Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Модель надежности отказоустойчивого кластера с миграцией виртуальных машин
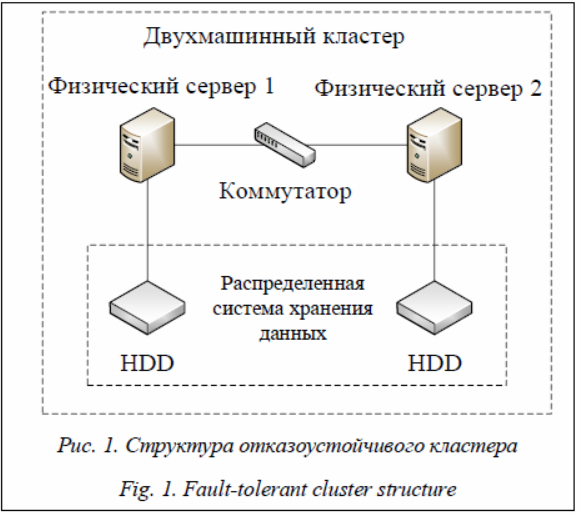
Аннотация:Обеспечение высокой надежности, отказоустойчивости и непрерывности вычислительного процесса компьютерных систем поддерживается при объединении вычислительных ресурсов в кластеры и основывается на использовании технологии виртуализации в результате перемещения виртуальных ресурсов, служб или приложений между физическими серверами при поддержке непрерывности вычислительных процессов. В качестве объекта исследования рассматривается отказоустойчивый кластер, который в простейшем случае состоит из двух физических серверов (основного и резервного), связанных через коммутатор. В каждом сервере установлен локальный жесткий диск. На локальных дисках серверов развернута распределенная система хранения данных с синхронной репликацией данных с исходного сервера на резервный. На кластере запущена виртуальная машина. Система предполагает запуск теневой копии виртуальной машины на резервном сервере, что позволяет в случае отказа основного сервера продолжить вычислительный процесс на виртуальной машине резервного сервера. В качестве показателя надежности используются коэффициенты стационарной и нестационарной готовности. Предложена марковская модель надежности отказоустойчивого кластера, учитывающая издержки на миграцию виртуальных машин, а также механизмы, обеспечивающие непрерывность вычислительного процесса (сервиса) в кластере в случае отказа одного физического сервера. В результате миграции в памяти поддерживаются две копии виртуальной машины, расположенные на разных физических серверах, чтобы в случае отказа одного из них продолжить работу на другом. Построена упрощенная модель отказоустойчивого кластера, пренебрегающая издержками на миграцию виртуальных машин при восстановлении кластера и дающая верхнюю оценку надежности. Показано существенное влияние на надежность отказоустойчивого кластера (оцениваемую по нестационарному коэффициенту готовности) процесса ми-грации виртуальных машин. Полученные результаты могут быть использованы при обосновании выбора технологии обеспечения отказоустойчивости и непрерывности вычислительного процесса компьютерных систем кластерной архитектуры.
Abstract:Ensuring high reliability, fault tolerance and computing process continuity of computer systems is supported by clustering computing re-sources. It is based on the virtualization technology as a result of moving virtual resources, services, or applications between physical servers with the support of computing process continuity. The object of study is a fault-tolerant cluster, which in the simplest case consists of two physical servers (primary and backup) connected through a switch. Each server has a local hard disk. Server local disks have a distributed storage system with data synchronous replication from the source server to the backup server. The virtual machine is running on the cluster. The system involves running a shadow copy of the virtual machine on a backup server, which allows computational process implementation without interruption after the primary server fails to continue its implementation on the virtual machine backup server. Stationary and nonstationary availability coefficients are used as a reliabil-ity indicator. The paper proposes the Markov reliability model of a fault-tolerant cluster, which takes into account virtual machine migration costs, as well as mechanisms ensuring the continuity of the computing process (service) in the cluster in case of one physical server failure. After mi-gration, two copies of virtual machines located in different physical servers are supported in memory, so that in case of failure of one of them to continue working on the second one. There is a developed simplified model of a fault-tolerant cluster that ignores the costs of virtual machine migration when restoring a clus-ter. It gives an upper reliability evaluation. The paper shows the notable impact of the virtual machine migration process on the failover clus-ter reliability (measured by a non-stationary availability coefficient). The obtained results can be used to justify the choice of fault tolerance and continuity of the computing process of computer systems of cluster architecture.
| Авторы: Алексанков С.М. (aleksankov.sergey@gmail.com) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (инженер-исследователь), Санкт-Петербург, Россия, кандидат технических наук, Богатырев В.А. (vladimir.bogatyrev@gmail.com ) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (Университет ИТМО) (профессор), Санкт-Петербург, Россия, доктор технических наук, Деркач А.Н. (chegguevara-1928@mail.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (аспирант), Санкт-Петербург, Россия | |
| Ключевые слова: нестационарный коэффициент готовности, кластеры, резервирование, отказоустойчивость, надежность, виртуализация |
|
| Keywords: non-stationary availability coefficient, clusters, reservation, fail-safety, reliability, virtualization |
|
| Количество просмотров: 6982 |
Статья в формате PDF Выпуск в формате PDF (6.60Мб) |
К современным системам обработки, хранения и передачи данных различного назначения, в том числе к киберфизическим и инфокоммуникационным, предъявляются высокие требования по надежности, безопасности, отказоустойчивости и низкой стоимости реализации и эксплуатации [1–3]. Требования, предъявляемые к компьютерным системам, во многом зависят от выполняемых ими прикладных задач, их критичности к задержкам и непрерывности обслуживания, особенностей эксплуатации и ее сложности [4–6]. Высокая надежность, отказоустойчивость и готовность компьютерных систем к критическому применению достигаются при консолидации ресурсов обработки и хранения данных на основе технологии кластеризации, динамического распределения запросов [7–9] и виртуализации. В кластерной системе с виртуализацией в случае отказов или отключений физических серверов для профилактических или иных работ работоспособность обеспечивается в результате перемещения виртуальных ресурсов, служб или приложений между физическими серверами [10] при поддержке непрерывности вычислительных процессов. Современные технологии виртуализации основываются на целенаправленной миграции виртуальных ресурсов между физическими серверами с целью адаптации кластерных систем к накоплению отказов физических серверов [8]. При миграции виртуальных машин (ВМ) в кластере может использоваться общее хранилище данных с виртуальными дисками ВМ, что ускоряет процесс миграции в результате переноса только оперативной памяти, регистров виртуальных процессоров и состояния виртуальных устройств ВМ [11–13]. В кластере без реализации общей системы хранения данных при миграции дополнительно перемещается содержимое виртуальных дисков ВМ, объем которых может быть значительным, что замедляет процесс миграции. Процесс миграции виртуальных ресурсов может дополнительно замедляться в случае их перемещения через сеть [14–16]. В процессе динамической миграции можно выделить этапы передачи данных (регистры ВМ, оперативная память, диск(и)) на резервный сервер и активизации функционирования на нем ВМ [17, 18]. Технология виртуализации, направленная на обеспечение высокой надежности компьютерных систем, включает технологии «Высокая доступность» (High Availability Cluster) и «Отказоустойчивость» (Fault Tolerance), первая из которых поддерживает автоматический перезапуск ВМ на работоспособных узлах кластера [12], а вторая – непрерывность вычислительного процесса при его перемещении на ВМ одного из серверов кластера, сохранивших работоспособность [13]. Технология «Высокая доступность» позволяет автоматически перемещать ВМ с отказавшего сервера на работоспособный. Восстановление функционирования ВМ может происходить за несколько минут в зависимости от конфигурации и загрузки физического сервера и свойств пользовательских приложений. При этой технологии для автоматического перезапуска ВМ все их данные должны храниться на общем хранилище данных, которое может быть реализовано в виде или устройства, подключенного ко всем узлам кластера, или распределенной системы хранения данных [10]. После отказа какого-либо физического сервера в других серверах могут запускаться ВМ, используя виртуальные диски ВМ, располагающиеся на общем хранилище. При этом теряется состояние ВМ, в том числе данные в оперативной памяти, регистры виртуальных процессоров и состояния внешних устройств. Поэтому системе требуется время для инициализации ВМ и приведения ее к состоянию перед отказом. Для корректной работы данного механизма виртуализации необходимо обеспечить изоляцию физических серверов после отказа, чтобы при перезапуске исключить одновременное выполнение вычислительного процесса двумя ВМ с целью исключения неоднозначности данных в общем хранилище. Технология «Высокая доступность» предполагает, что после отказа любого физического сервера функционирующие на нем ВМ автоматически распределяются по уцелевшим узлам и перезапускаются на них. Состояние оперативной памяти всех ВМ, находившихся на отказавшем узле, теряется. Технология «Отказоустойчивость» обеспечивает непрерывность вычислительного процесса (сервиса) в кластере после отказа одного физического сервера при поддержке двух копий ВМ в оперативной памяти, расположенных на разных физических серверах, чтобы в случае отказа одного из них продолжить работу на другом. Для рассматриваемой организации вычислительного процесса во время функционирования ВМ на одном из серверов на другом должна поддерживаться актуальная копия оперативной памяти [10] активной ВМ. При этом образы виртуальных дисков ВМ должны храниться в выделенном или распределенном хранилище данных с синхронной репликацией данных. К программным продуктам, поддерживающим технологию отказоустойчивости, можно отнести VMware Fault Tolerance, Kemari для Xen и KVM [17, 18]. Указанные механизмы виртуализации влияют на надежность кластерной системы, что необходимо учитывать при обосновании структуры системы, организации вычислительных процессов и дисциплин восстановления и обслуживания высоконадежных кластерных систем. Обоснование выбора проектных решений построения высоконадежных кластерных систем должно опираться на моделирование [19–21] при оценке надежности, готовности, отказоустойчивости и производительности рассматриваемых реализаций. Целью авторов статьи является построение моделей кластерных систем, позволяющих оценить влияние процесса виртуализации на их надежность. Рассматриваемые модели ориентированы на обоснование выбора структуры и дисциплины обслуживания и восстановления кластера с учетом требований к реализуемым прикладным задачам и используемых механизмов виртуализации [10]. Объект исследования Рассмотрим высоконадежный кластер, реализованный на базе технологии виртуализации, ориентированной на поддержку непрерывности сервиса (вычислительного процесса).
Система предполагает запуск теневой копии ВМ на резервном сервере, что позволяет после отказа основного сервера без прерываний продолжить вычислительный процесс на ВМ резервного сервера. Поддержка непрерывности вычислительного процесса при автоматическом восстановлении функционирования после отказов (реконфигурация) требует: - постоянной синхронизации оперативной памяти и дисковых данных, для чего возможно использование высокоскоростных сетевых адаптеров и коммутаторов второго уровня, например, 10G Ethernet или InfiniBand; - организации в серверах распределенной системы хранения данных, поддерживающей синхронную репликацию дисковых данных с основного на резервный сервер или отдельного сервера для организации внешней общей системы хранения данных. Рассмотрим восстановление ресурсов системы, теряемых в результате отказов, осуществляемое сразу после отказа (предполагает мгновенное определение возникновения отказа средствами контроля, наличие комплекта ЗИП, приспособлений и персонала, готовых к проведению ремонтных работ). Для отказоустойчивых кластерных систем в качестве показателя надежности воспользуемся коэффициентами стационарной и нестационарной готовности [22, 23]. Модель надежности отказоустойчивого кластера с оперативным восстановлением
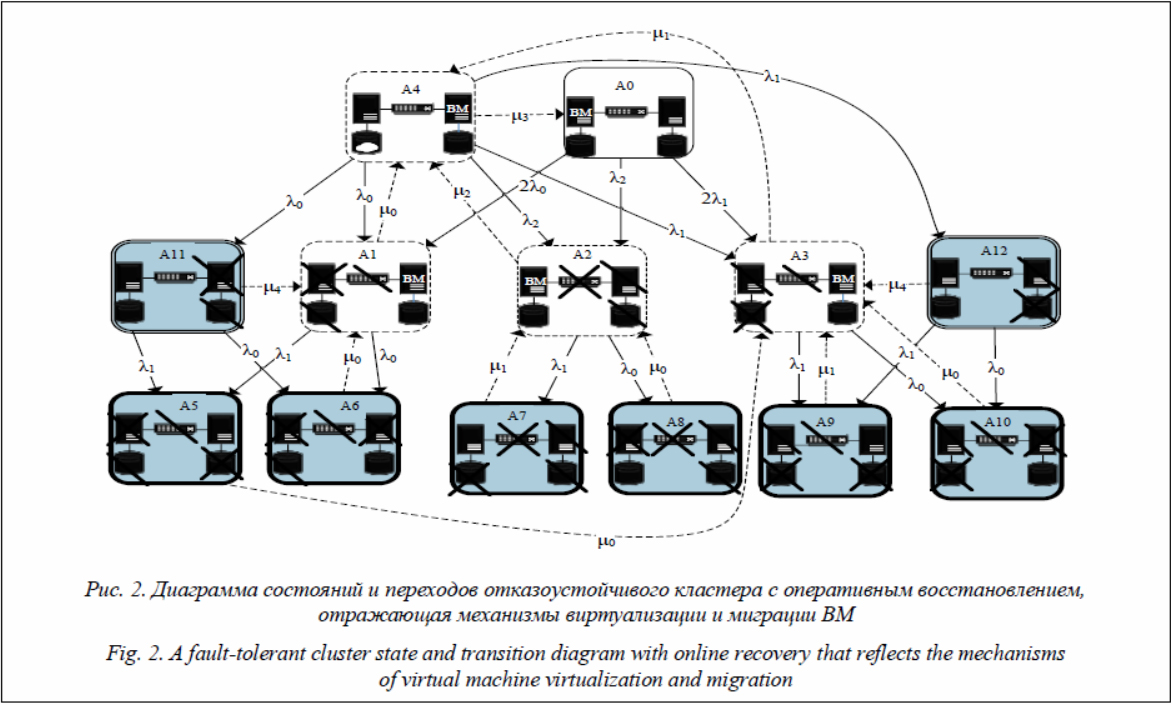
На рисунке исправные состояния кластера (работоспособные состояния без отказавших узлов) обозначены вершинами, обведенными сплошной линией, работоспособные состояния с отказавшими узлами – пунктирной, неработоспособные состояния, в которых происходит автоматическое восстановление пользовательского сервиса, – двойной сплошной, неработоспособные состояния, в которых ожидается восстановление узлов ремонтником, – жирной сплошной линией. Пометка «ВМ» на вершинах графов обозначает сервер, на котором запущена в данный момент ВМ с виртуальным сервисом. Перечеркнутая двумя линиями вершина обозначает отказ узла, одной линией – состояние узла, при котором он в данный момент не функционирует и, соответственно, не отказывает. На диаграмме обозначены интенсивности отказов (λ0, λ1, λ2) и восстановлений (μ0, μ1, μ2) сервера, диска и коммутатора соответственно. Интенсивность восстановления (синхронизации системы распределенного хранилища), включающего занесение актуальной реплики данных на восстановленный диск, – μ3. Интенсивность восстановления ВМ после автоматического перезапуска, включающего запуск ВМ на резервном сервере и загрузку на нем приложения пользователя, – μ4. Для нахождения искомых вероятностей состояний по приведенным диаграммам состояний и переходов составляются системы алгебраических уравнений при оценке стационарного коэффициента готовности или дифференциальных уравнений при оценке нестационарного коэффициента готовности [23, 26]. Систему дифференциальных уравнений в соответствии с диаграммой состояний и переходов (рис. 2) представим следующим образом:
Система дифференциальных уравнений, соответствующая диаграмме состояний и переходов, приведенной на рисунке 3, имеет вид:
Результаты расчета коэффициентов нестационарной готовности кластера по моделям, соответствующим диаграммам на рисунках 2 и 3, показаны на рисунке 4. На рисунке 4 кривые 1 и 2 соответствуют оценке нестационарных коэффициентов готовности К1(t) и К2(t) на основе диаграмм на рисунках 2 и 3. Кривая 3 на рисунке 4 соответствует разнице d = К2(t) – К1(t). Расчет выполнен при следующих интенсивностях отказов сервера, диска, коммутатора: λ0 = 1,115 10-5 1/ч, λ1 = 3,425×10-6 1/ч, λ2 = 2,3×10-6 1/ч и интенсивностях их оперативного восстановления соответственно: μ0 = 0,33 1/ч, μ1 = 0,17 1/ч, μ2 = 0,33 1/ч. Интенсивность синхронизации системы распределенного хранилища: μ3 = 1 1/ч, μ4 = 2 1/ч. Расчеты выполнены в системе компьютерной математики Mathcad-15.
Заключение Таким образом, предложена марковская модель надежности отказоустойчивого кластера, учитывающая издержки на миграцию ВМ. Построена упрощенная модель отказоустойчивого кластера, пренебрегающая издержками при восстановлении на миграцию ВМ. Показано существенное влияние на надежность отказоустойчивого кластера (оцениваемую по нестационарному коэффициенту готовности) учета механизмов виртуализации, в том числе миграции ВМ. Литература 1. Kopetz H. Real-time systems: design principles for distributed embedded applications. Springer, 2011, 396 p. 2. Sorin D. Fault tolerant computer architecture. Morgan & Claypool, 2009, 103 p. 3. Верзун Н.А., Колбанев М.О., Татарникова Т.М. Технологическая платформа четвертой промышленной революции // Геополитика и безопасность. 2016. № 2. С. 73–78. 4. Абрамян Г.В. Структура и функции информационной системы мониторинга и управления рисками развития малого и сред- него бизнеса Северо-Западного федерального округа // Аудит и финансовый анализ. 2017. № 5–6. С. 611–617. 5. Velichko E.N., Grishentsev A.Y., Korobeynikov A.G. Inverse problem of radiofrequency sounding of ionosphere. Intern. J. of Mod-ern Physics A, IET, 2016, vol. 31, no. 2–3, art. 1641033. 6. Богатырев В.А., Богатырев С.В. Резервированное обслуживание в кластерах с уничтожением неактуальных запросов // Вестн. компьютер. и информ. технологий. 2017. № 1. С. 21–28. 7. Богатырев В.А., Богатырев С.В., Богатырев А.В. Надежность кластерных вычислительных систем с дублированными связями серверов и устройств хранения // Информационные технологии. 2013. № 2. С. 27–32. 8. Богатырев В.А., Богатырев А.В., Голубев И.Ю., Богаты- рев С.В. Оптимизация распределения запросов между кластерами отказоустойчивой вычислительной системы // Науч.-технич. вестн. СПбГУИТМО. 2013. № 3. С. 77–82. 9. Богатырев В.А., Богатырев С.В., Богатырев А.В. Оптимизация древовидной сети с резервированием коммутационных узлов и связей // Телекоммуникации. 2013. № 2. С. 42–48. 10. Алексанков С.М. Модель процесса динамической миграции с копированием данных после остановки виртуальных машин // Изв. вузов: Приборостроение. 2016. Т. 59. № 5. С. 173–178. 11. Как «быть готовым» или DR на Nutanix: асинхронная репликация. 2015 // Блог компании Nutanix. URL: https://habrahabr.ru/ company/nutanix/blog/250197/ (дата обращения: 25.04.2018). 12. Самойленко А. Требования и ограничения VMware Fault Tolerance. 2010 // портал VM Guru. URL: http://www.vmgu.ru/articles/ vmware-fault-tolerancemain (дата обращения: 25.04.2018). 13. Общее представление о конфигурациях кворума в отказоустойчивом кластере. URL: https://technet.microsoft.com/ru-ru/ library/cc731739(v=ws.11).aspx (дата обращения: 25.04.2018). 14. Татарникова Т.М. Аналитико-статистическая модель оценки живучести сетей с топологией mesh // Информационно-управляющие системы. 2017. № 1. С. 17–22. 15. Абрамян Г.В. Модели и технологии оптимизации телекоммуникаций в науке и образовании Северо-Западного региона на основе использования saas/sod облачных сервисов // ИТСиТ: сб. тр. Всерос. науч.-практич. конф. 2015. С. 27. 16. Алиев Т.И., Муравьева-Витковская Л.А. Приоритетные стратегии управления трафиком в мультисервисных компьютерных сетях // Изв. вузов: Приборостроение. 2011. Т. 54. № 6. С. 44–48. 17. Технология Kemari // xguru.ru: портал обмена знаниями по UNIX/Linux-системам, системам с открытым исходным кодом, сетям и другим родственным вещам. URL: http://xgu.ru/wiki/Kemari (дата обращения: 25.04.2018). 18. Елизаров Е. Dell Live Volume: виртуализуем дисковое пространство. URL: https://onlanta.ru/press/blogs/evgeniy-elizarov/32031/ (дата обращения: 25.04.2018). 19. Кутузов О.И., Татарникова Т.М. Инфокоммуникационные сети. Моделирование и оценка вероятностно-временных характеристик. СПб: Изд-во ГУАП, 2015. 382 с. 20. Gatchin Y.A., Zharinov I.O., Korobeynikov A.G., Zhari- nov O.O. Theoretical estimation of Grassmann's transformation resolution in avionics color coding systems. MAS, 2015, vol. 9, no. 5, pp. 197–210. 21. Жмылев С.А., Мартынчук И.Г., Киреев В.Ю., Алиев Т.И. Оценка длины периода нестационарных процессов в облачных системах // Изв. вузов: Приборостроение. 2018. Т. 61. № 8. С. 645–651. 22. Черкесов Г.Н. Надежность аппаратно-программных комплексов. СПб: Питер, 2005. 479 с. 23. Половко А.М., Гуров С.В. Основы теории надежности. СПб: БХВ-Петербург, 2006. 704 с. 24. Шубинский И.Б. Надежные отказоустойчивые информационные системы. Методы синтеза. Ульяновск: Печатный двор, 2016. 544 с. 25. Алиев Т.И. Основы моделирования дискретных систем. СПб, 2009. 363 с. 26. Шубинский И.Б. Структурная надежность информационных систем. Методы анализа. Ульяновск: Печатный двор, 2012. 296 с. References
|
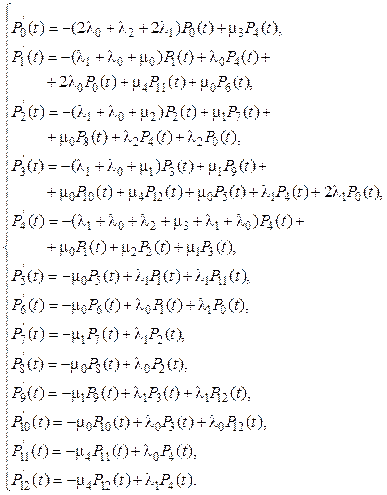

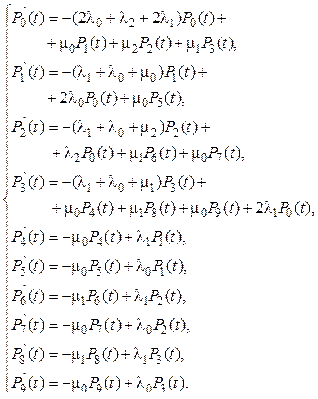

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4563 |
Версия для печати Выпуск в формате PDF (6.60Мб) |
| Статья опубликована в выпуске журнала № 1 за 2019 год. [ на стр. 103-108 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Фазовый переход наработки на отказ в растущих вычислительных сетях
- Повышение коэффициента сохранения эффективности вычислительного комплекса при использовании средств виртуализации
- Особенности модернизации центра обработки данных и космоцентра
- Опыт разработки программ для кластеров на механико-математическом факультете МГУ
- Методы сокращения количества уязвимостей в специальном программном обеспечении реального времени
Назад, к списку статей