Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Современные подходы к обучению интеллектуальных агентов в среде Atari
Аннотация:Статья посвящена разработке и исследованию алгоритмов машинного обучения в задаче обучения интеллектуальных агентов в среде Atari, представляющей эмуляцию игровой консоли Atari2600 при помощи платформы OpenAI Gym. Основные цели исследования – описание и сравнение современных алгоритмов обучения с подкреплением в различных ситуациях, выявление их достоинств и недостатков, а также формирование предложений по повышению эффективности этих алгоритмов. Авторы описывают математическую модель задачи обучения с подкреплением в виде марковского процесса принятия решений и формируют критерий оптимальности системы. Отдельно отмечены особенности, характерные для среды Atari. Описаны принцип работы существующих решений, а также использующиеся в них инструменты. Рассмотрены базовый подход Q-обучения и его известная модификация с использованием нейронной сети. Представлена идея алгоритма на основе градиента по стратегиям. Дано описание подхода алгоритмов типа «актор-критик», а также рассмотрена его асинхронная многопоточная версия. Все рассмотренные алгоритмы описаны в виде псевдокода. Предложен способ повышения эффективности обучения с помощью выделения признаков. Разработан алгоритм генерации вектора признаков на основе распознавания образов. Описаны этапы формирования вектора признаков и его использования в процессе обучения. Алгоритмы реализованы, проведен эксперимент с их использованием. Выполнен сравнительный анализ результатов и получены выводы об эффективности алгоритмов. Предложены идеи по дальнейшему увеличению скорости и качества обучения интеллектуальных агентов.
Abstract:The article describes the research and development of machine learning algorithms for the problem of training intelligent agents in the Atari environment. The environment is the game console Atari2600 emulation on OpenAI Gym platform. The main aims of the research are to describe and compare modern learning algorithms with reinforcement in a number of cases, to expose their advantages and drawbacks and to give suggestions in order to increase their effectiveness. The authors describe a mathematical model of the reinforcement learning task in terms of Markov Decision Process and form a system optimality criterion. In addition, they note the Atari environment properties. There is a description of an operation principle of existing solutions, as well as the tools used in them. The paper considers a basic Q-learning approach and its well-known modification that uses a neural network. It also presents the idea of the algorithm based on policy gradient. The paper gives a description of the approach of “actor-critic” algorithms and considers its asynchronous multithreaded version. All the described algorithms are presented in pseudocode. The authors propose a method of increasing the effectiveness of learning using feature extraction. The developed algorithm for feature vector generation is based on image recognition. The paper describes the steps of feature vector selection and its usage during the learning process. The described algorithms are implemented, and the experiment is conducted. A comparative analysis of the results gave conclusions on the efficiency of the algorithms. Finally, the authors propose some ideas for further increasing the speed and efficiency of training of intelligent agents.
| Авторы: Коробов Д.А. (тroyalruby@yandex.ru) - Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» (студент), Санкт-Петербург, Россия, Беляев С.А. (beliaev@nicetu.spb.ru) - Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» им. В.И. Ульянова (Ленина) (доцент), Санкт-Петербург, Россия, кандидат технических наук | |
| Ключевые слова: atari, интеллектуальные агенты, обучение с подкреплением, q-обучение, градиент по стратегиям, асинхронный актор-критик, распознавание образов, выделение признаков |
|
| Keywords: atari, intellectual agents, time, reinforcem ent learnin, q-learning, policy gradient, asynchronous actor-critic, pattern recognition, feature matching |
|
| Количество просмотров: 8714 |
Статья в формате PDF Выпуск в формате PDF (19.46Мб) |
Интеллектуальными агентами принято называть самообучающиеся программы, способные играть в классические и видеоигры. Согласно [1], «агентом является все, что может рассматриваться как воспринимающее свою среду с помощью датчиков и воздействующее на эту среду с помощью исполнительных механизмов». Интеллектуальные агенты способны моделировать поведение человека в задачах сбора и обработки информации, при этом они могут активно перемещаться внутри информационного пространства в направлении цели. Одной из платформ, позволяющих проводить разработку и исследование алгоритмов машинного обучения, является OpenAI Gym, включающая в себя возможность эмуляции игровой консоли Atari2600. В качестве входных данных среда Atari предоставляет последовательность изображений экрана размера 210×160 пикселей, а также общий игровой счет и индикатор победы или поражения. На основе описанных входных данных агент должен выбрать одно из возможных действий с помощью обучения с подкреплением – машинное обучение, направленное на решение задачи принятия решения о выборе действия в заданной ситуации таким образом, чтобы максимизировать выгоду в долгосрочной перспективе [2]. В частности, интерес представляют интеллектуальные агенты, не зависящие от правил игры, то есть способные проходить несколько различных игр Atari без изменения алгоритма. В дальнейшем разработанные алго- ритмы могут быть применены в робототехнике при движении роботов-гуманоидов, в проектировании человеко-машинных интерфейсов, а также в системах алгоритмической торговли. Формальная постановка задачи Стандартным способом формализации задачи обучения с подкреплением является представление ее в виде марковского процесса принятия решений (МППР) [3]. МППР предоставляет способ редукции задачи принятия решения к следующим ключевым компонентам: множеству состояний S, множеству действий A, функции перехода P : S ´ A ® ® Dist(S), функции награды P : S ´ A ®
Результат действия зависит только от текущего состояния и не зависит от предыдущих состояний. Поведение агента описывается стратегией p : S ® ® Dist(A), которая отображает множество состояний в распределение вероятностей над множеством действий. Под стратегией понимаются весовые коэффициенты модели, корректируемые агентом в процессе обучения. Важным является то, что в среде Atari отдаленные награды менее значимы, чем ближайшие. Фактор дисконтирования γ может иметь значение 0 или 1: 0 означает, что только настоящее имеет значение, а 1 – что будущие награды имеют полный вес в принятии решения:
Цель агента – найти оптимальный план – стратегию, максимизирующую ожидаемую полезность из любого состояния st, определяемую как математическое ожидание суммы дисконтированных будущих наград: Существующие решения Классические алгоритмы обучения с подкреплением на каждом этапе оценивают модель состояния будущего полностью, присваивают ценность каждому действию и затем выбирают действие с наивысшим значением ценности. Впоследствии появились модели, использующие новые методы принятия решений. Нейронные сети, составленные из нескольких слоев линейных моделей, позволяют строить абстракции в виде иерархии признаков, а сверточные нейронные сети являются наиболее мощным инструментом для извлечения информации из изображений [4]. В данной статье рассмотрены следующие современные алгоритмы, использующие нейронные сети: - Deep Q-learning (глубокое Q-обучение); - REINFORCE (алгоритм на основе градиентов по стратегиям); - A3C (алгоритм асинхронного актора-критика). Алгоритмы Q-обучения оперируют функцией качества Q(s, a), обозначающей наибольший возможный счет, которого можно достичь в конце игры после выбора действия a в состоянии s. Функцию Q(s, a) можно определить рекурсивно:
где T(s, a, s’) – вероятность перехода в состояние s’ из состояния s в случае выбора действия a. Однако, так как функции R(s, a) и T(s, a, s’) априори неизвестны, требуется оценивать Q*(s, a) и обновлять оценку по мере исследования игры в соответствии с различными действиями
где γ – фактор дисконтирования; a – скорость обучения, определяющая степень значимости новых наблюдений при обновлении оценки. При a = 1, например, предыдущие оценки не учитываются. В начале обучения оценка Инициализировать Q(s, a) произвольным образом Получить начальное состояние s для каждого эпизода: Выбрать и выполнить действие a Получить награду r и новое состояние s’ s = s’ В случае, когда среда имеет дискретное пространство состояний, а агент дискретное количество возможных действий, модель динамики среды представляет собой одношаговую матрицу перехода: T(s(t+1) | s(t), s(a)). Данная стохастическая матрица содержит все вероятности перехода в желаемое состояние из текущего при выборе каждого действия. В среде Atari пространство состояний после масштабирования без потери информации является множеством изображений размера 64×64 пикселя, а агент имеет 18 возможных действий, значит, размер матрицы перехода вычисляется следующим образом: |S ´ S ´ A| » |(66.7 ´ 109) ´ (66.7 ´ ´ 109) ´ 18 |, что при 32-битном размере элемента матрицы требует 3.4×1014 Гб памяти. Из-за невозможности хранить такой объем памяти требуется аппроксимировать таблицу переходов. Алгоритм Deep Q-learning (DQN), описанный впервые в [6], использует нейронную сеть для аппроксимации функции Q. Теперь вместо того, чтобы обновлять функцию Q напрямую, нейронной сети передается состояние s, после чего сеть возвращает значения Q для каждого возможного действия. Одной из особенностей использования нейронных сетей в обучении с подкреплением является отсутствие гарантий сходимости. Для улучшения сходимости применяется метод сохранения предыдущего опыта в памяти (experience replay memory). Вместо обучения сети на каждом переходе в новое состояние и отбрасывания этого перехода в памяти сохраняются N предыдущих переходов, а при обучении используется случайная выборка из данных переходов [7]. При выборе действия теперь также используется ε-жадная стратегия, которая заключается в том, что вместо выбора наиболее выгодного действия агент с вероятностью ε выбирает случайное действие. В итоге с учетом рассмотренных замечаний алгоритм DQN выглядит следующим образом:
Инициализировать память переходов D Инициализировать модель вычисления Q(s, a) случайными весами Получить начальное состояние s для каждого эпизода: Выбрать и выполнить действие a:{ с вероятностью ε выбрать случайное действие иначе выбрать } Получить награду r и новое состояние s’ Сохранить переход в памяти D Получить выборку переходов из памяти Вычислить tt для каждого элемента выборки{ если ss’ - терминальное состояние, то tt = rr иначе } Обучить сеть, используя в качестве функции потерь s = s’ Алгоритмы на основе градиентов по стратегиям (policy gradient) представляют собой тип алгоритмов обучения с подкреплением, которые пола- гаются на оптимизацию параметров стратегии в соответствии с ожидаемой суммарной наградой, используя для этого градиентный спуск [8]. Классическим алгоритмом данного типа является REINFORCE, особенность которого в том, что в процессе обновления стратегии (корректировки весов модели) он учитывает всю траекторию агента. Под траекторией понимается последовательность всех переходов – четверок объектов S ´ A ® S ´ R (состояние, действие, новое состояние, награда) на протяжении периода одной игры. Задачей алгоритма является максимизация ожидаемой суммарной награды:
Пусть R(τ) – математическое ожидание суммарной награды для траектории τ. Вероятность каждой траектории задается стратегией, определяющей действия, которые предпринимает агент. Следовательно, формулу (4) можно переписать следующим образом:
где θ определяет параметры обучаемой модели. С целью максимизации функции ρ(s) вычисляется градиент ρ по θ, который после преобразований, описанных в [3], представляется в виде
Градиент
Псевдокод алгоритма будет следующим:
Вход: модель, задающая стратегию Инициализировать веса модели θ повторять бесконечно: Сгенерировать эпизод S0, A0, R1, …, ST-1, AT-1, RT, следуя стратегии π для каждого шага t=0,…,T-1: Rt ← вычислить Алгоритмы типа «актор-критик» оперируют как стратегией (актор), так и функцией полезности (критик), формируя стратегию подобно алгоритму REINFORCE. Отличие заключается в том, что для расчета градиента используется функция полезности, а не траектория. Во время перехода в новое состояние система получает сигнал о значении награды и вычисляет функцию полезности по методу временной разности (temporal difference) при помощи уравнения Беллмана [9]. Функция полезности затем используется для корректировки весов модели. В статье [10], описывающей асинхронные методы для глубокого обучения с подкреплением, был представлен алгоритм асинхронного актора-критика (Asynchronous Advantage Actor-Critic – A3C), использующий несколько копий нейронной сети и несколько экземпляров среды, где каждый агент взаимодействует со своей собственной копией среды. Результаты, полученные несколькими агентами, в дальнейшем объединяются в глобальную модель. Рассматриваемая версия алгоритма использует функцию преимущества A, которая оценивается, используя дисконтированную сумму будущих наград R: A = R – V(s), где V(s) – функция, обозначающая наибольший счет, которого можно достичь из состояния s, и не зависящая от действий агента. Псевдокод алгоритма АЗС:
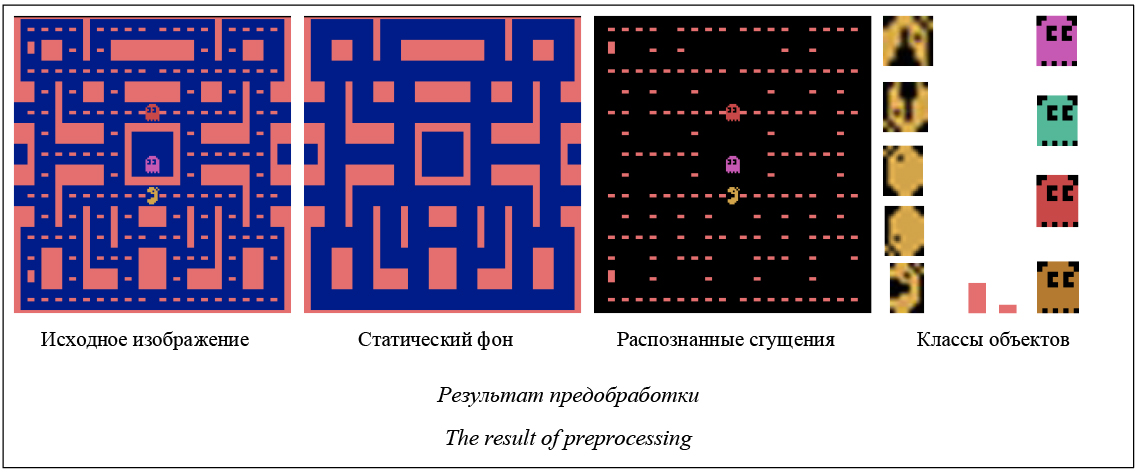
Задать глобальные общие векторы параметров θ и θv и глобальный общий счётчик T = 0 Задать векторы параметров θ’ и θv’ для каждого потока Инициализировать счётчик шагов потока t ¬ 1 повторять: Обновить градиенты: Синхронизировать: θ’ = θ и θv’ = θv tstart = t Получить состояние st повторять: Выполнить действие at согласно стратегии Получить награду rt и новое состояние st+1 t ¬ t + 1 T ¬ T + 1 до тех пор пока st терминал или t - tstart == tmax для i Î {t - 1, …, tstart}: Выполнить асинхронное обновление θ и θv пока В качестве модели в рассмотренных алгоритмах предлагается использовать сверточную нейронную сеть. Значительными ограничениями применимости данных алгоритмов являются огромная размерность входных данных и ресурсоемкость задачи обучения при использовании пикселей в качестве входных данных, за счет чего обучение даже на высокопроизводительном компьютере может занимать десятки часов. Редукция задачи посредством распознавания образов Увеличить скорость и качество обучения может формирование информативных признаков [11]. Использование вектора признаков вместо набора пикселей позволит интеллектуальному агенту ориентироваться лишь на значимые характеристики входных данных и, следовательно, быстрее обу- чаться. Авторами предлагается вариант алгоритма генерации вектора признаков, основанный на обнаружении набора классов игровых сущностей (персонажей и окружения) и нахождении положения экземпляров данных классов на каждом изображении экрана. В его основу легли следующие наблюдения: большинство игр Atari имеют статический фон и небольшое число игровых сущностей, перемещающихся по экрану. Все игровые сущности могут быть разделены на небольшое число непересекающихся классов. При этом задача разбивается на два этапа: на первом этапе для новой игры строится вектор признаков, а на втором проводится обучение с его использованием. 1. Предобработка. Включает в себя обнаружение фона и выделение сгущений – групп связанных и совместно движущихся пикселей. Далее сгущения разделяются на множество классов C. Под классом объектов понимается множество всех возможных форм (фигур), задающих игровую сущность, где формы представляют различные кадры в анимации объекта. Классы могут содержать обрезанные вариации формы, например, при частичном выходе объекта за пределы экрана. Пример результатов различных этапов предобработки изображен на рисунке. 2. Обучение. Как только агент начинает действовать, на каждом шаге распознаются объекты классов c Î C, с их помощью происходит генерация вектора признаков.
Метод распознавания объектов классов использует классы, полученные на предыдущем этапе. Формально ставится задача нахождения списка Yt(c), содержащего координаты и скорости всех экземпляров класса c на экране Xt для каждого класса c Î C. Сначала строится список всех возможных фигур всех классов, который затем упорядочивается по размеру от самой большой фигуры к самой маленькой. Далее изображение экрана сканируется на предмет наличия каждой фигуры o из списка. Если совпадение найдено, пиксели помечаются как распознанные и в дальнейшем не учитываются. Центр масс распознанных пикселей добавляется в список Y(o.class). За распознаванием объектов классов следует этап генерации вектора признаков для обучения модели. В результате вектор признаков содержит следующие данные: - количество объектов каждого класса (в зависимости от наличия или отсутствия определенных объектов действия агента могут различаться); - абсолютное положение каждого объекта (координаты объектов – основная информация, необходимая для построения эффективной стратегии); - векторы скорости объектов (направление движения играет значительную роль при принятии решения о выборе следующего действия; скорость определяется разностью координат объектов yt и yt–1). На каждом экране класс с может иметь от 0 до nc(t) экземпляров, где nc(t) не является постоянным и зависит от этапа игры. Однако все алгоритмы обучения с подкреплением требуют на входе вектор фиксированной длины. Следовательно, необходимо найти способ эффективной генерации вектора фиксированной длины из распознанных объектов. Пусть При использовании данного подхода вектор признаков будет иметь размер, зависящий от суммы максимального количества объектов каждого класса. Помимо количества объектов n класса c, в векторе признаков содержатся 2×n координат (x и y) и 2×n скоростей (vx и vy). Значит, итоговый размер вектора будет следующим:
Псевдокод общего алгоритма генерации вектора признаков на основе распознавания образов:
Пусть заданы C – множество классов и Nc – максимальное возможное количество экземпляров класса c для данной игры Входные данные: Xt – изображение экрана Выходные данные: Vt – вектор признаков 1. Yt ¬ распознать_объекты_класса(Xt) 2. вычислить_скорости(Yt, Yt-1) 3. для cÎC: n ¬ количество непустых объектов класса Yt(c) Добавить n в вектор Vt для yÎYt(c): если y – не пустой: Добавить [y.x, y.x, y.vx, y.vy] в вектор Vt иначе: Добавить [null, null, null, null] в вектор Vt OpenAI Gym. Сравнительная характеристика алгоритмов Эксперимент проводился при помощи открытой платформы машинного обучения OpenAI Gym. Реализованные на языке Python с использованием фреймворка Tensorflow алгоритмы исследовались в следующих играх Atari: Pong, Breakout, SpaceInvaders, MsPacman. В качестве оборудования использовалась виртуальная машина Google Cloud, имеющая 4 Гб оперативной памяти и один виртуальный CPU, где под виртуальным CPU понимается вычислительная мощность, эквивалентная мощности одного ядра процессора Intel Xeon E5 v3 (Haswell) – 2.3 GHz. Для проведения оценки результатов введем следующие понятия. Пусть эпизод – одна тренировочная игра от начала партии до перезагрузки (победы или поражения). Принятие решения о выборе действия a в состоянии s с переходом в состояние s' назовем итерацией. Шагом обучения будем называть процесс обучения сети, то есть пересчет весов модели, который может выполняться либо каждую итерацию (как в REINFORCE), либо через каждые k итераций. Первый эксперимент проводился в среде Pong. Модели обучались на вычислительном сервере в течение 32 часов. Оценка результатов проводилась с помощью 100 тестовых игр, затем вычислялись средний и максимальный игровой счет в выборке. Также оценивались следующие параметры: количество эпизодов и количество шагов обучения (табл. 1). Таблица 1 Эксперимент 1 – pong Table 1 Experiment 1 – pong
Алгоритм A3C требует наименьшего числа шагов обучения на эпизод игры (6 шагов/эпизод) по сравнению с REINFORCE (756 шагов/эпизод) и DQN (460 шагов/эпизод), что позволяет сократить количество обновлений модели. Тем не менее, для алгоритма DQN требуется наименьшее число эпизодов по сравнению с другими алгоритмами при сравнимом конечном результате (максимальном счете). Учитывая, что производительность разработанного метода формирования вектора признаков пропорциональна количеству эпизодов, было принято решение применить алгоритм распознавания образов к алгоритму DQN. Задачей второго эксперимента было исследование возможностей использования DQN в различных играх. Для каждой игры представлены три результата: до начала обучения (стратегия случайного выбора действия), а также счет после 32 часов обучения на пикселах и в результате применения метода формирования вектора признаков (табл. 2). В первом случае в классическом варианте DQN используется сверточная нейронная сеть следующего вида: слой с 32 фильтрами размера 8×8 с шагом 4, слой с 64 фильтрами размера 4×4 с шагом 2, слой с 64 фильтрами размера 3×3 с шагом 1, полносвязный слой из 512 нейронов. Каждый из слоев также содержит ReLU-блок. В варианте, включающем процедуру распознавания образов, полученный вектор признаков проходит обучение лишь на полносвязном слое, содержащем 512 нейронов и ReLU-блок, минуя при этом сверточные слои. Таблица 2 Эксперимент 2 – исследование DQN Table 2 Experiment 2 – research on DQN
Примечание: в таблице А – средний счет, B – максимальный счет. По результатам эксперимента можно сделать вывод, что алгоритм DQN показывает хорошие результаты в игре MsPacman. Вероятно, это связано с тем, что в данной игре агенту довольно просто принять решение, ориентируясь на отдельное состояние экрана. Неплохие результаты обучения в игре Pong связаны с достаточно простыми правилами игры и небольшим числом сущностей (3 объекта). В таких динамичных играх, как SpaceInvaders и Breakout, есть сложности в оценке динамики по одному состоянию без использования траектории и расчет Q-функции оказывается не слишком эффек- тивным. Алгоритм, использующий метод генера- ции признаков на основе распознавания образов, во всех рассмотренных случаях увеличивает эффективность обучения, позволяя при этом использовать более простую модель нейронной сети. Следует учесть, что во всех рассмотренных вариантах модель самостоятельно генерировала обучающие выборки на основе предыдущего опыта либо случайного выбора действия. Дальнейшее улучшение эффективности алгоритмов возможно путем совмещения обучения с подкреплением и обучения с учителем, например, предоставляя нейронной сети выборки, сформированные человеком. Заключение Задача обучения интеллектуальных агентов является актуальной и имеет достаточно широкую область применения. В данной статье были рассмотрены современные алгоритмы обучения с подкреплением в среде Atari. Предложенный вариант алгоритма генерации вектора признаков на основе распознавания образов позволяет увеличить скорость и качество обучения, производя при этом обработку видеопотока в режиме реального времени. При помощи рассмотренных алгоритмов обучения с подкреплением можно решить другие важные задачи, стоящие перед искусственным интеллектом, в том числе создание роботов, способных обучаться подобно человеку, передвигаться на ногах, самостоятельно принимать решения и научиться понимать естественный язык. Литература 1. Рассел С., Норвиг П. Искусственный интеллект. Современный подход. М.: Вильямс, 2007. 1410 с. 2. Mnih V., Kavukcuoglu K., Silver D., Graves A., Antonoglou I., Wierstra D., Riedmiller M. Playing Atari with deep reinforcement learning. NIPS Deep Learning Workshop, 2013. URL: https://arxiv.org/pdf/1312.5602.pdf (дата обращения: 08.02.2018). 3. Саттон Р.С., Барто Э.Г. Обучение с подкреплением. М.: Бином, 2017. 400 с. 4. Гудфеллоу Я., Бенджио И., Курвилль А. Глубокое обучение. М.: ДМК-Пресс, 2017. 652 с. 5. Melo F.S. Convergence of Q-learning: A simple proof. Tech. Rep. 2011. URL: http://users.isr.ist.utl.pt/~mtjspaan/readingGroup/ProofQlearning.pdf (дата обращения: 08.02.2018). 6. Mnih V. Human-level control through deep reinforcement learning. Nature, 2015, vol. 518, no. 7540, pp. 529–533. 7. Schaul T., Quan J., Antonoglou I., Silver D. Prioritized experience replay. Proc. ICLR-16. 2016. URL: http://www0.cs.ucl. ac.uk/staff/d.silver/web/Publications_files/prioritized-replay.pdf (дата обращения: 08.02.2018). 8. Silver D., Lever G., Heess N., Degris T., Wierstra D., Riedmiller M. Deterministic policy gradient algorithms. Proc. ICML-14. 2014. URL: http://www0.cs.ucl.ac.uk/staff/d.silver/web/Publications_files/deterministic-policy-gradients.pdf (дата обращения: 08.02.2018). 9. Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. СПб: Питер, 2017. 480 с. 10. Mnih V., Badia A.P., Mirza M., Graves A., Harley T., Lillicrap T.P., Silver D., Kavukcuoglu K. Asynchronous methods for deep reinforcement learning. Proc. ICML-16, 2016. URL: https:// arxiv.org/pdf/1602.01783.pdf (дата обращения: 08.02.2018). 11. Liu D.R., Li H.L., Wang D. Feature selection and feature learning for high-dimensional batch reinforcement learning: A sur- vey. Intern. J. Automation and Computing. 2015, vol. 12, pp. 229–242. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
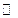 и фактору дисконтирования γ, где Dist(S) – пространство всех распределений вероятности на множестве X. В среде Atari предполагается, что S и A – конечные множества. На каждом шаге t агент исследует состояние st Î S и выбирает действие at Î A. Далее агент получает награду rt : = R(st, at) и новое состояние st+1 из распределения P(×|st, at). В МППР переходы удовлетворяют свойству марковости: для любых st+1 и для любой истории состояний и действий s0, a0, …, st, at выполняется следующее равенство:
и фактору дисконтирования γ, где Dist(S) – пространство всех распределений вероятности на множестве X. В среде Atari предполагается, что S и A – конечные множества. На каждом шаге t агент исследует состояние st Î S и выбирает действие at Î A. Далее агент получает награду rt : = R(st, at) и новое состояние st+1 из распределения P(×|st, at). В МППР переходы удовлетворяют свойству марковости: для любых st+1 и для любой истории состояний и действий s0, a0, …, st, at выполняется следующее равенство: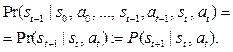 (1)
(1)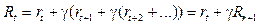 .
.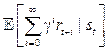 , где последовательность будущих состояний {st+1, st+2, …} индуцируется функцией перехода P и стратегией π.
, где последовательность будущих состояний {st+1, st+2, …} индуцируется функцией перехода P и стратегией π.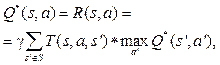 (2)
(2)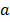 в различных состояниях s, учитывая при этом награду r и следующее состояние s’. Правило итеративного обновления оценки Q выглядит следующим образом:
в различных состояниях s, учитывая при этом награду r и следующее состояние s’. Правило итеративного обновления оценки Q выглядит следующим образом: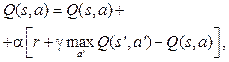 (3)
(3)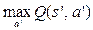 может быть далека от истинного значения, но по мере обновления Q(s, a) гарантируется сходимость к истинной функции [5]. Основная идея алгоритма Q-обучения выглядит следующим образом:
может быть далека от истинного значения, но по мере обновления Q(s, a) гарантируется сходимость к истинной функции [5]. Основная идея алгоритма Q-обучения выглядит следующим образом: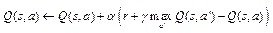
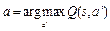
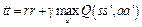
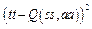
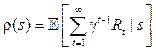 . (4)
. (4)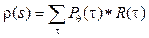 , (5)
, (5)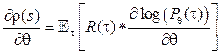 . (6)
. (6)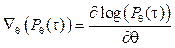 – это вектор, направленный в сторону возрастания функции ρ(s). Аппроксимируя математическое ожидание
– это вектор, направленный в сторону возрастания функции ρ(s). Аппроксимируя математическое ожидание 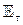 средним арифметическим по T переходам в рамках одного эпизода (игры), получаем правило обновления вектора коэффициентов θ, максимизирующее функцию суммарной награды:
средним арифметическим по T переходам в рамках одного эпизода (игры), получаем правило обновления вектора коэффициентов θ, максимизирующее функцию суммарной награды: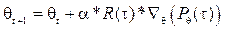 . (7)
. (7)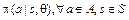
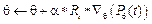
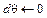 и
и 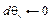
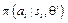
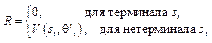
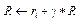
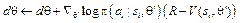
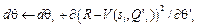
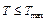
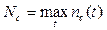 – максимально возможное число объектов класса
– максимально возможное число объектов класса 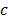 , которые встретились в последовательности изображений экрана [X1, X2, …, Xn]. Тогда для нахождения числа Nc для каждого класса c Î C необходимо на этапе предобработки сохранять и максимальное количество встретившихся объектов каждого класса.
, которые встретились в последовательности изображений экрана [X1, X2, …, Xn]. Тогда для нахождения числа Nc для каждого класса c Î C необходимо на этапе предобработки сохранять и максимальное количество встретившихся объектов каждого класса.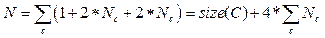 . (8)
. (8)| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4457&lang= |
Версия для печати Выпуск в формате PDF (19.46Мб) |
| Статья опубликована в выпуске журнала № 2 за 2018 год. [ на стр. 284-290 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Программное обеспечение для автоматизированного обнаружения и оценки разрушений соединительных швов зданий
- Выделение и анализ скелетов объектов на цветных снимках
- Реализация методов обучения с подкреплением на основе темпоральных различий и мультиагентного подхода для интеллектуальных систем реального времени
- Система автоматического картографирования знаков дорожного движения
- Разработка системы стереозрения для мобильного робота
Назад, к списку статей