Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Ключевое слово: |
|
| Page views: 12338 |
Print version Full issue in PDF (1.18Mb) |
Известно, что в рамках развивающейся в настоящее время теории моделирования и параметризации тестирования (ТМПТ) удается интерпретировать процесс разумно организованного педагогического тестирования как процесс измерения уровня подготовленности испытуемых в определенной области знаний. Результаты измерений (в полной аналогии с измерениями в физике, технике и т.п.) отражаются на метрической шкале логитов и обеспечивают таким образом реальную объективность окончательных оценок испытуемых. Основополагающие идеи в этом направлении впервые были сформулированы датским математиком Рашем в 1960 году. Поэтому семейство логистических моделей, составляющих основу современной ТМПТ, обычно называют моделями Раша [2-4]. В приложении тестирования в образовании задания теста различных трудностей играют роль своеобразного измерительного инструмента, а исходными данными алгоритмов ТМПТ служат так называемые первичные баллы, то есть количество верно выполненных заданий (или определенных частей заданий) каждым испытуемым. Уникальность ТМПТ состоит в том, что она разрабатывает определенный механизм преобразования формальных наблюдений за исходом событий (первичные баллы) в объективные измерения, то есть в определенные индексы на определенной метрической шкале латентных стимулов этих событий. Принципиальная возможность такого преобразования, собственно, и определяет собой то, что делает тестологию в широком смысле настоящей наукой и позволяет ей количественно решать задачи не только в образовании, но и во многих науках медицинского, социологического и экономического характера. Цель данной статьи - показать, что соотношение между первичными баллами испытуемых на порядковой шкале и соответствующими оценками в логитах на метрической шкале устанавливается определенной функцией, которую мы называем характеристической. Эта функция в рамках основной логистической модели Раша является исчерпывающей характеристикой теста, и потому служит удобным инструментом сравнения тестов при их конструировании, а также при выравнивании различных вариантов одного и того же теста на единую метрическую шкалу в процессе математической обработки результатов тестирования. Обсудим сначала суть дела на простейшем численном примере. Предположим, что тест состоит из k = 5 заданий с известными трудностями
Заметим, что в условии задачи не сказано, какие именно 3 задания выполнены верно, а какие 2 задания выполнены ошибочно. Заданному первичному баллу b = 3 могут соответствовать 10 различных строк матрицы индикаторов ответов. Например, 11100, 01110, 00111 и т.д. Согласие этих строк с моделью Раша, конечно, различно - наилучшее согласие дает первая строка из перечисленных (каноническая строка), наихудшее - третья. Однако с точки зрения оценивания Одним из простейших методов математической статистики, предназначенных для отыскания состоятельных оценок латентных параметров, является метод моментов К. Пирсона. Согласно этому методу, мы должны приравнять теоретический момент (в данном случае математическое ожидание М(b) первичного балла, то есть начальный момент первого порядка) его эмпирическому значению (в данном случае заданному первичному баллу b=3): M(b)=3. (2) Поскольку при заданных значениях трудностей заданий
есть некоторая функция только одной переменной
Здесь нижний индекс 5 напоминает зависимость Корень последнего уравнения и есть искомая оценка Для наглядности мы решим уравнение (4) графически (рис.1). Таким образом, Эта оценка получена, исходя из строки матрицы ответов 11100. Но если взять вместо нее любую другую строку с k=5 и b=3, то ни функция (3), ни уравнение (4) никак не изменятся и, следовательно, мы получим ту же оценку Итак, имея график функции То же можно сказать и относительно графика функции Видно, что при заданных трудностях тестовых заданий вся информация, необходимая для оценивания подготовленности испытуемых, содержится только в первичных баллах Сказанное полностью справедливо и относительно соответствия между первичными баллами Поэтому первичные баллы испытуемых
Левая часть уравнения (4), то есть функция Пусть в общем случае тест состоит из k заданий с трудностями
назовем характеристической функцией теста (ХФТ). Ее область определения включает весь диапазон уровня подготовленности испытуемых, Если, в частности, k=1, то ХТФ совпадает с характеристической функцией соответствующего тестового задания р(q;d1). Знание ХФТ равносильно знанию точного соответствия между первичными процентными баллами и окончательными оценками уровня подготовленности испытуемых в логитах. Аналогично вводится понятие и характеристической функции контингента (ХФК) испытуемых:
где В следующих разделах выведены аналитические выражения ХФТ под условием определенных предположений о распределении трудностей заданий составляемого теста. ХФТ при равномерном распределении трудностей тестовых заданий
В указанных условиях математическое ожидание каждого слагаемого выражения (5) имеет вид
Поэтому первичный процентный балл в среднем определяется как
Интегрируя, имеем:
Если a= –g, а
Предположим теперь, что тест состоит из k заданий, трудности В самом деле, если
Сдвиг начала отсчета приводит к изменению всех параметров На рисунке 2 показан график выведенной ХФТ вида (10), (11) при Например, первичному баллу b=26 при общем количестве тестовых заданий k=40 соответствует процентный первичный балл ХФТ при нормальном распределении трудностей тестовых заданий Рассмотрим теперь ХФТ (5)
в условиях, когда трудности В связи с этим функцию успеха (1)
Она известна в математике как функция логистического распределения вероятностей [1], ее значения с точностью до сотых долей совпадают со значениями функции распределения F нормального закона. Надо только изменить масштаб аргумента, исходя из равенства
В указанных условиях математическое ожидание каждого слагаемого выражения (12) имеет вид
где f(t) - плотность центрированной и нормированной нормальной случайной величины. Поэтому первичный процентный балл в среднем определяется как
Учитывая (14), выражение (17) перепишем в виде
Этот интеграл вычисляется с помощью известного соотношения для нормального распределения:
В нашем случае
Другими словами, в (19) Следовательно,
Видим, что ХФТ зависит только от
и вспомнить равенство (13), то получим окончательно:
На рисунке 3 показаны графики четырех ХФТ, различающихся параметрами m и Изменение математического ожидания m, как видим, приводит к параллельному переносу кривой вдоль оси абсцисс, а поворот кривой вокруг точки Сравнение ХФТ при различных распределениях трудностей заданий Ранее мы получили усредненную ХФТ при условии, что трудности заданий распределены или равномерно на отрезке [-3; 3], или по нормальному закону. Соответствующие графики отличаются друг от друга в зависимости от параметров нормального закона m и Если m=0 и Если m=0 и Характеристическая функция
позволяющую аппроксимировать любую реальную ХФТ.
В наших рассуждениях функция (23) играет роль лишь некоторого инструмента, позволяющего назвать существенные параметры имеющейся ХФТ в целом. Так, например, ХФТ (7) при равномерном распределении трудностей тестовых заданий лучше всего аппроксимируется функцией (23) с параметрами m=0 и d=0,68, а существенные параметры ХФТ (22) при нормальном распределении трудностей с m=0 и Если иметь в виду дискриминацию только в окрестности средней трудности теста, то этот результат можно получить и без привлечения аппроксимирующей функции (23). В самом деле, поскольку для ХФТ нам известны аналитические выражения (10) и (22), то мы можем продифференцировать их и вычислить значения производных в точке
Заметим, что аппроксимирующая функция (23) с d=0,60 совпадает с ХФТ (10) только в узкой окрестности точки m=0. Аппроксимация в среднем по всему отрезку [-3; 3] лучше выполняется при несколько другом значении d=0,68. Что касается ХФТ при нормальном распределении (22), то при Таким образом, при одинаковой средней трудности теста m нормальное распределение трудностей заданий с Аналогично можно устанавливать существенные параметры ХФТ при наличии только ее табличных значений. Рисунок 4 иллюстрирует определение существенных параметров таблично заданной ХФТ по физике, состоящего из 40 заданий (общероссийское централизованное тестирование 2002 г.). Оценки параметров m=0,4 и d=1,05 позволяют судить о средней трудности и коэффициенте дискриминации не отдельного задания, а всего теста в целом. Понятие ХФТ и ее существенные параметры m и d позволяют сравнивать между собой тесты в целом. В частности, показано, что распределение трудностей тестовых заданий по нормальному закону в среднем имеет преимущество по сравнению с равномерным распределением, поскольку коэффициент дискриминации при нормальном распределении почти в полтора раза превышает аналогичный параметр при равномерном распределении. Наибольший интерес, однако, представляет возможность количественно сравнивать тесты при реальном распределении трудностей тестовых заданий, то есть при таком распределении, которое лишь приближенно соответствует каким-нибудь намерениям. Например, какие практически создаваемые тесты можно считать параллельными? По мнению автора, тесты одинаковой содержательной валидности следует считать параллельными, если их характеристические функции совпадают. Расстояние между этими функциями в той или иной метрике может служить количественной мерой непараллельности тестов. В ослабленном виде можно сравнивать не сами характеристические функции, а их существенные параметры. В связи с указанной возможностью характеристические функции различных вариантов одного и того же теста полезно использовать при решении проблемы выравнивания этих вариантов и при отображении всех результатов тестирования на единую шкалу. Список литературы 1. Вероятность и математическая статистика: Энциклопедия. – М., 1999. 2. Rasch Models. Foundations, Resent Developments and Applications. Editors Fisher G.H., Molenaar I.W. New York, Berlin, 1997, Springer, 436 p. 3. Нейман Ю.М., Хлебников В.А. Введение в теорию моделирования и параметризации педагогических тестов. - М.: Прометей, 2000. - 169 с. 4. Нейман Ю.М., Хлебников В.А. Педагогическое тестирование как измерение. - М.: Прометей, 2003. - 70 с. |
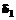 = -1,
= -1, 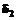 = 0,
= 0, 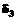 = 1,
= 1, 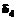 = 2 и
= 2 и 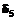 = 3 в логитах. Некоторый испытуемый при работе над этим тестом верно выполнил 3 задания. Требуется оценить его уровень подготовленности
= 3 в логитах. Некоторый испытуемый при работе над этим тестом верно выполнил 3 задания. Требуется оценить его уровень подготовленности  , если вероятность
, если вероятность  того, что испытуемый с уровнем подготовленности
того, что испытуемый с уровнем подготовленности 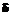 , определяется функцией успеха основной логистической модели Раша вида:
, определяется функцией успеха основной логистической модели Раша вида: . (1)
. (1)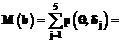
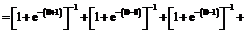
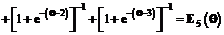 (3)
(3) , а равенство (2) перепишем в виде уравнения
, а равенство (2) перепишем в виде уравнения от количества k заданий теста (в данном случае k=5).
от количества k заданий теста (в данном случае k=5). .
. при любом другом количестве k заданий в тесте.
при любом другом количестве k заданий в тесте. испытуемых. Важно только количество верно выполненных заданий из k возможных, а какие именно задания выполнены верно, оказывается, значения не имеет. Этот факт часто вызывает сомнение, поскольку кажется, что верное выполнение трудных заданий должно поощряться больше, чем верное выполнение такого же количества легких заданий. Однако на деле ошибки в легких заданиях необходимо штрафовать с той же мерой, которая используется для поощрения за верное выполнение трудных заданий. Своеобразная компенсация поощрений за то, что человек знает и умеет с наказаниями за то, что он не знает или не умеет, и приводит к тому, что для оценивания уровня подготовленности испытуемых в рамках модели Раша достаточно знать только первичные баллы
испытуемых. Важно только количество верно выполненных заданий из k возможных, а какие именно задания выполнены верно, оказывается, значения не имеет. Этот факт часто вызывает сомнение, поскольку кажется, что верное выполнение трудных заданий должно поощряться больше, чем верное выполнение такого же количества легких заданий. Однако на деле ошибки в легких заданиях необходимо штрафовать с той же мерой, которая используется для поощрения за верное выполнение трудных заданий. Своеобразная компенсация поощрений за то, что человек знает и умеет с наказаниями за то, что он не знает или не умеет, и приводит к тому, что для оценивания уровня подготовленности испытуемых в рамках модели Раша достаточно знать только первичные баллы  тестовых заданий и оценками
тестовых заданий и оценками  трудности
трудности  этих заданий при заданном контингенте испытуемых. Это позволяет, в частности, пользоваться итерационным процессом последовательного уточнения: сначала находят оценки
этих заданий при заданном контингенте испытуемых. Это позволяет, в частности, пользоваться итерационным процессом последовательного уточнения: сначала находят оценки 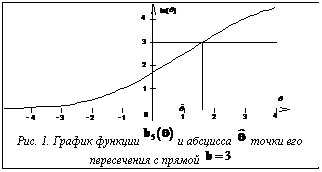 Отметим также, что, если трудности всех заданий увеличить (или уменьшить) на какую-нибудь константу, то и оценка
Отметим также, что, если трудности всех заданий увеличить (или уменьшить) на какую-нибудь константу, то и оценка 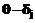 , j = 1, 2,..., k, определяющие вероятность успешного выполнения заданий, остаются без изменений. Пусть, например,
, j = 1, 2,..., k, определяющие вероятность успешного выполнения заданий, остаются без изменений. Пусть, например, 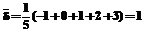 . Поэтому все числовые значения в логитах надо уменьшить на
. Поэтому все числовые значения в логитах надо уменьшить на 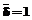 и полагать
и полагать 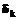 . Функцию одной переменной
. Функцию одной переменной  (5)
(5) ; ее значениями служат соответствующие первичные процентные баллы b%
; ее значениями служат соответствующие первичные процентные баллы b%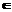 (0; 100).
(0; 100).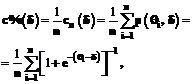 (6)
(6)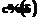 - первичный процентный балл тестовых заданий; n - количество испытуемых; i=1, 2,..., n.
- первичный процентный балл тестовых заданий; n - количество испытуемых; i=1, 2,..., n.![Подпись:
Рис. 2. График ХФТ при равномерном распределении
трудностей заданий на отрезке [ -3; 3 ]](uploaded/image/2005-4/image776.gif) Найдем характеристическую функцию
Найдем характеристическую функцию 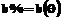 теста, содержащего произвольное количество k заданий, при условии, что трудность каждого задания теста может иметь равновероятно любое значение от
теста, содержащего произвольное количество k заданий, при условии, что трудность каждого задания теста может иметь равновероятно любое значение от 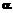 до
до 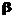 . Здесь
. Здесь  . (7)
. (7)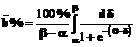 . (8)
. (8)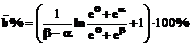 . (9)
. (9)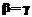 , где
, где  - любая положительная константа, то
- любая положительная константа, то (10)
(10)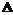 . Убедимся, что в таком случае характеристическая функция
. Убедимся, что в таком случае характеристическая функция 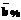 теста в среднем приближенно совпадает с аналогичной функцией, описанной уравнением (10), причем тем ближе, чем больше количество тестовых заданий k.
теста в среднем приближенно совпадает с аналогичной функцией, описанной уравнением (10), причем тем ближе, чем больше количество тестовых заданий k.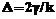 , то
, то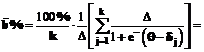
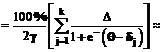
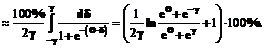 (11)
(11)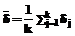 . Таким образом, ХФТ вида (11) зависит только от одного параметра
. Таким образом, ХФТ вида (11) зависит только от одного параметра 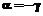 ,
, 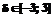 .
. =65 и уровень подготовленности
=65 и уровень подготовленности 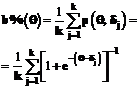 (12)
(12)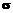 логит.
логит. удобно обозначить как
удобно обозначить как 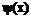 , где х=
, где х= , то есть
, то есть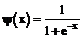 . (13)
. (13)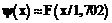 . (14)
. (14)![Подпись:
Рис. 3. Графики ХТФ при нормальном распределении труд-ностей заданий на отрезке [-3; 3] с различными параметрами m и s](uploaded/image/2005-4/image822.gif) Точный смысл этого утверждения состоит в следующем:
Точный смысл этого утверждения состоит в следующем: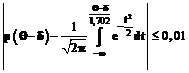 . (15)
. (15) , (16)
, (16)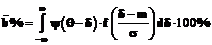 . (17)
. (17)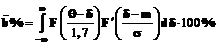 . (18)
. (18)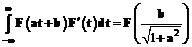 . (19)
. (19) , и потому
, и потому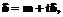
 .
. и
и 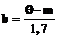 .
.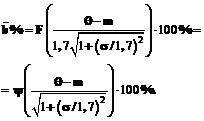 (20)
(20)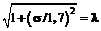 (21)
(21)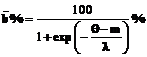 . (22)
. (22) является следствием изменения среднего квадратического отклонения
является следствием изменения среднего квадратического отклонения  является исчерпывающей характеристикой соответствующего теста. Однако на практике часто удобно пользоваться не всей ХФТ, а лишь ее числовыми характеристиками. В качестве таких числовых характеристик естественно выбрать среднее местоположение характеристической кривой относительно нуля на шкале логитов и средний наклон характеристической кривой относительно оси абсцисс. Речь идет о средней трудности m всех тестовых заданий и о значении d первой производной
является исчерпывающей характеристикой соответствующего теста. Однако на практике часто удобно пользоваться не всей ХФТ, а лишь ее числовыми характеристиками. В качестве таких числовых характеристик естественно выбрать среднее местоположение характеристической кривой относительно нуля на шкале логитов и средний наклон характеристической кривой относительно оси абсцисс. Речь идет о средней трудности m всех тестовых заданий и о значении d первой производной 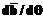 от ХФТ в точке
от ХФТ в точке 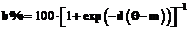 , (23)
, (23)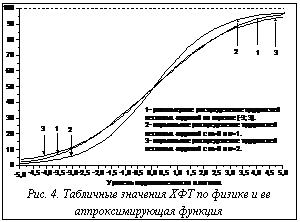 Как видим, правая часть равенства (23) совпадает с известной функцией успеха Бирнбаума (наличие коэффициента пропорциональности 100 не меняет, конечно, сути дела). В условиях модели Бирнбаума речь идет, как известно, о вероятности верного выполнения одного тестового задания трудности m любым испытуемым с уровнем подготовленности
Как видим, правая часть равенства (23) совпадает с известной функцией успеха Бирнбаума (наличие коэффициента пропорциональности 100 не меняет, конечно, сути дела). В условиях модели Бирнбаума речь идет, как известно, о вероятности верного выполнения одного тестового задания трудности m любым испытуемым с уровнем подготовленности 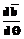 =25d – для аппроксимирующей функции (23);
=25d – для аппроксимирующей функции (23);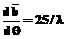 – для ХФТ при нормальном распределении, откуда следует d=0,86 при
– для ХФТ при нормальном распределении, откуда следует d=0,86 при | Permanent link: http://swsys.ru/index.php?page=article&id=491&lang=&lang=en |
Print version Full issue in PDF (1.18Mb) |
| The article was published in issue no. № 4, 2005 |
Perhaps, you might be interested in the following articles of similar topics:
- О программной реализации геоинформационных систем
- Компьютерная интеграция и интеллектуализация производств на основе их унифицированных моделей
- Компьютерный тренажер для операторов технологических процессов доменного производства
- Оптимизация обработки информационных запросов в СУБД
- Программная система поддержки принятия проектных решений
Back to the list of articles