Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Поддержка аппарата контрольных точек в кластерных вычислительных системах
Аннотация:
Abstract:
| Авторы: Машечкин И.В. () - , Попов И.С. () - , Смирнов А.А. (Xantrax1956@mail.ru) - Научно-исследовательский центр Центрального научно-исследовательского института войск Воздушно-космической обороны Минобороны России (начальник отдела), Тверь, Россия, кандидат технических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 12298 |
Версия для печати Выпуск в формате PDF (1.31Мб) |
Для решения больших вычислительных задач в биологии, физике, астрономии и других требуются высокопроизводительные вычислительные системы. Производительность последовательного компьютера имеет свои пределы и существенно увеличить ее не удается. В такой ситуации на помощь приходят параллельные вычислители, которые по своей производительности могут значительно превосходить последовательные. Однако написание программ для параллельных вычислителей является отдельной задачей, решением которой занимается параллельное программирование. При написании параллельных программ принимается некоторая модель параллельных вычислений, одной из которых является модель обмена сообщениями. В этой модели единственным способом взаимодействия ветвей параллельной задачи является обмен сообщениями между ними. Широко используемым стандартом на интерфейс обмена сообщениями является MPI [2]. Наиболее часто такие вычислительные системы обладают кластерной архитектурой. Контрольная точка – информация о состоянии задачи, которая позволяет продолжить ее выполнение с некоторого момента времени. Основной целью применения механизма контрольных точек является повышение эффективности использования кластерного времени. Такое повышение эффективности может быть достигнуто путем повышения отказоустойчивости вычислительных задач [1], а также путем обеспечения большей гибкости планирования для системы управления заданиями. В первом случае периодически создаваемые контрольные точки задачи позволяют свести к минимуму потери при сбое в кластере. Во втором случае механизм контрольных точек предоставляет системе управления заданиями возможность временно снимать со счета длительные вычислительные задачи, освобождая ресурсы для задач с более коротким временем счета, а затем путем восстановления из контрольной точки продолжать выполнение длительных задач (при этом возможна ситуация, при которой задача будет восстановлена и продолжит работу на другом наборе узлов по сравнению с тем набором, на котором она была запущена изначально). В ситуации, когда длительные задачи прерываются на время в пользу более коротких, также может улучшаться качество обслуживания пользователей вычислительной системы, если под улучшением понимать минимизацию времени, которое задача проводит в очереди готовых к запуску при незначительном увеличении времени счета других задач. При применении механизма контрольных точек для параллельных задач в системе обмена сообщениями возникают особые проблемы, не свойственные системам контрольных точек для последовательных задач. Дело в том, что параллельная задача в этом случае представляет собой множество ветвей, каждая из которых реализована в виде независимого процесса, а единственным способом взаимодействия ветвей является обмен сообщениями через некоторую общую коммуникационную среду. Возможны ситуации, при которых даже корректное восстановление состояния всех ветвей задачи приведет к некорректному продолжению вычислений, что может быть связано с потерей или дублированием сообщений в коммуникационной среде. Кроме проблемы обеспечения корректности восстановления для параллельных задач, актуальной является задача повышения эффективности механизма контрольных точек, то есть уменьшение издержек на создание контрольной точки и восстановление из нее. Очевидно, что контрольные точки должны быть реализованы таким образом, чтобы их применение не оказывало существенного влияния на время выполнения задачи, однако объем контрольной точки параллельной задачи примерно равен произведению количества ветвей на объем памяти, которая необходима каждой ветви. Таким образом, при большом уровне параллельности и высоких требованиях задачи к памяти объем контрольной точки может составлять десятки гигабайт, и передача такого количества данных на какой-либо носитель может потребовать значительного количества времени, что неизбежно приведет к задержкам в выполнении исходной задачи. Следовательно, проблеме повышения эффективности должно уделяться особое внимание при проектировании и разработке систем контрольных точек.
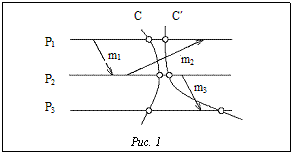
Все механизмы контрольных точек по способу реализации можно разделить на пользовательские и автоматические. В случае применения первого подхода программист для каждой задачи реализует механизм контрольных точек с нуля, полностью решая задачу сохранения и корректного восстановления состояния задачи. Автоматические контрольные точки реализуются на уровне операционной системы или на уровне библиотеки программирования; такая реализация предлагает услуги по созданию контрольных точек для широкого класса задач, требуя от программиста внесения минимальных изменений в исходный код задачи. Реализация на уровне операционной системы (в виде модуля ядра системы) позволяет более полно сохранять и восстанавливать состояния процесса, однако такая реализация предполагает относительно низкую переносимость (система контрольных точек обращается к структурам данных ядра ОС, которые подвержены частым изменениям) и требует прав администратора при внедрении; реализация же в виде библиотеки, которая работает на уровне процесса пользователя, использует менее подверженные изменениям интерфейсы и не требует участия администратора в процессе внедрения, однако позволяет сохранить лишь подмножество состояния процесса, которого, однако, оказывается достаточно для большинства вычислительных задач. Если же сравнивать пользовательские и автоматические контрольные точки, то можно сказать, что пользовательские контрольные точки обычно являются более эффективным механизмом, так как их реализация может учитывать специфические особенности конкретной задачи, однако необходимость реализации для каждой задачи является серьезным недостатком. Автоматические контрольные точки в общем случае могут предложить более низкую эффективность, но это может компенсироваться общностью подхода. Как уже упоминалось ранее, чаще всего параллельные задачи в кластерных вычислительных системах взаимодействуют при помощи обмена сообщениями через общую коммуникационную среду, которой в кластерах является сеть либо специализированная (например, Myrinet, SCI), либо обычная (например, Fast Ethernet). Это означает, что в состояние параллельной задачи (а значит, и в контрольную точку этой задачи) входит, кроме состояния каждой ее ветви как отдельного процесса, еще и состояние коммуникационной среды. Обычно состояние коммуникационной среды (сообщения, которые могли в ней находиться в момент создания контрольной точки) не сохраняется, так как его сохранение и восстановление потребует значительных усилий, вместо этого вводятся ограничения на это состояние. Рассмотрим пример (рис. 1). На рисунке показаны три ветви параллельной задачи P, которые взаимодействуют при помощи отправки сообщений m. Горизонтальные линии соответствуют времени в каждой ветви, кружочками отображены моменты создания контрольных точек. Так, при восстановлении из контрольной точки C будет потеряно сообщение m2, а при восстановлении из контрольной точки С¢ будет потеряно m2 и продублировано сообщение m3. Таким образом, при восстановлении возможны два типа ошибок – потеря и дублирование сообщений, которые для вычислительных задач приведут к некорректному продолжению вычислений (в других применениях в случае взаимодействующих при помощи сообщений приложений цена потери и дублирования может быть разной). Поэтому будем называть в дальнейшем контрольную точку вычислительной задачи консистентной, если в момент ее создания не было обменов сообщениями, то есть все отправленные сообщения были получены, и в каналах связи не было сообщений. Во всех других случаях контрольная точка будет называться неконсистентной. Существует два классических алгоритма обеспечения консистентности: синхронные и асинхронные контрольные точки. В первом случае происходит инициализация процедуры создания контрольной точки в одной из ветвей, которая отправляет служебное сообщение всем остальным ветвям: «Готовьтесь к созданию контрольной точки». После получения такого сообщения ветви прекращают отправлять сообщения, за исключением служебных, но продолжают принимать. Затем, когда все ветви убеждаются в том, что коммуникационные каналы пусты, они сообщают о своей готовности ветви-инициатору. Как только все ветви готовы к созданию контрольной точки, они одновременно начинают создавать свои контрольные точки. После того как создание контрольных точек завершено, выполнение параллельной задачи продолжается. Асинхронные контрольные точки создаются в ветвях задачи в произвольные моменты времени, причем в каждой ветви независимо. При этом пропадает всякая необходимость в синхронизации процессов, однако получение консистентной контрольной точки из набора контрольных точек ветвей не всегда является тривиальной задачей. При таком подходе требуется хранить несколько (а иногда и все) контрольные точки для каждой ветви. Поиск консистентного состояния на наборах контрольных точек является задачей отдельного алгоритма, но при его использовании возможны ситуации, когда ни одна комбинация контрольных точек отдельных ветвей не образует консистентного состояния (эффект домино). Рассмотрим еще один подход: предварительная синхронизация, гарантирующая консистентность контрольной точки. В этом случае в исходном коде задачи заранее размещаются подсказки для системы контрольных точек, которые говорят о том, в какой именно момент ветви параллельной задачи находятся в таком состоянии, что их контрольные точки будут образовывать консистентное состояние. Выбор места синхронизации основывается на следующих критериях: · коммуникационные каналы пусты; · никакой процесс не заблокирован в состоянии получения сообщения. Эти условия, очевидно, гарантируют консистентность контрольной точки, так как ни одно сообщение не будет потеряно (первое условие) и все процессы готовы к созданию контрольной точки (второе условие). Такие точки синхронизации обычно располагаются в конце какой-то итерации вычислений, после выполнения групповых операций MPI, которые затрагивают все ветви задачи. Данный подход за счет предварительного выбора предполагает минимальные временные затраты на синхронизацию ветвей задачи перед созданием контрольной точки. Для осуществления выбора места синхронизации может быть предложено несколько методов: - ручной выбор программистом; - статический анализ программы (места синхронизации выявляются на этапе компиляции); - динамический анализ программы (выполняется несколько тестовых прогонов программы, во время которых обнаруживаются самые удачные точки синхронизации). Под повышением эффективности системы контрольных точек понимают уменьшение издержек на создание контрольной точки и восстановление из нее. Основная часть издержек при создании контрольной точки связана с записью данных на диск, а объем записываемых данных можно оценить объемом памяти, используемым параллельной задачей (суммарным объемом данных всех ее ветвей). Издержки на восстановление из контрольной точки связаны с чтением того же объема данных, дополнительными процедурами при восстановлении, но все же большая часть издержек связана с вводом-выводом. Следовательно, повышение эффективности можно ожидать при уменьшении издержек на чтение и запись данных на диск (или на файловый сервер, в зависимости от конфигурации кластера), а также при уменьшении самого объема данных, который необходимо записать. Рассмотрим несколько методов повышения эффективности механизма контрольных точек [3-4]. Сжатие данных. Так как контрольная точка содержит данные процесса, а они достаточно хорошо сжимаются (в предположении об избыточности данных), то применение алгоритма сжатия к содержимому контрольной точки позволяет значительно уменьшить ее размер. Однако так как цель состоит также в уменьшении задержек на время создания контрольной точки, необходимо выбирать алгоритмы, которые бы обеспечивали приемлемые коэффициенты сжатия, но при этом не требовали большого количества процессорного времени. Такой компромисс можно найти в семействе алгоритмов словарного сжатия. Если заранее известен характер данных задачи, можно применять специализированные алгоритмы сжатия, которые бы позволили достичь более качественных результатов на конкретных задачах. Обычный процесс создания контрольной точки имеет существенный недостаток: выполнение процесса прерывается на время создания контрольной точки. В случае асинхронной контрольной точки выполнение задачи не прерывается, а создание контрольной точки ведется в фоновом режиме, но так как требуется сохранить состояние процесса на момент создания контрольной точки, необходимо каким-то образом сохранить это состояние. В ОС семейства UNIX сохранение состояния может быть достигнуто экономным способом, при помощи системного вызова fork(). Так как создание контрольной точки – это в основном ввод-вывод, а самой вычислительной задаче требуется время ЦП, то эти операции можно выполнять параллельно без потери производительности. Еще одним способом повышения эффективности является исключение ненужных областей памяти из контрольной точки. Этот способ является актуальным, если после создания контрольной точки задача первой операцией обращается к некоторым достаточно большим областям памяти на запись, а не на чтения. В такой ситуации нет необходимости включать эти области памяти в контрольную точку, так как после восстановления сохраненные значения не будут использованы. Примером таких областей памяти могут служить временные массивы данных, используемые задачей на каждой итерации вычислений, при условии, что контрольная точка создается в конце итерации. Экспериментальная реализация: libcheckpoint В результате анализа существующих решений, а также исследования различных вариантов к реализации систем контрольных точек был найден подход: библиотека автоматических контрольных точек на уровне процесса пользователя ОС семейства UNIX. Такая реализация предполагает простоту внедрения (не требуется вмешательства системного администратора), легкость использования (требуется лишь внесение минимальных изменений в существующие программы) и высокую переносимость. Выбор класса операционных систем связан с тем, что операционные системы этого семейства чаще всего используются при построении кластеров (в частности, ОС Linux). Также был осуществлен выбор коммуникационных сред: · разделяемая память (чистые SMP-системы); · cеть Myrinet (коммуникационная среда многих высокопроизводительных кластеров). Была выбрана конкретная реализация MPI – MPICH, так как она является наиболее распространенной реализацией MPI (MPICH, например, используется в МВС-1000М). Был осуществлен выбор метода обеспечения консистентности контрольной точки – предварительная синхронизация. Данный метод позволяет обеспечить низкие задержки на синхронизацию ветвей, требует хранения лишь одного набора контрольных точек ветвей и его реализация не приводит к изменению структуры обмена сообщений задачи (не требует применения служебных сообщений). В библиотеке были реализованы три наиболее применимых метода повышения эффективности: сжатие данных, асинхронные контрольные точки и исключение ненужных областей данных из контрольной точки. При проектировании и разработке преследовалось несколько основных целей: переносимость; отсутствие необходимости внесения изменений в системные библиотеки и библиотеки MPICH (или необходимость минимальных изменений); настройка на конечную архитектуру на этапе компиляции; максимальная эффективность при сохранении корректности сохранения состояния задачи. Основными характеристикам библиотеки являются: - реализация автоматических контрольных точек на уровне процесса пользователя (сама библиотека libcheckpoint написана на языке C); - поддержка различных архитектур: o FreeBSD/x86, o Linux/x86, o Linux/Alpha; - поддерживаемые языки программирования: o С/C++, o Fortran; - сохранение состояния процесса (сегмент данных, стек, куча, контекст процесса); - сохранение состояния операционной системы (отображения в память (mmap/munmap), открытые файлы (open/close/lseek/read/write/…), обработчики сигналов); - миграция процессов между машинами с идентичной архитектурой (восстановление задачи на другом наборе узлов по сравнению с тем, на котором она работала до создания контрольной точки); - получение информации об эффективности работы библиотеки. Архитектура библиотеки представлена следующим образом. · Подсистема чтения/записи файлов контрольных точек отвечает за формирование файла контрольных точек, который состоит из заголовка и информации о каждой сохраненной области памяти (ее тип, размер, начальный адрес и содержимое). Эта подсистема также отвечает за нумерацию файлов контрольных точек. · Подсистема сжатия контрольных точек отвечает за сжатие содержимого сохраняемых областей памяти. Сжатие используется для уменьшения размера контрольной точки. Данная подсистема может быть полностью отключена при настройке библиотеки. · Подсистема поддержки списка областей адресного пространства обеспечивает изменение, сохранение и восстановление списка областей адресного пространства, которые необходимо включить или исключить из контрольной точки. Данный список может модифицироваться как другими подсистемами библиотеки, так и пользователем через специальный интерфейс (чтобы обеспечить программисту возможность исключать ненужные области памяти из контрольной точки). · Подсистема определения расположения различных областей процесса инициализирует и поддерживает список областей адресного пространства процесса, внося туда информацию о расположении сегмента данных, стека и кучи процесса. · Подсистема перехвата обращений к библиотечным вызовам позволяет библиотеке запоминать информацию обо всех системных ресурсах, используемых процессом. Информация о ресурсах заносится в специальные таблицы и используется при восстановлении, также может модифицироваться список областей адресного пространства процесса (например, при выделении и освобождении отображений в память). · Подсистема интерфейса с библиотекой MPICH обеспечивает синхронизацию, корректное сохранение и восстановление состояния библиотеки обмена сообщениями при создании и восстановлении из контрольной точки. Кроме того, необходимо упомянуть подсистему сбора информации об эффективности библиотеки, которая сохраняет информацию о продолжительности работы различных этапов работы библиотеки (создание контрольной точки, восстановление из контрольной точки, синхронизация). Рассмотрим некоторые аспекты реализации библиотеки. Передача управления при работе библиотеки
После запуска программы управление передается в функцию main(), которая находится в библиотеке libcheckpoint. Если использование библиотеки не было запрещено при помощи конфигурационного файла, вызывается функция ckptInit(), которая проверяет наличие контрольной точки программы. Если контрольная точка не была найдена, управление передается в функцию ckpt_main(), которая уже находится в основной программе. После этого основная программа в какой-то момент может вызывать функцию создания контрольной точки, ckptCheckpoint(), которая сохранит контрольную точку и вернет управление обратно в программу. При восстановлении последовательность вызовов изменяется (рис. 3). Функция ckptInit() обнаруживает наличие контрольной точки и вызывает функцию ckptRestore(), которая в конце восстановления вызывает библиотечную функцию longjmp(), которая уже передает управление основной программе в точку, соответ- ствующую возврату из функции ckptCheckpoint(), после чего выполнение продолжается (данная схема несколько упрощена по сравнению с реальной последовательностью вызовов). Результаты тестирования эффективности Для тестирования эффективности библиотеки была выбрана вычислительная задача расчета свободномолекулярного обтекания цилиндра, написанная на языке Fortran-77. Тестирование производилось на суперЭВМ МВС-1000М, программа запускалась в штатном режиме работы суперкомпьютера, поэтому на приведенные результаты существенное влияние могла оказать загруженность файлового сервера, связанная с работой других задач. Библиотека контрольных точек была сконфигурирована с использованием подсистемы сжатия. Измерения проводились при помощи встроенных в библиотеку средств, в каждом эксперименте задача создавала 10 контрольных точек на протяжении своей работы, после этого временные затраты усреднялись. В этом тестировании не использовались никакие методы повышения эффективности, за исключением сжатия данных контрольных точки. Полученные результаты отражены в таблице:
Из полученных результатов следует, что в среднем издержки на создание контрольной точки такой задачи составляют 9,35 секунды, что при интервале создания контрольных точек в 30 минут составляет 0,5% потери по времени. Коэффициент сжатия данных контрольной точки в данном эксперименте достигал 43%.
На основе проведенных исследований была выполнена экспериментальная реализация библиотеки автоматических контрольных точек для параллельных задач в системе обмена сообщениями. Предлагаемая реализация поддерживает библиотеку обмена сообщениями MPICH в двух коммуникационных средах: разделяемая память (SMP-узлы) и сеть Myrinet (используется в кластерных системах, например, МВС-1000М). Одной из целей при разработке являлось обеспечение переносимости полученной библиотеки. Так, поддерживаются следующие архитектуры вычислительных систем: FreeBSD/x86, Linux/x86, Linux/Alpha. К библиотеке разработан интерфейс для языков C/C++ и Fortran, то есть она может быть использована в вычислительных задачах, написанных на этих языках. В перспективе могут быть разработаны интерфейсы для других языков программирования. Библиотека полностью сохраняет состояние процесса, из состояния операционной системы сохраняются только открытые файлы и отображения в память. Такого сохраненного состояния хватает для корректного восстановления выполнения большинства вычислительных задач. Предложенная реализация не является единственной, существуют и другие реализации систем контрольных точек (например [3,8-10]), однако они обладают рядом существенных недостатков, таких как отсутствие поддержки параллельных задач, малая переносимость и отсутствие поддержки MPICH. Необходимо упомянуть миграцию процессов – перенос работающего процесса с одной вычислительной системы на другую, причем эти системы могут иметь разную архитектуру. Миграция осуществляется путем создания контрольной точки (в случае разных архитектур – в особом формате), которая и перемещается между вычислительными системами [6-7]. Отметим возможные направления развития библиотеки. 1. Перенос библиотеки libcheckpoint на другие архитектуры вычислительных систем, в том числе и на другие коммуникационные среды (например, Fast Ethernet). Возможна адаптация к другим реализациям MPI (например, LAM/MPI). 2. Автоматический выбор места синхронизации, гарантирующего консистентность контрольной точки. 3. Автоматическое исключение ненужных областей памяти из контрольной точки [5]. Список литературы 1. Christine Morin, Isabelle Puaut. A Survey of Recoverable Distributed Shared Memory Systems. – IEEE Trans. on Parallel and Distributed Systems. – Volume 8. – Issue 9. – pp. 959-969. – 1997. 2. Message Passing Interface Forum. MPI: A Message-Passing Interface Standard. Version 1.1, June 1995. 3. James S. Plank, Micah Beck, Gerry Kingsley, Kai Li. Libckpt: Transparent Checkpointing under Unix. In Proceedings of the 1995 Winter USENIX Technical Conference. – UT-CS-94-242. 4. James S. Plank, Jian Xu, Robert H. B. Netzer. Compressed Differences: An Algorithm for Fast Incremental Check- pointing. Technical Report CS-95-302, University of Tennessee, August 1995. 5. James S. Plank, Micah Beck, Gerry Kingsley. Compiler-Assisted Memory Exclusion for Fast Checkpointing. - IEEE Technical Committee on Operating Systems and Application Environments, Special Issue on Fault-Tolerance. – Winter 1995. 6. Peter Smith, Norman C. Hutchinson. Heterogeneous Process Migration: The Tui System. - Software Practice and Experience. – Volume 28. – Issue 6. – pp. 611-639. – 1998. 7. Adam J. Ferrari, Stephen J. Chapin, Andrew S. Grimshaw. Process Introspection: A Heterogeneous Checkpoint/Restart Mechanism Based on Automatic Code Modification. - CS-97-05. – 1997. 8. Sriram Sankaran, Jeffrey M. Squyres, Brian Barrett, Andrew Lumsdaine, Jason Duell, Paul Hargrove, Eric Roman. Parallel Checkpoint/Restart for MPI Applications. 9. Duell J., Hargrove P. and Roman E. The Design and Implementation of Berkley Lab's Linux Checkpoint/Restart, 2002. 10. Абрамова В.А., Баранов А.В., Храмцов М.Ю. Библиотека интерфейсных вызовов (API) для организации контрольных точек (КТ) (Документация по ПО МВС-1000М). | ||||||||||||||||||||||||||||||||||||||||||||
 Теоретические аспекты реализации механизма контрольных точек
Теоретические аспекты реализации механизма контрольных точек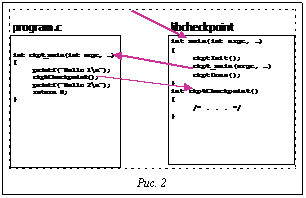 При запуске программы без восстановления из контрольной точки схема передачи управления между программой и библиотекой контрольных точек выглядит следующим образом (рис. 2).
При запуске программы без восстановления из контрольной точки схема передачи управления между программой и библиотекой контрольных точек выглядит следующим образом (рис. 2).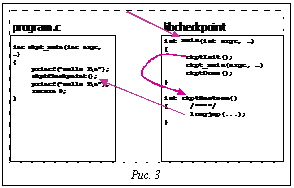 Среднее время восстановления задачи составляет около 15 секунд, что является вполне приемлемым.
Среднее время восстановления задачи составляет около 15 секунд, что является вполне приемлемым.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=564 |
Версия для печати Выпуск в формате PDF (1.31Мб) |
| Статья опубликована в выпуске журнала № 4 за 2004 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Системы компьютерной поддержки процессов анализа, синтеза и планирования решений в условиях неопределенности
- Информационно-вычислительный комплекс по применению мембран в биотехнологии
- Правовая охрана программного обеспечения с точки зрения международного сотрудничества стран-членов СЭВ
- Опыт разработки и эксплуатации системы управления базами данных (DBS/R)
- Знания в интеллектуальных системах
Назад, к списку статей