Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Поисковые системы с пространственно-образным индексированием и использованием нечетких моделей принятия решений
Аннотация:
Abstract:
| Авторы: Беляков С.Л. () - , Котов Э.М. () - , Целых А.Н. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10746 |
Версия для печати Выпуск в формате PDF (1.96Мб) |
Поиск информации является обязательной функцией любой информационной системы. Принципы поиска значительно различаются в зависимости от организации информационной базы. Чем более упорядочена информационная база, тем проще реализуются поисковые средства. Однако достичь упорядочения часто невозможно по ряду причин: - процесс накопления данных развивается независимо от процесса их использования, причем цели каждого из процессов различны; - информационная основа настолько разнородна, что не имеет смысла указывать единую схему данных из-за многоаспектности использования информации; - элементы данных и связи между ними динамичны, причем общей тенденцией является рост объема накапливаемых сведений. Как следствие, возникает проблема избыточности ответов на поисковые запросы. Типичным примером является получение информации из Интернета: обычным явлением может быть ответ поисковой системы, содержащий не одну сотню документов. При ограниченных возможностях восприятия человека анализ одного-двух десятков уже представляет серьезную проблему. Поэтому возникает вопрос об использовании новых инструментов поиска информации, позволяющих снижать избыточность ответов. Возможным путем решения проблемы может стать использование технологии геоинформационных систем (ГИС). Ее особенность в манипулировании пространственно-образными моделями реальных объектов и событий [1]. Если речь идет о земном пространстве, то естественной концептуальной основой моделей являются географические карты. Однако ничто не мешает создавать пространственно-образные модели информационного пространства, каковым может являться информационная база крупного предприятия или учреждения. С точки зрения организации поиска привлекательны следующие свойства карт, схем и планов. - Мощные изобразительные возможности. Бесспорно то, что рисунок, схема или диаграмма обладают большей информационной емкостью, проще воспринимаются, чем тексты. - Субъективность отображения и восприятия связей между объектами. Символы, слова и предложения являются эффективным инструментом любых формальных построений. Графические символы, фигуры и схемы способны отобразить ряд неформальных свойств, интуитивно воспринимаемых зависимостей. - Динамичность инструментария работы с картами, схемами и планами. Современные ГИС оснащены развитым пользовательским интерфейсом, что позволяет оперативно модифицировать картографические и атрибутивные объекты. В данной работе анализируется пространственно-образное индексирование элементов информационной базы как средство поиска в сложных разнородных системах. Целью применения пространственно-образного индексирования является сокращение сетевого трафика. Известным и эффективно применяемым на практике принципом поиска документов является поиск по ключевым словам [2]. Поисковая система для множества доступных документов Запрос на поиск формируется как выражение Результатом выполнения запроса является множество документов Здесь Пространственный характер индекс приобретает в случае, когда
где Запрос на поиск документов является выражением
Расширение размерности пространства для индексирования документов с формальной точки зрения не ускоряет поиск и не упрощает индексирование. Цель подобной операции – переход в более естественную для человека среду решения интеллектуальных задач. В отличие от числовых операций и символьных преобразований, пространственно-образные категории способны отобразить самые ценные – глубинные знания человека-эксперта [3]. Хотя указанные преимущества не реализуются автоматически, следует обратить внимание на особенность инструментария ГИС, позволяющего работать с объектами сложных систем: документы, характеризующиеся не набором ключевых слов Чем сложнее информационная база, тем большую роль начинают играть высокоуровневые показатели: достоверность, правдоподобие сведений документа, рейтинг авторов и источника публикации, уровень изложения, объем фактографического материала, цитируемость, уровень языка, стиль и другие. Многие из них субъективны и не поддаются количественной оценке, что создает серьезные трудности в отображении подобных данных в информационных системах. Для преодоления этих проблем представляется возможным использование нечетких моделей принятия решений, в которых важную роль играют, во-первых, лингвистические переменные, позволяющие формализовать именно качественную информацию об объекте принятия решений, представленную в словесной форме по результатам опроса экспертов в конкретной области, и, во-вторых, понятие функции принадлежности нечеткого множества. В этом случае весь массив документов описывается как набор нечетких множеств терминов, и при этом каждый термин определяет некую функцию принадлежности документам массива. Когда строится поисковый образ с использованием булевого оператора «И», то это интерпретируется как минимум из двух функций, соответствующих терминам запросов. При использовании булевого оператора «ИЛИ» это интерпретируется как максимум, а при использовании булевого оператора «НЕ» – как 1 («значение функции»). Далее документы результата поиска ранжируются в соответствии с полученными значениями так же, как и в случае с поиском по мерам близости. Построение функции принадлежности множества Q по результатам опроса одного эксперта осуществляется сопоставлением экспертом каждому элементу множества Х определенной степени принадлежности в силу имеющихся у эксперта опыта и уровня компетентности. При наличии ситуации, когда функция принадлежности строится по результатам опроса группы экспертов, возникает необходимость построения некоторой усредненной функции, что может не в полной мере учитывать мнения всех экспертов и в результате приведет к принятию неправильного решения. Для избежания этого предлагается введение функции принадлежности, принимающей значения для заданного аргумента из некоторого интервала, ширина которого определяется разбросом характеристик, представленных экспертами. Такую функцию можно назвать интервальной функцией принадлежности интервального нечеткого множества [4]. Рассмотрим алгоритм построения функции принадлежности интервального нечеткого множества. Пусть требуется для множества А* найти значения функции принадлежности по результатам опроса m экспертов [5] 1. Каждому из экспертов предъявляется количественное значение xj и определяется субъективное значение функции принадлежности 2. Определяется отклонение от среднего значения по формуле
3. Определяются предварительная верхняя и предварительная нижняя границы по формулам 4. Определяется максимальное значение max( 5. Значения
производятся нормировки верхней и нижней границ. Верхняя граница не должна превышать 1, а нижняя граница не должна быть меньше 0. Пункты 1-5 повторяются для всех количественных значений шкалы Х, тем самым определяются все значения функции C целью совершенствования организации информационной базы необходимо привлекать опыт экспертов и пользователей и на основе поступающей от них информации проводить улучшение формулировки запросов пользователей. Можно предложить метод изменения запросов, известный под названием обратная связь по релевантности. Суть его состоит в том, что некоторые документы, отвечающие в наибольшей степени поступившему от пользователя запросу q, выдаются пользователю, после чего ему необходимо эти документы, полагаясь на собственные требования и опыт, разделить на релевантные R или нерелевантные S. Далее оценки релевантности возвращаются в систему, и с их помощью производится изменение запроса посредством увеличения веса терминов запроса, присутствующих в релевантных документах, и понижения веса терминов запроса, присутствующих в нерелевантных документах. В результате новый запрос q' с использованием обратной связи по релевантности может бать описан следующим образом:
где При проведении оценки поиска с использованием обратной связи на основе процесса анализа слов и также, в большей степени, если для анализа используется тезаурус, установлено, что, среди прочих интерактивных методов поиска, поиск с обратной связью по релевантности дает наилучшие результаты [7]. С точки зрения организации массивов логических структур индекса также может быть выбрана прямая организация файлов и так называемые обратные, или инвертированные файлы. Инвертированный файл основан на логическом разделении документального файла на несколько подфайлов, по числу индексационных терминов, имеющихся в словаре системы, и по своей структуре аналогичен предметному указателю книги и состоит из словаря и списков вхождений ключевых слов.
Если документы и запросы представлены множеством наборов взвешенных терминов документа и запроса, можно вычислить функцию подобия векторов S, отражающую степень сходства каждой пары «запрос-документ»: запрос где документ j где Функция подобия
Далее документы можно ранжировать в порядке уменьшения значений функции подобия «запрос-документ». При решении проблемы отображения данных, не поддающихся количественной оценке, в ГИС может быть использован следующий прием: вводится совокупность тематических карт или схем, в каждой из которых вектор показателей документа Это означает представление в двухмерной координатной системе Инструментарий ГИС дает дополнительные возможности построения запросов интуитивно-образного характера. Например, запрос "найти документы, близкие по содержанию" может реализоваться как построение на заданном расстоянии (в евклидовой метрике) области, подобной образу области известного содержания. Выражение "искать информацию в направлении…" в ГИС приобретает наглядную интерпретацию и понятную реализуемость. Заметим, что запросы могут транслироваться в выражения для поиска по ключевым словам и направляться соответствующим серверам для выполнения. Структуру поисковой системы можно изобразить следующим образом: Запрос строится пользователем с использованием навигатора – диалогового средства, предоставляемого ГИС. С его же помощью ГИС формирует и поддерживает пространственно-образный индекс. Планировщик выполнения запросов является экспертной системой, которая на основе знаний из пространственно-образного индекса формирует множество ссылок на запрошенные документы. Приведенная структура может быть эффективно реализована по технологии "клиент-сервер". Многие современные ГИС представляют объектный интерфейс внешним приложениям по спецификациям COM или CORBA. Таким образом, сервер ГИС выполняет традиционную функцию по управлению картографической информацией, которая в данном случае относится к информационному пространству. Список литературы 1. Берштейн Л.С., Беляков С.Л. Геоинформационные справочные системы.- Таганрог: Изд-во ТРТУ, 2001. 2. Гаврилова Т.Н., Хорошевский В.Ф. Базы знаний интеллектуальных систем. – С-Пб: Питер, 2000. 3. Дулин С.К., Самохвалов Р.В. Оценка эффективности экспертного анализа диссиминации неструктурированной текстовой информации - Изв. РАН: Теория и системы управления. - 2003. - №1. - С. 95-104. 4. Целых А.Н. Разработка и исследование моделей принятия решений в интегрированных интеллектуальных системах и их применение для решения экологических задач: Дис. … докт. техн. наук. - Таганрог, 2000. 5. Берштейн Л.С., Целых А.Н., Тимошенко Р.П. Об использовании интервальной функции принадлежности нечеткого множества. - Изв. вузов. Северо-Кавказский регион. Технические науки. - Р-н-Д.: Изд-во РГУ. - 1999. - №1. - С. 3-8. 6. Бочаров. П.П., Печерина А.В. Теория вероятностей. Математическая статистика: Учеб. пособие. - М.: Гардарика, 1998.-326 с. 7. Solton G., The Performance of interactive information retrieval, Information processing letters, 1, No. 2, 1971. |
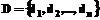 строит индекс как отображение множества ключевых слов
строит индекс как отображение множества ключевых слов 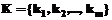 в множестве документов
в множестве документов 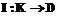 .
.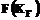 , где
, где 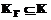 .
.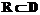 , причем
, причем 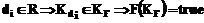 .
. – ключевое множество слов документа
– ключевое множество слов документа 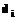 .
.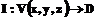 ,
,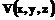 – трехмерное евклидово пространство. Каждому документу в таком представлении сопоставлен объект трехмерного пространства – образ множества документов
– трехмерное евклидово пространство. Каждому документу в таком представлении сопоставлен объект трехмерного пространства – образ множества документов 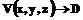 ,
, 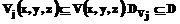 .
.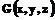 , которое используется аналогично рассмотренному выше:
, которое используется аналогично рассмотренному выше: .
. .
. (xj)=[
(xj)=[ (xj),
(xj),  (xj)], xjÎX, j=1,..,n.
(xj)], xjÎX, j=1,..,n.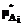 (xj), получаемое от i эксперта, соответствующее значению для множества А*. Далее находим среднее значение функции принадлежности, используя среднее арифметическое, задаваемое формулой [6]
(xj), получаемое от i эксперта, соответствующее значению для множества А*. Далее находим среднее значение функции принадлежности, используя среднее арифметическое, задаваемое формулой [6] 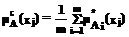 .
. .
.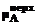 (xj)=
(xj)=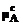 (xj) + g(xj),
(xj) + g(xj), 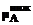 (xj)=
(xj)=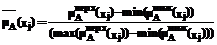 ,
,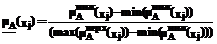 ,
,
 – это i-й документ, входящий в множество релевантных документов;
– это i-й документ, входящий в множество релевантных документов; 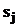 – j-й документ, входящий в множество нерелевантных документов;
– j-й документ, входящий в множество нерелевантных документов; 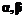 – константы.
– константы.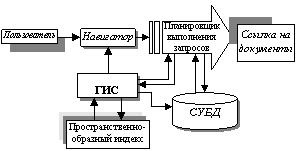 При использовании инвертированных файлов вместо поиска в большом файле документов применяется короткий поиск, который заключается в считывании инвертированных списков, номеров документов, позиций слова в документах и в соответствующем ранжировании полученного результата.
При использовании инвертированных файлов вместо поиска в большом файле документов применяется короткий поиск, который заключается в считывании инвертированных списков, номеров документов, позиций слова в документах и в соответствующем ранжировании полученного результата.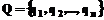 ,
,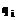 – вес i-го термина запроса;
– вес i-го термина запроса;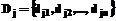 ,
,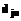 – вес i-го термина документа j.
– вес i-го термина документа j. .
.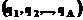 представляется, например, как
представляется, например, как 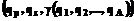 ,
, 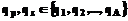 .
.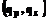 документа образом, характеризующимся
документа образом, характеризующимся 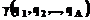 . Сопоставляя слои графического изображения, цвет, текстуры и формы, комбинируя пары показателей
. Сопоставляя слои графического изображения, цвет, текстуры и формы, комбинируя пары показателей | Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=600 |
Версия для печати Выпуск в формате PDF (1.96Мб) |
| Статья опубликована в выпуске журнала № 1 за 2004 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Расчет нечеткого сбалансированного показателя в задачах взвешивания терминов электронных документов
- Формирование программ развития больших систем административно-организационного управления
- Правовая охрана программного обеспечения с точки зрения международного сотрудничества стран-членов СЭВ
- Знания в интеллектуальных системах
- Методы поисковой адаптации на основе механизмов генетики, самообучения и самоорганизации
Назад, к списку статей