Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Построение корпоративных хранилищ данных с использованием технологии Informix DataStageXE
Аннотация:
Abstract:
| Автор: Чихарев М.Н. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 11945 |
Версия для печати Выпуск в формате PDF (1.58Мб) |
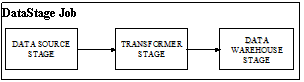
Рано или поздно любая компания приходит к решению о создании корпоративного хранилища данных. Этому могут предшествовать много причин: попытка централизации накопленных данных, то есть возможность получения представления о данных предприятия как о едином целом, создание OLAP-системы и выполнение аналитических запросов над всей информацией из данной прикладной области, стандартизация форматов хранения данных и т.д. Любое хранилище данных включает в себя следующие функциональные компоненты: средства ETL (средства извлечения, очистки и загрузки данных), сервер БД и OLAP-средства. Продукты компании Informix Software the database company и Ascential Software позволяют получить комплексное решение для создания корпоративного хранилища данных. В качестве серверов БД для хранилища данных можно использовать серверы Informix Extended Parallel Server (XPS) и Red Brick Decision Server, хотя в некоторых случаях реализация возможна на Informix Dynamic Server. Однако сервер Red Brick Decision Server обладает большим функционалом, помогающим быстро и оптимально обрабатывать OLAP-запросы. В качестве OLAP-средств удобно использовать продукт компании Informix MetaCube. Когда корпорация принимает решения о создании хранилища данных, она, как правило, сталкивается со следующими вопросами: как загрузить данные из существующих разнородных информационных систем (это могут быть dbf-файлы, различные серверы БД: Informix, Oracle, SyBase, MS-SQL, унаследованные системы на FOXPRO, CLIPPER, CLARION или просто текстовые файлы) в хранилище данных; как сделать процесс загрузки более быстрым; как построить и оценить информационную модель преобразования данных, хранящихся в различных, неоднородных источниках данных; как реализовать модель преобразования, трансформации данных; как поддерживать ссылочные отношения между загружаемыми данными, которые извлекаются из различных источников; как работать и управлять метаданными. Эффективном средством решения поставленных вопросов является пакет DataStageXE. Что такое DataStageXE? Пакет DataStageXE, предназначен для извлечения данных из различных источников, предварительной очистки этих данных перед их консолидацией и загрузкой в любой приемник или хранилище данных (Data Warehouse) для последующего анализа. В пакет входят следующие модули: DataStage Client, DataStage Server, MetaStage Explorer, Quality Manager, MetaStage Director. Дополнительные модули для DataStageXE: DataStage Click Pack, DataStage XML Pack, MetaBrokers, DataStage XE/390. Рассмотрим, какой функционал содержит в себе модуль DataStage: он позволяет выполнять основные операции по извлечению данных из различных источников, их очистке, объединению и выполнению других необходимых операций и записи этих данных в хранилище или другой источник данных. Кроме этих стандартных функций, обеспечиваются следующие возможности: · использование графической среды для определения схемы по извлечению, трансформации и загрузке данных; · извлечение данных практически из любых источников; · агрегирование и конвертирование данных с использованием стандартных возможностей DataStage; возможно использование собственных функций для этих целей (при легком и интуитивно понятном графическом интерфейсе); · возможность использования XML для импорта и экспорта (XML интегрирован в ядро); · загрузка данных в любой целевой приемник или хранилище данных. DataStage состоит из двух компонентов: Client Component (клиентская часть, доступна на Windows NT, Windows 2000) и Server Component (серверная часть, доступна на Windows NT и Unix). Клиентская часть состоит из модулей DataStage Designer, DataStage Manager, DataStage Director, DataStage Administrator. В серверной части три компонента: Repository, DataStage Server, DataStage Package Installer. Работа с DataStage начинается с создания проекта. Сначала необходимо описать структуру источника и приемника данных. Для доступа к источникам данных можно использовать SQL-операторы или процедуры, а также и стандартный набор уровней (stage). При создании проекта обычно описывают всю работу (DataStage job), которую необходимо выполнить в этом проекте, то есть все действия, связанные с извлечением данных, операции преобразования и очистки данных, которые необходимо произвести на промежуточном этапе, прежде чем данные будут помещены в хранилище или другой приемник данных. Для описания действий по очистке данных, которые необходимо выполнить с извлекаемыми данными, можно использовать встроенные компоненты (built-in component), которые стандартно поставляются с DataStage, а также собственные компоненты (user-defined component). Для создания и описания проекта используется клиентский модуль DataStage Manager, который обладает легким и понятным графическим интерфейсом. Следующий шаг – это описание непосредственно самой DataStage job, действий по извлечению и очистке данных. DataStage job – это совокупность последовательных действий: действия по извлечению данных из описанного источника, действия, которые необходимо произвести с данными, прежде чем они будут помещены в приемник, и запись данных в целевой приемник. DataStage job состоит из отдельных stage, которые будем называть уровнями. Каждый уровень описывает часть процесса по извлечению и трансформации данных или используется для определения источника (приемника) данных внутри одной DataStage job. Уровни между собой соединяются с использованием элемента связи DSLink. Приведем пример DataStage job и уровней, из которых она состоит (см. рисунок). Data Source Stage – уровень, определяющий источник данных, откуда и какие данные будут извлекаться. В качестве данного уровня может выступать ODBC Stage или любой другой уровень. Второй уровень (Transformer Stage) описывает действия по очистке или преобразо- ванию данных. Data Warehouse Stage – уровень, определяющий приемник данных. В качестве него может выступить DataStage Informix Bulk Load plug-in. В DataStage существуют два типа уровней. Built-in – это уровни, поставляемые с DataStage и используемые для извлечения, очистки, трансформации и записи данных. Plug-in – это дополнительные уровни, которые могут быть установлены в DataStage для выполнения специфических задач, которые не могут быть реализованы с применением built-in уровней. DataStage имеет следующие built-in уровни: Aggregator stage, Hash File stage, Internal Stage, ODBC data access stage, Sequential data access stage, UniData data access stage, UniVerse data access stage и др. Процесс преобразования о очистки данных можно описывать, используя Aggregator stage, Transformer stage или любой другой уровень, который используется для этих целей. Transformer уровень предназначен для управления потоками данных, выполнения конвертации данных и передачи этих данных другим transformer уровням или другим уровням, которые описаны как приемники данных. Transformer уровень позволяет иметь любое количество источников данных, которые связаны с различными уровнями. Используя Transformer уровень, можно: объединять данные, принадлежащие различным источникам, для каждого источника определять условия выборки и конвертации данных, отношения между источниками данных. Аналогична ситуация с приемниками данных, которых может быть любое количество. Потоки данных можно распределять между приемниками в произвольном порядке, приемники могут принадлежать к различным уровням источников данных. Уровни, описывающие источники данных, которые имеют реляционную модель, позволяют связывать объект (таблицы) между собой, используя интуитивно понятный синтаксис написания SELECT-оператора. DataStage позволяет в качестве источников данных использовать пользовательские функции, хранимые процедуры или просто SELECT-операторы. При этом имеется возможность определять действия перед началом ввода одинаковых данных. Есть возможность описать обработчик ошибок, какие действия следует выполнить при возникновении нестандартных ситуаций. Создание, описание свойств и соединение уровней друг с другом – эти действия совершаются с применением графической среды DataStage Designer, которая имеет понятный графический интерфейс. После того как создан проект и описана DataStage job, выполняется процесс компиляции. Для запуска DataStage job используется DataStage Director.
Существуют два основных вида DataStage job – Server job и Mainframe job. Server job – откомпилированная DataStage Job, запускаемая на DataStage Server. Mainframe job – действия, которые доступны только при установлении DataStage XE/390. Это действия и операции, которые связаны с извлечением данных из mainframe. В DataStageXE реализована поддержка национальных языков – NLS (National Language Support). Серверная часть DataStage После рассмотрения основных принципов работы DataStage рассмотрим ее клиентскую и серверную компоненты. Серверная часть представлена в DataStage тремя компонентами. Repository содержит всю информацию для построения или определения хранилища данных. Repository хранит описание всех источников и приемников данных, определение всех таблиц и колонок, описание всех проектов и DataStage job. DataStage Server предназначен для исполнения DataStage job, которая извлекает данные, производит необходимые действия с извлеченными данными и загружает их в другой приемник или хранилище данных. DataStage Package Installer – компонента, предназначенная для инсталляции DataStage plug-ins. Может оказаться, что встроенные уровни не удовлетворяют всем потребностям по извлечению и трансформации данных. В этом случае есть возможность установить plug-in уровень, который обладает дополнительными свойствами по извлечению и трансформации данных. В настоящее время доступны DataStage plug-in уровни: DataStage IBM DB2 plug-in, DataStage ERwin 3.5 Meta Data plug-in, DataStage File Transfer plug-in и др. Особое внимание следует уделить следующим DataStage plug-ins. DataStage Informix Call Interface plug-in – это реализация компании Informix ODBC стандарта. В данной версии продукта есть возможность работать с БД Informix только через ODBC уровень, но можно использовать DataStage Informix Call Interface plug-in для улучшения работы с БД Informix, так как в этом случае чтение и запись данных в/из БД Informix происходят через Informix-CLI (Informix Call Interface). Это дает следующие преимущества: увеличение производительности, Informix-CLI уровень использует CLI API, что позволяет корректно работать с национальным языком; поддержка DDL операторов (create table, drop table) для приемника данных, более легкая конфигурация на Unix; поддержка MetaStage и многое другое. DataStage Informix Bulk Load plug-in – уровень, который быстро и эффективно подготовит и загрузит данные из любого DataStage уровня (ODBC stage, Sequential File stage и др.) в БД Informix. Данный уровень использует утилиту Informix DBLOAD, что увеличивает эффективность загрузки данных в том случае, когда выполняется DataStage job под административным пользователем на той же машине, где установлен Informix сервер. При этом появляются дополнительные возможности: поддержка национального языка, поддержка MetaStage, возможность выполнить операции над данными до и после загрузки данных и др. DataStage Informix XPS Bulk Load plug-in загружает данные в Informix XPS таблицы, а также предоставляет другие возможности для увеличения производительности. DataStage Red Brick Bulk Load plug-in позволяет быстро и эффективно подготовить и загрузить потоки отформатированных данных из любого источника DataStage в таблицы Red Brick Warehouse, а также генерировать и исполнять команды для загрузки данных в Red Brick, поддерживать национальные языки, MetaStage и многое другое. Клиентская часть DataStage состоит из следующих модулей: DataStage Designer, DataStage Manager, DataStage Director, DataStage Administrator. DataStage Designer – графический интерфейс для создания DataStage приложения (известного как DataStage Job). Каждая DataStage Job определяет источники данных, приемники данных и требования для трансформации данных. Процесс компиляции DataStage job можно выполнить как в DataStage Director, так и в DataStage Designer. В случае возникновения сообщения об ошибке во время процесса компиляции, имеется возможность получения подробного сообщения об ошибках. DataStage Director – графическая утилита для определения времени и срока выполнения DataStage job и ее состояния. DataStage Director позволяет запускать и отслеживать статус выполнения DataStage job, которая выполняется DataStage сервером. Важно отметить, что это – графическая среда, обладающая легким и понятным интерфейсом. Есть возможность отслеживать текущие состояния DataStage job, определять, находится ли DataStage job в процессе выполнения или работа завершена, каков статус завершения работы (с ошибками или без ошибок), когда последний раз была выполнена эта работа. DataStage job может находиться в следующих состояниях: откомпилирована (compiled), не откомпилиро- вана (no compiled), выполняется (running), за- кончена (finished), закончена (см. журнал) (finished (see log)), остановлена (stopped), прервана (aborted), validate, validate (see log), failed validate, has been reset. Очень важное свойство в DataStage Director –Validate job – это тот случай, когда можно проконтролировать успешное выполнение работы без чтения реальных данных. Validate job следует выполнить перед первым запуском или после выполнения любых значительных изменений параметров для DataStage job. Когда выполняется validating job, делается контроль следующих параметров без реального извлечения, конвертации и записи данных. Проверяется возможность соединения с источниками и приемниками данных; контроль предкомпилированных SQL-операторов (prepared sql-stmt), открытия файлов и других источников данных. DataStage Director осуществляет ведение логического журнала выполнения работы, в котором хранится информация обо всех выполненных работах DataStage, когда была стартована та или иная DataStage job, как проходил процесс выполнения этой DataStage job. При необходимости есть возможность получить более детальную информацию о предупреждениях и об ошибках, которые возникли во время выполнения данной работы. При возникновении ошибки можно легко определить, на каком этапе DataStage job она возникла, а также быстро получить подробную информацию об ее возникновении. Имеется возможность определять количество обрабатываемых строк для отдельной работы, а также для всех работ на уровни сессии. После того как DataStage job обработает требуемое количество строк, DataStage прервет свою работу. Можно определять количество warning и многие другие свойства для работы. Используя DataStage Director, возможно составлять план выполнения DataStage job, определять дату и время выполнения работы. В DataStage Director есть возможность выполнить трассировку DataStage job: трассировку вводимых и выводимых строк, отслеживание вызова функций и процедур, которые вызываются во время работы DataStage job и многое другое. Можно получить статистическую информацию о выполнении DataStage job. Эта информация очень облегчает процесс создания DataStage job. Можно легко и быстро определить место возникновения ошибки или проверить правильность исполнения последовательности действий по извлечению данных. В DataStage Director есть возможность определить входные параметры для каждой DataStage job. Используя возможности DataStage Director, можно легко отслеживать, какие ресурсы были блокированы во время выполнения DataStage job и при необходимости иметь возможность освободить эти ресурсы. Существует возможность создавать batch (это группа различных DataStage job или одной DataStage job, но с разными параметрами, которые должны выполняться последовательно), определять входные параметры для группы или другие свойства. Контроль за работой группы производится аналогично контролю за DataStage job. DataStage Manager – графический интерфейс для просмотра и редактирования содержания репозитория. Он используется для определения: структуры источников данных, структуры таблиц и колонок, через которые будет осуществляться доступ к источникам данных. Аналогичные параметры определяются для приемника данных. DataStage Administrator – графический интерфейс для определения прав пользователей, создания проектов и перемещения проектов. При помощи данного модуля можно создавать новые проекты и определять свойства для этих проектов. Можно выполнять export и import вашего проекта для переноса его в другое место. Большинство задач по конфигурированию DataStage выполняется из модуля DataStage Administrator, однако для этого пользователь должен принадлежать к группе root или uvadm для Unix или Administrator group для Windows NT. Для предотвращения несанкционированного доступа к DataStage проекту можно связать пользовательские группы в системе (user group) с соответствующими правовыми категориями. В DataStage существует всего три категории: · DataStage Developers – пользователи имеют полный доступ ко всем элементам и областям DataStage проекта; · DataStage Operator – пользователи имеют право только запускать и управлять DataStage job; · None – это пользователи которые не имеют права соединяться с DataStage проектом. В заключение отметим, что DataStageXE успешно используется такими компаниями, как: SIEMENS, IBM, DEUTSCHE BANK, AMERICAN EXPRESS, MOTOROLA, DHL, AT&T, XEROX, LUFTHANSA, RENAULT, FRANCE TELECOM, WHIRLPOOL, BARCLAYS и многими другими. В России DataStageXE применяется в ЛУКОИЛ (Пермь), а такие компании как Philip Morris, Илим Палп, Автоваз, Комстар уже планируют использовать DataStage. Мы дали всего лишь краткий обзор DataStage и обозначили место этого продукта в технологии Informix по построению хранилищ данных. Informix широко признан в мире как лидер в области технологии корпоративных СУБД – от небольших рабочих групп до очень крупных приложений с параллельной обработкой. Инструментальные средства разработки приложений, серверы баз данных Informix позволяют компании быть на переднем крае информацион- ных технологий, включая такие области, как хра- нилища данных, высокопроизводительная опера- тивная обработка транзакций (OLTP), OLAP и Web/электронная коммерция. Дополнительная информация по технологии Informix и DataStageXE находится на Web-сайтах http://www.Informix.com или http://www.Informix.ru. Список литературы 1. Ardent DataStage ”Server Job Developer’s Guide” version 4.1.1. 2. Ardent DataStage ”Core Developer’s Guide” version 4.1.1. 3. Ardent DataStage ”Operator’s Guide” version 4.1.1. 4. Ardent DataStage ”Server Job Tutorial” version 4.1.1. 5. Quality Manager ”User’s Guide” version 4.8. 6. MetaStage ”User’s Guide” version 2.1. 7. Quality Manager ”Methodology and Application Guide” version 4.8. |
 После определения свойств для всех уровней и описания всей DataStage job, необходимых в этом проекте, завершаем описание проекта и переходим к исполнению этого проекта. На следующем шаге необходимо определить, когда будут запускаться DataStage job работы, из которых состоит проект. Действия по определению того, когда и с какими параметрами будет выполняться DataStage job, определяются с помощью DataStage Director.
После определения свойств для всех уровней и описания всей DataStage job, необходимых в этом проекте, завершаем описание проекта и переходим к исполнению этого проекта. На следующем шаге необходимо определить, когда будут запускаться DataStage job работы, из которых состоит проект. Действия по определению того, когда и с какими параметрами будет выполняться DataStage job, определяются с помощью DataStage Director.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=821 |
Версия для печати Выпуск в формате PDF (1.58Мб) |
| Статья опубликована в выпуске журнала № 2 за 2001 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Инженерная программа трехмерного моделирования магнитных систем LittleMag
- Автоматизированное рабочее место расчета стоимости эксплуатации кораблей
- Автоматизированная система принятия решений при стратегическом планировании устойчивого развития региона в условиях нечеткой информации
- Устройство для резервирования коммуникационных узлов
- Формулировка задачи планирования линейных и циклических участков кода
Назад, к списку статей