Модифицированный алгоритм обучения нейронных сетей
| Зуев В.Н. (zvn_tver@mail.ru) - НИИ «Центрпрограммсистем», Тверской государственный технический университет (зав. лабораторией), Тверь, Россия, Аспирант , Кемайкин В.К. (vk-kem@mail.ru) - Тверской государственный технический университет, кафедра «Информационные системы» (доцент), Тверь, Россия, кандидат технических наук | |
| Ключевые слова: нейронная сеть, обратное распространение, целевая функция, функция ошибки, алгоритм обучения |
|
| Keywords: neural network, backpropagatio, objective function, error function, learning algorithm |
|
|
|
|
В статье представлен метод отбора примеров в обучающую выборку с учетом их влияния на процесс обучения сети. Показано, что в задаче обучения сети с учителем при использовании пакетного режима [1] скорость обучения и качество работы обученной нейронной сети зависят от величины ошибки на выходе, обусловленной не только уровнем обученности сети, но и характеристиками обучающей выборки: типичностью примеров, их количеством для различных исходов, а также достоверностью. Целью работы является повышение качества обучения сети за счет оценки обучающего множества и формирования обучающей выборки. Обучение нейронной сети – это процесс минимизации в пространстве обучаемых параметров функции оценки. При использовании метода обратного распространения ошибки корректировка синаптической карты весов нейронной сети выполняется после подачи всех обучающих примеров по усредненному значению градиента целевой функции, формулируемой в виде квадратичной суммы разностей между фактическими и ожидаемыми значениями выходных сигналов [2]:
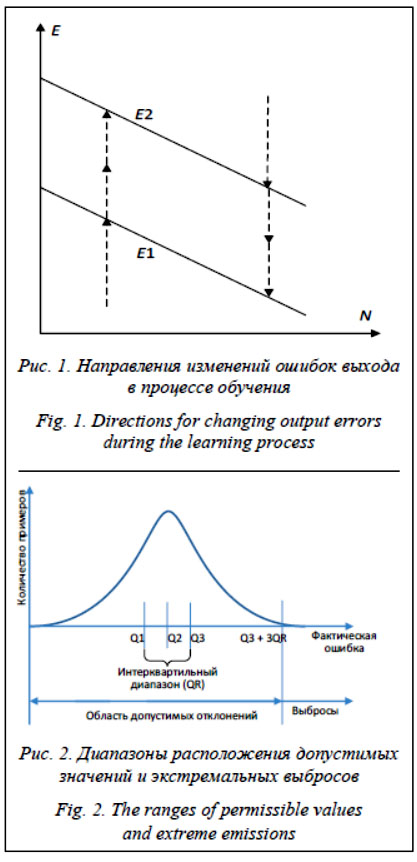
где y – выходное значение нейронной сети; d – желаемое значение выхода; m – количество нейронов в выходном слое; k – номер нейрона в выходном слое. Основная идея рассматриваемого в данной работе подхода состоит в том, что используемые для обучения примеры должны получать весовые коэффициенты, улучшающие нейронную сеть, полученную в процессе обучения. Необходимость использования весов примеров при обучении может быть обусловлена следующими причинами: 1) один из примеров плохо обучается; 2) число примеров разных классов в обучающем множестве сильно отличается; 3) примеры в обучающем множестве имеют различную достоверность [3]. Первая причина актуальна в случае, когда имеется априорная информация о значимости примера и необходимо, чтобы нейронная сеть научилась его воспринимать. Однако в силу своих особенностей пример не учитывается при обучении нейронной сети обычными методами. Вторая причина актуальна для случая, когда в обучающей выборке есть классы, число примеров которых мало по сравнению с другими классами. В пакетном режиме обучения ошибка, рассчитанная по этим примерам, может потеряться в суммарной ошибке по всей выборке, в результате чего такие примеры могут быть проигнорированы. Ошибка по этим примерам останется большой, и нейронная сеть не научится их воспринимать. По этой причине существует критика пакетного режима обучения. Так, в работе [4] показывается преимущество online-обучения в контексте объема вычислений, осуществляемых в процессе обучения. Однако последовательный режим обучения не решает данную проблему. Еще одним подходом, используемым для решения данной проблемы, является уменьшение размеров нейронной сети. В работе [5] доказана несостоятельность данного метода. Третья причина актуальна при наличии в данных ошибочных значений – выбросов, которые могут давать большую ошибку. Пытаясь научиться воспринимать такие значения, нейронная сеть может ухудшить свою способность к обобщению [6]. Для решения проблемы, вызванной первой и второй причинами, обучающим примерам необходимо присвоить весовые коэффициенты. Они будут использоваться при расчете ошибки обучения E и усиливать вклад выбранных примеров в суммарную ошибку обучения. Для решения третьей проблемы в работе [7] предложена редукция данных, основанная на ограничении диапазона значений признака, однако при данном подходе существует вероятность исключения значимых примеров. Учитывая все перечисленные особенности, становится очевидной необходимость более эффективного представления обучающей выборки. Так, в работе [8] предлагается задавать пороговое значение ошибки, при превышении которого пример не должен рассматриваться. Более гибкий подход реализован в Lazy training (ленивое обучение) [9], однако этот алгоритм предназначен исключительно для задач классификации. Его основная идея заключается в том, что для коррекции весов используются только те наблюдения, которые были классифицированы неправильно. Помимо узкой направленности, этот алгоритм имеет и другие недостатки. Для решения проблемы, вызван- ной третьей причиной, необходим алгоритм, учитывающий описанные недостатки. Основная идея рассматриваемого подхода состоит в том, что обучающие примеры, ошибки по которым оказываются слишком большими, не должны участвовать в обучении нейронной сети. Однако задание граничного значения ошибки, разделяющего исходное множество на используемые и неиспользуемые примеры, неэффективно. Если использовать для обучения часть примеров, то ошибка выхода по ним будет постепенно уменьшаться. При этом ошибка на неиспользуемых примерах может расти. Таким образом, использование граничного значения может привести к следующему эффекту. Если ошибка, полученная на рассматриваемом примере, меньше заданного значения, то при следующей итерации этот пример не будет использован. При этом ошибка по этому примеру может вырасти и снова преодолеть установленную границу. При очередной итерации данный пример опять будет использован в обучающей выборке. В результате нейронная сеть перестанет обучаться. Для избежания подобного эффекта предложено использовать два граничных значения ошибки обучения: нижнее (E1) и верхнее (E2), которые определяют три области и являются функцией количества циклов обучения. Для каждого примера в зависимости от значения ошибки E и его положения относительно значений E1 и E2 принимается решение о выборе значения весового коэффициента: - E < E1 – пример не усиливается весовым коэффициентом (получает весовой коэффициент, равный единице); - E1 < E < E2 – пример усиливается весовым коэффициентом; - E > E2 – пример игнорируется (получает нулевой весовой коэффициент). Весовые коэффициенты рассчитываются индивидуально для каждого примера на каждом шаге обучения. В начале процесса обучения используются все имеющиеся примеры. Поскольку нейронная сеть перед началом обучения инициализируется случайными значениями, распределение ошибок по используемым примерам равномерно. При этом ошибки по всем примерам не превышают значение E2. В процессе обучения нейронной сети ошибка обучения приобретает нормальный вид распределения. У большинства примеров ошибка стремится к нулю, у части примеров она остается большой. Попав в интервал E1 < E < E2, пример получает весовой коэффициент и ошибка по нему начинает уменьшаться быстрее. Как только ошибка примера пересекает границу E1, он получает единичный коэффициент. Если при дальнейшем обучении ошибка примера превысит E1, он снова получит усиливающий весовой коэффициент. Если ошибка примера превысила значение E2, то пример считается выбросом и не участвует в дальнейшем обучении. Направления изменений ошибок показаны пунктирными стрелками на рисунке 1. Граничные значения E1 и E2 рассчитываются на каждом шаге обучения сети. Для расчета значений E1 и E2 используется критерий, основанный на интерквартильном размахе. Метод основан на вычислении трех квартилей, делящих данные на четыре равные группы по ошибке обучения. Интерквартильный размах [10] считается как разность между первой и третьей квартилями: IQR = Q3 – Q1. (2) Значения E1 и E2 рассчитываются следующим образом: E1 = Q1, (3) E2 = Q3 + QR. (4) На рисунке 2 показана схема, выражающая эти определения.
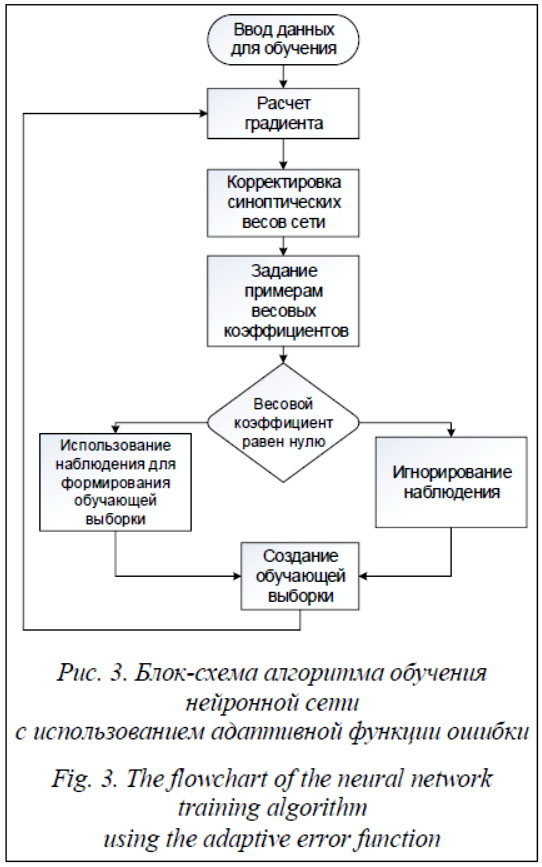
Предложенная реализация алгоритма обучения позволяет избежать переобучения нейронной сети, связанного с чрезмерным стремлением достичь нулевой ошибки. При этом данный алгоритм в большей степени учитывает свойства малочисленных групп примеров, чем стандартный алгоритм. Блок-схема алгоритма изображена на рисунке 3. Таким образом, алгоритм будет следующим. Шаг 1. Формируем обучающую выборку, используя все обучающее множество. Шаг 2. Вычисляем значение среднего градиента для предоставленной выборки. Шаг 3. Выполняем корректировку весов нейронной сети. Шаг 4. Устанавливаем веса примерам, используя данные об ошибках выхода. Для этого создается матрица, содержащая флаг для каждого наблюдения. Если ошибка, соответствующая наблюдению, меньше значения ошибки E1, этому наблюдению ставится единичный коэффициент. Если ошибка больше значения ошибки E2, наблюдению ставится нулевой коэффициент. Если ошибка находится в диапазоне E1–E2, наблюдению ставится усиливающий коэффициент. Шаг 5. Используя полученный набор флагов, разделяем выборку на две части: используемую для следующего уточнения весов нейронной сети и игнорируемую. Шаг 6. Создаем новую обучающую выборку для следующей итерации. Шаг 7. Возвращаемся к шагу 2.
Литература 1. Дьяконов В.П., Круглов В.В. MATLAB 6.5 SP1/7/7 SP1/7 SP2 + Simulink 5/6. Инструменты искусственного интеллекта и биоинформатики. М.: Солон-Пресс, 2006. 456 с. 2. Оссовский С. Нейронные сети для обработки информации; [пер. с польск. И.Д. Рудинского]. М.: Финансы и статистика, 2004. 344 с. 3. Миркес Е.М. Нейроинформатика. Красноярск: Изд-во КГТУ, 2002. 347 с. 4. Царегородцев В.Г. Общая неэффективность использования суммарного градиента выборки при обучении нейронной сети // Нейроинформатика и ее приложения: матер. XIII Всерос. семинара. 2004. С. 145–151. 5. Царегородцев В.Г. Редукция размеров нейросети не приводит к повышению обобщающей способности // Нейроинформатика и ее приложения: матер. XII Всерос. семинара. Красноярск, 2004. С. 163–165. 6. Хайкин С. Нейронные сети: полный курс; [пер. с англ. Н.Н. Куссуль, А.Ю. Шелестова]. М.: Вильямс, 2006. 1104 с. 7. Царегородцев В.Г. Оптимизация предобработки данных для обучаемой нейросети: критерии оптимальности предобработки // Междунар. конф. по нейрокибернетике: сб. докл. Ростов н/Д, 2005. Т. 2. С. 64–67. 8. Xiao-Ping Zhang. Thresholding neural network for adaptive noise reduction. Proc. IEEE Transactions on Neural Networks, 2001, vol. 12, no. 3, pp. 567–584. 9. Rimer M.E., Anderson T.L. and Martinez T.R. Improving backpropagation ensembles through lazy training. Proc. IEEE IJCNN’01, 2001, pp. 2007–2112. 10. Певзнер М.З. Систематизация, статистический анализ данных, контроль и управление производственными процессами. Киров: Изд-во ВятГУ, 2012. 165 с. References
|
http://swsys.ru/index.php?page=article&id=4590&lang=%E2%8C%A9=en |
|
Perhaps, you might be interested in the following articles of similar topics:
- Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
- Разработка нейронной сети для оценки исправности гидроагрегата по результатам вибромониторинга
- Информационная и алгоритмическая поддержка интеллектуальной системы экологического мониторинга воздуха на основе нейронных сетей
- Интеллектуальные системы и алгоритмы управления объектами обстановки в тренажерах
- Оценка эффективности тренажерной подготовки методом целевого управления