Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Способы ускорения подготовки и встраивания цифрового водяного знака с использованием мобильных устройств на основе преобразования Арнольда и вейвлет-преобразования
Аннотация:В последние годы технология цифрового маркирования фото- и видеоматериалов приобретает все большее значение из-за взрывного роста объемов информации, передаваемой через незащищенные каналы связи. Встроенные с помощью этой технологии цифровые водяные знаки позволяют сократить объемы передаваемой информации, а также могут применяться для защиты изображений (носителей) от незаконного использования. Для более эффективной реализации послед-ней задачи проводятся различные исследования с целью повышения устойчивости, незаметности и защищенности цифровых водяных знаков. В большинстве случаев это приводит к увеличению требуемой вычислительной мощности, что затрудняет применение цифрового маркирования в мобильных устройствах. В данной работе предложены несколько способов снижения вычислительных затрат и уменьшения времени вычислений методов цифрового маркирования, основанных на преобразовании Арнольда и вейлет-преобразовании. Первый способ заключается в линейной интерпретации цифровых водяных знаков и изображения-носителя, что позволяет избежать использования двойных циклов. Второй способ состоит в применении таблиц преобразований для замены непосредственных вычислений. Одна из таких таблиц позволяет выполнять преобразование Арнольда за определенное время вне зависимости от количества итераций. Для определения количества итераций для каждого блока используются хэш-код секретного ключа и специально сформированные для этого таблицы. Третий способ сокращения времени встраивания цифровых водяных знаков состоит в многопоточном выполнении, реализованном с помощью технологии OpenMP. В совокупности с применением линейной интерпретации это дает ускорение в 1,90, 2,56 и 3,01 раза для двух, трех и четырех потоков соответственно.
Abstract:In recent years, digital watermarking technology has become increasingly important due to the explo-sive growth of data transmitted through unprotected communication channels. Digital watermarks can reduce the amount of transmitted information and be used to protect images (hosts) from illegal use. For a more effective implementation of the latter task, various studies are being carried out in order to improve robustness, imperceptibility and security of the watermark. In most cases, this leads to an in-crease in computational costs, which makes it difficult to use digital watermarking in mobile devices. This work proposes several ways to reduce computational costs and computation time of digital wa-termarking methods based on Arnold and wavelet transforms. The first way consists in linear interpre-tation of digital watermark and a host, so it avoids the use of double cycles. The second way is to use lookup tables (LUT) to replace direct calculations. One of these tables allows performing the Arnold transform in certain time regardless of the number of iterations. Iterations for each block are deter-mined using hash code of the secret key and specially formed tables. The third way of digital water-marks embedding time reduction is multithreaded execution implemented using the OpenMP technolo-gy. In combination with linear interpretation, this results in accelerations of 1.90, 2.56 and 3.01 times for two, three and four threads, respectively.
| Авторы: Зотин А.Г. (zotinkrs@gmail.com) - Сибирский государственный аэрокосмический университет им. акад. М.Ф. Решетнева, г. Красноярск (доцент), г. Красноярск, Россия, кандидат технических наук, Проскурин А.В. (proskurin.av.wof@gmail.com) - Сибирский государственный университет науки и технологий им. академика М.Ф. Решетнева (доцент), Красноярск, Россия, кандидат технических наук | |
| Ключевые слова: openmp, таблицы преобразования, преобразование арнольда, цвз, цифровые водяные знаки |
|
| Keywords: OpenMP, lookup tables, arnold transform, digital watermarks, digital watermarks |
|
| Количество просмотров: 3790 |
Статья в формате PDF |
В связи с активным развитием мобильных и сетевых технологий в последние два десятилетия все большие объемы мультимедийной информации передаются через незащищенные каналы связи. При этом изображения и видео можно свободно копировать, редактировать и распространять, что затрудняет доказательство их авторства. Один из способов решения этой проблемы заключается в использовании цифровых водяных знаков (ЦВЗ). При нанесении ЦВЗ секретная информация, которая обычно представлена в виде небольшого изображения, скрывается внутри основного изображения, называемого носителем, с минимальными визуальными искажениями последнего. При этом ЦВЗ может быть извлечен обратно в исходном виде, что позволяет использовать его в качестве доказательства авторства. Таким образом, ЦВЗ и алгоритм его встраивания должны обладать следующими свойствами [1, 2]: - незаметность – встраивание ЦВЗ не должно приводить к очевидным визуальным искажениям носителя, а сама скрытая информация быть заметной человеку; - устойчивость – распространенные атаки на носитель, такие как сжатие алгоритмом JPEG, фильтрация, обрезка или зеркальное отображение, не должны приводить к существенным искажениям ЦВЗ и затруднять его извлечение; - вместимость – в носитель необходимо встроить как можно больше скрытой информации, продублировав ее для повышения вероятности успешного извлечения или добавив дополнительную информацию об авторе; - низкая вычислительная стоимость – мобильное устройство должно встраивать ЦВЗ в изображение высокого разрешения за приемлемое время. Существуют два основных подхода к встра-иванию ЦВЗ – встраивание информации в про-странственную или частотную область носителя. Пространственные методы основаны на прямом изменении параметров пикселов в выбранном регионе носителя. В качестве параметров могут выступать яркость или интенсивность цветовых каналов RGB. Наиболее известные пространственные методы – наименьшего значащего бита и его модификации [3, 4], а также средних значащих битов и его модификации [5, 6]. Данные методы просты в реализации и позволяют встроить большой объем информации. Однако встроенные ЦВЗ легко обнаруживаются с помощью компьютерного анализа или визуально. Кроме того, эти методы встраивания не способны эффективно противостоять большинству типов атак. Частотные методы обладают более высокой устойчивостью, поскольку ЦВЗ внедряется в частотные коэффициенты носителя (изображения). При этом определение частотных коэффициентов может происходить с использованием различных преобразований: дискретного преобразования Фурье [7], дискретного косинусного преобразования [8], дискретного вейвлет-преобразования (ДВП) и его модификаций [9, 10], сингулярного разложения [11]. Встраивание ЦВЗ в область средних частот позволяет одновременно повысить незаметность и устойчивость знака. Однако объем встраиваемой информации в таком случае существенно ниже, а необходимые вычислительные затраты значительно выше, чем при использовании пространственных методов. Несмотря на это, в последние годы широкое распространение получают именно частотные методы, так как они устойчивы ко многим видам атак [12]. С целью повышения устойчивости и незаметности многие методы используют предварительную обработку ЦВЗ алгоритмами скремблирования. Данные алгоритмы основаны на итерационном изменении положения пикселов изображения посредством матричного преобразования, что позволяет достичь хаотического визуального эффекта. Это дает два положительных эффекта. С одной стороны, скремблирование позволяет равномерно распределять биты ЦВЗ по всему изображению, что повышает устойчивость к таким атакам, как обрезка, шум, сжатие и фильтрация, а также затрудняет обнаружение ЦВЗ с помощью компьютерного анализа. С другой – скремблирование может повысить безопасность передачи секретной информации с помощью ЦВЗ, задавая количество итераций как ключ шифрования. В таком слу-чае только владельцы знают секретный ключ для восстановления ЦВЗ и исходного носителя. В связи с этим достаточно активно разрабатываются новые схемы использования алгоритмов скремблирования при встраивании ЦВЗ. Среди существующих алгоритмов широкое распространение получили преобразование Арнольда [11, 13], отображение пекаря (baker’s map) [14], логистическая хаотическая карта (logistic chaotic map) и преобразование магическим квадратом (magic square transform) [15]. Данные алгоритмы могут быть расширены для использования на разных цветовых каналах и в частотной области изображения. Негативной стороной скремблирования является высокая вычислительная сложность, вызванная необходимостью итеративной обработки всех элементов двумерной матрицы. Некоторые из разработанных методов предполагают дополнительные шаги при подготовке ЦВЗ, направленные на повышение надежности и безопасности передачи данных. Например, в статье [16] текстовая информация кодируется с помощью штрихкода Code 128 для повышения вероятности считывания информации даже при сильных повреждениях ЦВЗ. К полученному изображению штрихкода применяется преобразование Арнольда. После этого биты ЦВЗ встраиваются в области, полученные в ходе двухуровневого ДВП цветового канала Cb. Данный метод позволяет корректно считывать информацию даже при 30-процентном повреждении водяного знака, но требует затрат на преобразования (включая конвертации из одной цветовой модели в другую). Также в последние годы во многих исследованиях встраивание ЦВЗ осуществляется с использованием комбинаций частотных преобразований. Например, в работе [9] предложен метод, комбинирующий гомоморфное преобразование, дискретное избыточное вейвлет-преобразование (ДИВП), преобразование Арнольда и сингулярное разложение. ДИВП применяется к носителю для получения области LL, которая разделяется на компоненты освещения и отражения посредством гомоморфного преобразования. С целью повышения безопасности в такой схеме используется преобразование Арнольда для скремблирования водяного знака, встраиваемого с помощью сингулярных значений компоненты отражения. Данный метод демонстрирует превосходную незаметность и устойчивость ЦВЗ, однако требует огромных вычислительных затрат. Таким образом, методы, основанные на частотном преобразовании и скремблировании, устойчивы ко многим видам атак, однако требуют больших вычислительных затрат. Проводимые исследования, большинство из которых направлено на повышение незаметности и устойчивости ЦВЗ, только увеличивают эти затраты, что затрудняет использование технологии водяных знаков в мобильных устройствах. Для решения этих проблем в данной работе предложены улучшения, направленные на снижение общих вычислительных затрат, а также шифрование данных при подготовке и встраивании ЦВЗ. Встраивание и извлечение информации на основе ДВП
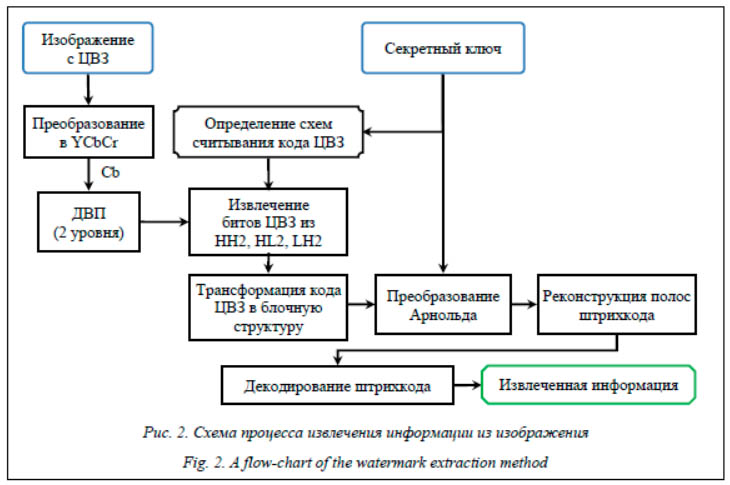
Условно в схеме встраивания информации можно выделить три ключевых этапа: - подготовка информации и формирование ЦВЗ; - определение схемы встраивания; - встраивание ЦВЗ в носитель. В процессе подготовки ЦВЗ выполняется преобразование исходной текстовой инфор-мации с учетом секретного ключа. Для повышения устойчивости ЦВЗ к различным видам атак [12] используется алгоритм преобразования данных в штрихкод (Code 128). Полученное отображение штрихкода имеет ширину модуля в 1 пиксел и высоту 16 пикселов. Для осуществления скремблирования штрихкод делится на сегменты размером 32×16 пикселов, после чего формируются квадратные блоки размером 32×32. К данным блокам применяется разное количество преобразований Арнольда, количество итераций определяется на основе секретного ключа. После преобразования блоки объединяются, формируя код ЦВЗ для встраивания. Если емкость носителя больше встраиваемого ЦВЗ, происходит циклическая запись. Определение схемы встраивания подразу-мевает формирование наборов частотных ко-эффициентов на основе секретного ключа. Для каждой частотной области HH2, HL2 и LH2 формируется свой уникальный список коэффициентов, которые будут использованы для встраивания битов слепка ЦВЗ. Весь процесс встраивания битов ЦВЗ происходит по следующей схеме: - преобразование носителя из цветовой модели RGB в YCbCr; - применение двухуровного дискретного преобразования Хаара к цветовому каналу Cb; - встраивание ЦВЗ с помощью модифицированного алгоритма Коха–Жао в HH2, HL2 и LH2 области; - применение обратного двухуровневого дискретного преобразования Хаара; - преобразование носителя из цветовой модели YCbCr в RGB.
Предлагаемые модификации Работа рассмотренных схем во многом зависит от секретного ключа, с помощью которого определяются схемы встраивания/извлечения и количество итераций преобразования Арнольда. Ускорения подготовки ЦВЗ, а также процессов встраивания/извлечения его битов можно достичь применением различных механизмов. Для упрощения распределения данных в памяти и сокращения количества двумерных циклов решено использовать линейную интерпретацию данных. При такой организации данных появляется возможность применения таблиц преобразования и более эффективного использования механизмов распараллеливания.
Символ кода принимает значение в виде цифр 0–9 и латинских букв A–F, которые в совокупности можно интерпретировать как значения 0–15. В этом случае скремблирование можно выполнить с помощью таблиц преобразования, что позволит добиться константного времени выполнения преобразования Арнольда. При этом для улучшения кодирования информации к каждому блоку будет применяться разное количество итераций, которое определяется на основе MD5 кода. Также было решено использовать таблицы преобразования для быстрой реализации ДВП и определения коэффициентов, использующихся при встраивании каждого бита информации в области вейвлет-преобразования. Подготовка ЦВЗ и преобразование Арнольда
На следующем шаге для лучшего сокрытия данных используется преобразование Арнольда. Это преобразование применяется только к квадратным изображениям, однако его можно применить и к полученным одномерным представлениям. Для блока размерно-стью N×N преобразование Арнольда изменяет координаты (X, Y) элемента в новые координаты (Xnew, Ynew) согласно выражению
Ключевой особенностью преобразования Арнольда является то, что после определенного количества итераций получается его оригинальное значение. В таблице 2 отражено количество итераций для типовых размеров блока. Таблица 2 Количество итераций для блоков разного размера, после которых будет получен исходный блок Table 2 The number of iterations for the blocks of different sizes, to obtain the original block
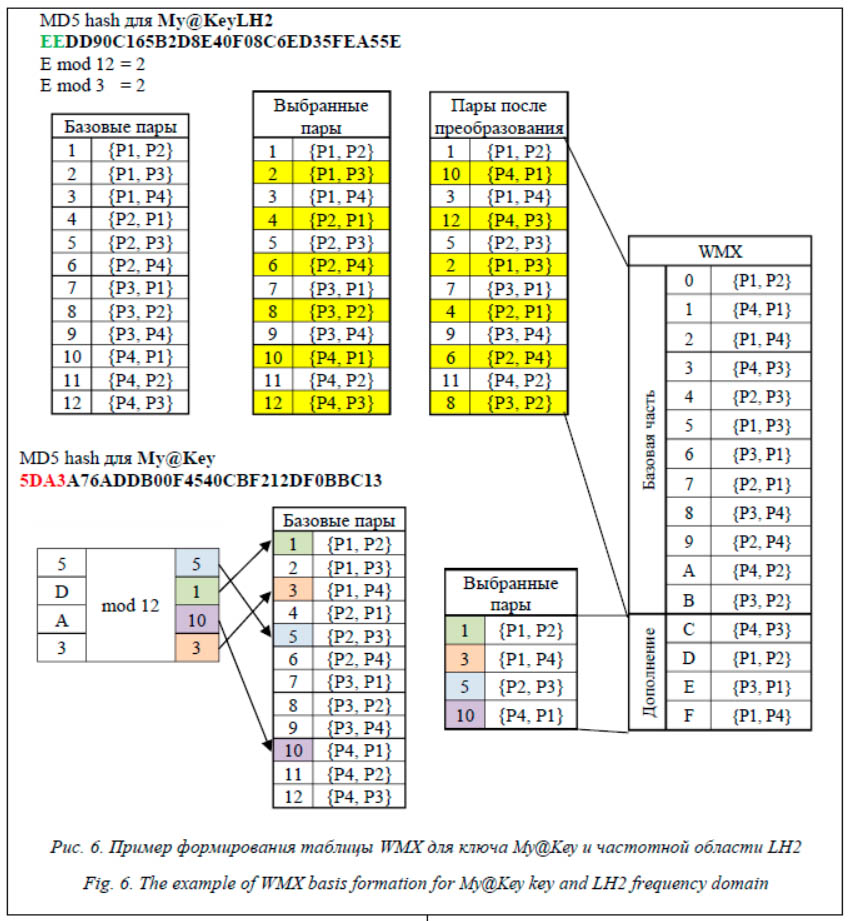
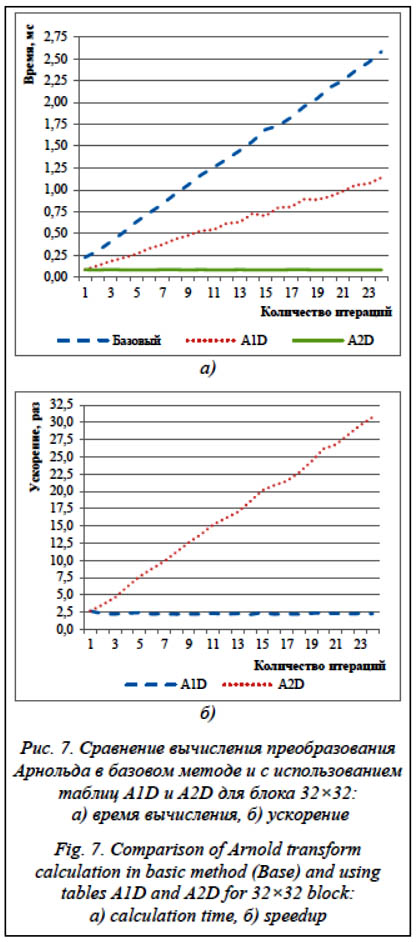
Непосредственное применение преобразования Арнольда приводит к высоким вычислительным затратам из-за итерирования по двумерной матрице. В связи с этим предлагается использовать таблицы преобразований. Для их формирования необходимо переписать выражение (1) в следующей форме: Xnew = (X + Y) mod N, Ynew = (X + 2Y) mod N. (2) При формировании таблиц преобразования необходимо учитывать одномерную интерпретацию блока. С учетом уравнений (2) формирование таблицы A1D для одной итерации скремблирования будет происходить следующим образом: A1D[YN + X] = YnewN + Xnew. Чтобы не повторять применение таблицы преобразования A1D многократно, дополнительно формируется таблица преобразований A2D, позволяющая добиться постоянного времени выполнения преобразования Арнольда вне зависимости от количества итераций. Первый уровень в таблице A2D означает номер итерации, второй – непосредственно параметры трансформации (аналогично A1D). Значения на первом уровне (A2D[1]) равны значениям из таблицы A1D. Расчет последующих уровней таблицы преобразования осуществляется согласно выражению A2D[i][p] = = A2D[i – 1][A2D[1][p]], где i – номер текущей итерации преобразования; p – позиция параметра трансформации в таблице преобразования. Каждый блок ЦВЗ преобразуется с помощью своего собственного количества итераций. Используемая в базовом методе схема определения количества итераций на основе непосредственных значений символов секретного ключа усложняла работу алгоритма. Если ключ небольшой, значения количества итераций регулярно повторяются. В связи с этим предложено сформировать таблицу преобразования AAlter, которая будет определять количество итераций преобразования, применяемых для блока. При ее генерации используются параметры хэш-кода, полученного для секретного ключа. Заполнение таблицы AAlter осуществляется в зависимости от допустимого набора итераций. Например, количество итераций может определяться с помощью базиса (первое число кода) и дополнительного смещения (остаток от суммы 1–3 последующих чисел). Применение MD5-кода даст возможность задать количество итераций для 16, 10 и 8 блоков размером 32×32 пиксела соответственно. При необходимости встраивать большее количество информации можно либо использовать иную хэш-функцию, либо задействовать цикличность.
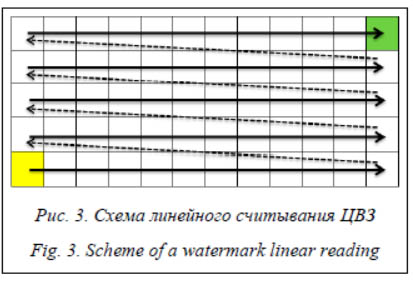
Определение схем встраивания и извлечения данных По сравнению с базовым методом алгоритм встраивания ЦВЗ не претерпел существенных изменений. Для определения схемы встраивания битов авторами применяются линейная интерпретация частотной области, а также таблица преобразования WMX, построенная с помощью хэш-кодов секретного ключа и идентификатора частотной области. При вейвлет-преобразовании второго уровня для встраивания будут использованы два частотных коэффициента из четырех доступных. При этом в случае четырех коэффициентов {P1, P2, P3, P4} возможны 12 комбинаций, которые можно представить множеством ({P1, P2}, {P1, P3}, {P1, P4}, {P2, P1}, {P2, P3}, {P2, P4}, {P3, P1}, {P3, P2}, {P3, P4}, {P4, P1}, {P4, P2}, {P4, P3}). Базовая часть таблицы WMX заполняется на основе этих 12 комбинаций. В зависимости от того, в какую область вейвлет-коэффициентов (HH2, HL2 или LH2) будет встраиваться ЦВЗ, порядок комбинаций может быть разнообразным. Для этого осуществляется циклический сдвиг на основе хэш-кода, полученного для секретного ключа и выбранной частотной области. Для определения параметров сдвига базовой части используется остаток от деления первого символа на 12. Тип сдвига определяется на основе остатка от деления второго символа на 3 (0 – все элементы, 1 – нечетные элементы, 2 – четные элементы).
Применение параллельных вычислений Для достижения большего ускорения при встраивании ЦВЗ возможно применение технологии распараллеливания обработки. Наиболее подходящим видом распараллеливания программного кода применительно к подготовке ЦВЗ, осуществления вейвлет-преобразования, а также непосредственного встраивания/извлечения ЦВЗ является распараллеливание, учитывающее параллелизм данных. Такому виду распараллеливания соответствуют задачи, которые включают неоднократное выполнение одного и того же алгоритма с различными исходными данными. Вычисления могут производиться параллельно в случае разделения данных на фрагменты и обработки каждого фрагмента выделенным ядром. Для реализации параллельных алгоритмов широкое распространение получил стандарт OpenMP [17], применяемый для распараллеливания программ на языках С, С++ и Фортран. Распараллеливание в OpenMP выполняется явно путем написания в коде специальных директив, а также вызова вспомогательных функций. С учетом измененного представления данных в виде линейной формы (одномерный массив) можно получить ускорение обработки почти на всех этапах: преобразование цветовых моделей, преобразование Арнольда, непосредственное встраивание битов ЦВЗ и т.п. Для параллельной реализации вычислений будет применяться распараллеливание цикла. Последовательная реализация предполагает использование циклов следующего вида: for(int i=0; i { Обработка данных } Реализация с помощью OpenMP отличается добавлением специальной директивы: #pragma omp parallel for for(int i=0; i { Обработка данных } При использовании данной директивы для разделения работы возможно использование опции schedule, которая будет выполнять балансировку нагрузки потоков (распределение итераций). Для того чтобы размер порции уменьшался с некоторого начального значения до величины chunk (по умолчанию chunk = 1), задается значение guided. В таком случае уменьшение порции будет пропорционально количеству еще не распределенных итераций, деленному на количество потоков, выполняющих обработку цикла. При этом количество итераций в последней порции может оказаться меньше значения chunk. Форма записи директивы примет следующий вид: #pragma omp parallel for schedule(guided, chunk). В большинстве случаев такое распределение позволяет аккуратнее разделить работу и сбалансировать загрузку потоков. Экспериментальные исследования Для экспериментов использованы по 100 фотографий каждого из разрешений: 1 280×720, 1 920×1 080, 2 560×1 440, 3 840×2 160 [18] (см. http://www.swsys.ru/uploaded/image/2021-3/2021-3-dop/1.jpg), а также компьютер с процессором Intel Core i7 4770. Технология Hyper-Threading была отключена. Максимальное дополнительное ускорение ядра (Turbo Boost) составляло 500 Mhz. Выполняемые эксперименты можно разделить на три части: - проверка ускорения трансформации Арнольда; - проверка общего ускорения встраивания ЦВЗ при однопоточном вычислении; - проверка общего ускорения встраивания ЦВЗ при использовании параллельных реализаций алгоритмов.
Во втором эксперименте проверялось общее ускорение внедрения ЦВЗ при вычислениях в одном потоке. В качестве передаваемой текстовой информации служил текст: Some embedding text information. В качестве секретного ключа использовалась строка, сформированная на основе базовой части Secret@Key#, к которой добавлялся порядковый номер эксперимента. Во время эксперимента дополнительно вычислялось время, затрачиваемое на каждый шаг алгоритма встраивания ЦВЗ. Для получе-ния более достоверных данных выполнялось по 1 000 замеров. Результаты, полученные для каждого из изображений, были усреднены и представлены в таблице 3. Согласно полученным данным, наибольшее ускорение от использования таблиц преобразования получил этап подготовки ЦВЗ, среднее ускорение составило 14,31 раза. Оценка ускорения подготовки ЦВЗ проведена для встраиваемой информации объемом 8–17 блоков. В случае встраивания битов ЦВЗ в частотные области было достигнуто ускорение в 1,28 раза для изображений 1 920×1 080. Таблица 3 Сравнение базового и предлагаемого методов при однопоточном вычислении для изображений разрешением 1 920×1 080 пикселов Table 3 Comparison of base and proposed methods for single-threaded computation for 1 920×1 080 images
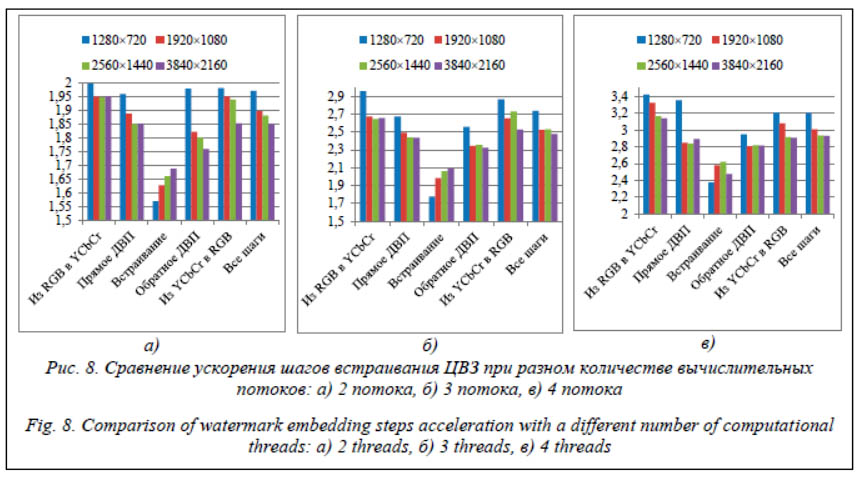
Оценка влияния параллельных вычислений при подготовке ЦВЗ показала, что в среднем возможно достичь ускорения в 1,74 раза для двух потоков, при этом для трех и четырех потоков ускорение составило 2,54 и 3,24 раза соответственно.
Можно заметить, что прирост производительности при использовании четырех потоков не очень большой, это обусловлено использованием в экспериментальных исследованиях четырехъядерного процессора (часть ресурсов используются операционной системой и фоновыми процессами). При этом следует учитывать, что в полученные результаты внесла свой вклад технология Turbo Boost, которая позволила делать более быстрые однопоточные вычисления. Использование параллельных вычислений дает дополнительное ускорение всего процесса встраивания в 1,9–3 раза в зависимости от количества потоков. Таблица 4 Время встраивания ЦВЗ для изображений разных разрешений при однопоточном вычислении (мс) Table 4 Execution time of the proposed method for different resolutions of images in single-threaded computation
Заключение В статье предложены несколько способов снижения вычислительных затрат и требуе-мого времени при подготовке и встраивании ЦВЗ с помощью преобразования Арнольда и ДВП. К таким способам относятся линейная интерпретация данных (носителя и ЦВЗ), использование таблиц преобразований и параллельные вычисления в нескольких вычислительных потоках. Предложенная двумерная таблица преобразования позволяет осуществлять скремблирование алгоритмом Арнольда за константное время. Для блоков ЦВЗ размером 32×32 пиксела это дает ускорение до 30 раз. Для изображений размером 1 920×1 080 было получено среднее ускорение этапа подго-товки ЦВЗ в 14,31 раза и этапа встраивания би-тов ЦВЗ в 1,28 раза. Использование параллельных вычислений при встраивании ЦВЗ позволяет получить дополнительное ускорение в 1,90, 2,56 и 3,01 раза для двух, трех и четырех потоков соответственно. Рассмотренные способы дают возможность использовать технологии цифрового маркирования в мобильных технологиях с большей эффективностью. Работа выполнена при поддержке РФФИ, проект № 19-07-00047 А. Литература 1. Verma V., Jha R.K. An overview of robust digital image watermarking. IETE Technical Review, 2015, vol. 32, no. 6, pp. 479–496. DOI: 10.1080/02564602.2015.1042927. 2. Begum M., Uddin M.S. Digital image watermarking techniques: A review. Information, 2020, vol. 11, no. 2, p. 110. DOI: 10.3390/info11020110. 3. Abraham J., Paul V. An imperceptible spatial domain color image watermarking scheme. JKSUCI, 2019, vol. 31, no. 1, pp. 125–133. DOI: 10.1016/j.jksuci.2016.12.004. 4. Feng B., Li X., Jie Y., Guo C., Fu H. A novel semi-fragile digital watermarking scheme for scrambled image authentication and restoration. Mobile Networks and Applications, 2020, vol. 25, no. 1, pp. 82–94. DOI: 10.1007/s11036-018-1186-9. 5. Zeki A.M., Manaf A.A. A novel digital watermarking technique based on ISB (Intermediate Significant Bit). Intern. Scholarly and Scientific Research & Innovation, 2009, vol. 3, no. 2, pp. 444–451. 6. Mohammed G.N., Yasin A., Zeki A.M. Robust image watermarking based on Dual Intermediate Significant Bit (DISB). Intern. Journal of Digital Content Technology and its Applications, 2014, vol. 7, no. 5, pp. 18–22. DOI: 10.1109/CSIT.2014.6805973. 7. Gaata M.T. An efficient image watermarking approach based on Fourier transform. IJCA, 2016, vol. 136, no. 9, pp. 8–11. DOI: 10.5120/ijca2016908559. 8. Roy S., Pal A.K. A blind DCT based color watermarking algorithm for embedding multiple watermarks. AEU – International Journal of Electronics and Communications, 2017, vol. 72, pp. 149–161. DOI: 10.1016/J.AEUE.2016.12.003. 9. Khare P., Srivastava V.K. Secure and robust image watermarking scheme using homomorphic transform, SVD and Arnold transform in RDWT domain. Advances in Electrical and Electronic Engineering, 2019, vol. 17, no. 3, pp. 343–351. DOI: 10.15598/aeee.v17i3.3154. 10. Tan L., He Y., Wu F., Zhang D. A blind watermarking algorithm for digital image based on DWT. J. Phys.: Conf. Ser. Proc. CMVIT, 2020, vol. 1518, art. 012068. DOI: 10.1088/1742-6596/1518/1/012068. 11. Li Y., Wei M., Zhang F., Zhao J. A new double color image watermarking algorithm based on the SVD and Arnold scrambling. Journal of Applied Mathematics, 2016, vol. 2016, pp. 1–9. DOI: 10.1155/2016/2497379. 12. Zotin A., Favorskaya M., Proskurin A., Pakhirka A. Study of digital textual watermarking distortions under Internet attacks in high resolution videos. Procedia Computer Science, 2020, vol. 176, pp. 1633–1642. DOI: 10.1016/j.procs.2020.09.187. 13. Li M., Liang T., He Y. Arnold transform based image scrambling method. Proc. III ICMT-13, 2013, pp. 1309–1316. DOI: 10.2991/icmt-13.2013.160. 14. Ye R., Zhuang L. Baker map's itinerary based image scrambling method and its watermarking application in DWT domain. IJIGSP, 2012, vol. 4, no. 1, pp. 12–20. DOI: 10.5815/ijigsp.2012.01.02. 15. Yu X., Wang C., Zhou X. A survey on robust video watermarking algorithms for copyright protection. Applied Sciences, 2018, vol. 8, no. 10, art. 1891. DOI: 10.3390/app8101891. 16. Favorskaya M., Zotin A. Robust textual watermarking for high resolution videos based on Code-128 barcoding and DWT. Procedia Computer Science, 2020, vol. 176, pp. 1261–1270. DOI: 10.1016/j.procs.2020.09.135. 17. Slabaugh G., Boyes R., Yang X. Multicore image processing with OpenMP. IEEE Signal Processing Magazine, 2010, vol. 27, no. 2, pp. 134–138. DOI: 10.1109/MSP.2009.935452. 18. HD Wallpapers. URL: https://www.hdwallpapers.in/3840x2160_ultra+hd+4k-wallpapers-r.html (дата обращения: 12.03.2021). References 1. Verma V., Jha R.K. An overview of robust digital image watermarking. IETE Technical Review, 2015, vol. 32, no. 6, pp. 479–496. DOI: 10.1080/02564602.2015.1042927 . 2. Begum M., Uddin M.S. Digital image watermarking techniques: A review. Information, 2020, vol. 11, no. 2, p. 110. DOI: 10.3390/info11020110 . 3. Abraham J., Paul V. An imperceptible spatial domain color image watermarking scheme. JKSUCI, 2019, vol. 31, no. 1, pp. 125–133. DOI: 10.1016/j.jksuci.2016.12.004 . 4. Feng B., Li X., Jie Y., Guo C., Fu H. A novel semi-fragile digital watermarking scheme for scrambled image authentication and restoration. Mobile Networks and Applications, 2020, vol. 25, no. 1, pp. 82–94. DOI: 10.1007/s11036-018-1186-9 . 5. Zeki A.M., Manaf A.A. A novel digital watermarking technique based on ISB (Intermediate Significant Bit). Intern. Scholarly and Scientific Research & Innovation, 2009, vol. 3, no. 2, pp. 444–451. 6. Mohammed G.N., Yasin A., Zeki A.M. Robust image watermarking based on Dual Intermediate Significant Bit (DISB). Intern. Journal of Digital Content Technology and its Applications , 2014, vol. 7, no. 5, pp. 18–22. DOI: 10.1109/CSIT.2014.6805973 . 7. Gaata M.T. An efficient image watermarking approach based on Fourier transform. IJCA, 2016, 8. Roy S., Pal A.K. A blind DCT based color watermarking algorithm for embedding multiple watermarks. AEU – International Journal of Electronics and Communications, 2017, vol. 72, pp. 149–161. DOI: 10.1016/J.AEUE.2016.12.003 . 9. Khare P., Srivastava V.K. Secure and robust image watermarking scheme using homomorphic transform, SVD and Arnold transform in RDWT domain. Advances in Electrical and Electronic Engineering, 2019, vol. 17, no. 3, pp. 343–351. DOI: 10.15598/aeee.v17i3.3154 . 10. Tan L., He Y., Wu F., Zhang D. A blind watermarking algorithm for digital image based on DWT. J. Phys.: Conf. Ser. Proc. CMVIT , 2020, vol. 1518, art. 012068. DOI: 10.1088/1742-6596/1518/1/012068 . 11. Li Y., Wei M., Zhang F., Zhao J. A new double color image watermarking algorithm based on the SVD and Arnold scrambling. Journal of Applied Mathematics, 2016, vol. 2016, pp. 1–9. DOI: 10.1155/2016/2497379 . 12. Zotin A., Favorskaya M., Proskurin A., Pakhirka A. Study of digital textual watermarking distortions under Internet attacks in high resolution videos. Procedia Computer Science, 2020, vol. 176, pp. 1633–1642. DOI: 10.1016/j.procs.2020.09.187 . 13. Li M., Liang T., He Y. Arnold transform based image scrambling method. Proc. III ICMT-13, 2013, pp. 1309–1316. DOI: 10.2991/icmt-13.2013.160 . 14. Ye R., Zhuang L. Baker map's itinerary based image scrambling method and its watermarking application in DWT domain. IJIGSP, 2012, vol. 4, no. 1, pp. 12–20. DOI: 10.5815/ijigsp.2012.01.02 . 15. Yu X., Wang C., Zhou X. A survey on robust video watermarking algorithms for copyright protection. Applied Sciences, 2018, vol. 8, no. 10, art. 1891. DOI: 10.3390/app8101891 . 16. Favorskaya M., Zotin A. Robust textual watermarking for high resolution videos based on Code-128 barcoding and DWT. Procedia Computer Science, 2020, vol. 176, pp. 1261–1270. DOI: 10.1016/j.procs.2020.09.135 . 17. Slabaugh G., Boyes R., Yang X. Multicore image processing with OpenMP. IEEE Signal Processing Magazine, 2010, vol. 27, no. 2, pp. 134–138. DOI: 10.1109/MSP.2009.935452 . 18. РВ Wallpapers. Available at: https://www.hdwallpapers.in/3840x2160_ultra+hd+4k-wallpapers-r.html (accessed March 12, 2021). |




| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4834 |
Версия для печати |
| Статья опубликована в выпуске журнала № 3 за 2021 год. [ на стр. 420-432 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Система моделирования масс-спектрометра на основе параллельного кода частиц в ячейке
- Использование частичной параллелизации для триангуляции двумерных областей
- Исследование статистических свойств алгоритмов минимизации недетерминированных конечных автоматов с использованием программы ReFaM
- Генетический алгоритм для задачи вершинной минимизации недетерминированных конечных автоматов
- HeО: библиотека метаэвристик для задач дискретной оптимизации
Назад, к списку статей