местоименной анафоры, а также то, что качество анализатора улучшается, когда не учитывается морфологический фактор падежа. Заключение В данной работе предложен и реализован метод разрешения анафоры местоимений третьего лица в текстах на русском языке. Разработан алгоритм разрешения местоименной анафоры, включающий в себя следующие компоненты: - компонент создания множества кандидатов в антецеденты, основанный на применении набора фильтров: дистанционного, морфологического, синтаксического; - классификатор выбора наиболее вероятного кандидата из множества предложенных на основе ряда признаков: дистанционного, морфологического, синтаксического. Были проведены исследования по проверке эффективности данного метода, доказывающие применимость разработанного подхода. Благодарность Авторы работы выражают благодарность коллективу создателей синтаксически размеченного корпуса СинТагРус, разработанного в Институте проблем передачи информации РАН, и коллективу создателей анафорически размеченного корпуса текстов на русском языке, разработанного в Институте системного анализа РАН. Литература 1. Шелманов А.О. Исследование методов автоматического анализа текстов и разработка интегрированной системы семантико-синтаксического анализа: дисс. … канд. тех. наук. М.: 2015. 210 c. 2. Barbu C., Mitkov R. Evaluation tool for rule-based anaphora resolution methods. Proc. 39th Annual Meeting on Association for Computational Linguistics, 2001, pp. 34–41. 3. Абрамов В.Е., Абрамова Н.Н., Некрасова Е.В., Росс Г.Н. Статистический анализ связности текстов по общественно-политической тематике // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: тр. 13 Всерос. науч. конф. Воронеж, 2011. C. 127–133. 4. Толпегин П.В. Автоматическое разрешение кореференции местоимений третьего лица русскоязычных текстов: автореф. дисс. … канд. тех. наук. М., 2008. 241 с. 5. Protopopova E.V., Bodrova A.A., Volskaya S.A., Krylo- va I.V., Chuchunkov A.S., Alexeeva S.V., Bocharov V.V., Granovsky D.V. Anaphoric Annotation and Corpus-Based Anaphora Resolution: An Experiment, Computational Linguistics and Intellectual Technologies // Диалог-2014: сб. тр. Междунар. науч. конф. по компьютер. лингвистике. 2014. Вып. 13. С. 562–571 (англ.). 6. Kamenskaya М.А., Khramoin I.V., Smirnov I.V. Data-driven Methods for Anaphora Resolution of Russian // Диалог-2014: сб. тр. Междунар. науч. конф. по компьютер. лингвистике. 2014. Вып. 13. С. 241–250 (англ.). 7. Arregi O., et al. Determination of features for a machine learning approach to pronominal anaphora resolution in basque. Procesamiento del Language Natural, 2010, no. 45, pp. 291–294. 8. Korobov M. Morphological analyzer and generator for russian and ukrainian languages. Analysis of Images, Social Networks and Texts. 2015, pp. 320–332. 9. Nivre J., Hall J., Nilsson J. et al. MaltParser: A language-independent system for data-driven dependency parsing. Natural Language Engineering. 2007, vol. 13, no. 2, pp. 95–135. 10. Nivre J., Hall J., Nilsson J. MaltParser: A data-driven parser-generator for dependency parsing. Proc. Intern. Conf. LREC, 2006, vol. 6, pp. 2216–2219. 11. Sharoff S., Nivre J. The proper place of men and machines in language technology: Processing Russian without any linguistic knowledge // Диалог-2011: сб. тр. Междунар. науч. конф. по компьютер. лингвистике. 2014. Вып. 10. С. 591–604 (англ.). 12. Смирнов И.В., Шелманов А.О., Кузнецова Е.С., Храмоин И.В. Семантико-синтаксический анализ естественных языков. Ч. II. Метод семантико-синтаксического анализа текстов // Искусственный интеллект и принятие решений. М.: Изд-во ИСА РАН, 2014. № 1. С. 11–24. 13. Chang C.C., Lin C.J. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Techno- logy, 2011, vol 2, iss. 3, art. no. 27. 14. Fan R.E., Chang K.W., Hsieh C.J., Wang X.R. and Lin C.J. LIBLINEAR: A library for large linear classification Jour. of Machine Learning Research. 2008, vol. 9, pp. 1871–1874. 15. Lappin S., Leass H.J. An algorithm for pronominal anaphora resolution. Computational Linguistics. 1994, vol. 20, no. 4, pp. 535–561. 16. Национальный корпус русского языка. URL: http://www.ruscorpora.ru/instruction-syntax.html (дата обращения: 14.05.2017). 17. Breiman L. Random forests. Machine learning. 2001, vol. 45, no. 1, pp. 5–32. |

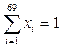 .
.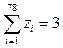 .
. – условие разбиения; Q(X, j, t) – критерий, характеризующий ошибку разбиения. Требуется найти наилучшие параметры j и t, при которых ошибка разбиения будет минимальной.
– условие разбиения; Q(X, j, t) – критерий, характеризующий ошибку разбиения. Требуется найти наилучшие параметры j и t, при которых ошибка разбиения будет минимальной.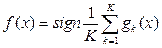 .
.
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4316&lang= |
Статья в формате PDF Выпуск в формате PDF (21.91Мб) Скачать обложку в формате PDF (0.59Мб) |
| Статья опубликована в выпуске журнала № 3 за 2017 год. [ на стр. 461-468 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Извлечение аспектов из текстов научных статей
- Методы автоматической классификации текстов
- Моделирование поведения интеллектуальных агентов на основе методов машинного обучения в моделях конкуренции
- Применение машинного обучения для прогнозирования времени выполнения суперкомпьютерных заданий
- Выделение областей интереса на основе классификации изолиний
Назад, к списку статей