Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Применение методов классификации и кластеризации для повышения эффективности работы прецедентных систем
Аннотация:В статье рассматриваются актуальные вопросы повышения эффективности работы систем, использующих рассуждения на основе прецедентов (CBR – Case-Based Reasoning). Прецедентные методы и системы (CBR-системы) активно применяются для решения целого ряда задач в области искусственного интеллекта (например, для моделирования правдоподобных рассуждений (рассуждений здравого смысла), машинного обучения, интеллектуальной поддержки принятия решений, интеллектуального поиска информации, интеллектуального анализа данных и др.). Следует отметить, что современные инструменты для интеллектуального анализа данных, широко используемые сегодня в интеллектуальных системах, системах управления базами данных и знаний, бизнес-приложениях, системах машинного обучения, системах электронного документооборота и др., не обладают развитыми CBR-средствами. Для повышения эффективности работы CBR-систем предлагается использовать модифицированный CBR-цикл, позволяющий сформировать базу удачных и неудачных прецедентов на основе имеющейся экспертной информации (тестовых выборок), а также модификацию алгоритма k ближайших соседей (k-NN) для извлечения прецедентов. Предложенные модификации позволяют повысить качество решения задач интеллектуального анализа данных (в частности, задачи классификации данных). Кроме того, в работе для повышения быстродействия CBR-систем рассматривается возможность сокращения количества прецедентов в базе удачных прецедентов за счет применения методов классификации и кластеризации. С использованием разработанного в среде MS Visual Studio на языке C# прототипа CBR-системы проведены вычислительные эксперименты по оценке эффективности предлагаемых в работе решений на наборе данных из UCI Machine Learning Repository.
Abstract:The article examines topical issues of improving efficiency of case-based reasoning (CBR) systems. Case-based methods and systems (CBR systems) are actively used to solve a number of problems in the field of artificial intelligence (for example, for modeling plausible reasoning (common sense reasoning), machine learning, intellectual decision support, intelligent information search, data mining (DM) and etc.). It should be noted that modern tools for DM, which are widely used in intelligent systems, database and knowledgebase management systems, business ap-plications, machine learning systems, electronic document management systems, etc., do not have advanced CBR tools. The paper proposes to use the modified CBR cycle to increase the efficiency of CBR systems. This cycle allows creating a base of successful (CB) and unsuccessful cases (UCB) based on available expert information (test samples), as well as the k-nearest neighbors (k-NN) modification algorithm for case retrieval. The proposed modifications allow improving the quality of solving DM tasks (in particular, data classification task). In addition, the authors consider the possibility of reducing the number of cases in CB using classification and clustering methods to improve performance of CBR systems. The paper shows computational experiments to estimate the effectiveness of the solutions offered while working on a data set from the UCI Machine Learning Repository. They use CBR system prototype developed in MS Visual Studio in C# language.
| Авторы: Варшавский П.Р. (VarshavskyPR@mpei.ru) - Национальный исследовательский университет «МЭИ» (доцент), г. Москва, Россия, кандидат технических наук, Ар Кар Мьо (arkar2011@gmail.com) - Национальный исследовательский университет «МЭИ» (аспирант), Москва, Россия, Шункевич Д.В. (shunkevichdv@gmail.com) - Белорусский государственный университет информатики и радиоэлектроники (БГУИР) (зав. кафедрой), Минск, Беларусь, кандидат технических наук | |
| Ключевые слова: кластеризация, классификация, интеллектуальный анализ данных, прецедентный подход, интеллектуальная система |
|
| Keywords: clusterization, classification, data intelligent analysis, case-based approach, intellectual system |
|
| Количество просмотров: 12996 |
Статья в формате PDF Выпуск в формате PDF (29.80Мб) |
В настоящее время актуальной задачей в области искусственного интеллекта (ИИ) является разработка методов интеллектуального анализа данных (ИАД) и соответствующих программных средств [1–3]. Методы ИАД активно применяются в интеллектуальных системах (ИС), системах управления БД (СУБД) и системах управления базами знаний (СУБЗ), бизнес-приложениях, системах машинного обучения, системах электронного документооборота и др. В ИАД для извлечения новых знаний из имеющихся данных применяются статистические и индуктивные методы, генетические алгоритмы, искусственные нейронные сети (ИНС), кластерный анализ, методы правдоподобных рассуждений на основе прецедентов (CBR – Case-Based Reasoning) и т.п. [2, 3]. Следует отметить, что в современных средствах ИАД для СУБД и СУБЗ, в том числе ориентированных на платформу Business Intelligence (BI) [4], практически отсутствуют развитые средства и инструменты для анализа данных на основе прецедентов. По этой причине остро стоит вопрос разработки эффективных CBR-средств для расширения инструментов ИАД на платформе BI для современных СУБД и СУБЗ. Прецедентный подход Прецедентный подход базируется на понятии прецедента, определяемого как случай, имевший место ранее и служащий примером или оправданием для последующих случаев подобного рода, и довольно простом принципе, что подобные задачи имеют подобное решение. В общем случае модель представления прецедента включает описание ситуации, решение для данной ситуации и результат применения решения: CASE = (Situation, Solution, Result), где Situation – ситуация, описывающая данный прецедент; Solution – решение (например диагноз и рекомендации); Result – результат применения решения, который может включать список выполненных действий, дополнительные комментарии и ссылки на другие прецеденты, а также в некоторых случаях обоснование выбора данного решения и возможные альтернативы. В большинстве случаев для представления прецедентов используется простое параметрическое представление [5]. Как правило, CBR-методы основываются на так называемом CBR-цикле [6], включающем в себя четыре основных этапа: - извлечение наиболее соответствующего (подобного) прецедента (или прецедентов) для сложившейся ситуации из базы прецедентов (БП); - повторное использование извлеченного прецедента для попытки решения текущей проблемы; - адаптация и применение полученного решения для решения текущей проблемы; - сохранение вновь принятого решения как части нового прецедента. Для извлечения прецедентов из БП системы могут применяться различные методы [5]: - метод ближайшего соседа (NN – Nearest Neighbor) и его модификации (например метод k ближайших соседей (k-NN)); - метод поиска на деревьях решений; - метод извлечения на основе знаний; - метод извлечения с учетом применимости прецедентов и др. В данной работе используются параметрическое представление прецедентов и модификация алгоритма k-NN. Модификация алгоритма k-NN для извлечения прецедентов Самым распространенным методом сравнения и извлечения прецедентов является метод ближайшего соседа [1, 5]. Он позволяет довольно легко вычислить степень сходства текущей проблемной ситуации и прецедентов из БП. Для определения степени сходства на множестве параметров, используемых для описания прецедентов и текущей ситуации, вводится некоторая метрика. Далее в соответствии с выбранной метрикой определяется расстояние от целевой точки, соответствующей текущей проблемной ситуации, до точек, представляющих прецеденты из БП, и выбирается ближайшая к целевой точка. Метод ближайшего соседа широко применяется для решения задач классификации, кластеризации, регрессии и распознавания образов. Обычно решение выбирается на основе нескольких ближайших точек (соседей), а не одной (метод k-NN) [7]. Основными преимуществами указанного метода являются простота реализации и универсальность в смысле независимости от специфики конкретной проблемной области, а к недостаткам можно отнести сложность выбора метрики для определения степени сходства, прямую зависимость требуемых вычислительных ресурсов от размера БП и низкую эффективность при работе с неполными и плохо определенными (так называемыми «зашумленными») исходными данными. В работе предложена модификация алгоритма k-NN, которая заключается в том, что k изменяется в зависимости от изменения размера БП. Чем больше прецедентов в БП, тем большее значение можно выбрать для k (от 1 до kmax). kmax соответствует максимальному количеству прецедентов из БП, имеющих одинаковое решение (то есть при- надлежащих одному классу или кластеру). В результате вычислительных экспериментов было установлено, что целесообразно выбирать k как ближайшее целое число к среднему арифметическому значению между 1 и kmin, то есть kavg = (1 + + kmin)/2, где kmin – минимальное количество прецедентов, имеющих одинаковое решение (то есть принадлежащих одному классу или кластеру).
Из графиков, представленных на рисунке 1, видно, что показатели качества классификации при увеличении БП (накоплении опыта – прецедентов) выше при выборе в алгоритме k-NN для извлечения прецедентов значения k, равного kAVG. Следует отметить, что при каждом добавлении нового прецедента в БП вычисляется новое значение для kAVG. Модифицированный CBR-цикл
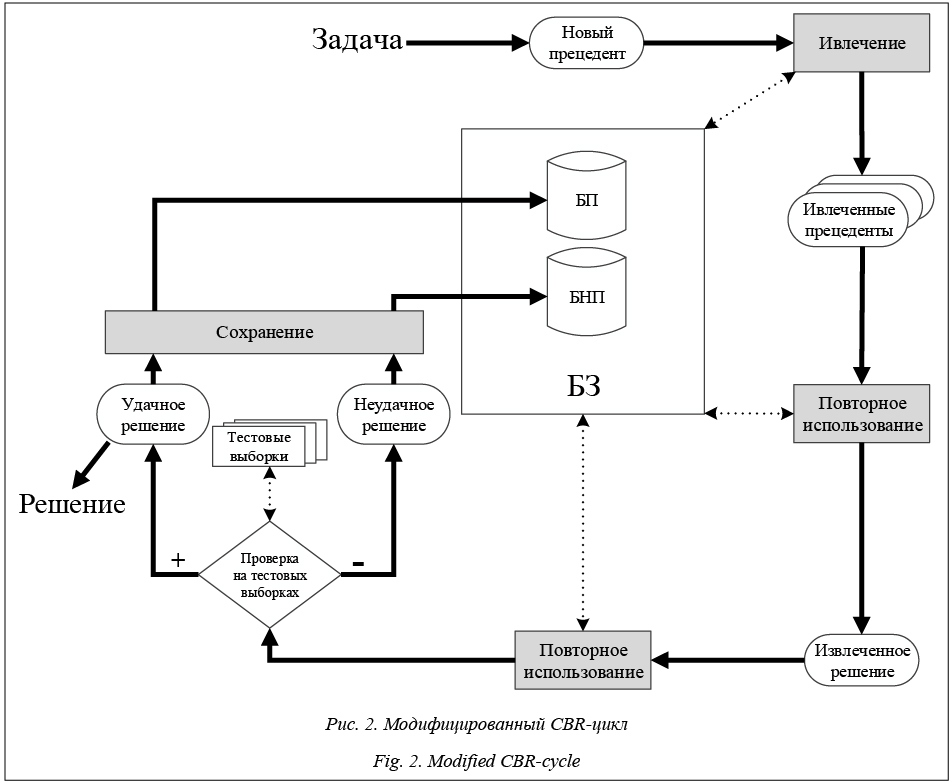
При наличии экспертных знаний (тестовых выборок) перед сохранением в CBR-цикле должна выполняться проверка корректности решения на тестовых наборах. Если решение проходит проверку и принимается пользователем, оно сохра- няется в БП как новый прецедент. Если проверка корректности решения на тестовых наборах завершается неудачно, прецедент сохраняется в базе неудачных прецедентов (БНП). Удачным назовем прецедент, который не ухудшает качество работы CBR-системы после его добавления в БП, а неудачным − прецедент, который ухудшает качество работы CBR-системы после его добавления в БП. Таким образом, предлагается использовать тестовую (экспертную) выборку на последнем этапе CBR-цикла для формирования БП и БНП.
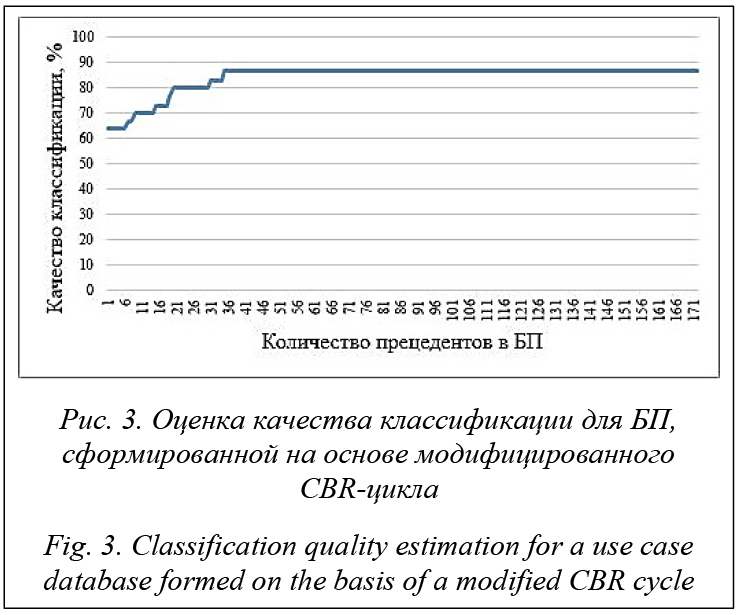
Использование модифицированного CBR-цикла и формирование БП на основе удачных прецедентов (171 прецедент) позволили улучшить качество классификации CBR-системой до 87 %. Повышение эффективности работы CBR-систем В процессе функционирования CBR-систем увеличивается количество прецедентов в БП, то есть CBR-системы обучаются (накапливают опыт) и качественно решают поставленные перед ними задачи, но при этом значительно увеличиваются временные затраты и затраты на организацию хранения прецедентов, требуемые для поддержания CBR-цикла. По этой причине для CBR-систем актуальной является задача повышения эффективности их работы за счет увеличения быстродействия CBR-систем и сокращения объема памяти, необходимого для хранения прецедентов в БП. Достичь этого можно несколькими путями, например, за счет индексации БП или сокращения количества прецедентов в БП системы. Индексирование БП. Можно повысить эффективность (быстродействие) работы CBR-системы за счет формирования индекса по БП. Индекс – объект БД, создаваемый с целью повышения производительности поиска данных. Таблицы в БД могут иметь большое количество строк, хранящихся в произвольном порядке, и их поиск по заданному критерию путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счет того, что индекс имеет структуру, оптимизированную под поиск, например сбалансированного дерева. Возможно сокращение количества преце- дентов в БП за счет применения методов классификации и кластеризации. Сокращение количества прецедентов в БП с использованием метода классификации. Одним из способов сокращения количества прецедентов в БП является классификация (например, с применением алгоритма k-NN) с последующим удалением всех прецедентов, которые определяются как ближайшие к выбранному. Это позволяет представить БП в компактном виде для пользователя с сохранением распределения по классам, снизив объем памяти, необходимый для хранения прецедентов, и существенно повысить быстродействие CBR-системы, но при этом возможно ощутимое снижение качества решения задач CBR-системой. Алгоритм 1. Алгоритм сокращения количества прецедентов в БП на основе классификации. Входные данные: CB – непустое множество прецедентов (БП); n – количество параметров в прецедентах; m – количество прецедентов в БП; S(Ci, Cj) – заданная метрика для вычисления расстояния между прецедентами Ci и Cj; H – пороговое значение степени сходства. Выходные данные: CB – множество прецедентов после сокращения БП. Промежуточные данные: SC – множество ближайших прецедентов к выбранному; i, j – параметры циклов. Шаг 1. j = 1, SC = Æ, переход к следующему шагу. Шаг 2. Если j ≤ m, выбираем прецедент Cj из множества CB (Cj Î CB); переход к шагу 3, иначе все прецеденты из БП рассмотрены и переход к шагу 5. Шаг 3. Определяем SC – множество ближайших прецедентов Ci (Ci Î CB, i ¹ j) к прецеденту Cj в соответствии с заданной метрикой S(Ci, Cj) и переходим к следующему шагу. Шаг 4. Если SC ≠ Æ, удаляем из CB все прецеденты, входящие в множество SC. Далее m = m – |SC|, SC = Æ, j = j + 1 и переход к шагу 2. Шаг 5. Конец (завершение алгоритма). Сокращение количества прецедентов в БП на основе кластерных методов. Кластерный анализ (кластеризация) – это способ группировки многомерных объектов, основанный на представлении результатов отдельных наблюдений точками подходящего геометрического пространства с последующим выделением групп как «сгустков» этих точек (кластеров, таксонов). В последние годы данный метод исследования получил развитие в связи с возможностью компьютерной обработки больших БД. Кластеризация предполагает выделение компактных, удаленных друг от друга групп объектов, характеризующихся внутренней однородностью и внешней изолированностью. Применительно к CBR-системам алгоритмы кластеризации позволяют получить множество прецедентов – «центров» кластеров, по отношению к которым остальные прецеденты в кластере близки. То есть множество «центров» кластеров в БП можно использовать вместо самой БП, так как ситуации, близкие к какому-либо прецеденту из кластера, будут близки и к центру этого кластера. В работе предлагается подход к сокращению количества прецедентов в БП на основе кластеризации (алгоритм k-средних) с последующим удалением всех прецедентов в каждом кластере, кроме его центрального представителя. Таким образом, кластеризация позволяет представить БП в более прозрачном виде для пользователя с сохранением распределения по кластерам и сократить время поиска решения и объем памяти, необходимый для хранения прецедентов в БП. Недостатком этого способа является потеря точности на границах кластеров. Алгоритм 2. Алгоритм k-средних для сокращения количества прецедентов в БП. Входные данные: CB – БП; m – количество прецедентов в БП; k – количество кластеров; n – ко- личество параметров в описании прецедентов; S(Ci, Cj) – заданная метрика для вычисления расстояния между претендентами Ci и Cj. Выходные данные: CB – множество прецедентов после сокращения БП. Промежуточные данные: CL – полученные кластеры; μ – центры масс кластеров; V – суммарное квадратичное отклонение объектов (прецедентов) в кластерах от их центров; i, j – параметры циклов. Шаг 1. Выбираются k случайных центров кластеров (прецедентов) из CB. Шаг 2. Для каждого центра кластера μi (i=1, …, k) определяется множество прецедентов, для которых соответствующий центр является ближайшим CLi, то есть расстояние S(Cj, μi) (метрика) от прецедента Cj (Cj Î CB) до центра кластера μi минимально. Шаг 3. Если для одного из центров соответствующее ему множество ближайших прецедентов является пустым, вместо него выбирается новый случайный центр (прецедент). Шаг 4. В каждом полученном множестве ближайших прецедентов (кластере CLi) определяется новый центр масс кластеров, который используется на следующей итерации. Шаг 5. Оценивается суммарное расстояние прецедентов в БП до полученных центров: Шаг 6. Из CB удаляются все прецеденты, за исключением полученных центров кластеров. Шаг 7. Завершение алгоритма (конец). В таблице приведены результаты вычислитель- ных экспериментов по оценке эффективности предложенных алгоритмов для сокращения количества прецедентов в БП на примере рассмотренной выше задачи классификации данных из хранилища UCI Machine Learning Repository. Результаты исследования Research results
Как видно из таблицы, при сокращении количества прецедентов в накопленной БП (со 171 до 25 прецедентов) с использованием классификационного алгоритма 1 качество классификации на тестовом наборе снижается на 15 %, а при сокращении количества прецедентов в накопленной БП (со 171 до 4 прецедентов) с использованием кластерного алгоритма 2 качество классификации на тестовом наборе снижается только на 7 %, что является допустимым значением при существенном повышении быстродействия CBR-системы и уменьшении объема памяти, необходимого для хранения прецедентов в БП, за счет сокращения количества прецедентов в БП (более чем в 40 раз). Архитектура прототипа CBR-системы
- пользовательский интерфейс – интерфейс для взаимодействия с экспертом или пользователем и отображения результатов работы; - блок извлечения прецедентов – для поиска прецедентов на основе модифицированного метода k-NN; - база знаний – содержит базу удачных и базу неудачных прецедентов (соответственно БП и БНП); - набор тестовых выборок – экспертная информация, содержащая данные (примеры) с корректными решениями, для ее учета при извлечении прецедентов и формирования БП и БНП; - модуль оптимизации БП – для выполнения сокращения количества прецедентов в БП с использованием предложенных в работе алгоритмов. Программная реализация прототипа CBR-системы выполнена с использованием языка C# и среды программирования MS Visual Studio, а также СУБД Microsoft SQL Server, в том числе Microsoft SQL Server Analysis Services. Модуль оптимизации базы прецедентов для CBR-систем зарегистрирован в государственном реестре программ для ЭВМ (свидетельство № 2016617638 от 13 июля 2016 г.). Заключение В статье обсуждается перспективная возможность расширения существующих инструментов ИАД для современных СУБД и СУБЗ средствами поиска решения (рассуждения) на основе прецедентов (CBR-средствами), а также рассматриваются актуальные вопросы повышения эффективности работы CBR-систем. Для повышения качества решения, получаемого CBR-системой, разработана модификация алгоритма извлечения прецедентов на основе k-NN, заключающаяся в изменении значения k в зависимости от размера БП, и предложен модифицированный CBR-цикл, использующий экспертную информацию (тестовые наборы данных) для проверки корректности полученного решения и формирования БП и БНП. Для повышения эффективности работы CBR-систем предложены алгоритмы сокращения количества прецедентов в БП на основе методов классификации и кластеризации. С использованием разработанного прототипа CBR-системы проведены вычислительные эксперименты по оценке эффективности предлагаемых в работе решений на наборе данных из хранилища UCI Machine Learning Repository. Работа выполнена при финансовой поддержке РФФИ, проекты №№ 15-07-04574, 16-51-00058, 17-07-00553. Литература 1. Рассел С., Норвиг П. Искусственный интеллект: современный подход; [пер. с англ.]. М.: Вильямс, 2006. 1410 с. 2. Финн В.К. Об интеллектуальном анализе данных // Новости искусственного интеллекта. 2004. № 3. С. 3–19. 3. Вагин В.Н., Головина Е.Ю., Загорянская А.А., Фоми- на М.В. Достоверный и правдоподобный вывод в интеллектуальных системах. М.: Физматлит, 2008. 712 с. 4. Барсегян А.А., Холод И.И., Тесс М.Д., Куприянов М.С., Елизаров С.И. Анализ данных и процессов. СПб: БХВ-Петербург, 2009. 512 с. 5. Варшавский П.Р., Еремеев А.П. Моделирование рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений // Искусственный интеллект и принятие решений. 2009. № 2. С. 45–57. 6. Aamodt A., Plaza E. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. Artificial Intelligence Communications. IOS Press. 1994, vol. 7, no. 1, pp. 39–59. 7. Алехин Р.В., Ар Кар Мьо, Варшавский П.Р., Зо Лин Кхаинг. Реализация прецедентного модуля для интеллектуальных систем // Программные продукты и системы. 2015. № 2. С. 26–31. 8. User knowledge modeling data set. URL: http://archive.ics. uci.edu/ml/datasets/User+Knowledge+Modeling: (дата обращения: 10.03.2017). References
|

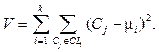 Если суммарное расстояние не уменьшилось, осуществляется переход к шагу 6, иначе – возврат к шагу 2.
Если суммарное расстояние не уменьшилось, осуществляется переход к шагу 6, иначе – возврат к шагу 2.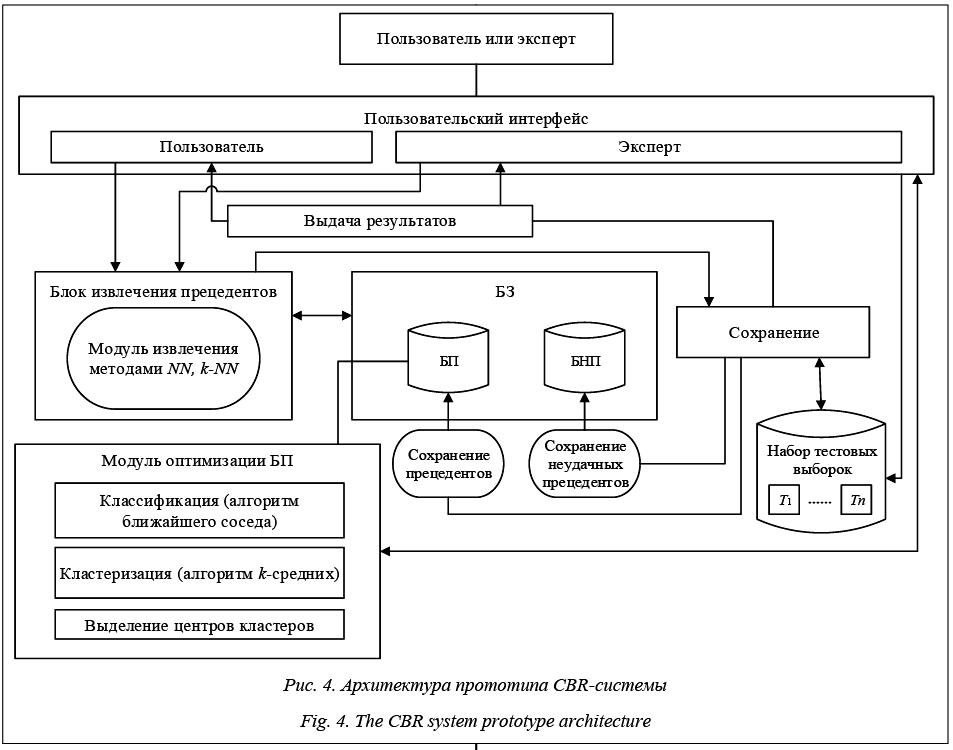
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4358 |
Статья в формате PDF Выпуск в формате PDF (29.80Мб) |
| Статья опубликована в выпуске журнала № 4 за 2017 год. [ на стр. 625-631 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка теоретических основ классификации и кластеризации нечетких признаков на основе теории категорий
- Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
- Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
- Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
- Реализация программных средств для классификации данных на основе аппарата сверточных нейронных сетей и прецедентного подхода
Назад, к списку статей